
2024.6.18
~ 2024.6.21
나중에 여기서 정보를 찾아볼 나 자신을 위해서 남기는 글. aws 강의가 전반적으로 설명도 부족하고 순서도 엉망이다. 특히 뒷부분은 신뢰할 수가 없다. 강의가 중간에 잘렸는데 그에 대한 언급없이 마치 의도한것 마냥 진행되기 때문이다. 처음부분부터 docker부분에 리액트 도커파일 생성하기 부분까지만 보고 그 뒷부분은 참조하지마라. s3로 배포하는건 라이브강사님께서 직접 보여주신거라 해도 될 것 같다.
AWS
Amazon Web Service는 아마존에서 제공하는 클라우딩 컴퓨터 서비스 플랫폼이다. AWS는 다양한 클라우드 기반 서비스(서버, 저장소, 데이터베이스, 네트워킹, 분석도구, 머신러닝, AI, 사물인터넷)를 제공한다. 이러한 서비스를 통해 기업이나 개발자는 물리적인 하드웨어 없이 인터넷을 통해 IT리소스를 사용 할 수 있다.
아마존의 모든 서비스는 API 중심으로 설계되어 있어 모든 기능이 API로 제어 가능하다. 광범위한 글로벌 클라우드 인프라를 갖추고 있어 최적의 인프라 환경을 제공한다.
출처 : https://brunch.co.kr/@e9c7009de84443b/102
-> 결국에 aws를 왜 사용하느냐? 안전하기 때문이다. 예전에 카카오 사태를 보면, 카카오에 db인지 서버인지가 하나뿐이었고, 그게 다운되자 회복될때까지 카카오 자체 이용이 불가능했다. 그에 반해 이 뒤에서 계속 배우겠지만, aws는 전 세계에 복사본 같은 서버들이 분산이 되어있어서 빠르기도 하지만 하나가 망가져도 근처에서 받아와서 사용할 수가 있다. 즉, 데이터가 소실될 위험이 적고 망가지더라도 금방 복구 될 수 있으며 빠르다. 또 이것도 뒤에 나오지만, 사용한 만큼만 가격을 책정하고 여러 권한을 설정할 수 있고 서버를 확장해야하면 바로 확장하면 된다. (돈만 더내면 된다.) 이런 여러 이유들로 aws가 세계 1등인 것 같다.
클라우드 컴퓨팅
클라우드 컴퓨팅이란 인터넷, 즉 클라우드를 통해 서버, 스토리지, 데이터베이스 등 필요한 IT자원을 제공하는 것을 뜻한다다. 요즘 사람들이 사진과 파일을 저장하는 클라우드가 바로 이것이다. 스토리지의 역할을 한다.
가장 큰 장점은 비용을 절감할 수 있는 것이다. 따로 소프트웨어를 구매하고 데이터 센터를 설치해 직접 운영하지 않아도 클라우드 컴퓨팅으로 모두 해결 할 수 있다. 대부분의 클라우드 컴퓨팅 서비스는 사용한 만큼만 비용을 지불하게 되어 있다. (특히 인건비 절감)
또한 어디서든 인터넷만 있으면 접속가능하기 때문에 빠르게 일을 처리할 수 있고, 몇 분만에 전 세계에 내가 만든 프로그램을 배포 할 수 있다.
클라우드 서비스
클라우드 서비스란 클라우드 컴퓨팅을 통해 제공되는 특정 서비스나 애플리케이션을 의미한.
-
IaaS (Infrastructure as a Service): 가상화된 컴퓨팅 자원, 즉 서버, 스토리지, 네트워킹 등을 제공하는 서비스. 예: AWS EC2, Microsoft Azure.
-
PaaS (Platform as a Service): 애플리케이션 개발 및 배포를 위한 플랫폼을 제공하는 서비스. 개발자가 인프라 관리 없이 애플리케이션을 개발, 실행, 관리할 수 있도록 지원한다. 예: Google App Engine, Microsoft Azure App Services.
-
SaaS (Software as a Service): 완전한 소프트웨어 애플리케이션을 인터넷을 통해 제공하는 서비스. 사용자는 소프트웨어를 설치하거나 관리할 필요 없이 사용할 수 있습니다. 예: Google Workspace, Microsoft Office 365.
정리하면, 클라우드 컴퓨팅은 컴퓨터를 통해서 it 자원을 제공하는 그 자체를 말하고 클라우드 서비스는 클라우드 컴퓨팅을 통해 제공되는 특정 서비스를 말한다.
with ChatGPT
AWS(Amazon Web Services)는 IaaS(인프라스트럭처 서비스)뿐만 아니라 PaaS(플랫폼 서비스)와 SaaS(소프트웨어 서비스)도 제공합니다.
IaaS (Infrastructure as a Service)
AWS의 IaaS 서비스는 사용자가 가상화된 컴퓨팅 리소스(예: 서버, 스토리지, 네트워킹)를 필요에 따라 사용할 수 있도록 제공합니다. 대표적인 서비스는 다음과 같습니다.
- Amazon EC2 (Elastic Compute Cloud): 가상 서버를 제공합니다.
- Amazon S3 (Simple Storage Service): 객체 스토리지 서비스로 데이터를 저장할 수 있습니다.
- Amazon VPC (Virtual Private Cloud): 격리된 네트워크를 생성하고 관리할 수 있습니다.
- Amazon EBS (Elastic Block Store): 블록 스토리지 볼륨을 제공합니다.
PaaS (Platform as a Service)
AWS의 PaaS 서비스는 애플리케이션 개발, 배포, 관리에 필요한 플랫폼을 제공합니다. 대표적인 서비스는 다음과 같습니다.
- AWS Elastic Beanstalk: 애플리케이션을 쉽게 배포하고 관리할 수 있는 플랫폼을 제공합니다.
- AWS Lambda: 서버를 관리하지 않고 코드를 실행할 수 있는 서버리스 컴퓨팅 서비스입니다.
- Amazon RDS (Relational Database Service): 관계형 데이터베이스를 설정, 운영 및 확장할 수 있는 플랫폼을 제공합니다.
SaaS (Software as a Service)
AWS의 SaaS 서비스는 완전한 소프트웨어 애플리케이션을 인터넷을 통해 제공하며, 사용자는 설치나 관리 없이 사용할 수 있습니다. 대표적인 서비스는 다음과 같습니다.
- Amazon WorkSpaces: 데스크탑 가상화 서비스로, 클라우드에서 데스크탑 환경을 제공합니다.
- Amazon Chime: 온라인 회의 및 비디오 회의 서비스를 제공합니다.
- Amazon QuickSight: 클라우드 기반의 비즈니스 인텔리전스(BI) 서비스로 데이터를 시각화하고 분석할 수 있습니다.
따라서 AWS는 IaaS에 해당하는 서비스도 제공하지만, PaaS 및 SaaS에 해당하는 서비스도 함께 제공하는 클라우드 서비스 플랫폼입니다.
EC2
Elastic Computing Cloud. c가 두개여서 c2
EC2는 aws의 핵심 서비스로 아마존이 각 세계에 구축한 데이터 센터의 서버용 컴퓨터들의 자원을 원격으로 사용하는 것으로, 쉽게말해 아마존으로부터 한 대의 컴퓨터를 임대하는 것을 말한다. AWS가 제공하는 URL을 통해 이 컴퓨터에 접근 할 수 있다.
임대한 컴퓨터에 OS(window, mac, linux 등)를 설치하고, 웹 서비스를 위한 프로그램(웹서버, db)을 설치해서 사용하면 된다. 1대의 컴퓨터를 하나의 EC2 인스턴스라고 부른다.
(아마존에게 컴퓨터 한대를 임대했다! = EC2 인스턴스를 하나 만들었다!)
EC2를 사용하면 하드웨어(컴퓨타)에 투자할 필요가 없고 더 빠르게 애플리케이션을 만들고 배포 할 수 있다. 원하는 만큼 가상 서버를 구축하고 보안 및 네트워크의 구성과 스토리지 관리가 가능하다. (서비스를 제공하려면 서버컴퓨터, db컴퓨터 등이 필요하고 그것을 직접 운용 할 수도 있지만 클라우드 서비스를 통해서 그것을 대체 할 수 있는 것이다.)
만약 제공중인 서비스가 인기 증대 등 변동사항이 갑작스럽게 생겨도 EC2를 이용하면 신속하게 규모를 확장하거나 축소 할 수 있기때문에 서버 트래픽 예측 필요성이 줄어든다.
이렇게 서비스의 성능이나 용량을 조절할 수 있고 그것이 자유로우며, 사용한 만큼만 요금을 지불 할 수 있음으로 탄력적이라는 의미의 Elastic이라는 이름이 붙여졌다.
보안 및 네트워크 구성, 스토리지 관리가 효율적으로 이뤄지고 클릭 몇번으로 서버를 생성할 수 있어서 실제 서버를 구축하는 것 보다 훨씬 간편하고 효율적이다.
보안그룹
aws에서 가장 기본이 되는 네트워크 보안 기술로, 보안그룹을 사용하여 ec2 인스턴스로 들어오거나inbound, 나가는 outbound 트래픽들을 직접 설정하여 제어 할 수 있다.
- 필요한 규칙
- 포트
- 인증된 IP범위
- inbound network
- outbound networ
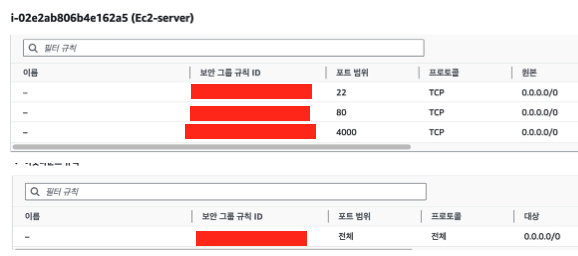 실제로 EC2 인스턴스를 만들고 보안그룹을 추가한 모습이다. 위는 inbouce, 아래는 outbounce이다.
