DeepLearning Workstation Benchmark (CPU, GPU benchmark)
DL Workstation을 구축하였으니 예상하는 수준의 성능으로 동작을 하는지 다양한 벤치마크를 통해 확인을 해보려고 한다. 꼭 직접 HW를 직접 구축하지 않았더라도 클라우드 환경에서 인스턴스를 사용할때 역시도 원하는 목적에 적합한 성능을 낼 수 있는지 또는 한계 성능은 어디까지 인지 판단하는데도 벤치마크는 도움이 된다.
🏁 벤치마크 알아보기
벤치 마크의 의의
이 분야에서 벤치마크라 함은 일반적으로 컴퓨팅파워를 사용하는 전자 기기의 연산능력을 시험하고 이를 수치화하고 비교 분석하는 일련의 과정을 일컷는다. 이때 기기라 함은 서버, 데스크톱, 스마트폰을 비롯한 가상의 컴퓨팅 리소스 자원(클라우드와 같은) 등 을 예로 들 수 있다.
쉽게 말해 벤치마크는 HW적, SW적으로 적절히 설치하고 적절한 셋업을 했지는를 객관적인 데이터를 기반으로 분석하는 일이다.
고려 사항
이번 벤치마크로 다음과 같은 사항을 검토하게 된다.
- 연산 능력
- 대조군(동일 사양의 타 유저 표본집단) 대비 전반적인 시스템성능은 적당한가?
- 목표하는 작업 성능 효율이 나오는가?
- 지속성
- 성능을 지속적으로 유지 가능한가?
- 기타
- 시스템의 배기 상태는 적당한가? ( Cooling system, 부품의 배치 등)
- 적절한 전력을 사용하고 있는가? ( Idle vs Full load )
- 드라이버 설치는 정상적으로 되었는가?
벤치 마크 종류
벤치 마크를 하는 방법은 다양하다. 대중들이 많이 이용하는 벤치마크 솔루션을 활용하는 방식과 목표 하는 작업을 테스트 할 수 있는 환경을 구축하는 방법 등이 있다.
3DMark (범용, 연산능력, Stress 테스트 등)

https://benchmarks.ul.com/3dmark
그래픽카드, CPU등의 성능을 종합 점수를 만들어주며 이 점수가 높을수록 성능이 좋음 을 뜻한다. 일반적으로 데스크탑이나 워크스테이션에서 가장 많이 사랑 받는 벤치마크 솔루션으로 주로 게임을 즐기는데 필요한 해상도와 프레임을 테스트할때 많이 사용되고 있으며 DLSS 테스트, PCI-E 테스트 및 DISK 테스트 등도 포함되어 있어 범용적으로 사용하기 적합하다.
PCMark 10 (범용, 오피스 작업 성능)

https://benchmarks.ul.com/pcmark10
3DMark와 동일한 회사에서 내놓은 벤치마크 솔루션으로 오피스 작업 성능의 전반을 확인 할 수 있다.
AIDA64 (센싱, Stress 테스트, 일부 벤치마크 기능)

https://www.aida64.com/
시스템 전반의 상태 정보(주로 부품 정보와 센서정보)를 확인할 수 있으며, 시스템 부하테스트와 간단한 벤치마크 기능을 보유 하고 있는 솔루션이다. 다양한 벤치마크를 진행하는 동안 이 프로그램을 통해 각 부품의 온도와 clcok, usage 등을 모니터링하는 용도로 주로 사용하며 GPU성능에 대한 벤치마크 기능도 있으니 다용도로 사용할만 하다.
Check Point
- CPU, GPU, 메인보드 등 온도 모니터링을 통해 쓰로틀링 가능성 검토
- 최적화된 PCIe 슬롯 사용 유무 (x16 - x16, x8 - x8 등)
- 전력 사용량 모니터링 (파워서플라이 적정성 및 경제성 검토)
- 시스템 Stress Test
- GPU benchmark, RAM benchmark
GeekBench

https://www.geekbench.com/
CPU성능과 GPU성능 모두 확인 가능하며 특히 일부 ML관련 성능(inference로 추정) 측정을 해주기때문에 참고 하면 좋다.
Cinebench R23

https://www.maxon.net/ko/cinebench
Cinebench는 컴퓨터 하드웨어 성능(특히 CPU 성능)을 평가할 수 있는 실제적인 크로스-플랫폼 벤치마크 테스트 소프트웨어이다.
