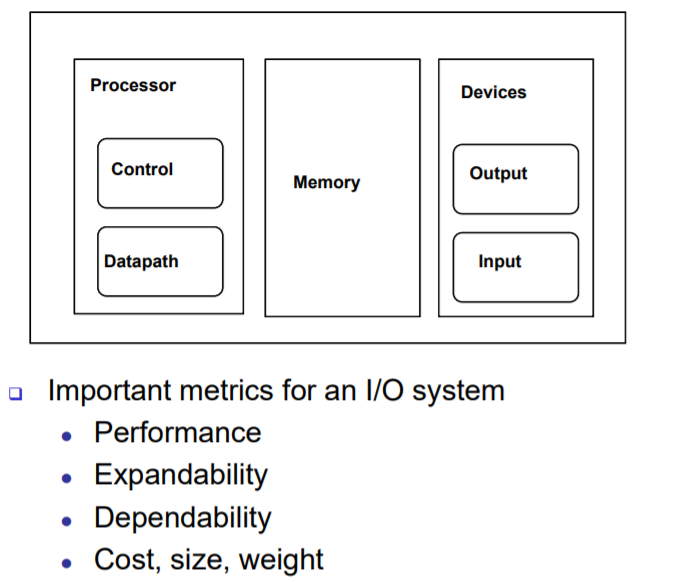
- Performance : CPU 미만.. 느린 장치이기 때문에, 전체적인 컴퓨터 시스템을 구성할 때 성능을 어떻게 연결할 것인가?
- expandability : 어떻게 다양한 장치를 연결시킬 것인가?
- Dependability : 결국 그 다양한 장치는 cpu랑 data를 주고 받는 장치, 어떻게 데이터를 주고 받을 것인가.
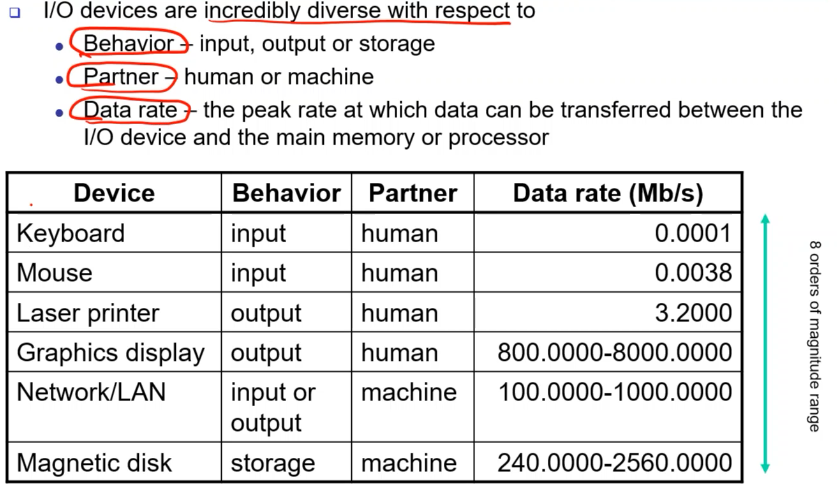
- Behavior, partner, data rate(속도)에 따라 I/O 장치를 다양한 기준으로 분류해볼 수 있다. 이러한 것은 I/O 서버 시스템으로 묶어서 전달을 해줘야 한다.

I/O 장치도, thoughput과 latency로 성능을 측정한다.
- throughput : 통신을 할 때 device장치에 연결선을 통해서 데이터를 주고 받을 때 단위 시간당 주고 받는 데이터의 양.
- latency: 단일 operation이 완료되는데 걸리는 시간
일반적으로 bandwidth가 올라갈 수록, latency가 낮아질 수록 성능이 좋다고 이야기한다.
