
matplotlib.pyplot
직선그래프_plot(x,y)
matplotlib.pyplot이 너무 길기 때문에 plt로 import 해준다.
import matplotlib.pyplot as plt
y = [11,12,13,14,15]
plt.plot(y)
plt.show()
다음은 plot() 메소드의 입력 파라미터의 개수가 2개인 경우이다. 여기에서는 첫번째 항목은 x축 좌표값에 해당하며 두 번째 항목은 y축 좌표값에 해당한다.
x = ['Mon', 'Tue', 'Wed', 'Thur', 'Fri','Sat', 'Sun']
y = [13,16,15,18,16,20,34]
plt.plot(x,y); #;는 2d 무시기를 안나오게 해준다!
plt.xlabel('Daily')
plt.ylabel('no. of Books sold')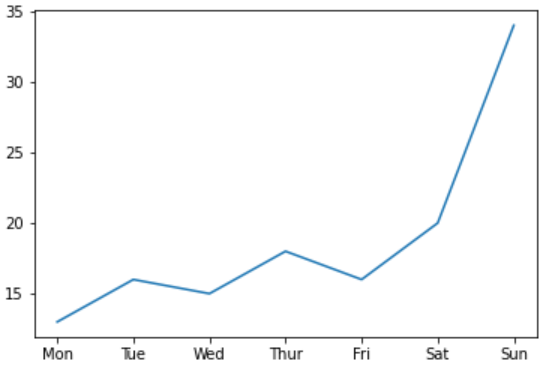
범례와 제목까지 넣어보자
x = ['Mon', 'Tue', 'Wed', 'Thur', 'Fri','Sat', 'Sun']
y1 = [13,16,15,18,16,20,34]
y2 = [31,23,45,50,1,8,50]
plt.plot(x,y1, label="sold"); #;는 2d 무시기를 안나오게 해준다!
plt.plot(x, y2, label="on Sales");
plt.xlabel('Daily')
plt.ylabel('no. of Books sold')
plt.legend(loc='upper left')
plt.title('le petit prince') #한글 쓰면 에러나요~ 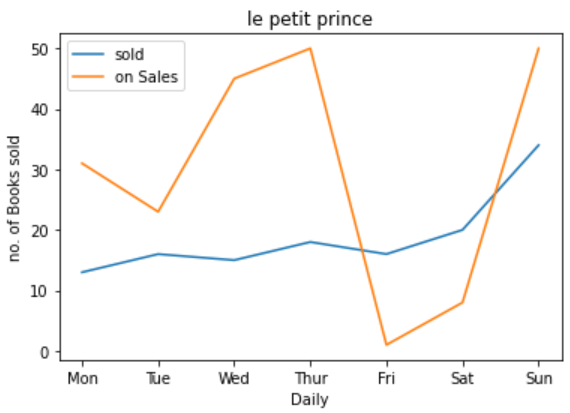
점선 그래프 _ plot(x,y,'bo')
plot 메소드의 옵션으로 'bo'를 입력하면 b(blue) 색상의 'o'모양으로 점을 표시한다.
x = [13,16,15,18,16,20,34]
y = [31,23,45,50,1,8,50]
plt.plot(x,y, 'bo')
import numpy as np
points = np.array([[1,1],[1,2],[1,3],[2,1],[2,2],[2,3],[3,1],[3,2],[3,3]])
p = np.array([2.5,2])
import matplotlib.pyplot as plt
plt.plot(points[:,0], points[:,1], "ro")
plt.plot(p[0], p[1], "bo")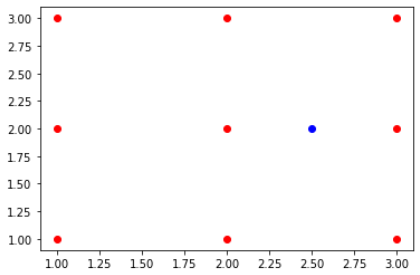
위와 같이 하나의 점만 blue인 o로 만들 수도 있다.
