캐시 서버, 캐싱 등에 관한 용어들을 자주 접해보았고 캐시가 무엇인지 왜 쓰는지 알고있었지만
정확히 어떠한 구조로 사용을 해야하는지 언제 어떤 부분에 적용을 해야하는지? 캐시를 사용해본 경험이 없기 때문에 다양한 의문점들을 가지고 있었습니다.
Cache 란?
Cache는 데이터를 복사하여 보관을 하고 있다가 데이터 접근 시간을 대폭 줄여주는 기법입니다.
대표적인 예로는 Cpu Cache가 있습니다.
즉 캐시는, 접근의 비용이 많이 드는 데이터의 사본을 만들어 저장하고, 동일한 요청이 있을 때 원본 데이터에 접근하지 않고 사본 데이터를 제공할 수 있게 하는 중간 장치의 개념입니다.
대부분의 데이터베이스는 하드디스크에 저장을 하고 탐색을 하기때문에 메모리 탐색 속도보다 느립니다. 따라서 메모리에 저장하고 탐색을 하는 것이 훨씬 빠른 성능을 가질 수 있습니다.
이를 인메모리(In-Memory) Cache 라고 부릅니다.
Cache 동작 구조
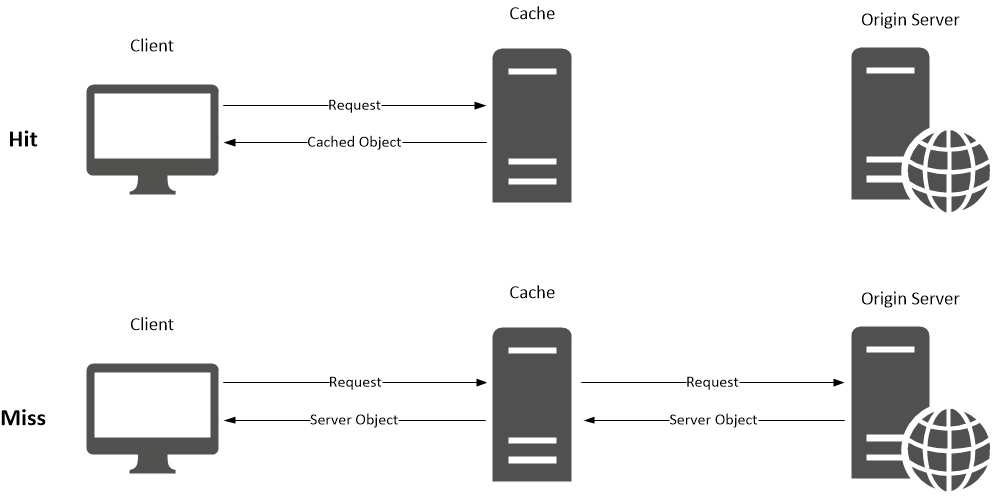
- Cache Hit : 참조하려는 데이터가 캐시에 존재할 때 Cache Hit라 합니다.
- Cache Miss : 참조하려는 데이터가 캐시에 존재 하지 않을 때 Cache Miss라 합니다.
- Cache Hit Ratio(캐시 히트율) : (cache hit 횟수)/(전체참조횟수) = (Cache Hit 횟수)/(Cache Hit 횟수 + Cache Miss 횟수)
Cache Miss가 발생하는 경우 실제 저장공간에서 데이터를 가져와야하기 때문에 비효율적이라고 할 수 있습니다. 캐싱의 활용도를 높이기 위해서는 캐시 히트율을 높이는것이 중요합니다.
캐시 히트율을 높이려면?
자주 참조되며 수정이 잘 발생하지 않는 데이터들로 구성되어야 합니다.
데이터의 수정이 잦은 경우 데이터베이스 접근 및 캐시 데이터 일관성 처리 과정이 필요합니다.
1000번을 같은 데이터를 참조한다고 하더라고 매번 데이터베이스와 캐시에 접근해야합니다.
따라서 성능을 높이고 싶으면 캐시 히트율을 어떻게 높일 수 있을까? 라고 고민을 하면 될 것 같습니다.
캐시에도 종류가 2가지가 있는 데 한번 알아보겠습니다.
Local Cache
캐시 저장소를 서버에 두는 방식
-
데이터 조회 오버헤드가 없다.
캐시 데이터를 서버 메모리상에 두는 것의 가장 큰 장점은, 무엇보다도 속도가 빠르다는 점입니다. 캐시를 외부 저장소에 저장하면 네트워크 통신을 통해 캐시 저장소에 접근하고, 데이터를 가져오는 과정 등의 I/O가 없기 때문에 Local Cache의 데이터 읽기 속도는 현저히 빠릅니다. -
서버 간 데이터 일관성이 깨질 수 있다.
Local Cache는 단일 서버 인스턴스에 캐시 데이터를 저장하기 때문에, 서버의 인스턴스가 여러 개일 경우 서버 간 캐시 데이터가 일치하지 않아 신뢰성을 떨어뜨릴 수 있습니다.
-
서버간 동기화가 어렵고, 동기화 비용이 발생한다.
