양자화 및 LLM – 모델을 관리 가능한 크기로 압축
출처: https://www.datasciencecentral.com/quantization-and-llms-condensing-models-to-manageable-sizes/
😈 데이터블로그 챌린지 7일차😈 입니다.
LLM 모델을 양자화를 통해 압축하는 방법에 대해 알아보았습니다.
요약
- 양자화는 AI 모델의 크기, 속도 및 메모리 요구 사항을 줄이는 데 효과적인 기술
- 다양한 유형의 양자화가 있으며, 각 유형마다 고유한 장점과 단점이 있습니다. 사용 사례에 가장 적합한 유형을 선택하는 것은 모델의 정확도, 성능 및 배포 제약 조건을 고려하는 것이 중요함
내용

LLM에는 1750억개의 매개변수(parameter)가 사용됨
양자화란?
- 모델의 각 매개변수의 numerical precision을 줄여서 메모리 공간을 줄이는 기술 ( 고해상도 이미지를 저해상도로 압축하는 것과 유사함)
양자화 기초
LLM이나 딥러닝 모델에서 숫자 값은 일반적으로 정밀도가 높은 부동 소수점 숫자(예: 32비트 또는 16비트 부동 소수점 형식)로 표현
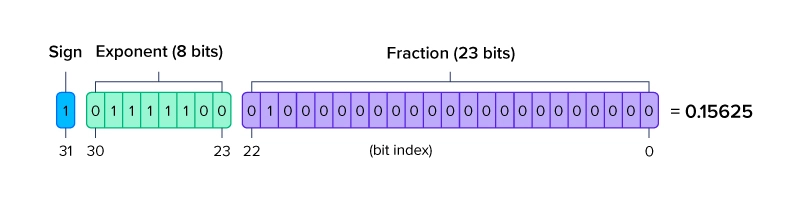
양자화는 정밀도가 높은 부동소수점 숫자를 16비트/8비트 정수와 같은 낮은 정밀도 표현로 변환하여, 훈련 및 추론 중에 모델의 메모리 효율성과 속도를 높임
=> 따라서, 모델 훈련 및 추론에 더 작은 저장공간와 더 작은 메모리가 필요하며, 하드웨어에서 더 빠르게 계산이 실행됨
양자화 유형
- 정적 양자화(Static Quantization)
-AI 모델 학습 단계에서 적용되는 기술로, 가중치와 활성화 값을 낮은 비트 정밀도로 양자화하여 모든 레이어에 적용합니다.
-가중치와 활성화 값은 미리 양자화되며, 전체적으로 고정됩니다.
-배포하려는 시스템의 메모리 요구 사항을 미리 파악할 때 유용합니다.
장점:
양자화 파라미터가 고정되어 배포 계획을 간소화합니다.
모델 크기를 줄여 에지 디바이스 및 실시간 애플리케이션에 더 적합하게 만듭니다.
단점:
정적 양자화 방식으로 인해 성능 저하가 예측 가능하며, 전체적인 고정된 접근 방식 때문에 특정 양자화된 부분이 더 많이 영향을 받을 수 있습니다.
다양한 입력 패턴에 대한 정적 양자화의 적응력이 제한적이며, 가중치 업데이트에 대한 강력함이 떨어집니다.
- 동적 양자화(Dynamic Quantization)
-가중치는 정적으로 양자화하고 활성화 값은 모델 추론 중 실시간으로 양자화하는 방식입니다.
-가중치는 미리 양자화되지만 활성화 값은 데이터가 네트워크를 통과하면서 동적으로 양자화됩니다. 즉, 특정 모델 부분의 양자화는 고정된 양자화 정밀도 대신에 다른 정밀도로 실행됩니다.
장점:
모델 압축과 런타임 효율성 사이의 균형을 맞추면서도 정확도의 손실 없이 작동합니다.
활성화 정밀도가 가중치 정밀도보다 더 중요한 모델에 유용합니다.
단점:
정적 방식과 비교하여 성능 향상이 예측하기 어렵습니다.
