6.5 멀티코어와 기타 공유 메모리 멀티프로세서
하드웨어 멀티스레딩이 추가 비용을 크게 들이지 않고 프로세서의 효율을 높이기는 했으나 칩에 집적되는 프로세서의 수가 많아지며 어떻게 호율적으로 프로그래밍을 해서 Moore의 법칙대로 성능 개선을 이룰 수 있을까가 문제였다.한 가지 답은 모든 프로세서들이 공유하는 단일 실제 주소 공간을 제공하는 것이었다. 이렇게 되면 프로그램들은 자신들이 사용할 데이터가 어디에 있는지 신경 쓸 필요 없이 병렬적으로 수행될 수 있다. 이 방식에서는 언제나 또 어느 프로세서나 프로그램의 모든 변수에 접근 가능. 다른 방식은 프로세서마다 별도의 주소 공간을 갖고 공유할 것이 있으면 명시적으로 표시하는 방식, 이에 대해서는 6.7절에서 살펴볼 것. 실제 주소공간이 공유될 때는 하드웨어가 캐시 일관성을 보장하여 모든 프로세서가 공유 메모리에 대해 일치된 관점을 가지도록 하는 것이 일반적.
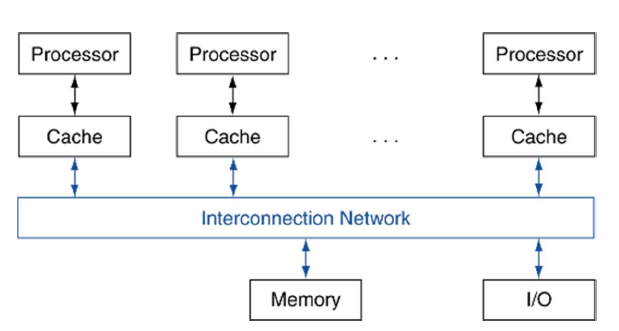
앞서 말한 바와 같이 공유 메모리 멀티프로세서(SMP: Shared memory multiprocessor)에서는 모든 프로세서가 단일 실제 주소공간을 가지며 멀티코어 칩은 거의 다 이런 방식으로 구현된다. 어쩌면 공유 주소 멀티프로세서라고 부르는 것이 더 정확한 표현일지도 모르겠다. 프로세서들은 어느 메모리 주소든지 적재와 저장 명령어를 사용하여 접근할 수 있으며 프로세서 간의 통신은 메모리에 있는 공유 변수를 통해 이뤄진다. 아래 그림은 SMP의 전형적인 구조를 보여준다. 프로세서들이 실제 주소 공간을 공유하더라도 작업들은 각각 별개의 가상주소공간에서 독립적으로 수행될 수 있음에 유의.
공유메모리 멀티프로세서: 단일 주소공간을 갖는 병렬 프로세서. 프로세서 간의 통신은 적재와 저장명령어를 통해 은연중에 이뤄진다.
단일 주소 공간 멀티프로세서에는 두 가지 스타일이 있다.
- 한 가지는 어느 프로세서가 어느 워드에 접근하든지 간에 동일한 시간이 걸리는 스타일. 이와 같은 것을 균일 메모리 접근(UMA : uniform memory access) 멀티프로세서라고 한다.
- 두 번째 스타일의 비균일 메모리 접근(NUMA nonuniform memory access) 어떤 프로세서가 어떤 워드에 접근하는지에 따라 메모리 접근 시간이 달라짐. 이것은 메인 메모리가 여러 조각으로 분할되어서 각각이 다른 마이크로프로세서 또는 동일 칩 내의 다른 메모리 제어기에 붙어 있기 때문.