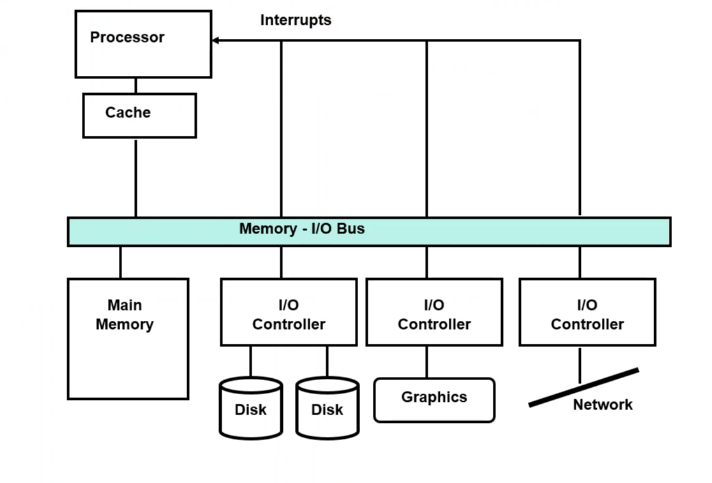
우선, 모두 bus connection을 통해서 processor에 종속적으로 연결되어 있다. 명령을 변환해서 전달해줄 뿐.(main meomory제외)

마이크로 컨트롤러를 아주 성능이 낮고 특정 기능을 위해서 구성되어 있는 임베디드부터 복잡한 서버까지 모두 컴퓨터의 시스템이다. 컴퓨터 시스템은 cpu 메모리 뿐만 아니라 i/o까지 고려해서 설계한다. 어떻게 성능의 필요요건을 맞추면서 설계할 것인가?
cpu는 clock, pipeline구조, excution로직, 캐시 등에 따라서 성능을 cycle당 몇 개의 명령어를 처리할 수 있는가? 초당 몇 개의 명령어를 처리할 수 있는가였다. I/O 시스템은 BUS에 물려서 bandwidth와 latency을 개선할 수 있을까?에 대해서 무엇을 따지는지에 대한 설명이 위에 나와있다.
- 1) I/O와 연결이 가장 취약한 부분을(병목현상) 찾기

하나의 명령어를 처리할 때는 200 + 100 => 30만개의가 필요. 초당 10,000개의 명령어가 필요하다. 디스트 I/O를 수행할 수 있는 I/O는 초당 1만개.
- MEMORY BAND WIDTH는 총 메모리 / WORKLOAD
- 디스크 I/O 컨트롤러에는 디스크를 여러가지 붙일 수 있다. 320MB/S 이고 디스크를 7개까지 붙일 수 있다. 붙여지는 디스크 드라이버의 성능은 75MB/S이고 ROATIONAL DISK인데 LATECY는 6MS 정도일 때. 컨트롤러와 메모리 프로세서를 가지고 I/O RATE를 어떻게 최대화할 수 있을까?
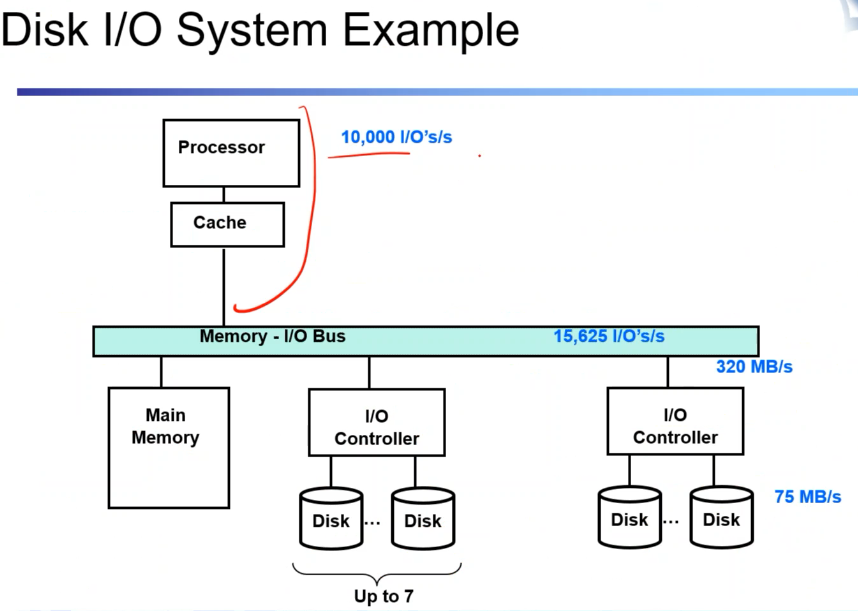
위를 도식화한 것.