실제로 EC2 인스턴스를 만들고 보안그룹을 추가한 모습이다. 위는 inbouce, 아래는 outbounce이다.
이렇게 설정이 되어 있으면 들어오는 트래픽은 포트는 22, 80, 4000에서만 허용되지만 ip는 상관이 없게되는 거고, 나가는 트래픽은 ip, port와 상관 없이 밖으로 보낼 수 있다.
인스턴스 생성
- aws 로그인 -> 콘솔 -> ec2 검색
- 인스턴스 시작 -> 이름 생성 -> os 선택
 실습에서는 ubuntu를 사용할 것임으로 ubuntu를 선택했다. 리눅스(보통 서버컴퓨터에서 실행되는 운영체제)의 배포판이라고 한다. 그리고 모두 프리티어로 선택한다. (기본으로 되어있다. 무료판! 이지만 검색해보니 프리티어는 1년간 무료로 aws를 사용하게 해주는건데, 허용 용량보다 많이 사용하면 요금이 청구되고 또 1년이 지나기 전에 삭제하지 않아도 청구가 된다고 한다. 무서워)
실습에서는 ubuntu를 사용할 것임으로 ubuntu를 선택했다. 리눅스(보통 서버컴퓨터에서 실행되는 운영체제)의 배포판이라고 한다. 그리고 모두 프리티어로 선택한다. (기본으로 되어있다. 무료판! 이지만 검색해보니 프리티어는 1년간 무료로 aws를 사용하게 해주는건데, 허용 용량보다 많이 사용하면 요금이 청구되고 또 1년이 지나기 전에 삭제하지 않아도 청구가 된다고 한다. 무서워) - 키페어 생성. ssh(보안)로 서버에 접근하기 위한 키를 발급한다.
 다운로드 된 모습
다운로드 된 모습 - 인스턴스 시작 -> 모든 인스턴스 보기
 인스턴스가 생성된 모습. 조금 지나면 상태가 실행 중으로 바뀐다.
인스턴스가 생성된 모습. 조금 지나면 상태가 실행 중으로 바뀐다.
인스턴스에 접근
터미널을 통해서 생성된 인스턴스에 ssh를 통해서 접근해보자. 키페어가 저장되어 있는 디렉토리로 이동한 후에 위와 같이 입력하면 된다. 뒤에 오는 dns는
키페어가 저장되어 있는 디렉토리로 이동한 후에 위와 같이 입력하면 된다. 뒤에 오는 dns는 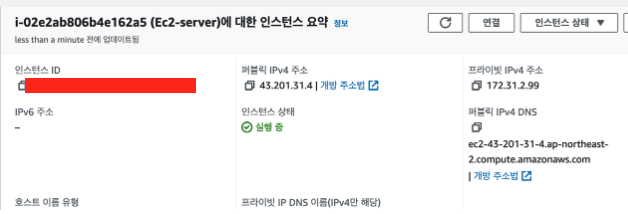 내 인스턴스에 들어가보면 퍼블릭 dns라고 나와있으니 저걸 복사해서 넣으면 된다. 앞으로 내가 서비스를 연결하면 저 dns로 접근하면 된다.
내 인스턴스에 들어가보면 퍼블릭 dns라고 나와있으니 저걸 복사해서 넣으면 된다. 앞으로 내가 서비스를 연결하면 저 dns로 접근하면 된다.
저렇게 하면 현재 키페어의 권한이 너무 오픈되어있다고 빠꾸먹인다. 입력해주고 다시 ssh -i blahblah 해주면 이번에는 접속이 잘 된다.
입력해주고 다시 ssh -i blahblah 해주면 이번에는 접속이 잘 된다.
이러면 내 터미널에서 생성해준 ec2 인스턴스에 접근 완료 됐다.
인스턴스에 파일 생성
해당 도메인에서 내가만든 서비스를 제공하려면 클라이언트 파일이나 서버파일, db파일 등을 필요에 따라서 넣어줘야한다.
터미널에서 하나씩 명령어로 입력 할 수도 있으나 보기 쉽게 GUI환경을 제공하는 filezilla를 이용한다. 구글에 검색해서 접속한 후 자신의 운영체제에 맞는 파일을 다운받으면 된다. 나는 macOS intel전용을 다운받았다. 실행해보면 이런 모습이다.
실행해보면 이런 모습이다.
filezilla도 EC2와 연결시켜줘야 한다.
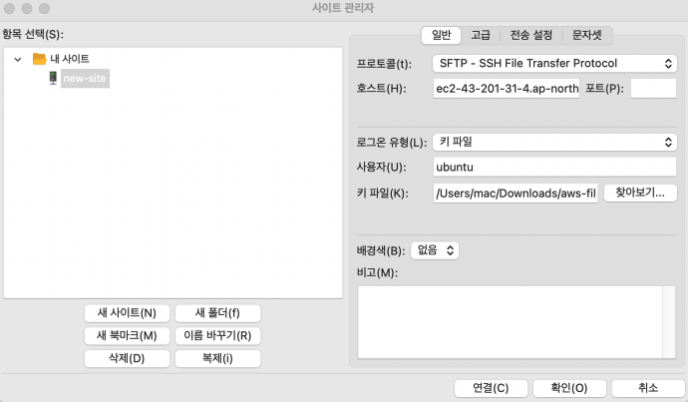 맨 왼쪽의 본체모양버튼을 누르고 필요에 따라서 입력 후 확인을 누르면 된다. 나는 위에 되어있는 설정대로 했다. 사용자가 ubuntu인 이유는 처음에 연결 할 때 터미널에서
맨 왼쪽의 본체모양버튼을 누르고 필요에 따라서 입력 후 확인을 누르면 된다. 나는 위에 되어있는 설정대로 했다. 사용자가 ubuntu인 이유는 처음에 연결 할 때 터미널에서 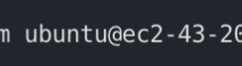 이렇게 입력해줬기 때문이다. -> 한번더 확인 -> 다시 본체버튼 누르고 -> 연결 -> 확인 (강사님은 이렇게 했는데 그냥 연결 해도 되지 않나 싶다.)
이렇게 입력해줬기 때문이다. -> 한번더 확인 -> 다시 본체버튼 누르고 -> 연결 -> 확인 (강사님은 이렇게 했는데 그냥 연결 해도 되지 않나 싶다.)
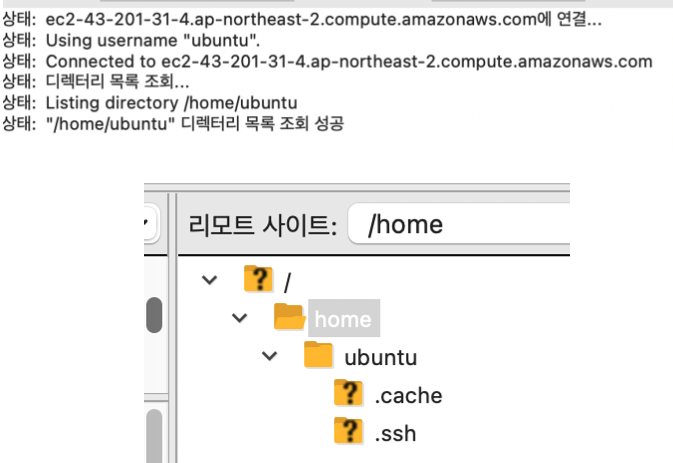 쫘라란~! 그러면 현재 ec2 컴퓨터의 디렉토리 상태를 보여준다. 내가 생성한 ec2 인스턴스의 컴퓨터안은 저렇게 구성되어 있는 것이다.
쫘라란~! 그러면 현재 ec2 컴퓨터의 디렉토리 상태를 보여준다. 내가 생성한 ec2 인스턴스의 컴퓨터안은 저렇게 구성되어 있는 것이다.
이제 여기에 서비스할 파일들을 넣어주면 된다.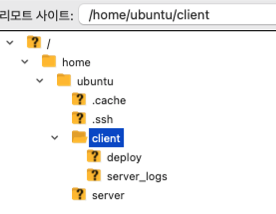 내가 실습에서 배포할 서비스는, 프론트는 리액트로 만들고 서버는 node.js, db는 따로 파일을 만들지는 않고 mongo atlas(이것도 클라우드로 인터넷을 통해서 api로 접근해서 사용한다.)를 이용한다.
내가 실습에서 배포할 서비스는, 프론트는 리액트로 만들고 서버는 node.js, db는 따로 파일을 만들지는 않고 mongo atlas(이것도 클라우드로 인터넷을 통해서 api로 접근해서 사용한다.)를 이용한다.
그래서 위와 같이 폴더를 구성한다. 우클릭해서 그냥 폴더 생성하면 된다. 클라이언트에서 배포할 내용은 npm run build 한 후에 생성되는 것들을 deploy폴더에 넣어주면 되고, server 관련된 것들은 server_logs에 넣어줄 것이다.
Nginx 설치
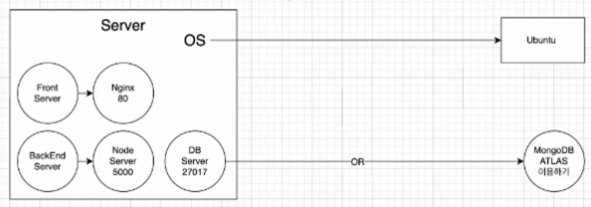
위 이미지대로, 프론트도 서버가 필요하다. 요청을 보내면 정적인 파일들을 제공하는 개발 환경의 서버가 존재한다.
프론트의 서버는 리액트에서 제공하는 기능처럼 어떤 값들을 바로 코드로 입력했을 때 그것을 화면에 바로 그리는 것과 같은 핫 리로드기능이 있다.
그런데 운영체제단계에서는 이런 기능은 필요가 없고 자료만 제공을 해주면 되고, 그것에 좀 더 최적화 되어있는 기능의 서버가 nginx라고 한다.