- NUMA 멀티프로세서가 UMA 멀티프로세서보다 프로그래밍 하기 어렵지만 가까운 메모리에 빨리 접근할 수 있고 규모를 크게 만들 수 있다는 장점
동시에 동작하는 프로세서들끼리 데이터를 공유하는 것이 일반적이므로 공유데이터에 대한 작업을 할 때는 조정이 필요. 조정이 이뤄지지 않으면 어느 프로세서가 공유 데이터에 대한 작업을 끝내기 전에 다른 프로세서가 같은 데이터에 대해 작업을 시작할 수 있을 것이다. 이 조정 작업을 동기화(synchronization)이라 하며 단일 주소 공간에서 공유가 허용되는 경우에는 동기화를 위한 별도의 매커니즘이 필요하다.


- 한가지 방법은 공유 변수에 대한 잠금변수(lock)를 이용하는 것이다. 한번에 한 프로세서만 잠금 변수를 얻을 수 있고, 공유 변수를 사용하고자 하는 다른 프로세서들은 그 프로세서가 잠금을 풀 때까지 기다려야만 한다.
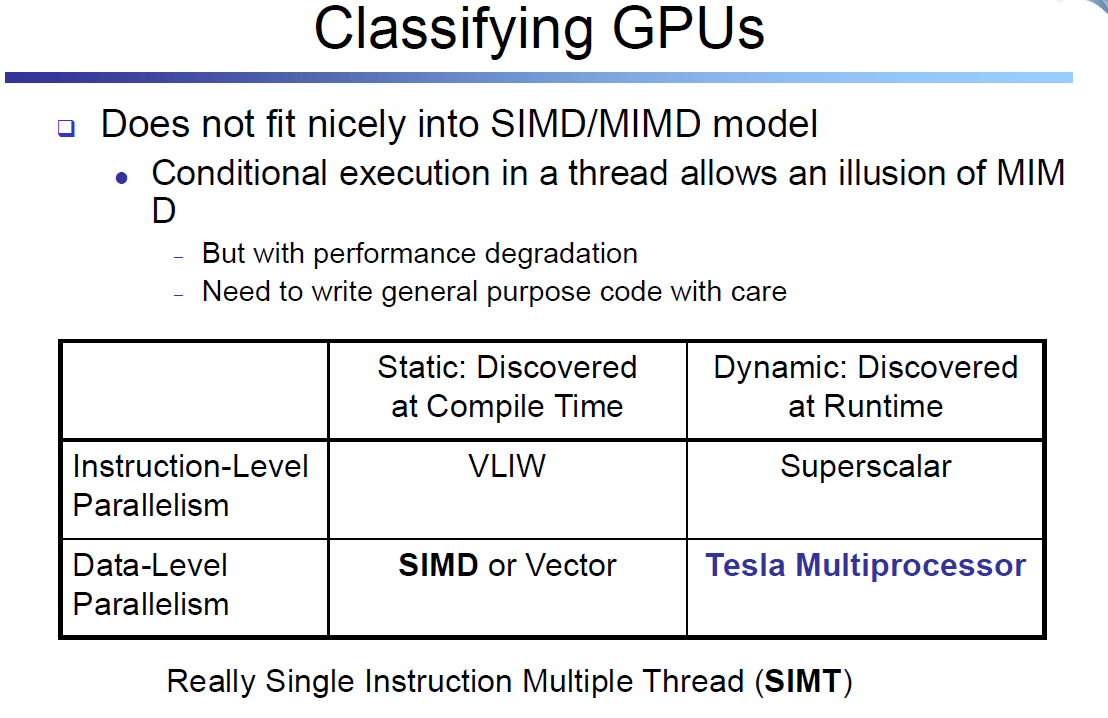
6.6 그래픽 처리 유닛의 기초
기존 구조에는 SIMD 명령어를 추가하는 것이 타당하다고 생각하게 된 초창기 이유는 PC와 워크스테이션이 많은 마이크로 프로세서들이 그래픽 디스플레이와 연결되어 있어 그래픽을 처리하는 시간의 비중이 점점 늘어난다는 것. Moore의 법칙대로 마이크로 프로세서에 사용 가능한 트랜지스터 수가 늘어나며 그래픽 처리 성능을 개선하는 것이 타당하게 되었다.