- 프로세서가 bottle neck이라고 가정할 때 (왜냐면 더 느리니까) 디스크 드라이버는 몇 개까지 붙일 수 있을까? 하나의 reqest 처리는ㄴ 64kb/75mb + 항상 걸리는 latency = 6.9ms. 하나가 저 값이니 1초에 146개를 처리할 수 있고 1000 / 146 = 69개까지 붙일 수 있고 하나의 컨트롤러에 7개 붙일 수 있다고 했으니 10개를 붙이면 된다.
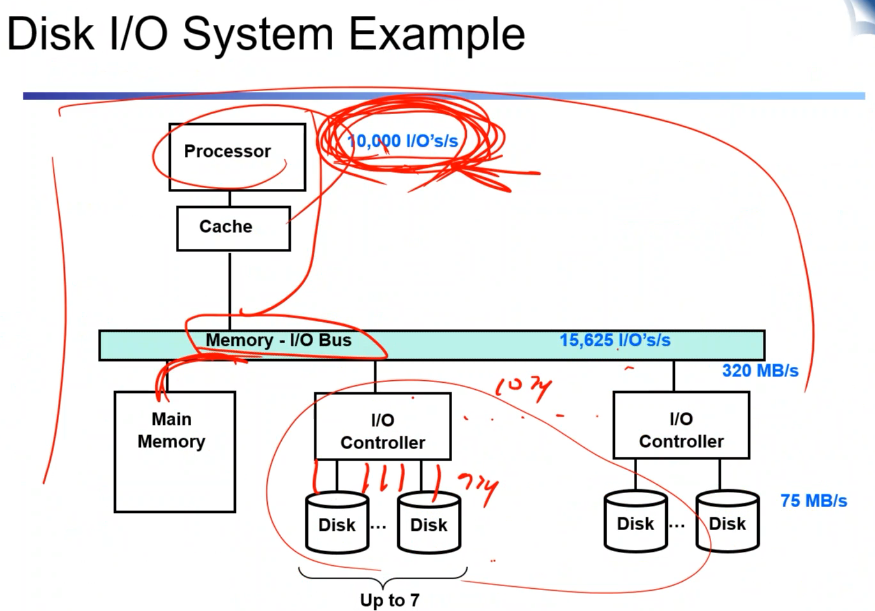
총 3200MB/S 가능하며 낭비가 발생하기는 하지만 CPU의 성능을 최대로 끌어낼 수 있다.
두번째 이슈는 다양한 I/O 장치가 붙기 때문에. 일반적으로는 BUS로 연결되어 있다. bus == shared communication link이다. 물려 있는 디바이스들끼리 bus를 공유하기 때문에. 왜 버스로 하는가? 장점은 버스 표준에 맞춰 설계가 되었다면 어떤 디바이스를 연결하더라도 쉽게 시스템에 연결시키거나 제거가 가능하다. 또한 low cost이다.
- 단점 : bandwidth가 공유가 일어나서 한계가 생긴다.
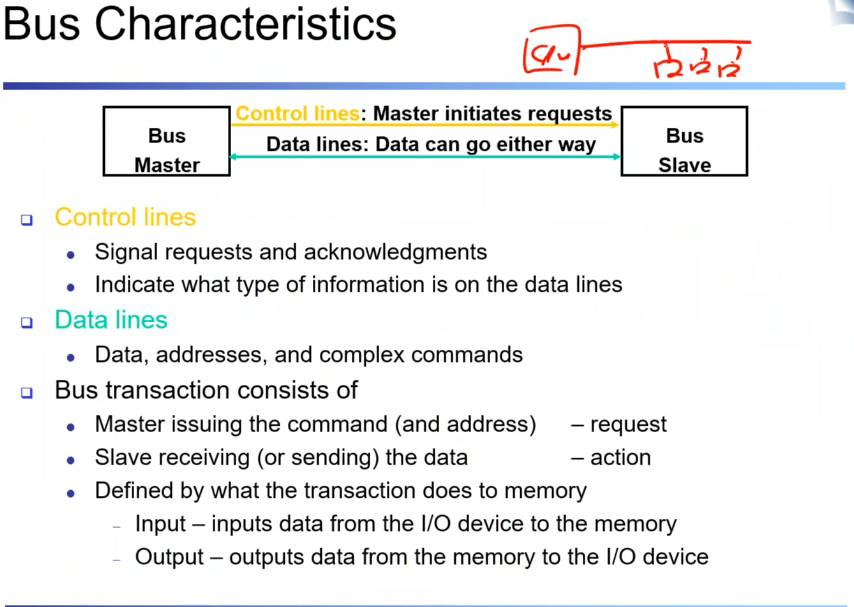
어떤 디바이스를 선택해서 어떻게 주고 받을까? 하드웨어적으로는 dataline과 address라인 control line. 각종 CPU가 master입장에서 control line으로 디바이스를 선택하고 데이터 라인으로 데이터, 주소 등을 주고 받는다. 그런 과정을 버스 트랜잭션이라고 말할 수 있다. 디바이스에 command를 내리고 (request) 그 커맨드에 따라서 action을 한다.