다양한 형태의 그래프 그리기
수식을 조금 변화시키면 다음과 같이 x^2의 형태의 그래프도 그릴 수 있다.
x = np.linspace(0,10,20)
y = x**2
plt.plot(x,y)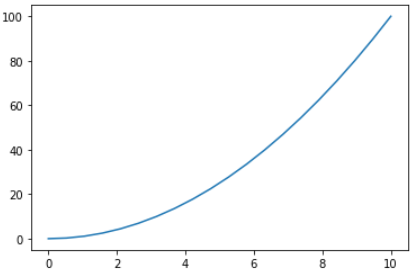
다음과 같은 점과 선의 굵기 등을 커스터마이징 하는 것도 가능하다
x = np.linspace(0,10,20)
y = x**2
plt.plot(x,y, "go-", linewidth =3, markersize=5);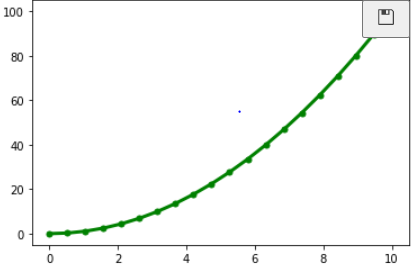
Pandas와 데이터 형식
pandas에는 크게 2가지 형태의 데이터 형식이 있다. 바로 시리즈(Series)와 데이터 프레임(Data Frame)이다. 시리즈는 1차원 배열의 개념이며, 데이터 프레임은 2차원 배열의 개념이다.
시리즈 형식
pandas의 시리즈는 1차원 배열의 행태와 비슷한데 복수의 행(row)으로 이루어진 하나의 열 구조를 가지고 있다. 또한 인덱스를 가지고 원하는 데이터에 접근할 수 있다. 아래는 pd로 가져와서 pandas의 시리즈 형식으로 array를 변환하는 명령문이다. 그러면 아래에는 자동으로 0~3까지의 색인을 만들어준다.
import pandas as pd
pd.Series([7,3,5,8])
0 7
1 3
2 5
3 8다음은 자동으로 색인을 만들지 않고 원하는 색인의 이름을 입력하는 명령문이다. 이때 index라는 키워드를 사용하며 아래와 같이 입력 데이터를 작성하면 된다.
x=pd.Series([7,3,5,8], index=['서울','대구','부산','광주'])
print(x)
서울 7
대구 3
부산 5
광주 8pandas의 시리즈 형식으로 변환된 데이터는 다음과 같이 색인을 나열하여 원하는 값들을 출력할 수 있다.
x[['서울','대구']]
서울 7
대구 3
dtype: int64
# 다음과 같이 index를 사용하면 만들어진 시리즈 데이터에서 인덱스만 출력할 수 있다
x.index #Index(['서울', '대구', '부산', '광주'], dtype='object')
# 다음과 같이 values를 사용하면 시리즈 데이터에서 값들만 출력할 수 있다.
x.values #array([7, 3, 5, 8], dtype=int64)sorted()
또한 sorted()함수를 사용하여 인덱스나 값들로 정렬할 수 있다.
print(sorted(x.index)) #['광주', '대구', '부산', '서울']
print(sorted(x.values)) #[3, 5, 7, 8]
x = x.reindex(sorted(x.index))
광주 8
대구 3
부산 5
서울 7series값 더하기
다음은 x와 y에 저장되어 있는 인덱스별로 지정된 값들의 합을 구하는 명령문이다. x와 y에 공통된 인덱스가 존재애햐 더할 수 있으므로 광주와 대전은 NaN가 표시된다. (index의 교집합만 계산 가능하다)
x = pd.Series([3,5,8,9], index =['서울', '대구', '부산', '광주'])
y = pd.Series([10,10,10,10], index =['대구', '부산', '서울', '대전'])
x + y
광주 NaN
대구 15.0
대전 NaN
부산 18.0
서울 13.0Pandas의 1차원 배열 형식인 Series 객체로부터 유일한 값들만을 반환하는 메소드를 사용한다.
medal = [1,3,2,4,2,3]
x = pd.Series(medal)
print(pd.unique(x)) #[1 3 2 4], 문자열도 동일하게 작동한다 걱정 nono다음은 사전 형식의 데이터를 Pandas의 Series 형식으로 변환하는 예제이다
age = {'민준':23, '현우':43, '서연':12, '동현':45}
x = pd.Series(age)
x
민준 23
현우 43
서연 12
동현 45그런데 Pandas형식을 사용할 때 유념할 점이 있다. 다음의 예제.
names = ['민준', '서연','현우', '민서', '동현', '수빈']
pdata = pd.Series(names)
print(pdata)
0 민준
1 서연
2 현우
3 민서
4 동현
5 수빈
a = pdata[3:6]
3 민서
4 동현
5 수빈
print(a[2]) # ValueError: 2 is not in range
print(a[5]) #수빈리스트라면 수빈이 출력되어야하는데 에러가 발생한다. 왜냐면 Series 기본 구조에서는 인덱스 번호가 저장되어 있기 때문이다.