그래픽과 게임 커뮤니티는 마이크로프로세서를 개발하는 커뮤니티와 다른 목표. 그래픽 프로세서가 점점 더 커지면서 CPU와 구별하기 위해서 그래픽처리 유닛(GPU)라는 이름을 사용. CPU와 GPU의 주요 차이점은 다음과 같다
- GPU는 CPU를 돕는 가속기. 따라서 CPU가 수행하는 모든 작업을 다 수행할 필요가 없다. 모든 자원을 그래픽만을 위해 사용할 수도. GPU가 어떤 작업을 수행할 수 없거나 느리게 수행한다고 해도 그 시스템이 CPU와 GPU를 모두 가지고 있으면 문제 X. CPU가 그 일을 하면 됨.
- GPU의 문제의 크기는 보통 수백MB에서 GB수준이며 수백 GB나 TB까지는 가지X
- GPU의 경우 메모리의 큰 지연시간 극복을 위해 CPU처럼 다단계 캐시를 사용하지 않음. 대신 GPU는 메모리 지연을 감추기 위해 하드웨어 멀티스레딩을 사용. 즉 메모리 접근을 요청한 후 데이터가 도달할 때까지 GPU는 그 요청과 무관한 스레드를 수백, 수천 개 수행
- GPU의 메민 메모리는ㄴ 지연시간보다는 처리율에 초점. CPU를 위한 DRAM칩도다 폭이 더 넓고 처리량이 큰 DRAM 칩을 GPU 전용으로 두기도 한다.
- 큰 메모리 대역폭을 얻기 위해 많은 수의 스레드를 활용하기에 GPU는 많은 스레드와 많은 병렬 프로세서(MIMD)를 수용할 수 있다. 따라서 전형적인 CPU와 비교 시 GPU는 훨씬 고도로 멀티스레딩되어 있고 프로세서도 더 많다
NVIDIA GPU 메모리 구조

위 그림은 NVIDIA GPU의 메모리 구조를 보여준다. 멀티스레드 SIMD 프로세서 내에 존재하는 온칩 메모리를 지역 메모리(local memory)라고 부른다. 멀티스레드 SIMD 프로세서 내에 있는 SIMD 레인은 지역 메모리를 서로 공유하지만 다른 멀티스레드 SIMD 프로세서와는 공유하지 않는다. 전체 GPU와 모든 스레드 블록이 공유하는 DRAM은 칩 외부에 존재하며 GPU메모리라고 부른다.
응용 프로그램의 모든 워킹셋(working set)을 담을 수 있는 큰 캐시 대신에 GPU는 전통적으로 작은 크기의 스트리밍 캐시를 사용하고, DRAM의 긴 지연시간을 감추기 위해서 SIMD 명령어 스레드들의 멀티스레딩을 대대적으로 사용. 그 이유는 워킹셋의 크기가 수백 MB나 되어서 멀티코어 마이크로프로세서 마지막 단계 캐시에 들어가지 않기 때문. DRAM 메모리 지연시간을 감추기 위해서 하드웨어 멀티스레딩을 사용하므로, 시스템 프로세서에서 캐시에 사용되는 칩 영역을 컴퓨팅 자원과 많은 레지스터 구현에 사용하였다. SIMD 명령어의 많은 스레드의 상태를 저장하기 위해서 레지스터가 많이 필요하기 때문이다.