강사님이 이렇게 말하셨는데 잘 이해가 안된다.
with Chat GPT
NGINX는 프론트엔드 서버뿐만 아니라 다양한 역할을 수행할 수 있습니다. 여기 몇 가지 주요 기능을 설명합니다:
웹 서버(Web Server): 정적 콘텐츠(HTML, CSS, JS, 이미지 등)를 클라이언트에게 제공하는 역할을 합니다. 아파치와 비슷하게 HTTP 요청을 처리합니다.
리버스 프록시(Reverse Proxy): 클라이언트 요청을 다른 서버로 전달하는 역할을 합니다. 이렇게 하면 NGINX가 트래픽을 여러 서버로 분산시키거나 백엔드 서버를 보호하는 데 도움이 됩니다.
대충 보통 웹 서버로 사용을 할 수 있다는 의미인것 같다. 만약에 누군가 어떤 사이트를 경로를 통해서 접근하면 그때 필요한 정적 파일들이나 이미지를 브라우저에서 서버로 요청을 보내게 되고, nginx가 그것을 전달한다. 또 프록시 역할을 한다는 것은 클라이언트의 요청을 다른 서버(현재는 node.js)로 전달하는 역할을 한다. 정적인 파일 요청은 nginx가 직접 처리하고, api 요청이나 동적 콘텐츠 요청은 nginx가 백엔드 서버(node.js)로 전달한다.
암튼 그래서 클라이언트 서버로 Nginx를 사용할거고, 일단 설치부터 해야한다.
-
일단 시스템을 업데이트 해준다.
 (강사님은 설명 안해주셨는데 찾아보니 최신 소프트웨어와 보안 업데이트를 위해서 주기적으로 한다는 것 같다.)
(강사님은 설명 안해주셨는데 찾아보니 최신 소프트웨어와 보안 업데이트를 위해서 주기적으로 한다는 것 같다.) -
nginx를 설치한다.

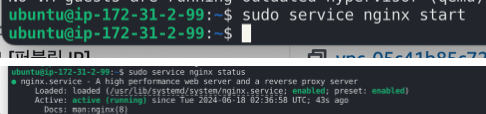 start 하고나서 status를 확인하면 running중인 것을 볼 수 있다. 컨트롤 C 해서 나오면 된다!
start 하고나서 status를 확인하면 running중인 것을 볼 수 있다. 컨트롤 C 해서 나오면 된다! -
nginx를 사용하려면 설정을 해줘야 한다. 아까 말한것처럼 정적파일을 제공하고, 프록시 역할을 해야하는데 그것들을 설정해줘야한다.
// 1 번 user ubuntu; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; client_body_buffer_size 100k; client_header_buffer_size 1k; client_max_body_size 100k; large_client_header_buffers 2 1k; client_body_timeout 10; client_header_timeout 10; keepalive_timeout 5 5; send_timeout 10; server_tokens off; #gzip on; on; include /etc/nginx/conf.d/*.conf; }// 2번 server { #listen 80; listen 80 default_server; listen [::]:80 default_server; server_name yourdomain.com; access_log /home/ubuntu/client/server_logs/host.access.log main; location / { root /home/ubuntu/client/deploy; index index.html index.htm; try_files $uri /index.html; add_header X-Frame-Options SAMEORIGIN; add_header X-Content-Type-Options nosniff; add_header X-XSS-Protection "1; mode=block"; add_header Strict-Transport-Security "max-age=31536000; includeSubdomains;"; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } server_tokens off; location ~ /\.ht { deny all; } }작성 방법이 따로 있겠지만, 일단 그런건 알려주지않았고(나도 따로 찾아보지 않았다) 강사님께서 제공해주신 코드를 받아왔다.
1번이 정적파일제공, 2번이 프록시 설정이다. - 1번설정 : nginx가 설치되고 설정파일이 있는 경로로 접근한다. 위에 마지막 부분은 잘못됐다. 관리자 권한으로 접근해야 한다.
- 1번설정 : nginx가 설치되고 설정파일이 있는 경로로 접근한다. 위에 마지막 부분은 잘못됐다. 관리자 권한으로 접근해야 한다.
sudo vi nginx.conf-> 들어가지면 d를 꾹 눌러서 원래 있던 설정은 다 지우고 1번을 붙여넣기한다. -> 쉬프트+; -> wq! -> 엔터
 - 2번 설정 : 이번에는 다른 경로로 접근한다. touch는 생성이다. conf.d로 이동해서 default.conf를 생성하고
- 2번 설정 : 이번에는 다른 경로로 접근한다. touch는 생성이다. conf.d로 이동해서 default.conf를 생성하고 sudo vi default.conf해서 편집모드로 들어간다. -> 2번 붙여넣기 -> 쉬프트+; -> wq! ->엔터
(vi 편집 모드에서 편집을 하고 싶을 때는 i를 누르고 원하는 부분을 수정한 후에 esc를 누르고 wq하면 된다. = 작성완료 후 수정)
대충 2번 파일은 로그는 아까 만들어준 server_logs폴더에 들어갈거고 위치는 /이고, 루트로 접근이 오면 엔지닉스가 파일을 찾는데 deploy폴더에서 찾을꺼고, 그 안에는 index.html이 있을거고, 그게 기본 파일이고, try_files는 리액트가 spa이다 보니 페이지 이동을 할때도 다 index.html을 보여줘야한다는 것이다. 그 아래 add부분은 보안부분이다.설정을 다 했으면 이제 nginx를 재실행 해야한다.
sudo service nginx restart
node.js 설치
서버도 설치해줘야 한다.  그러면 설치는 끝! 디비는 몽고디비 아틀라스 클라우드 서비스를 이용할거라서 설치할 필요는 없고 그냥 클러스터 생성 후 연결만 해주면 된다.
그러면 설치는 끝! 디비는 몽고디비 아틀라스 클라우드 서비스를 이용할거라서 설치할 필요는 없고 그냥 클러스터 생성 후 연결만 해주면 된다.
지금 위에 하는것들은 모냐면 내 ec2 컴퓨터에 설치하고 있는거다! 그 컴퓨터를 지금 내가 사용하는 컴퓨터처럼 인터넷을 켜서 일일이 설치해줄 수 없으니까 터미널을 통해서 접속하고 거기에 필요한 것들을 넣어준 것이다.
몽고 db 사용하기
몽고디비는 여러번 사용해봤는데.. 한번 더 정리해보자
- 새 프로젝트 생성 -> 클러스터 페이지에서 create
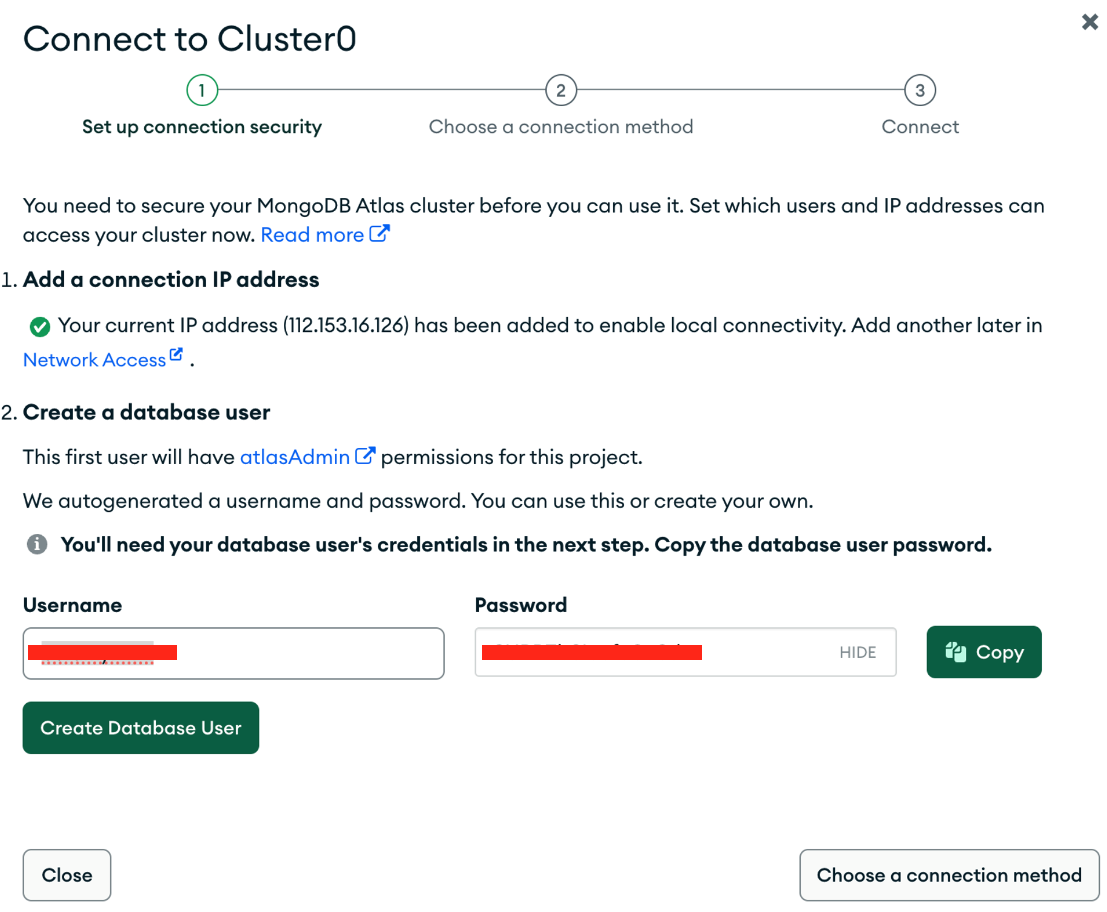 username과 비밀번호는 반드시 저장해둘것
username과 비밀번호는 반드시 저장해둘것 - 네트워크 엑세스 설정 : 어디에서 접근 가능하게 할것인가?
