(1) R이란?
- 1995년 로스 이하카와 로버트 젠틀맨에 의하여 제작된 언어
- 무료 오픈 소스로 사용자 간에 패키지와 최신 기술에 대한 공유가 쉬움 (프리웨어 x)
- S언어로 작성
- 인터프리터 언어로 라인별로 문장을 실행 가능
- 독립적으로 재활용 가능한 여러 모듈로 구성되어 설치 용량이 작음
(2) RStudio 기본 구성
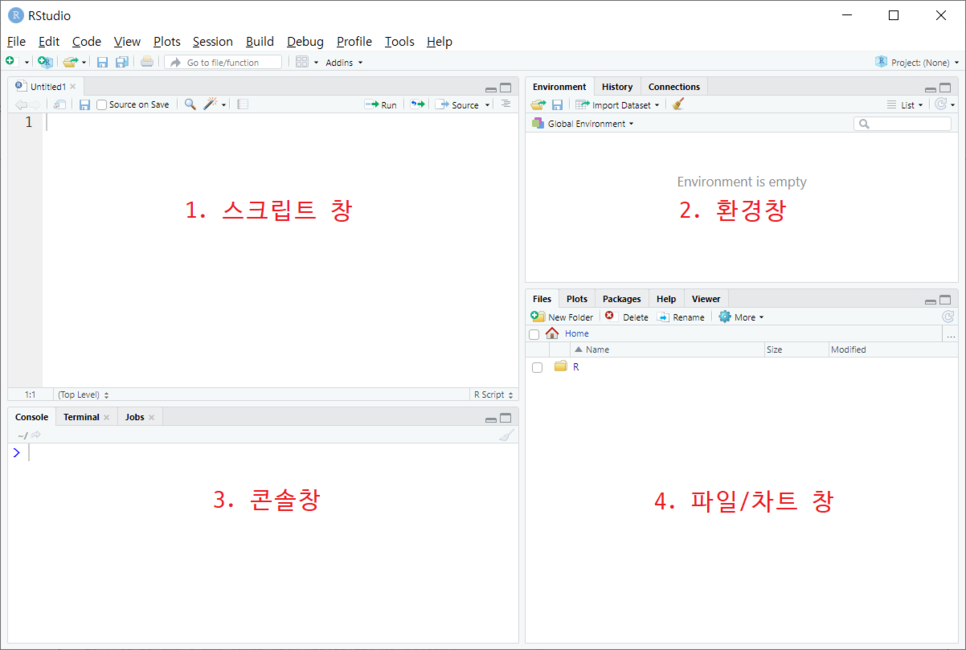
- {1} R 스크립트 창
- {2} 환경창과 히스토리
- 환경창 -> 명령문을 통해 생성된 변수, 불러온 데이터, 생성된 함수 등의 개요
- 히스토리 -> 그동안 실행된 과거 명령문
- {3} 콘솔창 -> 명령문을 작성하고 실행 가능, 명령문에 의해 발생한 오류, 결과 등 확인 가능
- {4} 파일/차트창 (기타창) -> 파일, 현재 호출되어 있는 패키지, 산점도같은 시각화 데이터, 도움말
(3) R의 데이터 타입
- 문자형 타입 (character) -> 따옴표 혹은 쌍따옴표
- 숫자형 타입 numeric (숫자형) : 계산이 가능한 데이터
- double (실수형), integer (정수), complex (복소수)
- Inf -> 무한대, -Inf -> 음의 무한대
- 논리형 타입 (logical): 참 혹은 거짓 의미
- TRUE, FALSE (대문자)
- NaN, NA, NULL (NaN, NA -> logical, NULL -> NULL)
- NaN -> Not a Number (계산 불가능)
- NA -> Not Available, 데이터 값 없음, 하나의 공간을 차지하는 결측값
- NULL -> 공간을 차지하지 않는 존재하지 않는 값
(4) R 기본 문법
- 대입 연산자
- 오른쪽 값을 왼쪽에 대입 : <-, <<-, =
- 왼쪽 값을 오른쪽에 대입 : ->, ->>
- 비교 연산자
- NA는 비교할 값이 존재 x / 어떤 것과 비교하더라도 NA
- is.na -> NA인지 아닌지를 비교, is.null -> NULL인지 아닌지를 비교
- 산술 연산자
- / -> 두 숫자의 나눗셈
- %/% -> 두 숫자의 나눗셈의 몫
- %% -> 두 숫자의 나눗셈의 나머지
(5) R 데이터 구조
- 벡터 : 타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조
- 'c' 안에 콤마를 구분자로 써서 성분 직접 입력 가능
- ':'을 활용하여 시작값과 끝 값 지정해 벡터 생성 가능
v1 <- c(3, TRUE, FALSE)
v2 <- c(1:6) # : (범위) : 1부터 6까지
- 행렬 : 2차원 이상의 구조를 갖는 벡터
- 벡터의 성질을 갖고 있어 저장된 모든 데이터는 같은 타입이어야 함.
- 배열 : 3차원 이상의 구조를 갖는 벡터
- 벡터의 성질을 갖고 있어 저장된 모든 데이터는 같은 타입이어야 함. 같은 데이터형이 아닌 경우 자동으로 str로 변환
- array를 사용하여 배열을 만들 수 있으나 몇 차원의 구조를 갖는지 dim옵션에 명시해야 함. 그렇지 않으면 1차원 벡터 생성
- 개수와 차원 맞춰주기
arr1 <- array(c(1:11, "hello"), dim = c(2,3,2))
arr1
a2 <- c(1:18) # 16까지하면 error
dim(a2) <- c(2,3,3)
a2
dim(a2)
- 리스트 : 데이터 타입, 데이터 구조에 상관없이 사용자가 원하는 모든 것을 저장할 수 있는 자료구조 / 성분간 이질적
- 데이터프레임 : 데이터 분석을 위한 2차원 구조를 갖는 관계형 데이터 구조, 각 열은 서로 다른 타입의 데이터 가질 수 있음. 단, 각 열의 벡터들의 길이가 같아야 함
vt1 <- c(1,2,3)
vt2 <- c("a","b","c")
df1 <- data.frame(vt1, vt2)
df1
(6) 기본 함수
- seq () -> 시작값, 끝값, 간격으로 수열 생성
(시작, 끝, 간격=length)
- rep () -> 주어진 데이터를 일정 횟수만큼 반복
- rep(값, time:전체반복횟수, each:개별반복횟수) /default: time
- ls () -> 현재 생성된 변수들의 리스트를 보여줌
- nchar -> 입력된 데이터의 글자 수 계산
- subset -> 입력 데이터의 특정 조건 만족하는 부분집합 구함
- merge -> 입력된 두 데이터프레임을 공통된 특정 기준열에 의하여 병합
(7) 통계 함수
- mean -> 평균, median-> 중앙값, var -> 표본분산, sd -> 표본표준편차
- summary -> 요약값
(8) R 데이터 핸들링
* 데이터 추출: [ ] / 데이터프레임 $이용
* 데이터 결합 : rbind - 행으로 결합 / cbind - 열로 결합
(9) 데이터 탐색
- head -> 데이터 앞 일부분, tail -> 데이터 뒤 일부분
- quantile -> 수치 벡터의 4분위수
(10) 정규 분포 (기본값 표준 정규 분포 mean =0, sd = 1)
- rnorm (확률밀도 함수) -> rnorm (표본갯수, 평균, 표본에 대한 표준편차)
(11) plot