6.7 클러스터, 창고 규모의 컴퓨터와 기타 메세지 전달 멀티프로세서
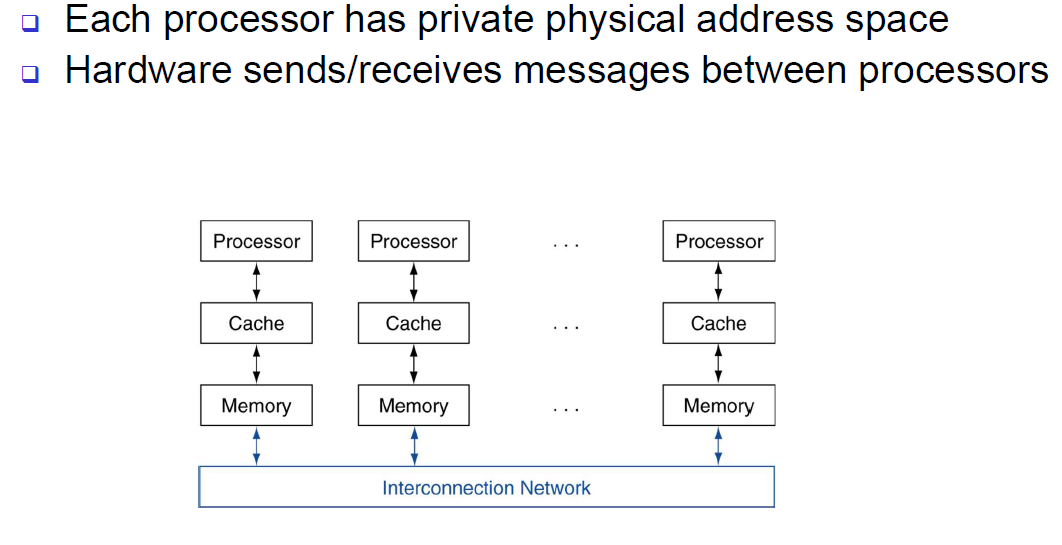
주소 공간을 공유하는 대신 프로세서들이 자신만의 실제 주소공간을 갖도록 하는 방법이 있다. 그림 6.13은 다수 전용 주소공간(private address space)을 사용하는 멀티프로세서의 전형적인 구성을 보여준다. 이 방식의 멀티프로세서는 메세지 전달 컴퓨터라고 부르는데 명시적인 메세지 전달(message passing) 방식으로 프로세서 간 통신이 이루어진다. 시스템이 메세지 전송 루틴(sending message routine) 과 메세지 수신루틴 을 가지고 있는 경우, 송신 프로세서는 메세지 전송 시점을 알고 수신 프로세서는 메세지 도착 시점을 알기 때문에 프로세서 간의 조정이 메세지 전달 자체로 이뤄진다. 송신 측이 메세지 도착 여부를 확인할 필요가 있을 때는 수신 프로세서가 송신 프로세서에게 확인 메세지를 보낼 수 있다.
- 메세지 전달: 명시적으로 정보를 보내고 받음으로써 프로세서 간의 통신을 수행하는 방식
- 메세지 전송 루틴 : 전용 메모리 컴퓨터에서 한 프로세서가 다른 프로세서로 메시지를 전송하는 루틴
- 메세지 수신 루틴: 전용메모리 컴퓨터에서 한 프로세서가 다른 프로세서로부터 메세지를 수신하는 루틴
 고성능의 메세지 전달 연결망을 기반으로 고성능 컴퓨터를 구성하려는 여러 시도가 있었다. 이들은 근거리 네트워크(LAN)를 사용하여 구성한 클러스터보다 통신 성능의 절대치 측면에서 우수하다. 실제로 오늘날 많은 수퍼컴푸터가 특화된 연결망을 사용한다. 문제는 이더넷과 같은 LAN보다 훨씬 비싸다는 것이다. 실제로 그렇게 많은 돈을 들여서 통신 성능을 좋게 하는 것을 정당화할 만한 응용은 고성능 컴퓨팅 분야 외엔 거의 없다.
고성능의 메세지 전달 연결망을 기반으로 고성능 컴퓨터를 구성하려는 여러 시도가 있었다. 이들은 근거리 네트워크(LAN)를 사용하여 구성한 클러스터보다 통신 성능의 절대치 측면에서 우수하다. 실제로 오늘날 많은 수퍼컴푸터가 특화된 연결망을 사용한다. 문제는 이더넷과 같은 LAN보다 훨씬 비싸다는 것이다. 실제로 그렇게 많은 돈을 들여서 통신 성능을 좋게 하는 것을 정당화할 만한 응용은 고성능 컴퓨팅 분야 외엔 거의 없다.