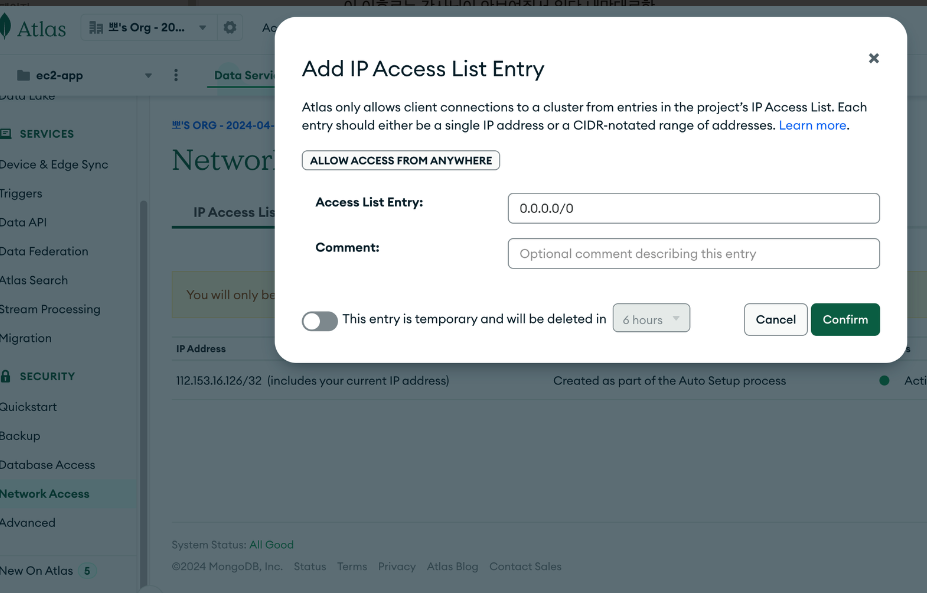 어디서든 접근 가능! 0.0.0.0/0
어디서든 접근 가능! 0.0.0.0/0 - db -> connect -> drivers
 이 코드를 복사해서 서버파일에서 디비와 연결하는 부분에 넣어주면 된다.
이 코드를 복사해서 서버파일에서 디비와 연결하는 부분에 넣어주면 된다.
 그러면 서버에서 몽고디비와 연결해서 데이터를 저장하고 불러온다.
그러면 서버에서 몽고디비와 연결해서 데이터를 저장하고 불러온다.
소스코드를 EC2 컴퓨터에 넣기
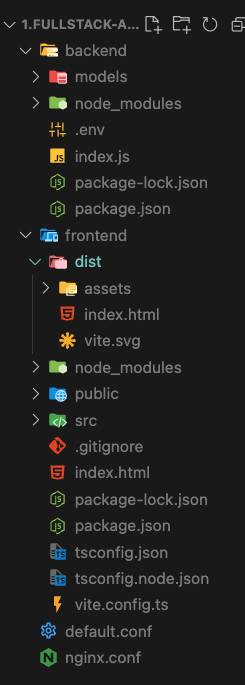 서비스는 이렇게 만들어져있다. frontend 부분과 server 부분이 따로 생성되어 있다. 아까 말한것처럼 프론트는 리액트, server는 nodejs+express로 작성되어있다.
서비스는 이렇게 만들어져있다. frontend 부분과 server 부분이 따로 생성되어 있다. 아까 말한것처럼 프론트는 리액트, server는 nodejs+express로 작성되어있다.
프론트에서는 배포한 파일을 deploy에 넣어야 함으로 npm run build한다.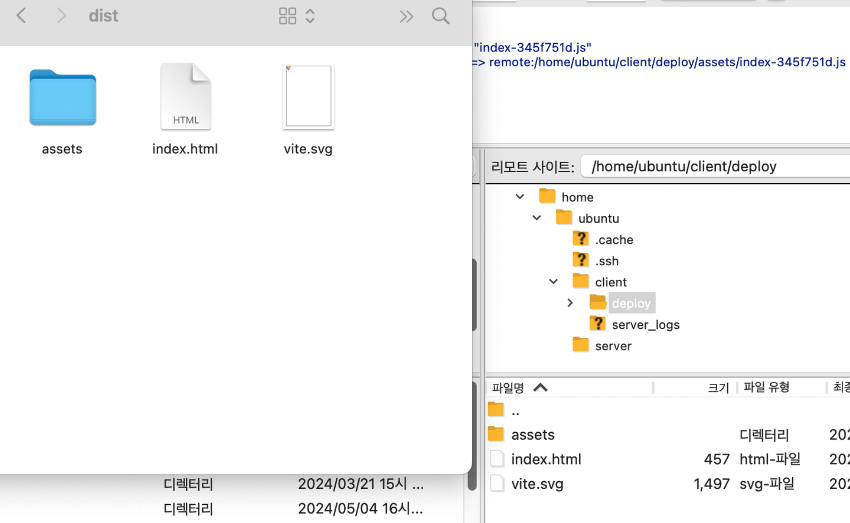
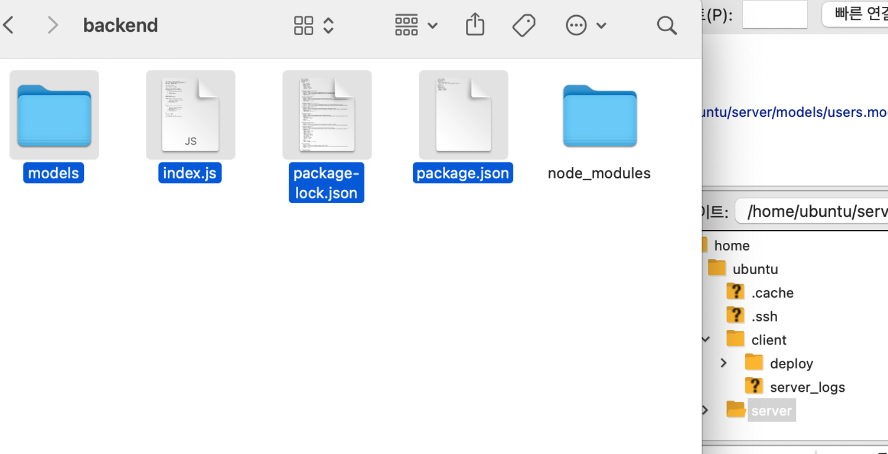 넣는 방법은 간단한데, 그냥 필요한 파일들을 긁어서 마우스로 이동시켜서 넣어주면 된다. GUIㅇ니까!@ 서버파일중에 node_modules는 안넣었다. 그래서 직접 ec2컴퓨터에서 설치해줘야한다.
넣는 방법은 간단한데, 그냥 필요한 파일들을 긁어서 마우스로 이동시켜서 넣어주면 된다. GUIㅇ니까!@ 서버파일중에 node_modules는 안넣었다. 그래서 직접 ec2컴퓨터에서 설치해줘야한다.
npm도 프로그램이니까 사용하려면 설치를 먼저 해줘야한다.
터미널로 와서 sudo apt install npm -> npm install 하면 엄청나게 많은 것들을 설치하려고 꽤 걸린다. .env도 따로 만들어 줘야한다. 왜냐면 깃이그노어에서 숨겨져있기 때문에 옮길때 들어가지 않았다. 그래서 위처럼 입력하고 파일을 생성한 후에 아까 .env에 있던거 넣고 그대로 wq!해서 나오면 된다.
.env도 따로 만들어 줘야한다. 왜냐면 깃이그노어에서 숨겨져있기 때문에 옮길때 들어가지 않았다. 그래서 위처럼 입력하고 파일을 생성한 후에 아까 .env에 있던거 넣고 그대로 wq!해서 나오면 된다.
클라이언트 부분은 따로 실행해줄게 없다. dist 파일들만 넣었으니까.
이러면 필요한 파일 설치하고 넣어주는건 끝났다.
이제 서버를 실행해주면 된다. 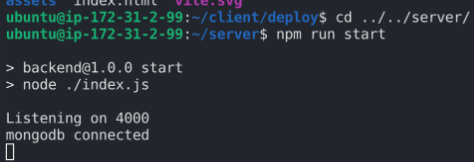 ec2 컴퓨터에서 실행해야 하니까 터미널로 가서 npm run start 해주면 실행되고 연결도 잘 됐다.
ec2 컴퓨터에서 실행해야 하니까 터미널로 가서 npm run start 해주면 실행되고 연결도 잘 됐다.
아직 더 설정해야 할게 있는데, 방화벽을 열여줘야한다. 위~~에서 각각 서버들을 어디서 열지 포트가 다 적혀있었고, 보안설정도 공부했다. 그 보안설정을 해줘야한다.