프로세서 - 메모리의 버스와 I/O-BUS는 분리되어 있는게 보통. 전자는 짧고 빠르게 동작. 밴드 위드를 최대화할 수 있도록 설계하고 캐시 블락에 최적화 되어 있다. 아이오버스는 메모리네 보다는 느리고 길이도 길다. 케이블을 통해서 연결을 하고. 다양한 장치를 포함할 수 있도록 구성되어 있다. Backplane bus는 외부 장치들을 바로 연결할 수 있는 것. (PCI, 이더넷, ATA 등)

- CPU와 I/O 사이의 동기/비동기이다. 싱크는 clock 사이클에 동기화 되어 나가는 방식. 에이는 clock이 아니라 request의 타입에 따라 주고 받는 형식으로 주고 받는 형식. 싱크는 clock에 딱딱 맞게 만들어져 있다. 또 내보내기만하면 되기 때문에 로직이 줄어든다. 그러나 버스가 길어지면 clock skew 등이 발생. 그래서 길게 설계하지 못하게 된다. 비동기는 길이에 상관 없이 코맨드를 해석하기 때문에 (핸드 세이킹) 근데 느릴 수 있다.
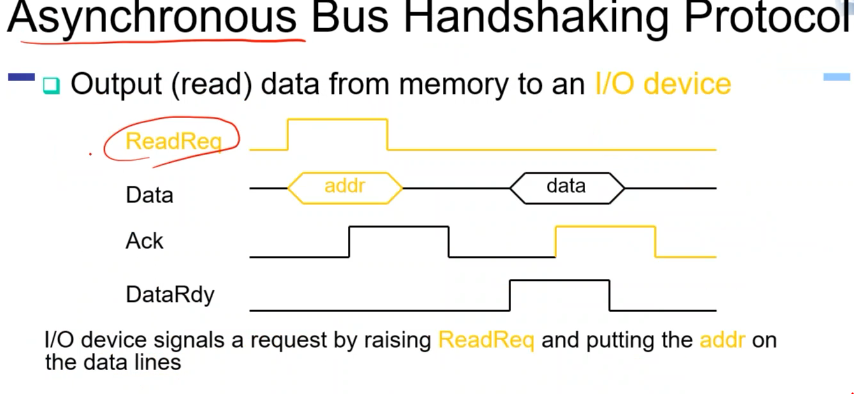
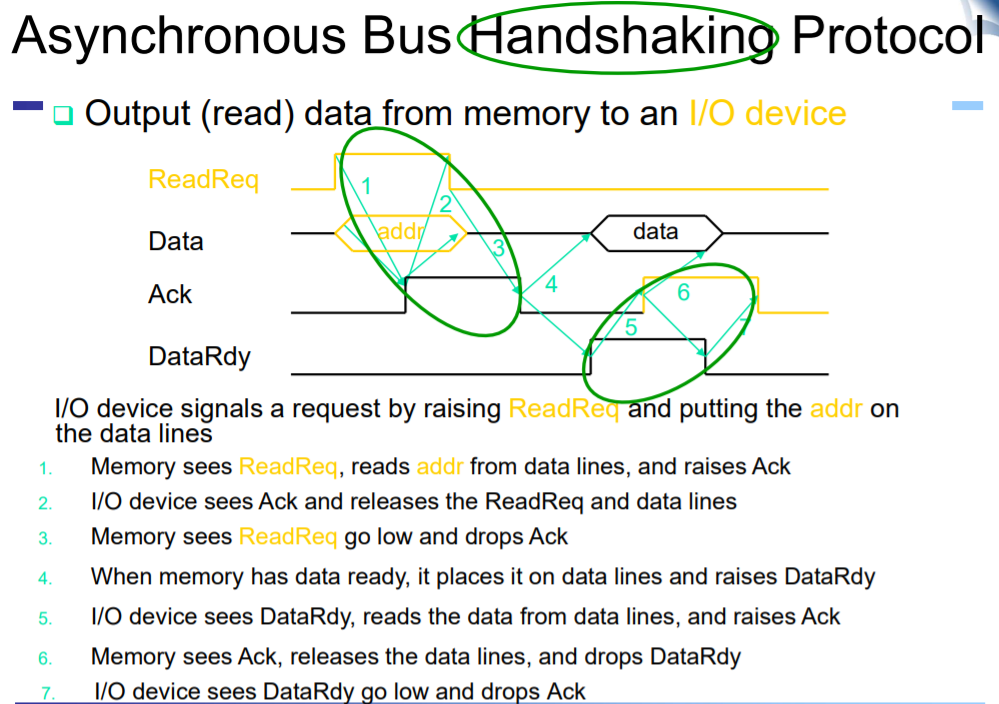