어떤 병행 응용은 공유 메모리 구조이든 메세지 전달 구조이든 상관없이 병렬 하드우에에서 잘 수행된다. 특히 태스크 수준 병렬성이나 웹 검색이나 파일 서버와 같이 통신이 거의 없는 응용은 공유 주소를 사용해야만 잘 수행되는 것은 아님. 그래서 메세지 전달 병렬 컴퓨터 중에서 클러스터(Cluster, 메세지 전달 멀티 프로세서를 구성하기 위하여 표준화된 네트워크 스위치와 입출력장치를 통하여 연결된 컴퓨터들의 집합)가 오늘날 가장 널리 쓰이고 있다. 클러스터의 각 노든느 독자적인 메모리와 운영체제를 가지고 있다. 반면에 마이크로 프로세서 내의 코어들은 칩 내의 고성능 연결망으로 연결되어 있으며, 멀티칩 공유 메모리 시스템은 메모리 연결망으로 연결되어 있다. 메모리 연결망은 대역폭이 더 크고 지연신간은 작기에 공유 메모리 멀티프로세서의 통신 성능이 훨씬 좋다.
병렬 프로그래밍 관점에서는 사용자 메모리를 따로따로 갖고 있다는 점이 약점이기도 하지만 시스템 신용도 측면에서는 오히려 강점이 된다. 클러스터는 근거리 네트워크로 연결된 독립적인 컴퓨터로 구성되므로 시스템 전체를 중단 시키지 않고 컴퓨터 하나를 대체하는 것이 공유 메모리 멀티 프로세서의 경우에 비해 훨씬 쉽다. 본래 공유주소를 사용하는 경우, 프로세서 하나를 분리하고 대체하는 것은 운영체제가 엄청난 일을 하고 서버의 물리적 설계가 기가 막히게 잘되어 있지 않는 한 아주 어려운 일이다. 클러스터의 경우 서버가 하나 고장나면 부드럽게 성능을 떨어뜨릴 수 있으므로 신용도가 좋아진다.
클러스터는 완전한 컴퓨터와 독립적이면서도 확장 가능한 네트워크로 구성되기에 클러스터 위에서 돌아가는 응용들을 중단시키지 않고 시스템을 확장하는 것도 쉽다. 낮은 비용, 높은 가용성, 빠르면서도 점진적으로 확장할 수 있는 특성으로 인해 대규모 공유 메모리 멀티프로세서와 비교 시 낮은 통신 성능을 보임에도 웹 서비스를 제공하는 사업자에게는 매력적. 아마존, 페북, 구글, 마소 등이 수 만 개의 프로세서로 구성된 클러스터들을 가지고 있는 데이터 센터 여러 개를 운영.
6.8 멀티프로세서 네트워크 위상의 기초
멀티 코어 칩들은 코어들을 연결하기 위해 칩 내에 네크워크가 필요하고 클러스터는 서버를 연결하기 위해 근거리 네트워크가 필요하다. 이 절에서는 여러 연결망 네트워크 위상의 장단점을 살펴본다.
네트워크 가격은 스위치의 개수, 스위치 하나당 필요한 링크 수, 링크의 폭(비트 수) 등에 의해 결정된다. 네트워크는 보통 그래프로 표현한다. 그래프 간선은 통신 네트워크의 링크를 나타낸다. 프로세서-메모리 노드는 검은 사각형, 스위치는 파란 원으로 표시한다. 이하의 링크는 모두 양방향성이며 모든 네트워크는 스위치들로 구성되었으며, 스위치에는 프로세서 - 메모리 노드로 가는 링크와 다른 스위치로 가는 링크가 있다. 첫 번째 네트워크는 모든 노드를 순서대로 연결하는 네트워크이다.
