'가성비' 좋은 LLM을 직접 만들어보자: PEFT를 활용한 LLM 경량화 테크닉
출처: https://blog-ko.superb-ai.com/lightweighting-llm-with-peft/
😈 데이터블로그 챌린지 8일차😈 입니다.
지난시간에는 RAG, 양자화에 대해서 알아봤는데 이번에는 PEFT 방법에 대해 알아보았습니다.
LLM을 적은 코스트로 효율적으로 사용하는 방법 & sLM에 관련된 기술을 전반적으로 이해할 수 있었습니다.
요약
-
PEFT는 적은 매개변수를 이용한 미세조정 방법을 지칭하며, LoRA와 양자화가 있음
-
다양한 태스크에 모델을 신속하게 적용하고자 하는 연구자나 개발자에 적합함
-
LoRA : 가중치는 유지하고 일부만 미세조정함
내용
전반적으로 LLM 성능을 좌우하는 요소: 매개변수(parameter)의 수와 모델이 학습하는 말뭉치(corpus)의 양이 많을수록 고성능
사전학습된 언어 모델의 소스코드가 공개되어도 파인튜닝하여 커스터미이징 하는 불가능 => 모델 사이즈를 줄이면서 LLM 성능을 유지하기 위한 방법들을 고안
=> PEFT (Parameter Efficient Fine-Tuning), PEFT를 적용하기 위한 대표기법인 LoRA(Low Rank Adaption)와 양자화(quantization)를 알아보자.
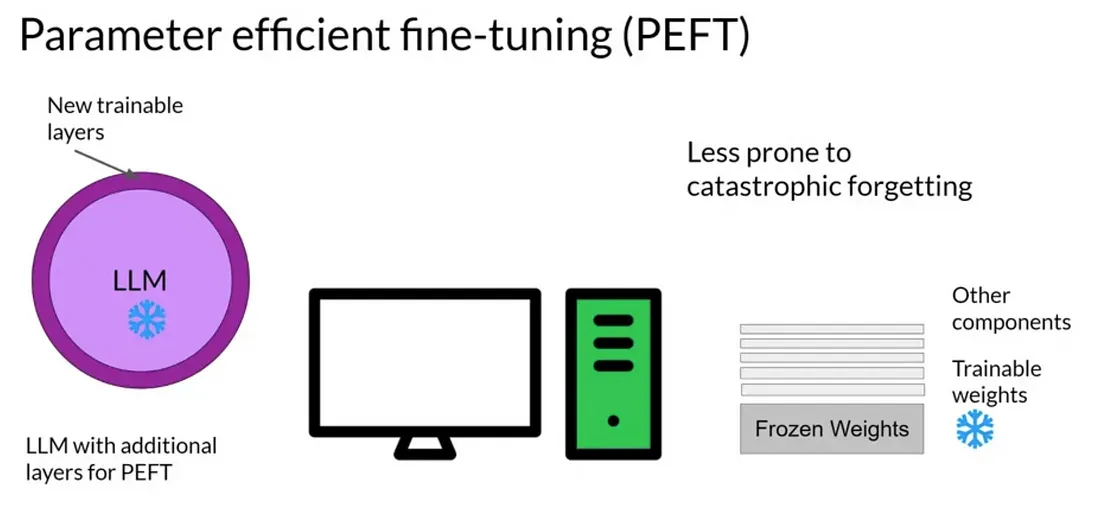
PEFT
-
적은 매개변수 학습만으로 빠른 시간에 새로운 문제를 효과적으로 해결하는 미세조정 방법을 지칭
-
적은 계산 자원과 데이터만을 사용함
-
다운로드나 업데이트의 제한이 있는 환경에서도 모델의 다양성을 유지
-
다양한 태스크에 모델을 신속히 적용하고자 하는 연구자나 개발자에게 유용함
LoRA
-
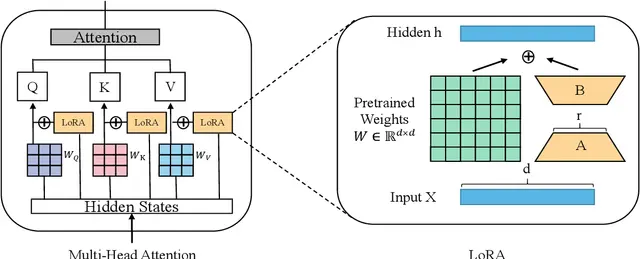
PEFT 방법론 중 하나로, 대부분의 매개변수 가중치는 원래대로 유지하되 일부만 미세조정하는 방식을 사용
-
행렬의 차원을 'r'만큼 축소 후 원래 크기로 복원하는 것과, 은닉층 'h'에 특정 값을 추가하여 출력을 조절하는 것이 핵심
양자화
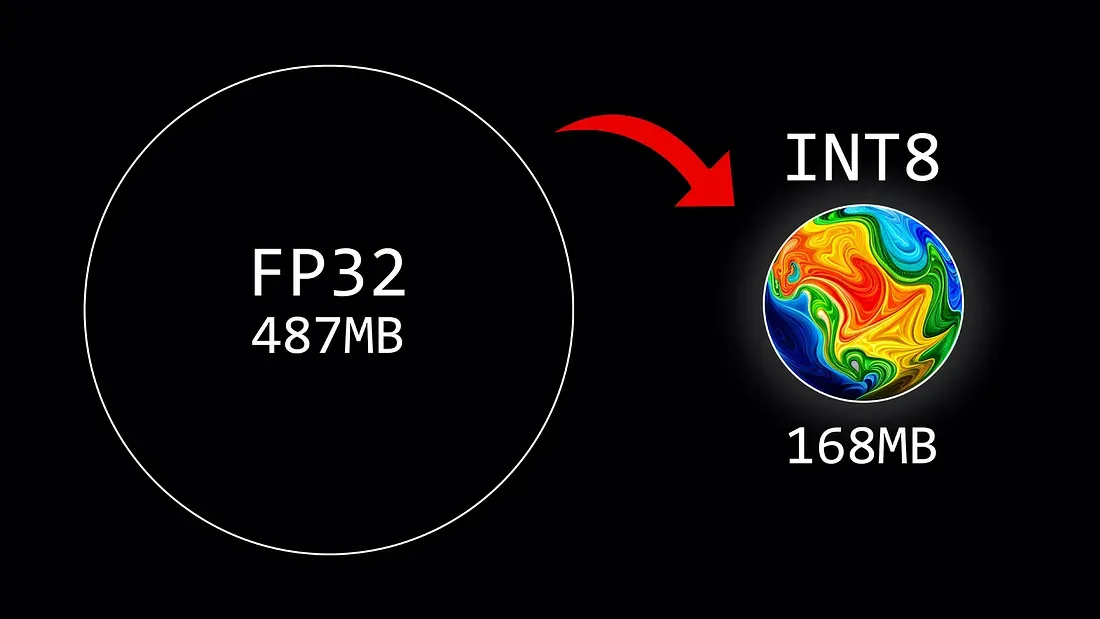
- PEFT의 한 방법론으로, 언어 모델의 매개변수를 실수형에서 정수형으로 바꾸어 비트 수를 줄이는 과정 ( ex) 32비트 => 8비트 )
PEFT 주의사항
- 성능저하 가능성: 어디까지나 가성비모델이므로 정확도는 떨어진다
- 태스크에 따른 적합성: 법률이나 의료 등 전문지식이 필요한 분야에선 부적절
- 하이퍼파라미터 조정 : 다양한 실험과 조정이 필요함