캐시 일관성을 유지하기 위해 동기화를 한다고 하더라도, 추가적인 비용이 발생합니다. 더군다나 서버의 개수가 늘어날수록, 자신을 제외한 모든 인스턴스와 동기화 작업을 해야 하기 때문에 비용의 크기는 서버의 개수의 제곱에 비례하여 증가합니다.
Global Cache
외부에 캐시 저장소를 두는 방식
-
네트워크 I/O 비용 발생
Global Cache는 외부 캐시 저장소에 접근하여 데이터를 가져오기 때문에, 이 과정에서 네트워크 I/O가 비용이 발생합니다. 하지만 서버 인스턴스가 추가될 때에도 동일한 비용만을 요구하기 때문에, 서버가 고도화될수록 더 높은 효율을 발휘합니다. -
데이터 일관성을 유지할 수 있다.
Global Cache는 모든 서버의 인스턴스가 동일한 캐시 저장소에 접근하기 때문에, 데이터의 일관성을 보장할 수 있습니다. 데이터의 일관성이 깨지기 쉬운 분산 서버 환경에 적합한 구조입니다.
(MSA의 적합한 구조!!)
Local Cache VS Global Cache
그러면 둘중 대체 뭐가 좋은 방식일까? 라고 한다면 프로젝트의 성격마다 그리고 어떤 도메인에 적용할지에 따라 다른것 같습니다.
만약에 다른 서비스에 전혀 영향을 받지 않는 데이터이고 캐싱이 필요하다면 Local Cache를 사용함으로써 많은 성능을 얻을 수 있고
전체적인 서비스가 공유되어야 되는 데이터 이지만 캐싱이 필요하다고 하면 Global Cache를 사용하면 좋을 것같습니다.
정확히 어디에 쓰면 되는건데?
변경이 자주 일어나지 않고 조회가 빈번한 데이터에 쓰면 베스트지만 정확히 이것이 어떠한 타입의 데이터인지 판별하기는 쉽지않습니다.
자주 쓰는건 아무래도 사용자의 세션 관리입니다. 사용자의 세션을 유지하고, 불러오고, 여러 활동들을 추적하는 게 매우 효과적으로 사용할 수 있습니다.
그 밖에도 강력하게 사용할 수 있는게 바로 API 캐싱입니다. 라우트로 들어온 요청에 대해 요청 값을 캐싱해면 동일 요청에 대해 캐싱된 데이터를 리턴하는 방식입니다.
특정 유저, 특정 Body 등등 원하는 데이터를 key 값으로 설정하여 캐싱 처리를 할수도있습니다.
이와 관련되서는 추후 스프링으로 직접 실습을 하여서 글을 올리겠습니다.
그외 본인 프로젝트에서 이러한 데이터는 캐싱 처리가 필요하다! 라고 느끼면 캐싱 처리를 해주면 될 것 같습니다.
쓰면 안되는 데이터를 예시를 들어보자면 유투브에 있는 조회수 데이터는 매우 자주 변경이 일어나기때문에 캐싱 처리를 하면 안되는 데이터 중 하나입니다.
Redis
레디스는 시스템 메모리를 사용하는 키-값 데이터 스토어입니다.
여기서 중요한 것은 레디스는 관계형 데이터베이스가 아닙니다!!!
따라서 몇가지 로우 레벨의 데이터 타입만 지원을 하게 됩니다.
특징
- 메모리 안에 저장 가능!
- List, Set, Hash, Map, String 등 다양한 데이터 타입 저장 가능
- 레디스는 한 번 생성한 키를 선택적으로 삭제하기 어렵습니다. 레디스의 키는 삭제가 아닌 보관되며 심지어 서버를 종료했다가 다시 켜도 상태가 유지됩니다.
- 다양한 언어 지원
하지만 키를 삭제하는 방법이 존재하는데
1. 일괄 삭제 : FLUSHDB 명령어를 통해 모든 키를 파괴
2. 일정 시간 이후 삭제 : 각각의 키를 저장할 때 셋에 저장해 특정 시간이나 조건에 따라 삭제하는 방법
3. 기간 만료 후 삭제 : 키-값을 SET 커맨드로 저장해 EXPIRE 커맨드로 기간 만료 시간을 정하는 방법 (TTL 이라고 생각하면 되용)
그리고 여러 Cloud 플랫폼에서 Redis 전용 스토리지 들을 서비스로 제공하고 있으니
사용하기 되게 편합니다.
아마 영속성과 데이터 타입 지원하는 것 때문에 레디스를 자주 쓸것 같습니다.
느낀 점
캐싱 방법중에 API 캐싱 방법을 알고나서 혁신적인 방법을 본거마냥 너무 신났습니다.
저런식으로도 활용할 수 있구나 라고 생각이 들었고 당장 프로젝트에 적용하고 싶은 마음이 많아져서 조만간 관련된 글을 올리도록 하겠습니다.
CQRS 패턴을 사용하게 되면 캐싱을 적용하기에 정말 딱좋은 환경이라고 생각되가지고
나중에 캐싱을 많이 적용하게 되는 프로젝트를 하게되면 CQRS 패턴을 고려하게 될 것 같습니다.
이제 실제로 캐시를 써볼 수 있어서 너무 행복하네요 ㅋㅋㅋ