비동기의 케이스를 보자. data와 command에 readRequest를 하나 실고, data에 실고 device에 전달. i/o 장치가 보고 ack 라는 받았다는 신호를 실어주고. cpu가 받은 신호를 지워준다. ack를 받았으면 핸드 세이크로 알게 됨 device가 data를 실어주면 cpu가 dataRdy 시그널을 읽고 data를 가져가고 ack를 통해 읽었음을 보내준다

여러 개의 device가 맞물리면 버느 내에서 누가 보냈는지를 알아야. 그걸 중개해줘야 하는데 그게 bus 아비터. 몇 가지 방식이 있음. 여러개가 경쟁적으로 하기 때문에 우선순위, 공정성에 대한 issue가 발생.
디스트리뷰트는 아비터가 알아서. 네트워크 장치에 실으면 request가 충돌할 수 있음. 버스가 바쁜지를 확인하고 보낸다.
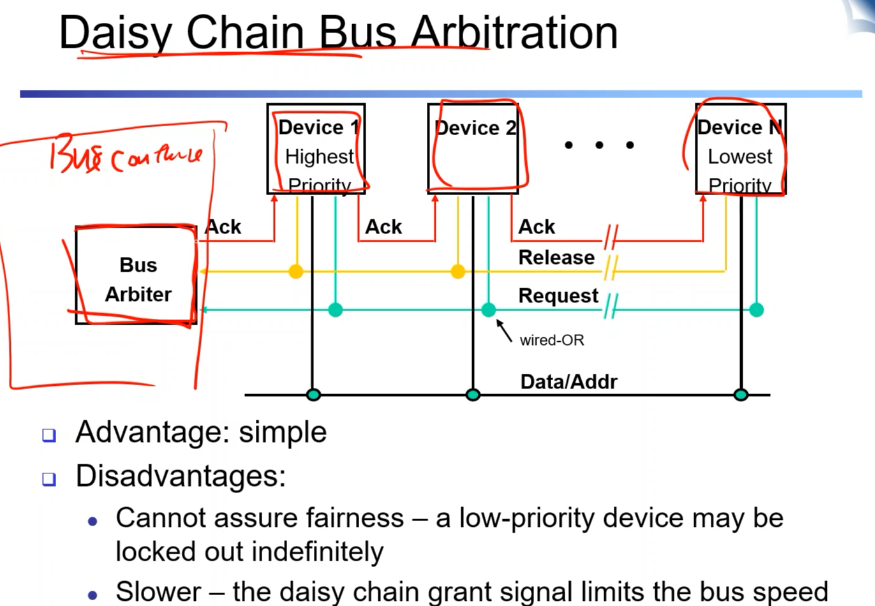
device간의 chain으로 연결되어 있음. 자기것이 아니면 체인으로 연결된 디바이스에 전달전달 해주는 것. 간단해질 수 있는 장점이 있지만 딜레이가 계속 늘어나거나 공정성이 안 좋은 것이 단점.
