Prophet 라이브러리를 사용하여 예측한 유동인구 데이터의 정확도를 파악하고자 하였다.
2018년 12월 1일 ~ 2019년 10월 31일의 유동인구 데이터셋을 통해 2019년 11월 1일 ~ 2019년 11월 30일의 유동인구를 예측하였고, 예측된 데이터를 실제 2019년 11월 1일 ~ 2019년 11월 30일의 유동인구 데이터와 비교하여 정확도를 측정하였다.
다음은 2019년 11월 1일 ~ 2019년 11월 30일의 유동인구를 예측하기 위한 코드이다.
2018년 12월 1일 ~ 2019년 10월 31일의 유동인구 데이터가 저장되어있는 openapi_evaluate.csv파일을 가져와서 Prophet을 이용해 2019년 11월 1일 ~ 2019년 11월 30일의 유동인구를 예측한 다음, 이를 predictedPop_evaluate.csv 파일에 저장하였다.
import pandas as pd
import numpy as np
from fbprophet import Prophet
data = pd.read_csv("D:/openapi_evaluate.csv")
populationDF = pd.DataFrame(columns=['date'])
def prediction(gucode,guDF):
df = pd.DataFrame({'ds':data['Date'], 'y':data[gucode]})
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=30, freq='d')
pre_future = m.predict(future)
population = pre_future[['ds', 'yhat']].tail(30)
guDF[gucode] = np.nan
guDF[gucode] = population['yhat']
guDF['date'] = population['ds']
guDF = guDF.rename({'ds':'date', 'yhat':gucode}, axis = 'columns')
prediction('11000', populationDF)
prediction('11110', populationDF)
prediction('11140', populationDF)
prediction('11170', populationDF)
prediction('11200', populationDF)
prediction('11215', populationDF)
prediction('11230', populationDF)
prediction('11260', populationDF)
prediction('11290', populationDF)
prediction('11305', populationDF)
prediction('11320', populationDF)
prediction('11350', populationDF)
prediction('11380', populationDF)
prediction('11410', populationDF)
prediction('11440', populationDF)
prediction('11470', populationDF)
prediction('11500', populationDF)
prediction('11530', populationDF)
prediction('11545', populationDF)
prediction('11560', populationDF)
prediction('11590', populationDF)
prediction('11620', populationDF)
prediction('11650', populationDF)
prediction('11680', populationDF)
prediction('11710', populationDF)
prediction('11740', populationDF)
populationDF.to_csv("D:/predictedPop_evaluate.csv", index=False)저장된 데이터를 실제 유동인구 데이터와 비교하였다.
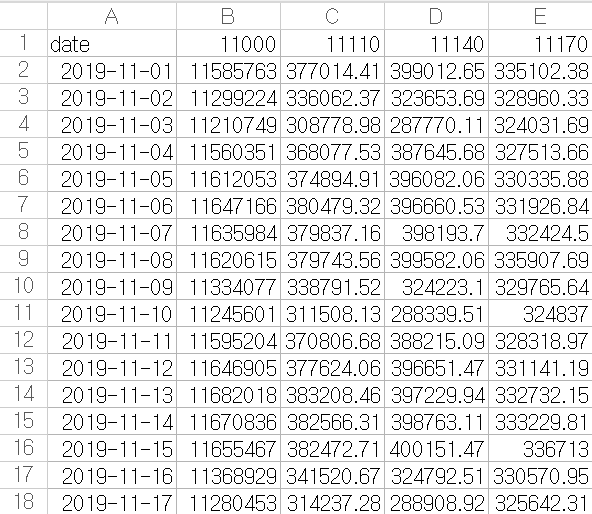
다음은 'predicted'sheet에 저장된 예측된 데이터의 일부이다.
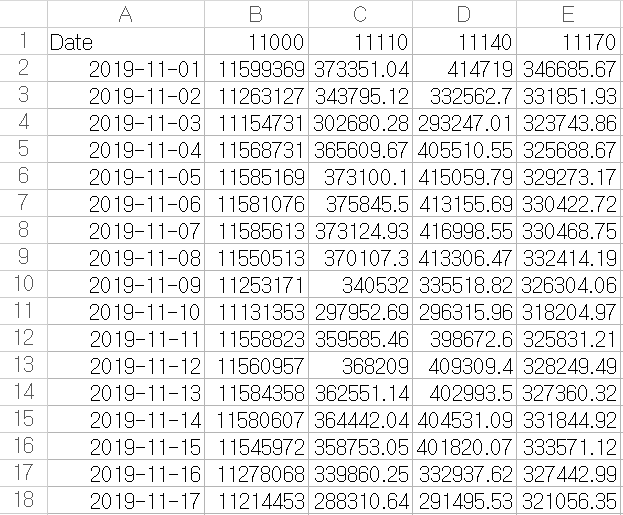
다음은 'actual'sheet에 저장된 실제 데이터의 일부이다.