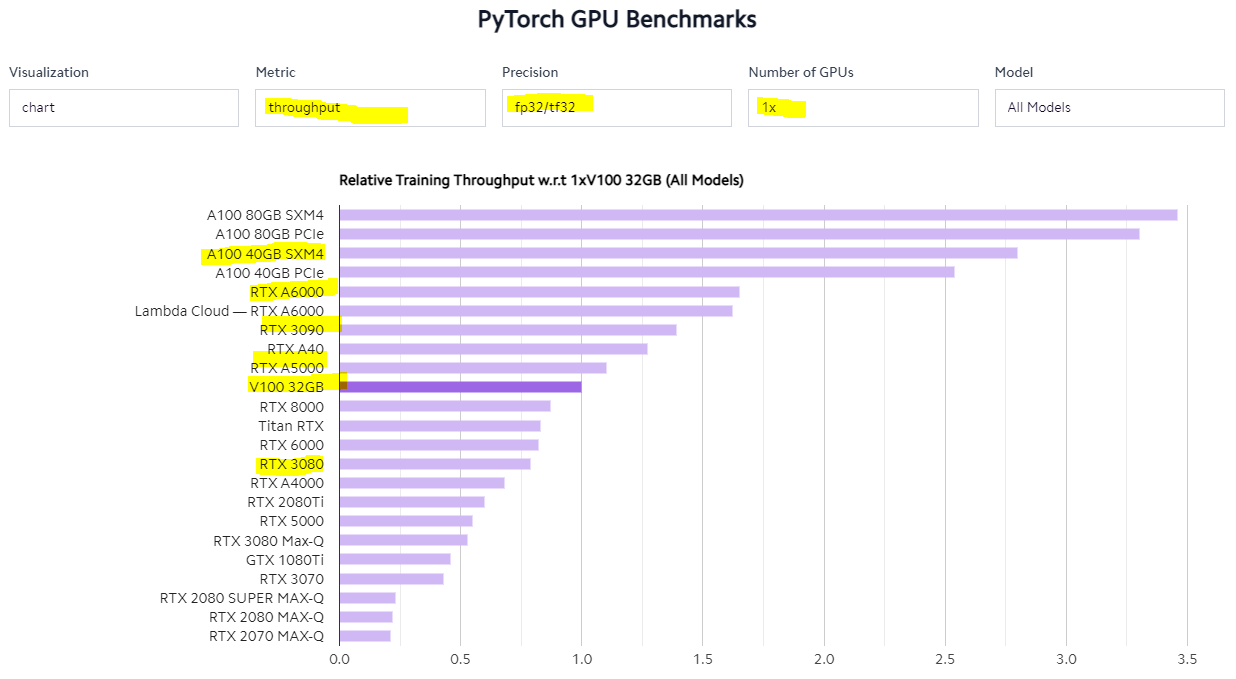
lambdalabs.com
https://lambdalabs.com/gpu-benchmarks
이곳은 벤치마크 솔루션을 제공해주는 것은 아니지만 각 GPU별로 GPU training speed를 비교 분석하기 좋은 곳이다.
ai-benchmark
https://pypi.org/project/ai-benchmark
https://ai-benchmark.com/ranking_deeplearning.html
tensorflow 기반으로 training과 inference를 테스트 하고 AI-Score 종합 점수를 매겨주는 툴이다. 19개의 모델에 대해 인퍼런스 및 트레이닝 테스트를 자동으로 진행해주고 마지막에 최종 스코어를 보여준다. 다만 벤치마크 랭킹 페이지는 2019년 말쯤까지만 운영한 것으로 추정되는데 v100, 2080ti 등이 가장 높은 스코어로 등록된 것으로 보아 A100, RTX 30XX, RTX A6000 등 최신의 GPU 점수가 없는 것은 다소 아쉽다. 또한 해당 벤치마크는 2개 이상의 GPU가 구성되어 있어도 하나의 GPU만 테스트하도록 설정되어 있어서 멀티 GPU를 테스트 하기에는 무리가 있다.
- installation
# if you have no TF
pip install tensorflow-gpu
pip install ai-benchmark- start benchmark
from ai_benchmark import AIBenchmark
benchmark = AIBenchmark()
results = benchmark.run()Manual Benchmark
벤치마크 솔루션이 원하는 작업 성능을 완벽히 체크해주면 좋겠지만 범용 솔루션은 한계가 있다. 결국 디테일한 성능 확인과 섬세한 사용성 테스트를 원한다면 본인이 직접 하고자 하는 작업의 성격에 맞게 프로그램을 동작 시키거나 코드를 작성하여 테스트 해야한다.
🏁 DL Workstation 벤치마크
기준 사양
AMD Ryzen 5950X + x570보드
NVIDIA RTX A6000 x 2EA
RAM 128GB
무엇을 봐야 하는가
CPU, GPU의 general 성능과 특히 Deeplearning 성능에 포커스 하여 벤치마크 하는 것이 DL Workstation 벤치마크의 핵심이라 할 수 있다.