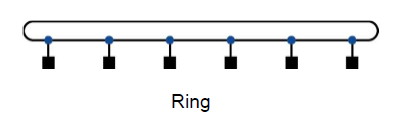
위와 같은 연결 구조를 링(ring)이라 한다. 직접 연결되지 않는 노드들도 있으므로 어떤 메세지들은 중간 노드들을 거쳐서 최종 목적지에 도달하게 된다. 버스와는 달리 링은 여러개의 전송을 동시에 수행할 수도 있다.
버스 : 연결된 모든 장치들에게 정보를 브로드캐스팅할 수 있는 한 무리의 공유 신호선
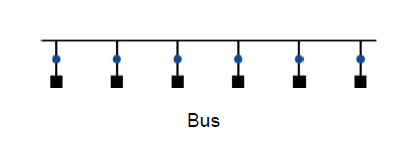
위상의 종류가 다양하기 때문에 구별하기 위한 성능 척도가 필요한데 보통 많이 쓰이는 것은 두가지. 첫째는 총 네트워크 대역폭(network bandwidth)으로 각 링크 대역폭에 링크 수를 곱한 값 이다. 이 척도는 최선의 경우에 얻을 수 있는 성능에 해당. 앞에서 본 링 네트워크의 경우, 프로세서가 p개라면 한 링크의 대역폭에 해당된다. 앞에서 본 링 네트워크의 경우, 프로세서가 p개라면 한 링크의 대역폭에 p를 곱한 값이 된다. 반면에 버스의 경우는 버스 대역폭이 전체 대역폭이 된다.
이 최선의 경우 대역폭과 균형을 맞추기 위해서 최악의 경우 성능에 근사한 또 다른 척도를 사용하는데 그것은 양분 대역폭(bisection bandwidth)이다. 양분 대역폭은 전체 네트워크를 같은 크기로 양분해 그 경계선을 통과하는 링크 대역폭을 모두 합한 값이다. 링크의 양분 대역폭은 링크 대역폭이 두 배, 버스의 양분 대역폭은 폭은 버스의 대역폭과 동일.
상용 병렬 컴퓨터에서 사용된 네트워크 위상 : 파란색 원은 스위치를 나타내고 검은 사각형은 프로세서-메모리 노드를 나타낸다. 각 스위치는 여러 개의 링크를 가지고 있으나 보통 그중 하나만이 프로세서에 연결된다. 불린(boolean) n-cube 위상은 2^n개의 노드를 n차원으로 연결하므로 스위치당 n개의 링크가 필요하고 따라서 이웃 노드가 n개 있다
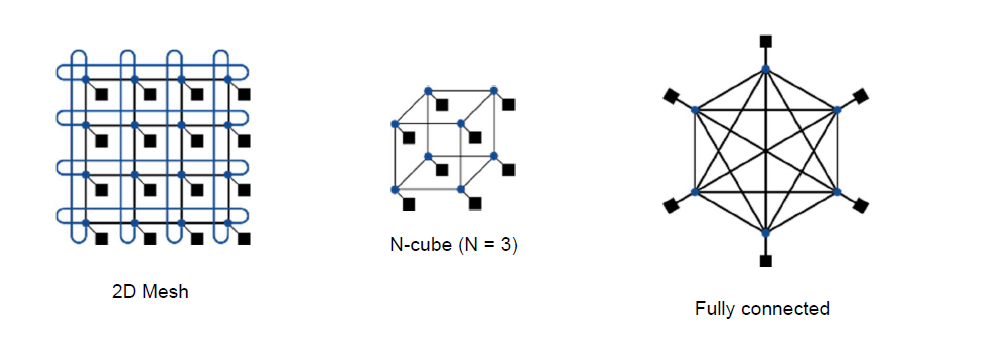
링과 반대쪽 극단에 완전 연결 네트워크(fully connected network)가 있다. 완전 연결 네트워크는 모든 프로세서를 양방향 링크로 직접 연결하므로, 전체 네트워크 대역폭은 p*(p-1)/2 이고 양분 대역폭은 (p/2)^2 이다.