보안그룹 생성하기
aws 웹사이트에 접속해서 만들어준 ec2 인스턴스로 간다. 아래로 내려보면 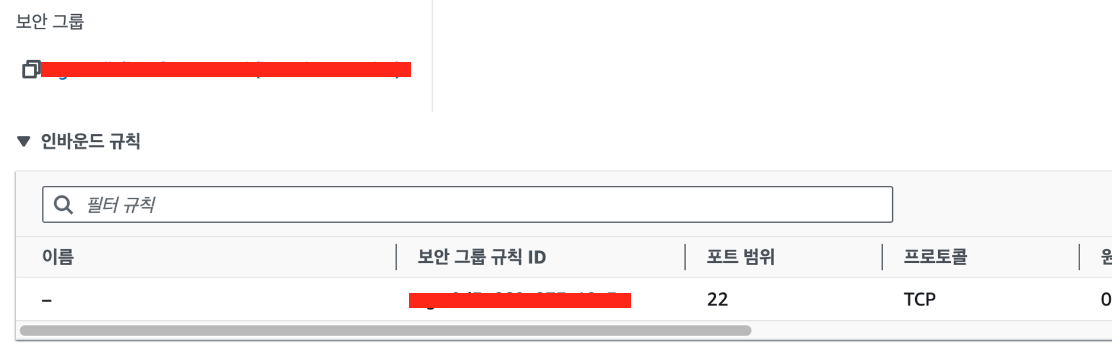 자동으로 생성되어 있는 보안그룹만 존재한다. 아까 위~~~에서 nginx는 80번 포트,
자동으로 생성되어 있는 보안그룹만 존재한다. 아까 위~~~에서 nginx는 80번 포트, 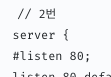
서버는 4000번 포트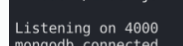
에서 열었다. 그걸 추가해야한다. 보안 그룹이라고 적혀있는 탭 바로 밑에꺼를 클릭하고 인바운드 규칙 편집을 누른다.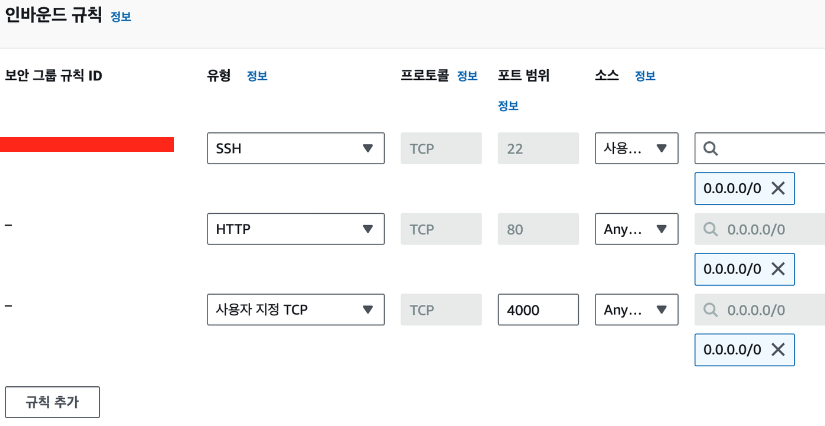 규칙 추가를 눌러서 각각 추가해주고 규칙 저장하면 된다. 이제 아까 dns로 접근하면(근데 서버를 내가 열어두지 않으면 추가하고 불러오고 이런건 안된다 ㅇㅅㅇ! 공부 다하고 터미널을 껏더니 안되더라!)
규칙 추가를 눌러서 각각 추가해주고 규칙 저장하면 된다. 이제 아까 dns로 접근하면(근데 서버를 내가 열어두지 않으면 추가하고 불러오고 이런건 안된다 ㅇㅅㅇ! 공부 다하고 터미널을 껏더니 안되더라!) 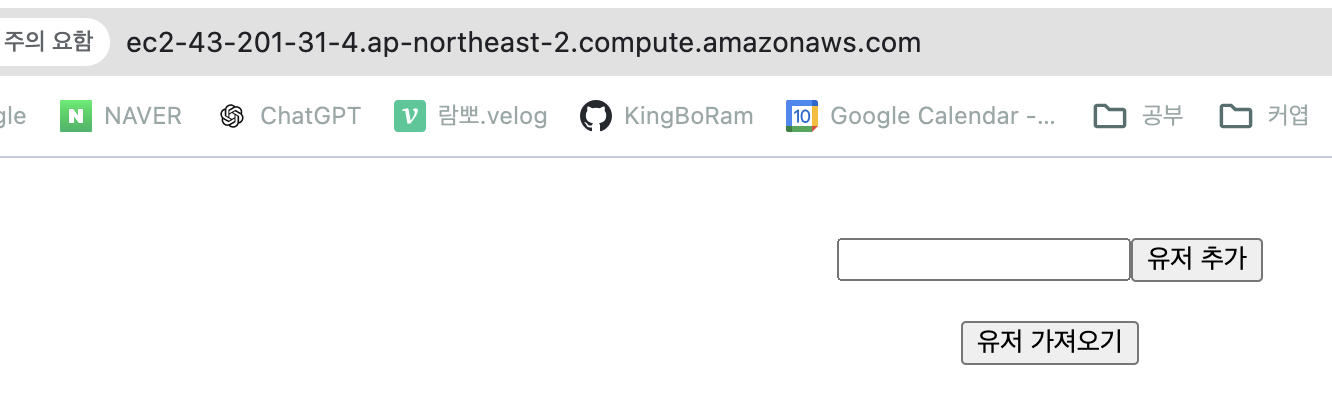 만들어준 서비스가 잘 제공이 된다 ^_^
만들어준 서비스가 잘 제공이 된다 ^_^
여기서 근데 서버랑 디비에 연결이 잘 안되는데, 강의에서 제공해주신 코드다 보니까 요청을 보내는 url이 잘못되어잇어서 그렇다. 내 dns를 넣고 4000번 포트라는것도 넣어주고, build도 다시 해주고~~
강의에서 제공해주신 코드다 보니까 요청을 보내는 url이 잘못되어잇어서 그렇다. 내 dns를 넣고 4000번 포트라는것도 넣어주고, build도 다시 해주고~~  ec2에도 다시 넣어준다. (덮어쓰기 하면 된다) 이후에 강력새로고침 한방 해주면
ec2에도 다시 넣어준다. (덮어쓰기 하면 된다) 이후에 강력새로고침 한방 해주면 등록한 데이터를 잘 불러오기까지 한다.
등록한 데이터를 잘 불러오기까지 한다.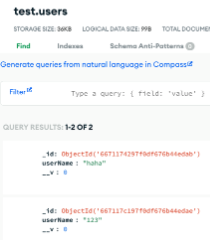 디비에도 잘 저장이 되어있다.
디비에도 잘 저장이 되어있다.
S3
배포를 할 수 있는 방법은 아주 많다. 오늘은 S3로 배포를 해본다.
-
배포 : 이때까지 자연스럽게 배포라는 단어를 썼는데, 라이브 강의에서 배포라는게 무엇이냐에 대한 설명을 들었다.
보통 작업을 할 때 localhost에서 파일을 열고 확인을 한다. 그런데 이건 내 컴퓨터 속의 환경이기 때문에, 다른 사용자들이 인터넷을 통해서 접근 할 수 있게 만드는 것을 배포한다라고 표현한다.
우리가 만든 웹 페이지나 서버가 다른사람들이 사용 할 수 있게 하려면 인터넷 상에 배포가 되어 있어야 한다. -
배포를 할 수 있는 방법은 매우 많다. aws도 그중에 하나일 뿐이다. 그렇다면 왜 aws를 사용할까? aws는 '개발'에 필요한 아주 다양한 서비스를 제공한다. 데이터를 저장하거나, 파일을 분리하거나, ai 관련 작업을 제공하거나 등등..
-
s3는 쉽게 말하면 파일 저장 서비스다. 사진을 구글드라이브 같은 곳에 저장하는거랑 똑같다. s3도 이렇게 파일을 저장 할 수 있는 서비스이다. 그럼 왜 구글드라이브가 아니라 s3를 쓸까? 개발에 필요한 더 많은 기능들이 추가되어있고 제공하기 때문이다.
 aws에 s3를 검색해서 나오는 이 설명이 결국 파일을 저장 할 수 있게 해주겠다~ 라는 뜻이다.
aws에 s3를 검색해서 나오는 이 설명이 결국 파일을 저장 할 수 있게 해주겠다~ 라는 뜻이다. -
naver.com에 접속했다고 예시를 들어보자. 그러면 보통 사용자들은 내가 어딘가에 들어갔다라는 느낌을 받는다. 사실은 그렇지 않다. 어딘가에 접속을 하면 서버컴퓨터에서 내 브라우저로 화면을 띄우는데 필요한 html, css, js파일들을 보내게 되고, 브라우저는 그것을 해석해서 화면에 그린다. 사용자는 파일을 제공하는 공간으로 들어가는게 아니라, 파일을 다운받아서 사용하는거다.
-
아까 s3는 파일을 저장하는 곳이라고 했고, 사용자는 파일을 다운받아야 한다고 했다. 이때 사용자가 파일을 다운받을 수 있도록 제공하는 것이 s3가 되는 것이다. 거기에다가 추가로 어떤 유저들이 파일을 다운 받을 수 있는지 권한도 설정 할 수 있고 어떤 파일을 다운받게 할지, 또 누군가는 수정의 권한도 줄지 등을 aws를 이용하면 모두 설정 할 수 있다. 이것이 일반적인 파일 클라우드와의 차이점이다.
-
그런데 우리는 aws로 배포를 한다고 했다. 특히 s3를 사용할거다. 파일 저장 시스템인데 어떻게 배포를 할 수 있을까? s3에서 부가적인 기능으로 배포를 제공하기 때문이다. 이것도 일반적인 파일 클라우드와 다른 점이다. 즉 s3의 부가적인 기능이 '정적 웹 사이트 호스팅' 기능이다. 쉽게 표현하면 웹 서비스를 다른사람들도 쓸 수 있게 인터넷에 배포하는게 호스팅이다. s3에 올린것 자체를 배포라고 표현한다면, 그것을 남들도 사용 할 수 있게 하는게 호스팅이라고 구분 할 수 있다.
-
여기서 '정적'이라는 표현을 쓴다. 정적인 웹사이트가 아니라면 s3로 배포를 못 할수도 있다. s3는 정적 웹사이트를 배포하는 서비스이기 때문이다. 간단하게 설명하면 리액트에서 우리가 서비스를 제공할때 개발환경에서 사용한 파일을 그대로 올리지 않고 npm run build해서 생겨나는 build폴더나 dist폴더를 이용해서 배포를 한다. 이 파일들이 정적파일이고, 그 파일을 호스팅 하기 때문에 정적 웹 사이트 호스팅이다.
-
즉, 이미 결과물이 다 만들어져있고 그것을 제공하는 경우에 정적인 웹사이트라고 부른다. 사용자에게 제공되는 파일들은 변경되지 않으며, 요청이 있을 때마다 같은 파일을 제공한다. 즉 서버와의 통신이 없다. 반대로 동적인 웹사이트들은, 요청이 오면 서버(서버는 또 db)와 통신을 해서 그때그때 다른 결과물을 사용자에게 제공한다.