결과
3DMark
| Bench Title | Bench Category | Score | 비고 |
|---|---|---|---|
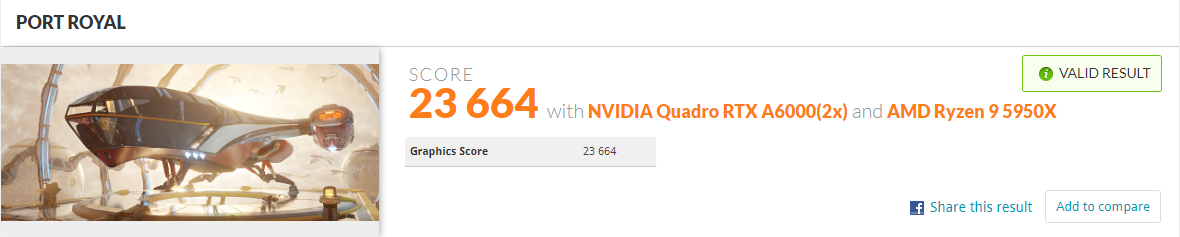
| PORT ROYAL | GPU | 23,664 | - |
| TIME SPY | GPU+CPU | 27,394 | - |
| TIME SPY EXTREME | GPU+CPU | 15,823 | - |
| Fire Strike | GPU+Physics | 30,148 | - |
| Fire Strike Ultra | GPU+Physics | 11,467 | - |
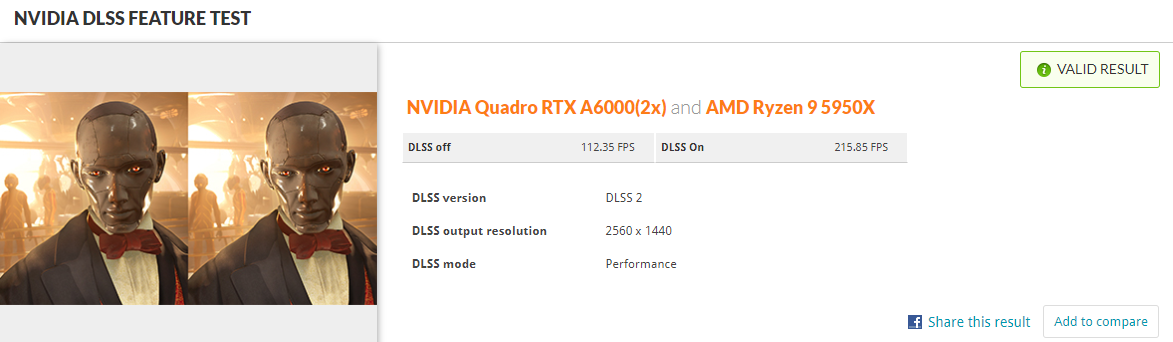
| DLSS Feature test | Nvidia DLSS | Off: 112.35FPS / On: 215.85FPS | res 2560 x 1440 |
| Raytracing Feature test | Raytracing | 104.90FPS | - |
