파이썬으로 DNA 데이터를 열고 가공하기
1. readlines()
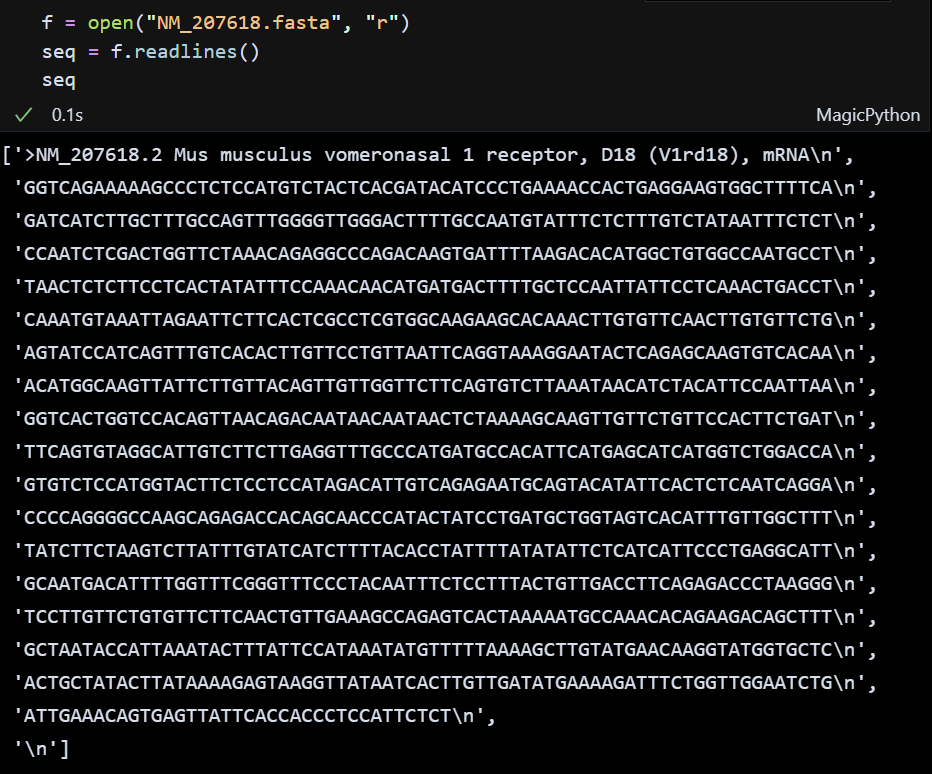
readlines(): 줄별로 모든 줄을 출력해준다.
2. readline()
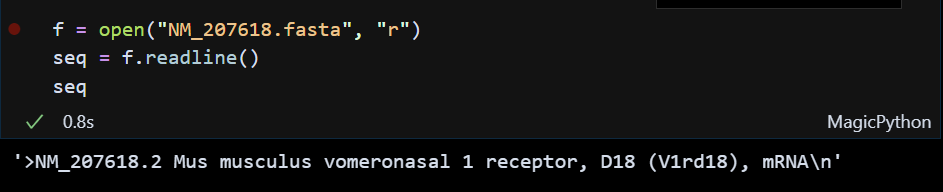
readline() : 위에 한 줄만 출력한다
3. splitlines(True)

4. writelines
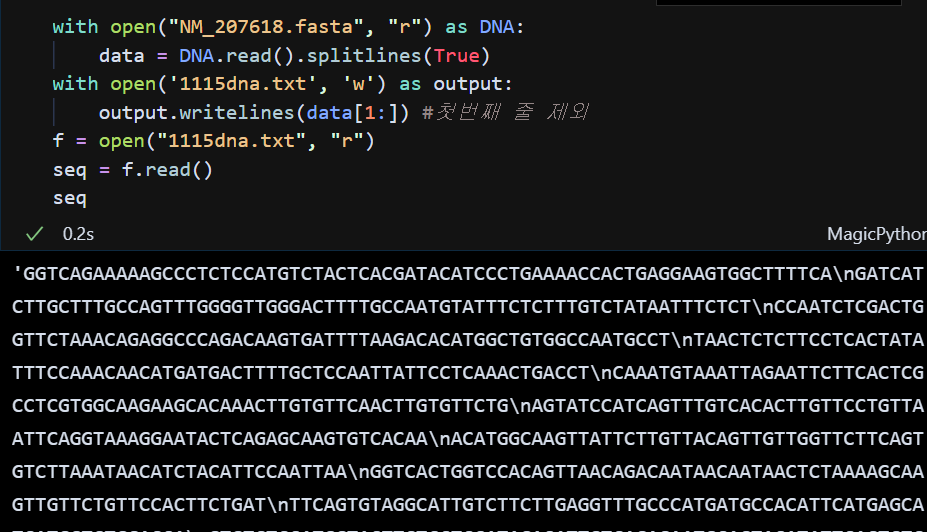
위의 결과를 살펴보면 '\n' 문자가 들어있는 것을 볼 수 있다. 그러나 데이터 분석에서는 필요하지 않으므로 삭제해야 한다. 다음과 같이 '\n'의 문자를 삭제해야 한다.