-
아까 위에서 s3를 사용할 때 동적인 웹사이트는 배포하지 못할수도 있다고 했다. 그건 못한다는게 아니라 다른 기능들이 추가로 필요하다는 뜻이지 아예 못한다는게 아니다. 예를들어 프론트앤드는 s3에서 배포하고, 백엔드는 ec2에 배포해서 API를 통해 동적 콘텐츠를 제공하는 방식 호스팅 되게 할 수 있다.
Cloud Front
-
s3가 저장소라면, cloud front는 그것을 빠르게 유저에게 전송 할 수 있는 시스템이다.
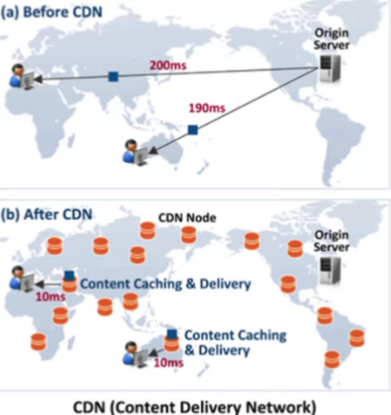
-
위 이미지를 예시로 들어보면, origin s3서버는 하나만 존재한다. 속도는 거리에 비례하니까 먼 지역일수록 파일을 다운받는 속도가 느려질 수 밖에 없다. -> 느려지면 문제는? 유저의 이탈
-
그래서 파일을 빠르게 제공하는것이 중요하고, 그것을 방지하기 위해서 cloud front를 사용한다. 그것이 아래있는 (b)이미지다. s3에 저장된 원본 파일을 여러 장소에 복사해두는 것이다. 이 임시 저장소들을 각 나라에 설치해두고 필요할 때 근처에 있는 임시저장소에서 자료를 받으면 멀리서 다운받을 필요가 없어서 속도의 저하를 방지 할 수 있다.
-
이것이 '캐싱caching'이라는 개념이다. 캐싱은 어떻게 보면 cloud front보다 중요한 개념이다. 아까 배포를 설명했던 것처럼 자연스럽게 쓰고 있지만 확실한 개념은 모르고 사용해왔다. 속도를 끌어올리는 작업에는 모두 캐싱이 들어간다. 뜻만 알고 과정을 몰라서는 안된다. 아까 설명한 그대로가 캐싱이다. 멀리 있는 원본 저장소에서 데이터를 받아오는게 느리기 때문에, 그걸 복사해서 빠르게 가져 올 수 있는 임시 저장소에 저장을 해두는거다.
-
캐싱의 장점은 성능을 개선시켜서 빠른 속도를 보장한다는 것이고, 단점은 실시간으로 동기화가 되지 않는다는 점이다. 보통 원본데이터를 특정 주기마다 복사해서 가져오도록 동작하기 때문에, 실시간으로 어떤 기능을 업데이트 했어도 사용자는 여전히 구버전을 사용하고 있을 수 있다.
-
다시 cloud front의 이야기로 돌아와서, 이렇게 세계 곳곳에 임시 저장소를 구축한 형태의 서비스를 CDN content delivery network라고 한다. 그래서 cloud front는 CDN 서비스라고도 한다.
-
그럼 이런 의문이 들 수 있다. 내가 s3로도 충분히 빠르면 cloud front는 안써도 되는건가? 아니다. s3는 https를 지원하지 않는다. https는 통신에 보안을 더한 개념이다. 이것은 개발을 하지 않는 인터넷 유저들도 아는 내용으로, 만약에 현재 내 어플리케이션이 https를 제공하지 않고 그것이 주소창에 보이면 유저는 해킹과 같은 공격을 걱정하게 될 수 있고 그것은 유저 이탈로 이어질 수 있다.
-
cloud front는 https를 제공한다. 왜 s3는 안되고 cloud front는 되느냐 하는것은 좀 더 딥한 이야기가 들어가게 된다. 지금은 일단 그렇게 알고 넘어가도록 하자.
-
추가로 취준생이라면 더 솔깃한 정보는.. 수많은 회사에서 이미 s3와 cloud front를 사용하고 있다. 그 회사들에 들어가고 싶은 나는 이걸 어떻게 써야하는지 무엇인지를 당연히 파악하고 있어야 한다.
사용
개념을 알고 있으면 배포를 직접 해보는건 super easy다. 일단 현재 앱을 build한다.
- build를 하는 이유는 기존의 개발에 사용한 프로젝트코드는 비효율적이기 때문이다. 공백도 많고, 줄바꿈도 많고 파일도 여러가지고.. 그것들을 하나로 압축해서 배포하기 좋은 형태로 바꾸는 것이 build 작업이다. cra는 build폴더가 생길거고, vite는 dist폴더가 생길거다. 이것이 배포에 사용되는 정적 파일들이다. (만들어 놓은 데로 정보를 제공한다.)
S3 생성과 설정
-
aws s3로 배포를 하다보면 옵션이 정
말 많다. 언젠가 모두 알고 잘 쓰게 될 수 있으면 좋겠지만, 우선순위도 중요하다. 지금은 필수로 알아야 할 정보들을 우선적으로 습득하고 필요 할 때마다 정보를 덧그려보자. -
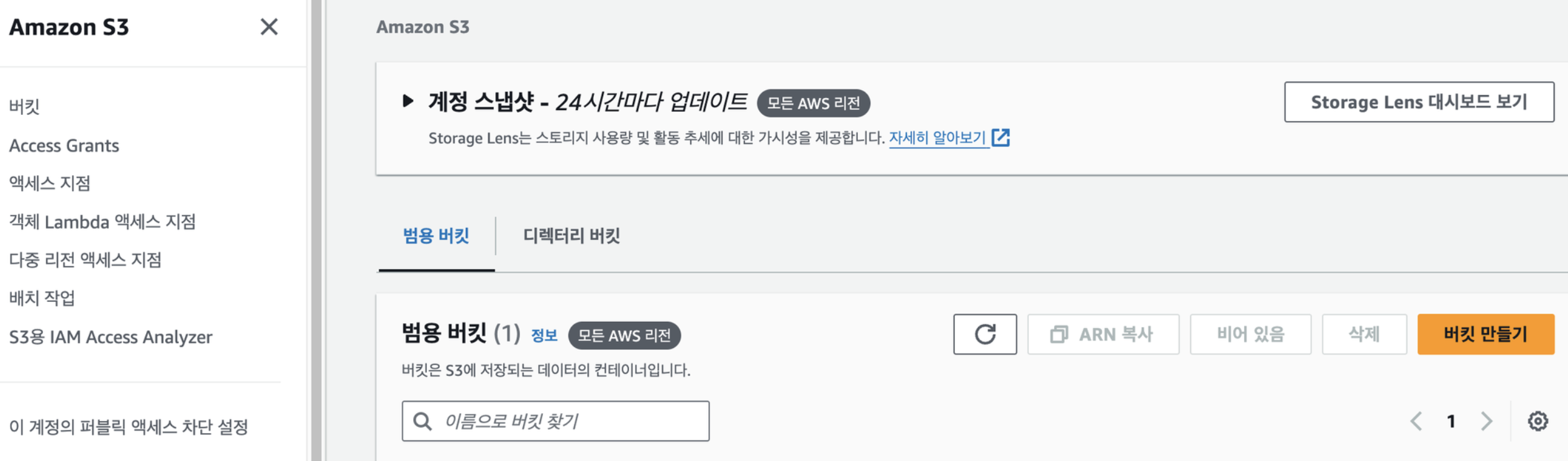 aws에 가입하고 s3를 검색해서 들어가보면 위와 같이 나온다. 여기서 버킷이란 저장소에 붙은 이름이라고 생각하면 된다. 깃허브에서 저장소의 이름을 repository라고 부르는것처럼 s3에서는 버킷이라고 부를 뿐이다. 버킷을 만들고, 버킷 키는 비활성화로 바꾸고, 이름을 설정하고, 서울로 지역을 설정하고 버킷을 만든다. 여기서 버킷 버전 관리라는 건 말그대로 버전을 말한다. s3는 파일을 안에 넣으면 덮어쓰기를 안해주고 아예 없애버리고 새로운걸로 배포를 해준다. 그렇게 안하고 버전을 관리하겠냐는 설정값이다.