| PCI EXPRESS | PCIe bandwidth | 13.46GB/s | PCIe4.0 8배속 |
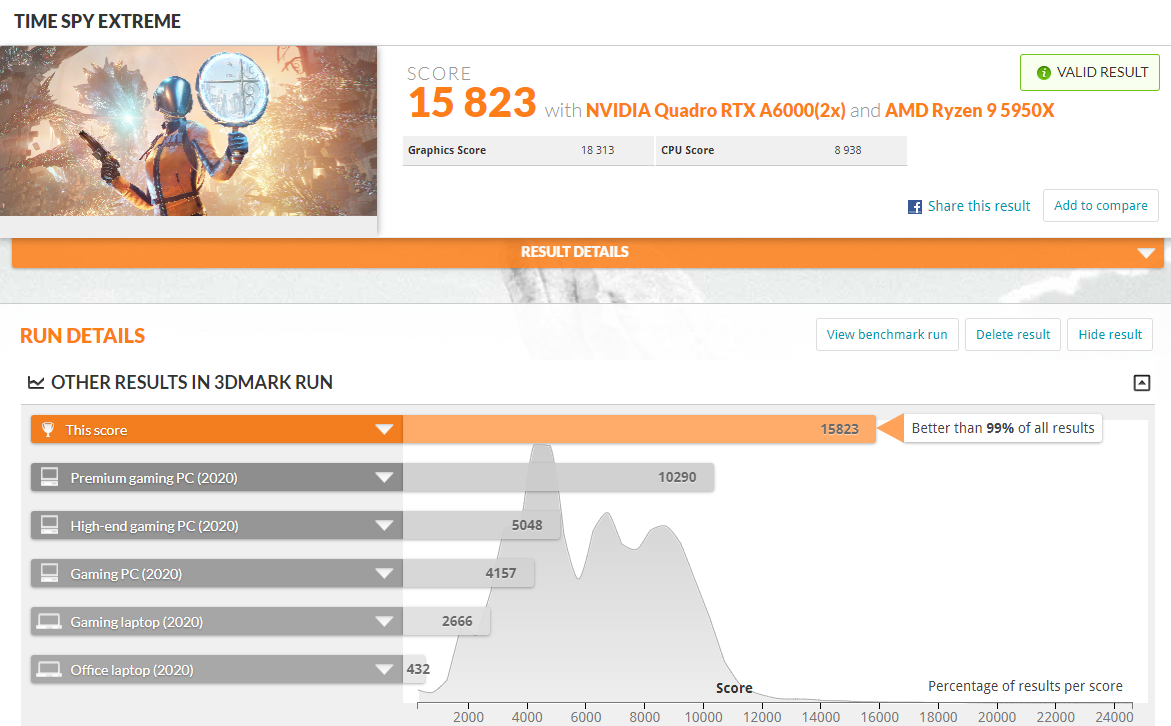

이전 글에서 설명했듯이 현재 A6000 2개를 설치하여 사용하고 있으면 CPU(zen3) 및 메인보드에서 2개의 GPU를 사용 하는 경우 x8 * x8 lane으로 동작한다. PCIe 4.0의 8배속 lane은 최대 대역폭으로 15.7GB/s을 가질 수 있으며 벤치 결과 13.46GB/s로 준수한 결과라고 볼 수 있다.
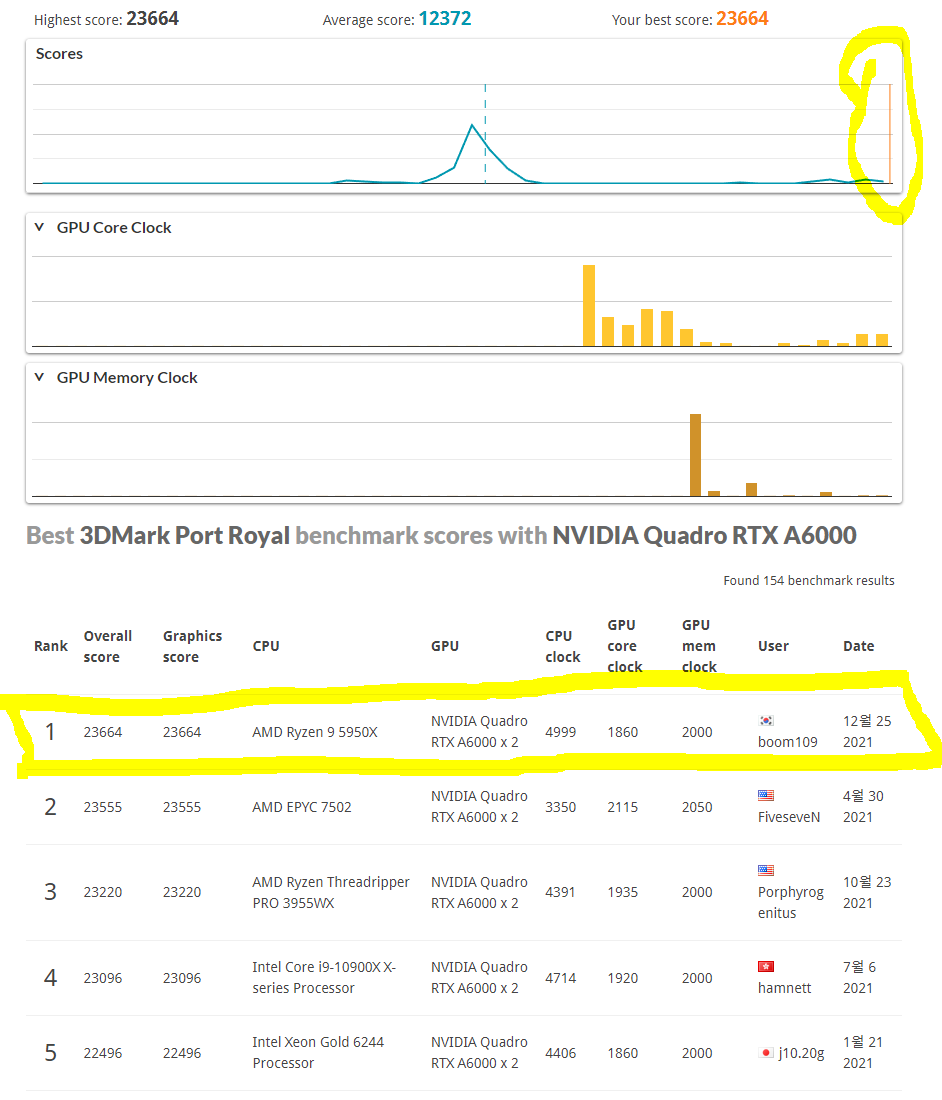
Port Royal 벤치마크 결과를 보면 유저 분포 대비 성능이 매우 좋은 상태로 부품 구성 및 세팅에 문제가 없고 타 유저들에 비해 좋은 성능을 내고 있음을 확인 할 수 있다. 특히 동일 GPU 구성 유저군에서 벤치마크 score 1위를 차지했다. 30XX 카드 대비 A6000은 벤치마크 수가 많지 않아서 가능했던 것 같다.