5. replace('\n','')
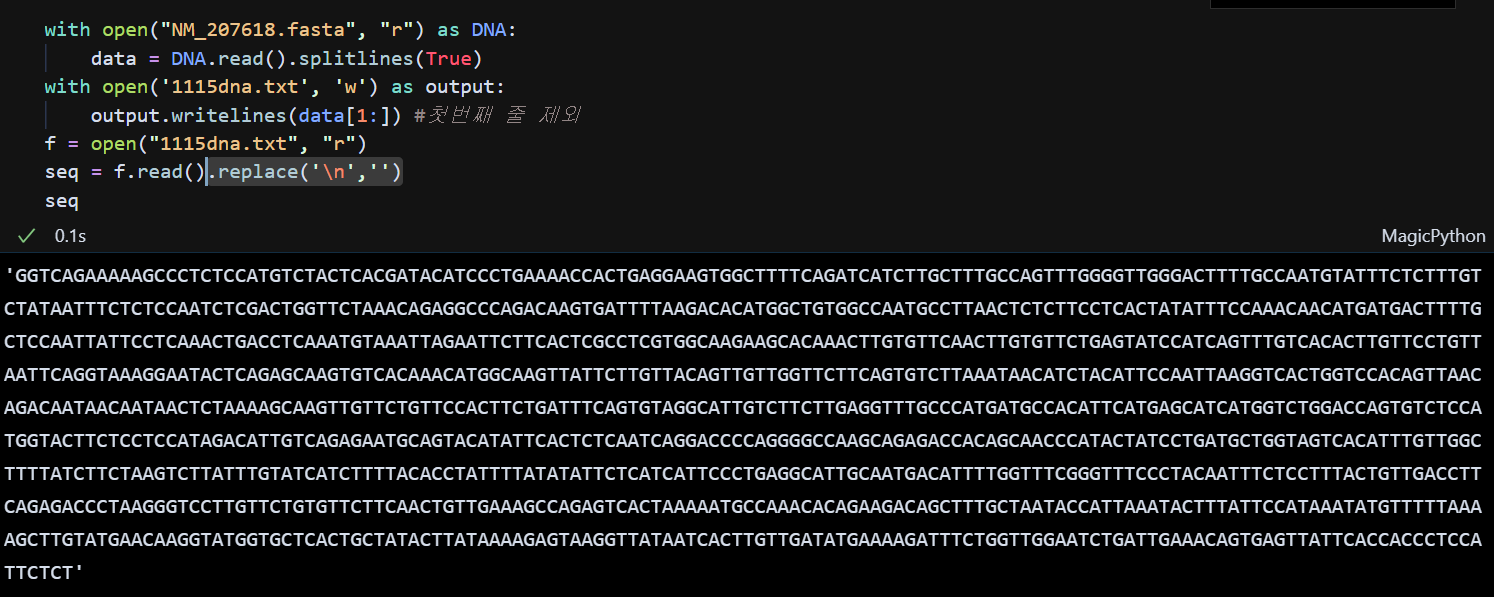
공란(' '), '\r'와 같은 문자들도 위와 같은 방식으로 대체할 수 있다.