동적 계산으로 인해 다른 방법보다 더 많은 계산 오버헤드와 더 긴 학습 및 추론 시간이 필요하지만, 양자화하지 않은 경우보다 여전히 가벼움
- 훈련 후 양자화(Post-training Quantization, PTQ)- 정적 or 동적
이 기술은 양자화를 훈련 프로세스 자체에 통합합니다. 가중치와 활성화 값의 분포를 분석하여 이 값들을 낮은 비트 심도로 매핑하는 작업을 포함합니다. PTQ는 에지 디바이스 및 모바일과 같은 리소스 제약적 디바이스에 배포됩니다.
장점:
다시 훈련할 필요 없이 사전 훈련된 모델에 직접 적용할 수 있습니다.
모델 크기를 줄이고 메모리 요구 사항을 줄입니다.
배포 중 및 이후 더 빠른 계산을 가능하게 하는 향상된 추론 속도
단점:
가중치 근사로 인해 모델 정확도가 저하될 수 있습니다.
양자화 오류를 완화하기 위해 신중한 캘리브레이션과 미세 조정이 필요합니다.
모든 유형의 모델, 특히 가중치 정밀도에 민감한 모델에는 적합하지 않을 수 있습니다.
- 양자화 인식 훈련(Quantization-aware Training, QAT)
훈련하는 동안 모델은 추론 중에 적용될 양자화 작업을 인식하며, 이에 따라 파라미터를 조정합니다. 이를 통해 모델은 양자화 유도 오류를 처리하는 방법을 학습할 수 있습니다.
장점:
모델 훈련에서 양자화 오류를 고려하기 때문에 PTQ에 비해 모델 정확도를 유지합니다. 정밀도에 민감한 모델에 더 강력하며, 낮은 정밀도에서도 더 나은 추론 성능을 제공합니다.
단점:
모델을 다시 훈련해야 하기 때문에 훈련 시간이 길어집니다.
양자화 오류 검사를 포함하기 때문에 계산적으로 더 집약적입니다.
- 이진 삼진 양자화(Binary Ternary Quantization)
이러한 방법은 가중치를 2개 값(이진) 또는 3개 값(삼진)으로 양자화하여 가장 극단적인 양자화 형태를 나타냅니다. 훈련 중 또는 훈련 후 가중치는 이진 양자화의 경우 +1, -1로, 삼항 양자화의 경우 +1, 0, -1로 제한됩니다. 이는 가능한 양자화 가중치 값의 수를 크게 줄이면서도 다소 동적인 방식을 유지합니다.
장점:
모델 압축 및 추론 속도를 최대화하며 메모리 요구 사항을 최소화합니다.
빠른 추론 및 양자화 계산으로 인해 저성능 하드웨어에서도 활용 가능합니다.
단점:
높은 압축률과 낮은 정밀도는 정확도가 크게 저하되는 결과를 초래합니다.
모든 유형의 작업이나 데이터 세트에 적합하지 않으며 복잡한 작업에는 어려움을 겪습니다.
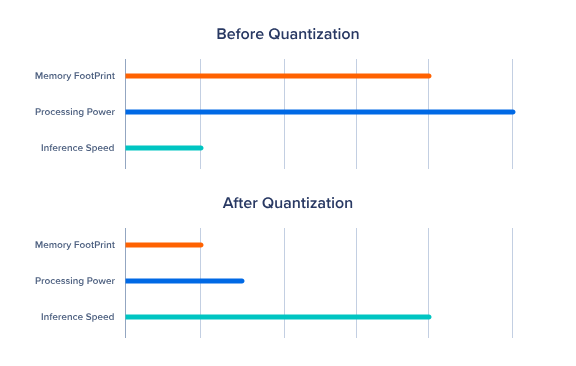
양자화의 과제
사후 양자화 모델의 목표는 메모리공간을 축소하는 것입니다.
양자화된 모델을 실행하는데 필요한 처리능력을 줄이면, 추론속도 향상 및 응답시간이 빨라짐.
하지만, 양자화는 실수 근사치를 포함하기 때문에 모델 정확도에 약간의 손실이 발생함
목표는 성능에 큰 영향을 주지 않고, 양자화 하는 것
성능과 리소스 소비 사이에 균형을 최적화 하는 경계를 찾아야함.