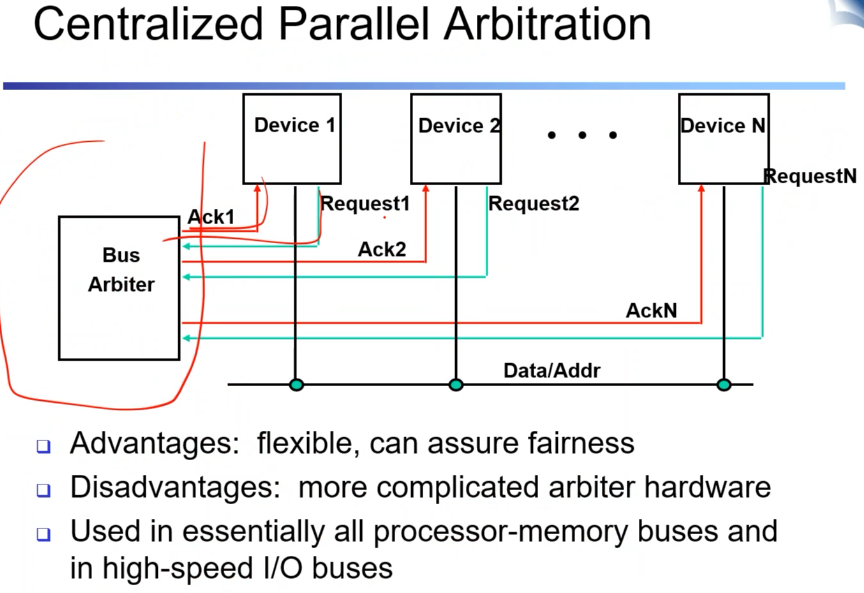
위와 달리 버스 아비터가 디바이스 개별적으로 관여를 하는 것. 일일히 중개를 하기 때문에 공정성과 속도가 유연하게 조절 가능한게 장점. 단점으로는 포트가 많아지고 개별적으로 관리해주는 것이 들어가야 하기 때문에 복잡하다.

버스 자체의 밴드위드. 종류가 많은데 스펙이 보통 정해져 있음. 위는 그 스펙.
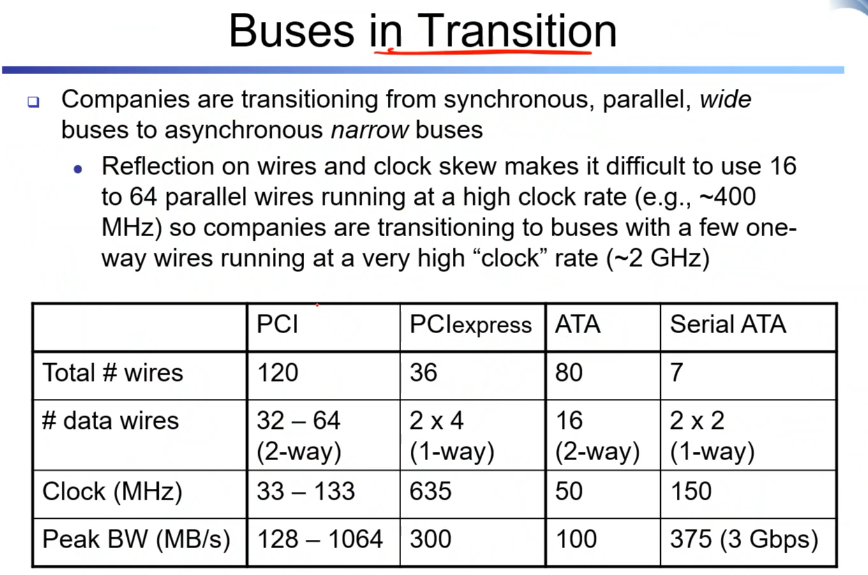
버스도 발전하고 있다.