PCMark
| Bench Title | Bench Category | Score | 비고 |
|---|---|---|---|
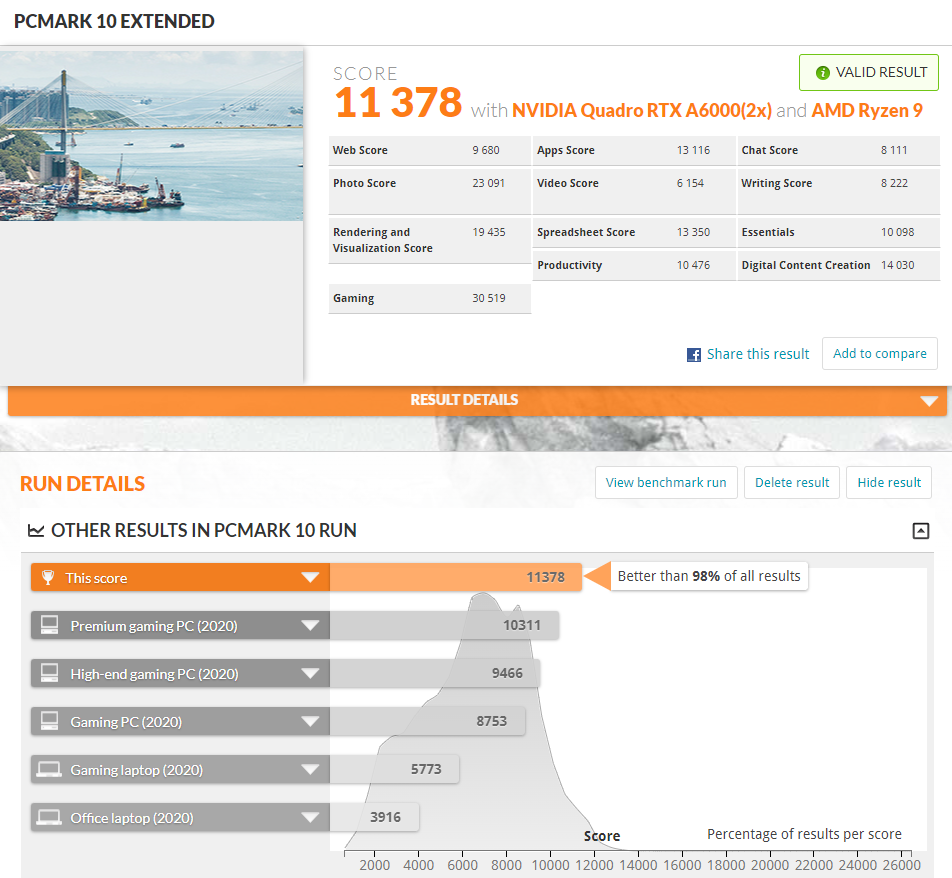
| PCMark 10 Exteneded | System overall | 11,378 | - |
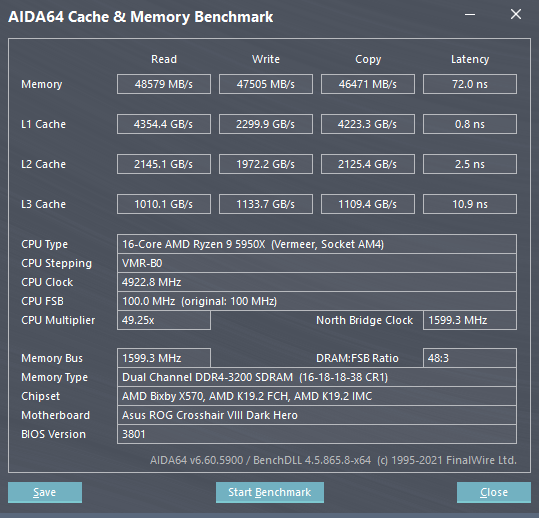
AIDA64
Cache & Memory, GPGPU benchmark와 Stress test를 진행한다.
AIDA64는 다른 Benchmark을 시행할때도 CPU, GPU 등의 온도와 clock, memory 상태, fan speed 등을 확인하는데 유용한 센서정보를 제공할 수 있어 모니터링 용도로도 사용할 수 있을 정도로 쓰임이 다양하다.