이 두 sheet를 비교하여 예측데이터의 오차범위를 'accuracy'sheet에 나타내었다.
오차범위는 엑셀 내에서 함수 '=ABS(1-predicted!##/actual!##)' 를 통해 측정하였다.
오차범위를 나타낸 전체 'accuracy'sheet이다.
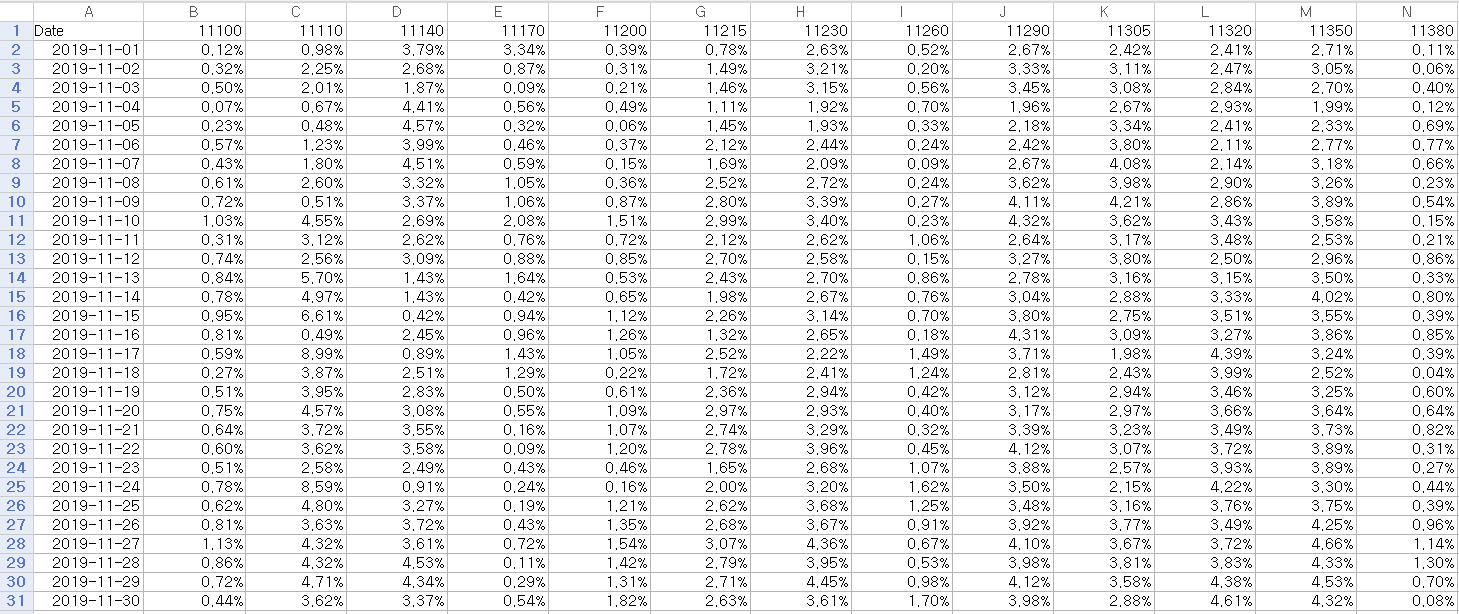
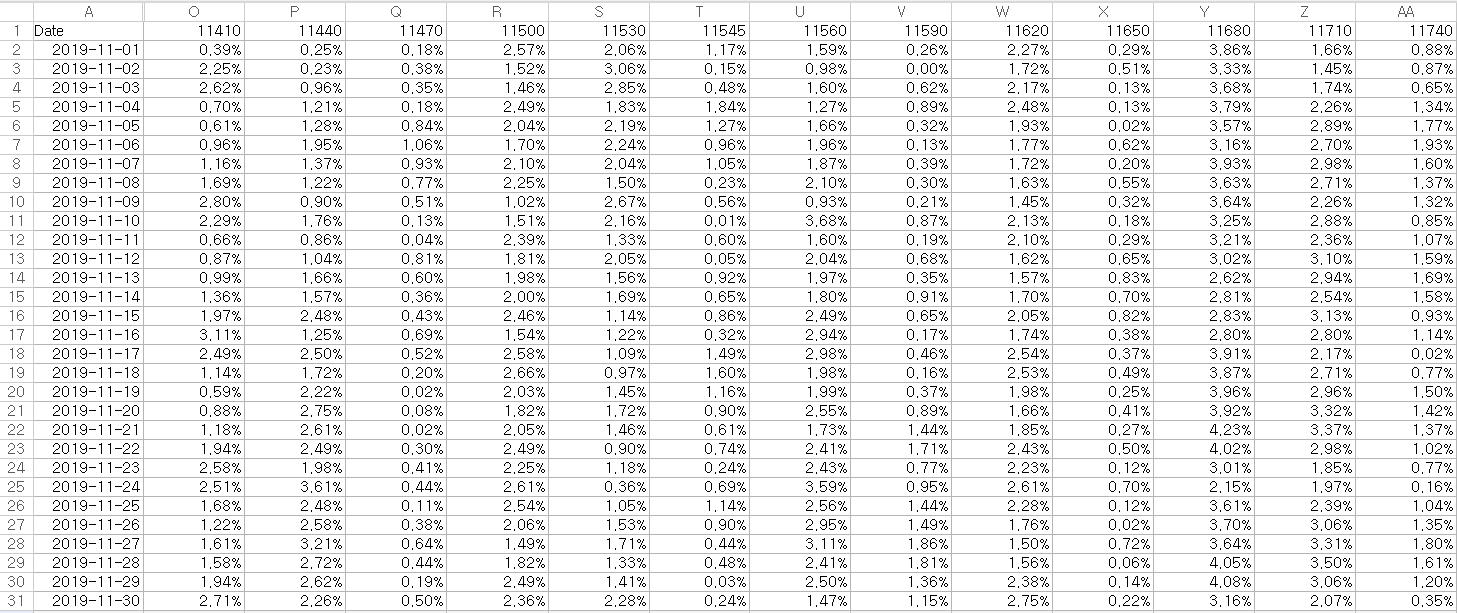
다음은 구별 평균 오차범위이다.
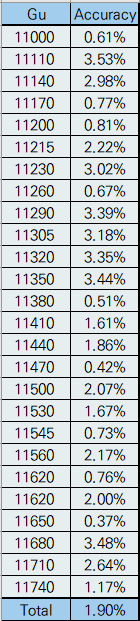
총 평균 오차범위는 1.9%인것으로 측정된다!
그래프로도 한번 살펴보자.
예측한 구들 중 11650코드에 해당하는 서초구 데이터를 python에서 plot함수를 사용하여 그래프로 나타내보았다.
사용한 코드는 다음과 같다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from fbprophet import Prophet
actual_data = pd.read_csv("D:/actualPopulation.csv")
actual = actual_data['11650']
predicted_data = pd.read_csv("D:/predictedPop_evaluate.csv")
predicted = predicted_data['11650']
plt.plot(actual, label = 'actual')
plt.plot(predicted, label = 'predicted')
plt.xlabel('Date')
plt.ylabel('Population')
plt.legend()
plt.show()위코드를 통해 출력된 그래프 결과는 다음과 같다.
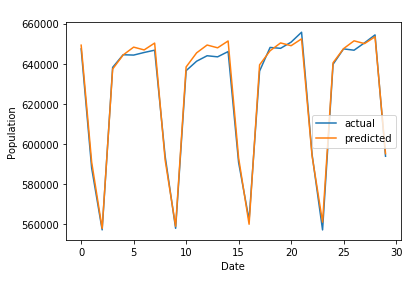
그래프의 추이가 매우 유사하고, 특히 회사가 많아 직장인들의 유동인구 비율이 높은 서초구의 특성상, 주말 유동인구가 큰 폭 감소하는 추이까지 성공적으로 예측되었다.
정확도 테스트 결과를 통해 Prophet을 통해 진행한 유동인구의 예측의 높은 정확도를 확인하였다.