CPU와I/O장치간 어떻게 데이터를 주고 받는지에 관한 이슈들. 이전까지는 하드웨어적인 이슈고 여기서부터는 논리적인 이슈. 특별한 I/O 명령어.
POLLING 계속해서 관찰을 하는 것. 그래서 CPU 타임이 안 좋고 쓰지도 않는다. interrupt는 cpu는 자기 일을 하고 있다가 특정 i/o장치가 작업을 하고 싶으면 controller를 통해서 전달. cpu는 i/o장치가 있든 없든 감독을 하지 않아도 된다. 단점은 인터럽트를 처리해주는 로직을 추가해야 한다.
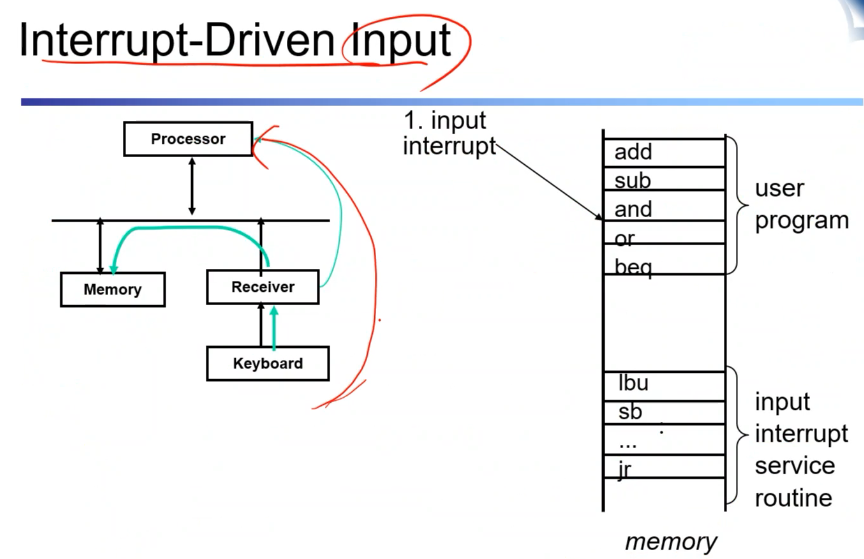
키보드를 치면, 인터럽트를 발생 CPU는 자기 현재 상태를 저장하고 interrupt service routine이 코드로 작성되어 있고 그 서비스 루틴으로 점프가 일어나고 서비스 루틴을 실행한다. 그리고 이후에 끝나면 본래 루틴으로 돌아온다.

이런 인터럽트가 데이터를 트리거해서 디바이스의 방해동작을 통해서 i/o request를 처리하는 일반적인 방식이다. 비동기적으로 처리함. interrupt를 사용하면 이를 처리하는 방식이 하드웨어적으로도 필요하다. 장점은 i/o 디바이스에 대한 감독을 계속하는 게 필요 없다. 다만 추가 구현 사항이 있다. 그렇다면 데이터를 전송은 어떻게 할까?
메모리에서 디스플레이고 가거나 네트워크에서 데이터가 들어오거나 나갈 때 결국 메모리를 거쳐야 한다. 근데 바이트마다 프로세서가 관여하면 넘 낭비. 그래서 DMA라는 것을 씀.

DMA 시작길이부터 원하는 지점까지 원하는 데이터를 옮기라는 것은 DMA 컨트롤러에게 명령하면, 데이터를 옮겨줌. 프로세서는 이동에 관해서 사이클 소모를 하지 않고 자기 일을 할 수 있다. 이런 방식을 DMA라고 한다.
1. DMA 트랜스퍼를 초기화한다.
2. 컨트롤러는 그것을 받아서 그것을 실행
3. DMA 트랜스퍼가 끝나면 인터럽트를 발생시켜서 다했음을 알린다.
이런 DMA를 할 때는 이슈가 존재. DATA를 메모리로부터 I/O디바이스로부터 CPU 관여 없이 옮기기 때문에 DMA리드인 경우에는 캐시의 최신데이터가 아니라 메모리의 최신 데이터가. 캐시데이터가 stale data가 된다.