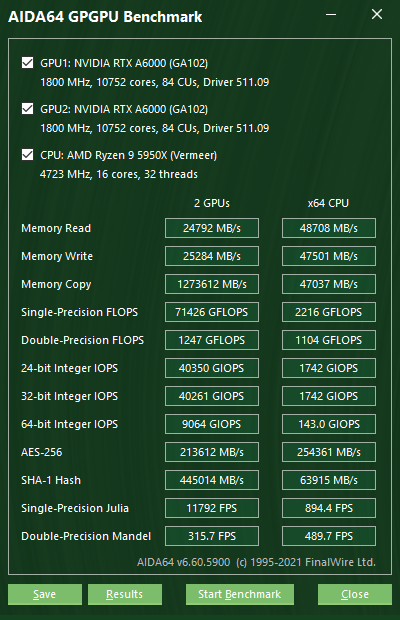
RTX A6000 datasheet를 보면 Single-precision performance가 38.7 TFLOPS 인데 벤치마크상 multi-GPU 에서 69.7 TFLOPS (71426 GFLOPS)으로 스펙에서 크게 벗어나지 않는 성능을 보여주고 있다.
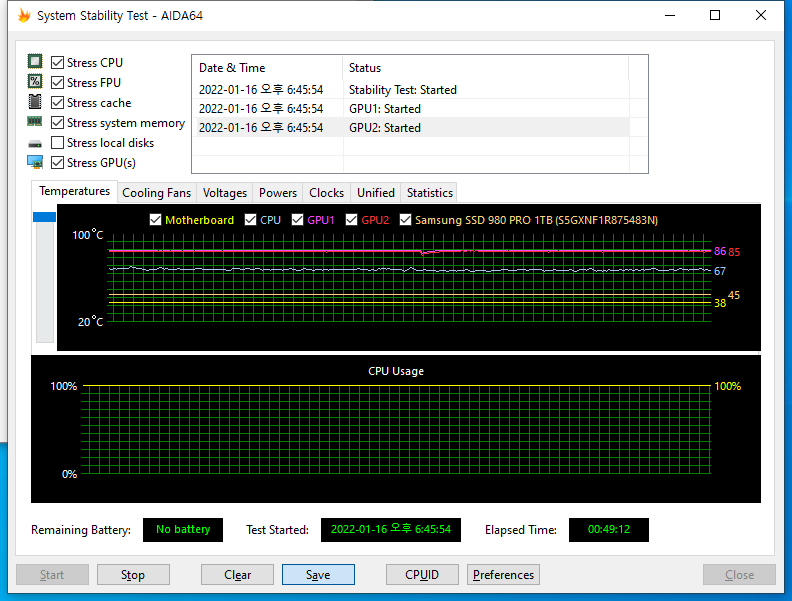
약 50분간 진행한 Stress Test 결과 CPU/GPU 모두 Clock, Power, temperature가 안정적인 수치로 유지되며 동작하는 것을 확인 하였다. 특히 RTX A6000의 소비 전력은 300W 전후로 아주 균일하게 유지되며 엔터프라이즈 및 전문가용 제품임을 확연히 보여주는 결과라 보인다.
GeekBench
CPU / GPU 전반의 성능을 파악하고 특히 ML 관련 성능을 집중하여 확인한다.
-
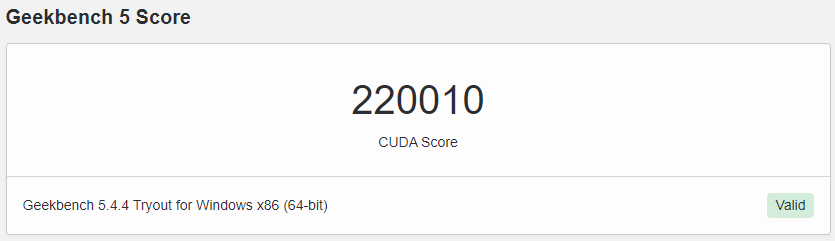
GPU 결과 (CUDA)
https://browser.geekbench.com/v5/compute/4091072
Multi-GPU 로 인식하지 못하여 한개의 GPU만 테스트하여 다소 아쉬운 점이 있다.