데이터 프레임
다음은 Pandas의 두 번째 형식인 DataFrame을 살펴보자. 앞서 설명한 대로 DataFrame은 2차원 배열의 개념. 그래서 열에 대한 각각의 이름을 부여.
data = {
'age':[23,43,12,45],
'name':['민준', '서연','현우', '민서'],
'height':[175.3, 180.3, 165.8, 172.7]
}
x = pd.DataFrame(data, columns =['name', 'age', 'height'])
x
name age height
0 민준 23 175.3
1 서연 43 180.3
2 현우 12 165.8
3 민서 45 172.7data = { 'age':[23,43,12,45], 'name':['민준', '서연','현우', '민서'], 'height':[175.3, 180.3, 165.8, 172.7] }
x = pd.DataFrame(data, columns =['name', 'age', 'height'])
print(x.mean()) 요렇게 평균을 구할 수도 있다
age 30.750
height 173.525
### 특정 칼럼만 출력하기
✔️name 칼럼만 출력하는 방법 x.name
0 민준
1 서연
2 현우
3 민서
x.height
0 175.3
1 180.3
2 165.8
3 172.7
### 특정한 행이나 위치의 내용을 지정해 출력하기
✔️ 위 방법으로는 특정한 위치의 내용들을 출력하기 어렵다.
Pandas에서는 iloc() 메소드를 사용해서 특정한 행이나 위치의 내용들을 지정하여 출력할 수 있다. first second0 1 2
1 3 4
2 5 6
✔️ 1차원 배열을 이용하면 특정한 행들의 값들을 출력할 수 있다. 여기에서는 1번 행의 값들을 출력하기 위해 다음과 같은 명령문을 실행한다.
data.iloc[1]
first 3
second 4
Name: 1, dtype: int64
✔️ 다음은 모든 행의 마지막 데이터만을 출력하는 명령문이다. data.iloc[:, -1]
0 2
1 4
2 6
✔️ 그리고 head() 와 tail()을 사용하면 처음이나 마지막 행의 결과를 출력할 수 있다. head() 메소드에서 괄호 안에 입력값을 넣으면 첫 행부터 입력한 수만큼의 행이 출력이 되며, 입력하지 않으면 다음과 같이 첫 5줄의 행을 출력. tail도 원리는 동일
array = [[1,2], [3,4], [5,6], [7,8], [9,10]]
data = pd.DataFrame(ary, columns =['First','Second'])
data.head(1)
First Second0 1 2
data.head(3)
First Second
0 1 2
1 3 4
2 5 6
boolean값 이용하기
pandas의 DataFrame에서 특정 항목만 선택하여 저장하거나 출력할 수 있다. 여기에서는 boolean 값을 이용하여 True 인 것은 선택하고 False인 것은 선택하지 않도록 설정하는 예를 설명한다.
ary = [[1,2], [3,4], [5,6], [7,8], [9,10]]
data = pd.DataFrame(ary, columns = ['First', 'Second'])
bools = [False, True, True, False, True]
data.Second[bools]
1 4
2 6
4 10
Name: Second, dtype: int64
bools의 1,2,4 번 인덱스 위치의 값들만 True 이므로 data의 Second 칼럼의 해당 값들만 출력.pandas의 []는 위치를 나타내는 인덱스 기능 외에도 추가적인 기능이 있다. 아래의 예제와 같이 부울형 리스트를 인덱스 값으로 입력하면 참에 해당하는 행(row)들만 출력하게 된다
data = {
'age':[23,43,12,45],
'name':['민준', '서연','현우', '민서'],
'height':[175.3, 180.3, 165.8, 172.7]
}
x = pd.DataFrame(data, columns =['name', 'age', 'height'])
index = [True,False,True,False]
print(x[index])
name age height
0 민준 23 175.3
2 현우 12 165.8pandas에 파일 가져오기
import pandas as pd
food = pd.read_csv('food.csv', encoding='cp949')
food.head()
구분 국가 시작일 종료일 성격 비고
0 단독형 말레이시아 2021-06-29 2021-06-29 B2B 온라인
1 단독형 태국 2021-07-29 2021-07-30 B2B 온라인
2 단독형 프랑스 2021-09-09 2021-09-10 B2B 온라인
3 단독형 호주 2021-07-14 2021-07-15 B2B 온라인
4 연계형 베트남 2021-11-04 2021-11-05 B2B 온라인