"CoCa: Contrastive Captioners are Image-Text Foundation Models"

History of Vision and Language training
- Vision pretraining
- pretrain ConvNets or Transformers on large-scale data such as ImageNet, Instagram to solve visual recognition problem
- these models only learn modes for the vision modality-> not applicable to joint reasoning task over both image and text inputs
- Vision-Language Pretraining(VLP)
- Early work: relying on pretrained object detection modules such as Faster R-CNN to extract visual representations
- Later work: unifying vision and language transformers, and training multimodal transformer from scratch
- Image-Text Foundation models
- recent works subsume both vision and vision-language pretrianing
- adaptable for a wide range of vision and image-text benchmarks
Previous models for vision and vison-language problems: 3 training paradigms
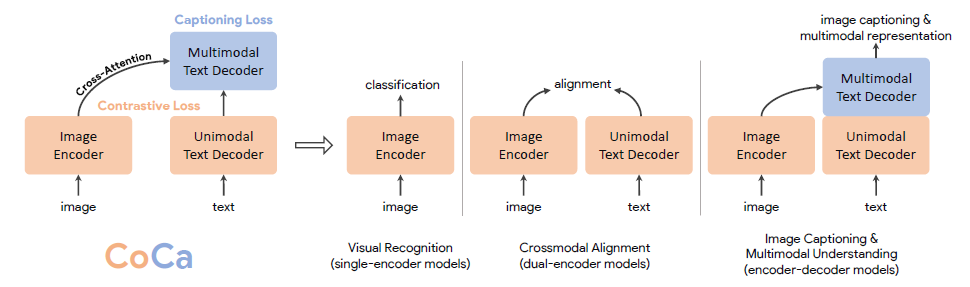
- Single-encoder models
- provides generic visual represantations that can be adapted for various downstream tasks including image and video understanding
- rely heavily on image annotains as labeled vectors
- cannot deal a free-form human natural language
- Dual-encoder models
- pretrains two parallel encoders wit a contrastive loss on web-scale noisy image-text pairs
- encode textual embeddings to the same latent space, enabling new crossmodal alignment
capabilities such as zero-shot image classification and image-text retrieval - misses joint componenets to learn fuesed image and text representations
-> not applicable for joint vision-language understanding tasks such as visual question answering - learns an aligned text encoder that enables crossmodal alignment applications such as image-text retrieval and zero-shot image classification
- Encoder-decoder models
- During training, it takes images on the encoder side and applies Language Modeling loss on the decoder outputs
- decoder outputs can be used as joint representations for mulitodal understanding tasks
- the image encoder: provides latent encoded features using Vision Transformers
- Text decoder: learns to maximize the likelihood of the paird text under the forward autoregressive factorization
CoCa
- focus on training an image-text foundation model from scratch in a single pretraining stage to unify image and text
- performs one forward and backward propagation for a batch of image-textpairs while ALBEF requires two (one on corrupted inputs and another without corruption)
- trained from scratch on the two objectives only while ALBEF is initialized from pretrained visual and textual encoders with additional training signals including momentum modules
- The decoder architecture with generative loss is preferred for natural language generation and thus directly enables image captioning and zero-shot learning
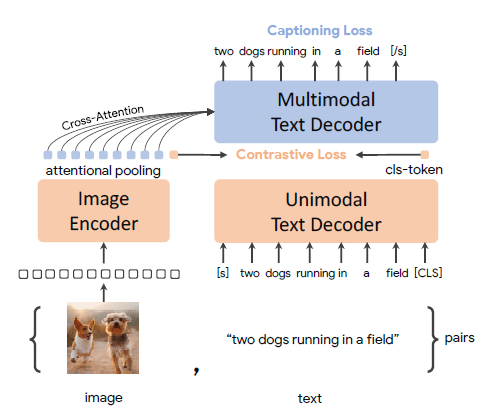
Architecture
- Image Encoder
Enocdes imgaes to latent representations by a neural network encoder - Decoupled Decoder
Simultaneously produces both unimdoal and multimodal text representations for both contrastive and generative objectives
1) Unimodal Text Decoder
- for Contrastive objective for learning global representations
- append learnable token[CLS] at the end of the input sentence
2) Multimodal Text Decoder
- for Captioning objective for fine-grained region-level features
- Benefits of
- Can compute two training losses efficiently
- Induces minimal overhead
Basic
Captioning approcah: optimies the conditional likelihood of text
Contrastive approach: uses an unconditional text representation

읏차 웃자