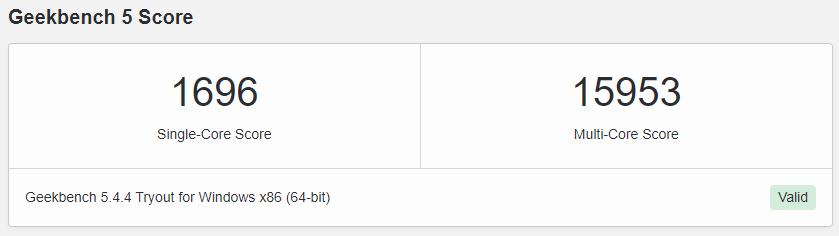
Cinebench
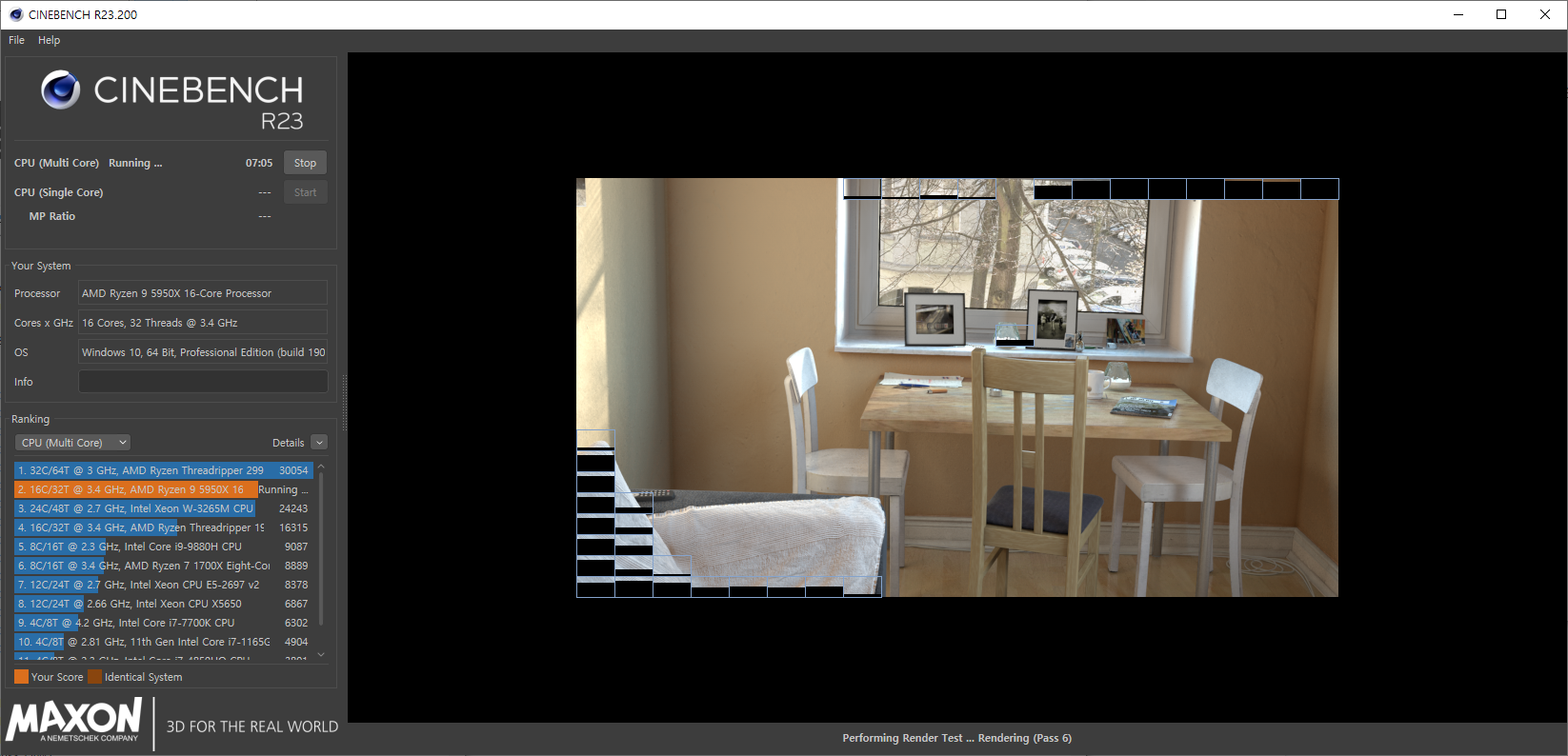
| Bench Title | Bench Category | Score | 비고 |
|---|---|---|---|
| Cinebench R23 | CPU Score(Multi Core) | 23976 pts | - |

ai-benchmark
* TF Version: 2.7.0
* Platform: Linux-5.11.0-46-generic-x86_64-with-glibc2.17
* CPU: N/A
* CPU RAM: 126 GB
* GPU/0: NVIDIA RTX A6000
* GPU RAM: 45.6 GB
* GPU/1: NVIDIA RTX A6000
* GPU RAM: 45.6 GB
* CUDA Version: N/A
* CUDA Build: N/A
The benchmark is running...