6. DNA 시퀀스를 아미노산 시퀀스로 변환
with open("NM_207618.fasta", "r") as DNA:
data = DNA.read().splitlines(True)
with open('1115dna.txt', 'w') as output:
output.writelines(data[1:]) #첫번째 줄 제외
f = open("1115dna.txt", "r")
a = f.read().replace('\n','')
def convert(seq):
# 아미노산 시퀀스 변환
genetic_code = {
'ATA':'I', 'ATC':'I', 'ATT':'I', 'ATG':'M',
'ACA':'T', 'ACC':'T', 'ACG':'T', 'ACT':'T',
'AAC':'N', 'AAT':'N', 'AAA':'K', 'AAG':'K',
'AGC':'S', 'AGT':'S', 'AGA':'R', 'AGG':'R',
'CTA':'L', 'CTC':'L', 'CTG':'L', 'CTT':'L',
'CCA':'P', 'CCC':'P', 'CCG':'P', 'CCT':'P',
'CAC':'H', 'CAT':'H', 'CAA':'Q', 'CAG':'Q',
'CGA':'R', 'CGC':'R', 'CGG':'R', 'CGT':'R',
'GTA':'V', 'GTC':'V', 'GTG':'V', 'GTT':'V',
'GCA':'A', 'GCC':'A', 'GCG':'A', 'GCT':'A',
'GAC':'D', 'GAT':'D', 'GAA':'E', 'GAG':'E',
'GGA':'G', 'GGC':'G', 'GGG':'G', 'GGT':'G',
'TCA':'S', 'TCC':'S', 'TCG':'S', 'TCT':'S',
'TTC':'F', 'TTT':'F', 'TTA':'L', 'TTG':'L',
'TAC':'Y', 'TAT':'Y', 'TAA':'_', 'TAG':'_',
'TGC':'C', 'TGT':'C', 'TGA':'_', 'TGG':'W',
}
protein = ""
if len(seq) % 3 == 0:
for i in range(0, len(seq), 3): #데이터의 길이가 3의 배수이면 아래를 실행
codon = seq[i: i+3]
protein += genetic_code[codon]
return protein
print(convert(a[20:938]))7. 변환한 아미노산 서열과 사이트에서 다운로드한 것이 일치하는지를 비교
prot = read_seq('protein.txt')
prot == Convert(dna[20:935]) #True통계와 수학적 기능을 위한 Numpy
Numpy는 과학적인 계산을 위해 파이썬에서 제작한 것이다. Numpy는 n차원 배열의 객체이며, 이산수학과 무작위 수 생성 등 수많은 작업을 할 수 있는 기능이 제공된다. 다만, C를 바탕으로 하고 있어 동적으로 생성되는 파이썬 리스트와 달리 Numpy 배열은 정적 메모리 할당과 같이 생성할 때 크기가 정해진다. Numpy가 특별한 또 다른 이유는 텐서플로우와의 호환성이다!
Numpy의 설치 & 기초
pip install Numpy #요렇게 설치할 수 있다 아래 표에서 보는 바와 같이 우선 import 명령문으로 무듈을 가지고 와서 해당 데이터를 Numpy 형식으로 수정한 후 원하는 Numpy의 기능을 수행하면 된다.
import numpy as np 🎸numpy 모듈 가져오기
x = np.array([1,3,5]) 🎸파이썬의 데이터형(리스트)을 Numpy 형식으로 변환
print(x.mean()) 🎸Numpy에서 제공하는 기능 수행 Numpy에서 제공해 주는 배열을 이용하면 배열에 저장된 원소들의 mean 값을 계산해준다. 그리고 array()라는 메소드를 사용하여 1차원 배열을 생성할 수 있다. 그리고 mean()이라는 메소드를 이용해 해당값을 구할 수 있다.
1차원 배열 확인하기
print(x.shape) #(3,) 출력여기에는 shape 해당 클래스에서 제공해주는 attribute이다. 1차원 배열로 3개의 원소가 있다는 결과가 나온다. shape는 Numpy 배열의 객체가 지원하는 attribute이다. 그렇기 때문에 함수처럼 ()을 붙여주면 안된다.