aws에 가입하고 s3를 검색해서 들어가보면 위와 같이 나온다. 여기서 버킷이란 저장소에 붙은 이름이라고 생각하면 된다. 깃허브에서 저장소의 이름을 repository라고 부르는것처럼 s3에서는 버킷이라고 부를 뿐이다. 버킷을 만들고, 버킷 키는 비활성화로 바꾸고, 이름을 설정하고, 서울로 지역을 설정하고 버킷을 만든다. 여기서 버킷 버전 관리라는 건 말그대로 버전을 말한다. s3는 파일을 안에 넣으면 덮어쓰기를 안해주고 아예 없애버리고 새로운걸로 배포를 해준다. 그렇게 안하고 버전을 관리하겠냐는 설정값이다. -
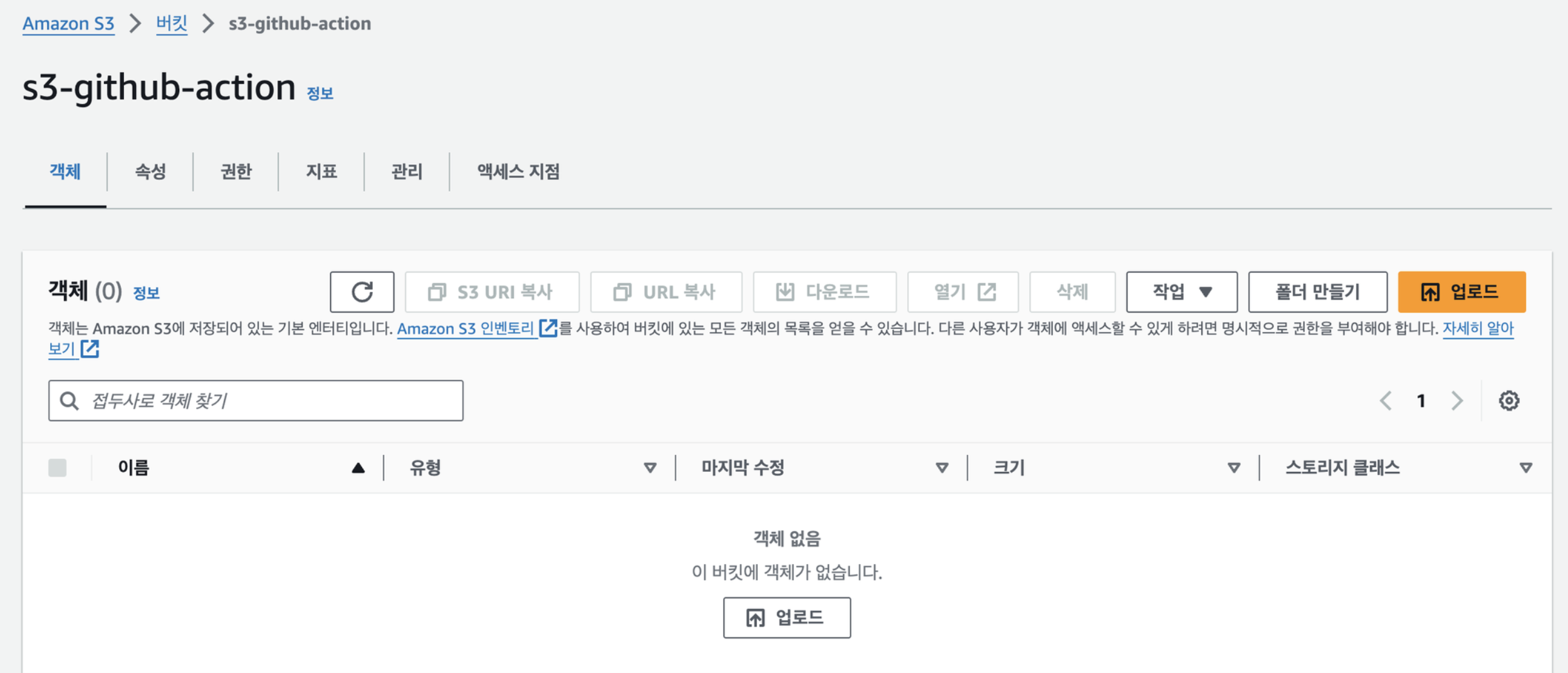 그러면 이런 화면이 뜬다. 여기서 객체란 s3에 저장된 파일 자체를 객체라고 부른다.
그러면 이런 화면이 뜬다. 여기서 객체란 s3에 저장된 파일 자체를 객체라고 부른다. -
우리의 목적은 여기에 배포를 하고 호스팅을 하는거다. 아까 배포는 s3의 부가기능이라고 말했다. 그렇기 때문에 따로 설정을 해줘야 한다.
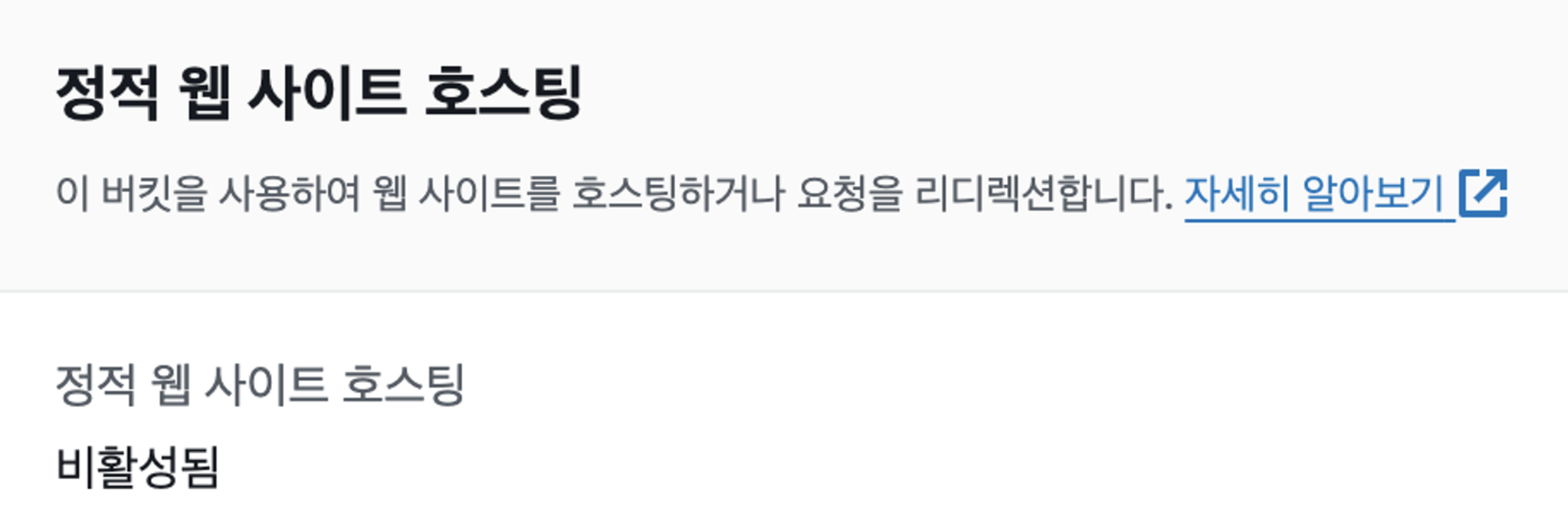 속성탭으로 이동해서 스크롤을 해보면 이렇게 비활성화가 되어있다. 편집 -> 활성화 -> 인덱스 문서에 index.html을 넣고 저장을 누른다.
속성탭으로 이동해서 스크롤을 해보면 이렇게 비활성화가 되어있다. 편집 -> 활성화 -> 인덱스 문서에 index.html을 넣고 저장을 누른다. 그러면 이렇게 도메인을 생성해준다. 이 상태에서 접근하면 403 오류가 뜬다. 권한이 없기 때문이다.
그러면 이렇게 도메인을 생성해준다. 이 상태에서 접근하면 403 오류가 뜬다. 권한이 없기 때문이다. -
s3를 설명 할 때, 이 파일을 누가 접근해서 다운받을 수 있게 할지 권한같은걸 설정 할 수 있다고 했다. 처음에는 그러한 보안 설정이 모두 잠겨있기 때문에, 하나씩 필요에 따라서 풀어주는 작업이 필요하다.
 권한 탭으로 이동해서 퍼블릭 엑세스 차단 설정부분에 편집을 누르고 모두 해제한 후에 저장을 한다. 이름 그대로 현재 내가 배포하는 앱에 다른 외부 사람들도 접근할 수 있게 설정하는 것이다.
권한 탭으로 이동해서 퍼블릭 엑세스 차단 설정부분에 편집을 누르고 모두 해제한 후에 저장을 한다. 이름 그대로 현재 내가 배포하는 앱에 다른 외부 사람들도 접근할 수 있게 설정하는 것이다. -
위는 접근 권한만 설정해준거고 누가 파일을 다운받아 가게 할 것인가, 또 어떤 파일을 받아가야 하는가, 그 파일은 어디에서 제공하는가를 추가로 설정해야 한다. 그것이 버킷정책이다.
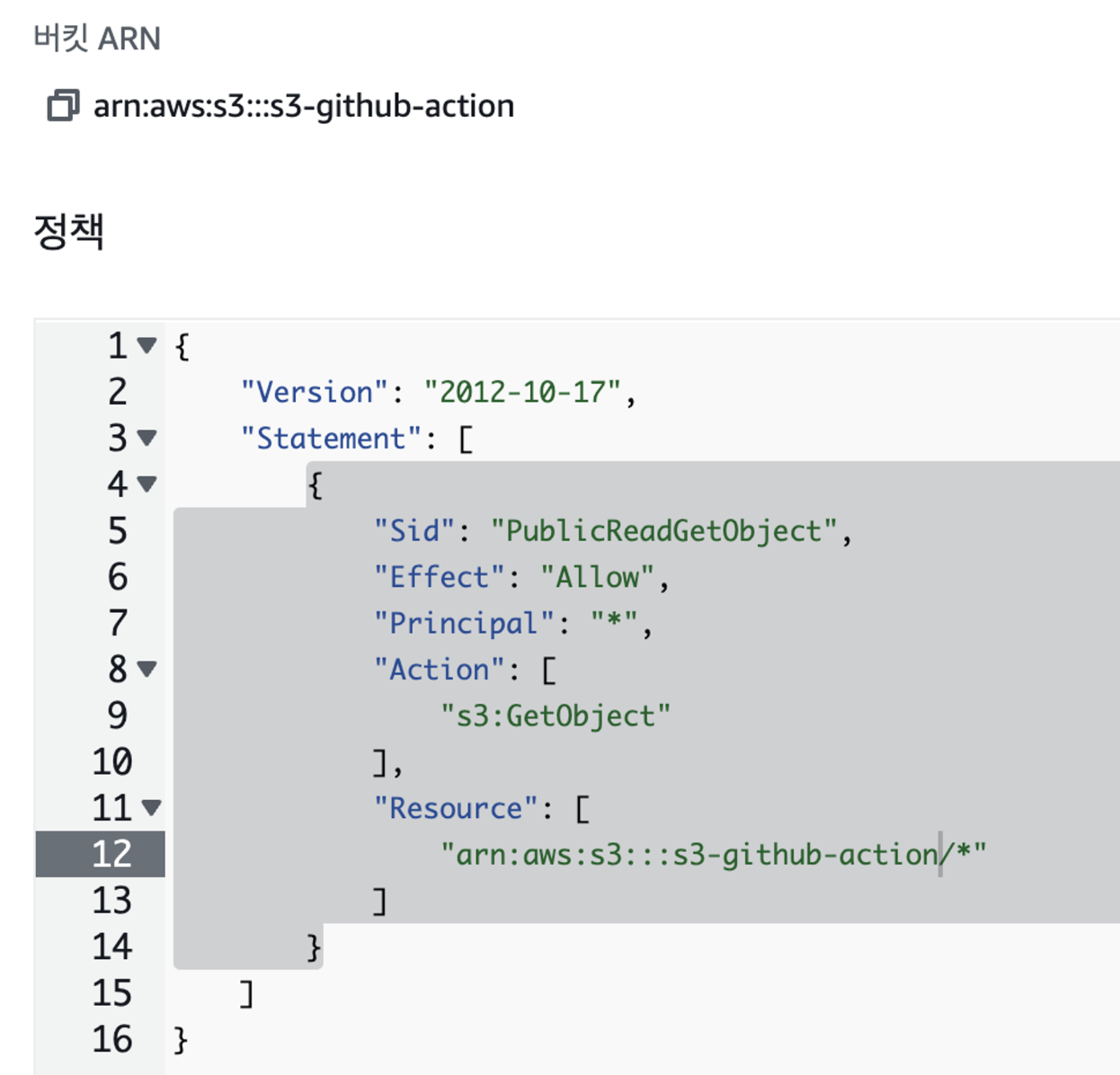 이 파일을 하나씩 분석해보자. 모든 것을 알 필요는 없지만 뜻을 어느정도 파악하고 있으면 활용도 할 수 있다.