The tests might take up to 20 minutes
Please don't interrupt the script
1/19. MobileNet-V2
1.1 - inference | batch=50, size=224x224: 28.4 ± 0.6 ms
1.2 - training | batch=50, size=224x224: 154 ± 1 ms
2/19. Inception-V3
2.1 - inference | batch=20, size=346x346: 27.5 ± 1.3 ms
2.2 - training | batch=20, size=346x346: 91.3 ± 0.5 ms
3/19. Inception-V4
3.1 - inference | batch=10, size=346x346: 26.7 ± 0.8 ms
3.2 - training | batch=10, size=346x346: 93.0 ± 0.7 ms
4/19. Inception-ResNet-V2
4.1 - inference | batch=10, size=346x346: 37.8 ± 0.7 ms
4.2 - training | batch=8, size=346x346: 108 ± 1 ms
5/19. ResNet-V2-50
5.1 - inference | batch=10, size=346x346: 18.4 ± 0.5 ms
5.2 - training | batch=10, size=346x346: 60.4 ± 0.5 ms
6/19. ResNet-V2-152
6.1 - inference | batch=10, size=256x256: 26.0 ± 0.8 ms
6.2 - training | batch=10, size=256x256: 92.6 ± 0.6 ms
7/19. VGG-16
7.1 - inference | batch=20, size=224x224: 29.5 ± 0.5 ms
7.2 - training | batch=2, size=224x224: 54.2 ± 0.5 ms
8/19. SRCNN 9-5-5
8.1 - inference | batch=10, size=512x512: 40.0 ± 1.3 ms
8.2 - inference | batch=1, size=1536x1536: 33.4 ± 0.5 ms
8.3 - training | batch=10, size=512x512: 103 ± 1 ms
9/19. VGG-19 Super-Res
9.1 - inference | batch=10, size=256x256: 33.7 ± 0.5 ms
9.2 - inference | batch=1, size=1024x1024: 56.7 ± 0.9 ms
9.3 - training | batch=10, size=224x224: 116 ± 1 ms
10/19. ResNet-SRGAN
10.1 - inference | batch=10, size=512x512: 57.1 ± 1.2 ms
10.2 - inference | batch=1, size=1536x1536: 50.5 ± 1.4 ms
10.3 - training | batch=5, size=512x512: 80.2 ± 0.7 ms
11/19. ResNet-DPED
11.1 - inference | batch=10, size=256x256: 65.9 ± 0.6 ms
11.2 - inference | batch=1, size=1024x1024: 107.9 ± 0.3 ms
11.3 - training | batch=15, size=128x128: 100.2 ± 0.4 ms
12/19. U-Net
12.1 - inference | batch=4, size=512x512: 101.3 ± 0.5 ms
12.2 - inference | batch=1, size=1024x1024: 100.3 ± 0.5 ms
12.3 - training | batch=4, size=256x256: 117.8 ± 0.6 ms
13/19. Nvidia-SPADE
13.1 - inference | batch=5, size=128x128: 33.1 ± 0.3 ms
13.2 - training | batch=1, size=128x128: 65.8 ± 0.4 ms
14/19. ICNet
14.1 - inference | batch=5, size=1024x1536: 85.4 ± 0.8 ms
14.2 - training | batch=10, size=1024x1536: 255 ± 22 ms
15/19. PSPNet
15.1 - inference | batch=5, size=720x720: 169 ± 1 ms
15.2 - training | batch=1, size=512x512: 70.9 ± 0.8 ms
16/19. DeepLab
16.1 - inference | batch=2, size=512x512: 53.7 ± 0.5 ms
16.2 - training | batch=1, size=384x384: 65.0 ± 1.6 ms
17/19. Pixel-RNN
17.1 - inference | batch=50, size=64x64: 268 ± 17 ms
17.2 - training | batch=10, size=64x64: 1394 ± 19 ms
18/19. LSTM-Sentiment
18.1 - inference | batch=100, size=1024x300: 299 ± 7 ms
18.2 - training | batch=10, size=1024x300: 591 ± 22 ms
19/19. GNMT-Translation
19.1 - inference | batch=1, size=1x20: 90.2 ± 1.8 ms
Device Inference Score: 24914
Device Training Score: 24565
Device AI Score: 49479GPU를 한개밖에 사용하지 않아 2개의 GPU성능은 아니나 DL모델에 대한 inference와 training 모두 평가 해볼 수 있어 추후 모델 개발시 참고할만 하다.
다소 예전 VGA 기록(2019년 말에 출시된 VGA만 반영된 것으로 예상됨)만 남아 있지만 아래의 URL을 참고 하면 현재 사용중인 VGA 성능과 비교 분석이 가능하다.
https://ai-benchmark.com/ranking_deeplearning.html
manual benchmark
추후 지속적인 벤치마크를 통해 기록 예정.