Quiz 9.1
import numpy as np
a = np.array([[1,2,3], [2,3,4]]) #[], [] 을 [] 로 한 번 더 감싸야함
print(a.shape)reshape()
여기에 reshape(행, 열) 메소드를 추가하면 다음과 같이 Numpy의 2차원 배열을 원하는 모양으로 생성할 수 있다.
x = np.array([1,3,5,7,9,11]).reshape(3,2)
print(x)
결과
[[ 1 3]
[ 5 7]
[ 9 11]]zeros([])
2차원의 배열을 0(1)의 값들로 채우려면 다음과 같이 실행하면 된다.
y = np.zeros([3,4])
print(y)
결과
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]Numpy 배열의 슬라이싱
다음은 파이썬의 2차원 리스트에서 모든 원소의 두번째 원소들만 출력.
import numpy as np
list = ([[1,11], [2,12], [3,13]])
np_ary = np.array(list)
print(np_ary[:,1]) #import numpy as np
list1 = [[1,11], [2,12], [3,13]]
print(np.array(list1[:,1]))
#TypeError: list indices must be integers or slices, not tuple
#리스트의 인덱스들은 튜플이어선 안 되며 반드시 정수나 슬라이스여야 한다. => 그냥 선언하면 튜플임리스트를 곧장 사용하면 안되고 2차원 리스트를 우선 Numpy의 배열 형식으로 변환 후 이를 다음과 같이 표현하여 실행하면 된다.
Numpy를 이용한 연산
import math
math.sqrt(2) #1.4142135623730951
# 리스트로 줘도 계산이 가능하다
np.sqrt([2,3,4]) #array([1.41421356, 1.73205081, 2. ])
한가지 확인해볼 수 있는 특징은 2. 뒤의 공백인데 메모리에 미리 공간을 할당해줌행렬 다루기
import numpy as np
a = np.arange(15)
print(a)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
b = a.reshape(3,5) #reshape(⬇️➡️) 요 순서다
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
quiz 9.4 6은 어떻게 출력?
print(b[1][1]) 제로 벡터와 제로 행렬
import numpy as np
zero_vector = np.zeros(3)
zero_vector #array([0., 0., 0.])다음의 코드를 실행하면 0으로 초기화된(4*3) 형식의 2차원 배열이 생성된다.
zero_matrix = np.zeros((4,3))
zero_matrix
#array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
일반적인 리스트의 결과와 달리 아래처럼 2개 배열에 저장된 내용을 인덱스별로 합을 구해 출력하게 된다. 선형대수의 행렬 합과도 같은 개념이며, 다른 사칙 연산들에서도 동일하게 작동한다.
x = np.array([1,2,3])
y = np.array([100,1000,10000])
z = x + y
z #array([ 101, 1002, 10003])다음과 같이 응용도 가능하다.
x = np.array([1,2,3])
y = x + 1
y #array([2, 3, 4])quiz 9.7
x = np.array([4,8,12])
y = np.array([2,4,6])
z = x // y
z # array([2, 2, 2], dtype=int32)리스트 인덱싱
다음처럼 리스트 인덱싱 방법으로 새로운 Numpy 배열에 접근할 수 있다.
a = np.array([10,20,30,40,50,60,70,80,90])
print(a[1::2])불리언(Boolean)
다음은 Numpy에서 제공하는 Boolean 배열
a = np.array([10,20,30,40,50,60,70,80,90])
b = a > 50
print(b) #[False False False False False True True True True]등간격 나누기
Numpy는 시작과 끝의 값을 지정하고 그 사이의 값을 균등하게 배분하는 기능을 제공한다.
np.linspace(0,12,4) # array([ 0., 4., 8., 12.])
np.linspace(0,12,4, retstep=True) # (array([ 0., 4., 8., 12.]), 4.0)
#retstep(return step)이 참이면 샘플 간의 간격을 마지막 값으로 출력함
np.linspace(0,12,3,endpoint=False) #array([0., 4., 8.]) 마지막 값 생략