이 파일을 하나씩 분석해보자. 모든 것을 알 필요는 없지만 뜻을 어느정도 파악하고 있으면 활용도 할 수 있다.- sid는 말 그대로 해당 파일의 id이다.
- effect는 적혀있는대로 허용할것인가 하는 부분이다. 해당 부분에 deny가 있으면 접근 할 수 없다.
- principal은 해당 권한에 대한 주체를 정하는 것이다. 누가 이 아래의 설정에 따른 기능을 사용 할 수 있게 하는 부분으로 *은 all user이다.
- action은 초반에 말햇지만 s3의 다양한 기능중에 어떤 기능을 사용할 수 있게 할거냐 라는 뜻이다. 지금 모든 유저가 아래으 기능을 사용하도록 허용했는데 막 파일을 수정하게 하면 안된다. getObject에서 오브젝트가 아까 말한것처럼 s3에 저장된 파일이니까, 파일을 다운로드만 할 수 있게 설정하는 것이다.
- 리소스는 어디에서 파일을 받아갈지이다. 내 버킷명이 들어가고 /뒷 부분은 그 중에서도 어떤 특정 파일을 받아가도록 하겠느냐 이다. *은 all
- 그래서 위 정책을 정리하면, 버킷에 존재하는 모든 파일들에 접근해서 조회 할 수 있는 기능을 모든 유저에게 허락하겠다 라는 뜻이다.
-
이것을 파악하고 있으면 위와같이 put을 넣어서 정보 수정 권한을 준다던가, deny를 한다거나 활용 할 수 있다.
-
이제 버킷에 파일을 저장하면 된다.
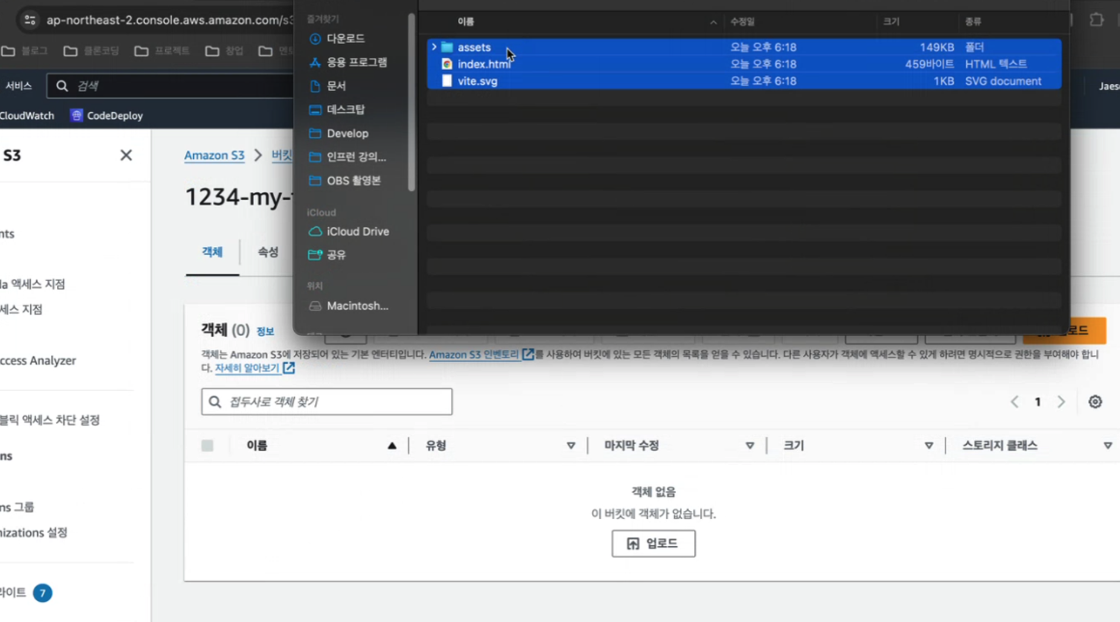 아까 말한 것처럼 정적 파일을 제공해야 하니까 dist에 존재하는 파일을 넣어주면 된다. 이 때 주의할점은 index.html이 가장 상단에 존재해야 배포가 된다. (거의 자동으로 되어있을거다)
아까 말한 것처럼 정적 파일을 제공해야 하니까 dist에 존재하는 파일을 넣어주면 된다. 이 때 주의할점은 index.html이 가장 상단에 존재해야 배포가 된다. (거의 자동으로 되어있을거다)
- 여기까지하면 이제 만들어진 앤드포인트로 접근해서 정적 웹사이트를 다운받아서 사용 할 수 있게 된다.
cloud front 생성과 설정
그런데 위 스크린샷에서 볼 수 있지만 도메인이 현재 개 못생겼다. 도메인도 좀 정리해주고, 아까 말한것처럼 https와 기타 등등의 기능을 사용하기 위해서 cloud front를 추가해보자.
-
cloud front를 검색해서 들어가고 배포생성을 누른다.
 origin domain 부분에 s3에서 생성한 도메인을 넣어주면 된다. 그러면 웹사이트 엔드포인트를 사용하라고 권장하는데 시키면 하는게 좋다. 이건 백엔드적 지식이 추가되어야 하는 부분이다.
origin domain 부분에 s3에서 생성한 도메인을 넣어주면 된다. 그러면 웹사이트 엔드포인트를 사용하라고 권장하는데 시키면 하는게 좋다. 이건 백엔드적 지식이 추가되어야 하는 부분이다. -
해당 페이지의 옵션을 설명해보자. 마찬가지로 알아야 할 것 위주로 우선 정리한다.
 뷰어에서 두번째 redirect http to https를 선택한다. 어떤 유저가 웹사이트를 방문하는데 자기도 모르게 http로 주소를 입력하고 접근 할수도 있다. 그 상태로 웹페이지를 이용하게 되면 정보가 탈취 될 수도 있다. 그것을 방지 하기 위해서 http로 접근하면 자동으로 https로 이동시켜 주는 설정이다.
뷰어에서 두번째 redirect http to https를 선택한다. 어떤 유저가 웹사이트를 방문하는데 자기도 모르게 http로 주소를 입력하고 접근 할수도 있다. 그 상태로 웹페이지를 이용하게 되면 정보가 탈취 될 수도 있다. 그것을 방지 하기 위해서 http로 접근하면 자동으로 https로 이동시켜 주는 설정이다. -
캐싱에 대한 부분은 알면 좋지만 우선순위에서 조금 밀어둔다. 추후에 공부해보도록 하자.
-
방화벽 부분은 필수적인 보안은 아니다. 설정 안해도 해킹 안됨으로 보안 보호 비활성화를 선택한다. 선택하면 추가요금
-
origin shield는 캐시적중률 향상, 오리진 로드 감소, 네트워크 성능을 향상시켜주는 옵션이다. 즉 클라우드 프론트의 기능을 향상시켜주는 옵션이다. 예를 선택하면 그 아래 지역을 서울로 하면 되는데..나는 아니오 했다. 추가 기능 결제 무섭다.
-
 가격 분류는 적혀있는 그대로 엣지로케이션 = CDN = 임시저장소에 어디까지 너의 파일을 복사할래? 라는거다. 왜냐하면 더 많은 엣지로케이션에 파일을 뿌려야 할수록 aws에서도 비용이 나가는 부분이기 때문에 추가결제가 필요하다. 그래서 지금 내 앱이 어디서 서비스 되면 좋을지를 판단해서 선택하면 된다. 나는 아시아!
가격 분류는 적혀있는 그대로 엣지로케이션 = CDN = 임시저장소에 어디까지 너의 파일을 복사할래? 라는거다. 왜냐하면 더 많은 엣지로케이션에 파일을 뿌려야 할수록 aws에서도 비용이 나가는 부분이기 때문에 추가결제가 필요하다. 그래서 지금 내 앱이 어디서 서비스 되면 좋을지를 판단해서 선택하면 된다. 나는 아시아! -
기본 루트에는 index.html을 넣어준다. 그래야 기본 파일이 뭔지 인식해서 배포해준다.
-
중요한건 다 입력하고 누르고나서 2-3분이 지나야 사이트가 배포가 된다. 이걸 몰라서 내가 뭘 잘못 입력한줄 알고 계속 오타를 찾았는데 아니었다. 원본 데이터를 서버로부터 엣지로케이션이 받아오는 시간이 걸리기 때문인것 같다.
-
이렇게 하면 끝이다! 이제
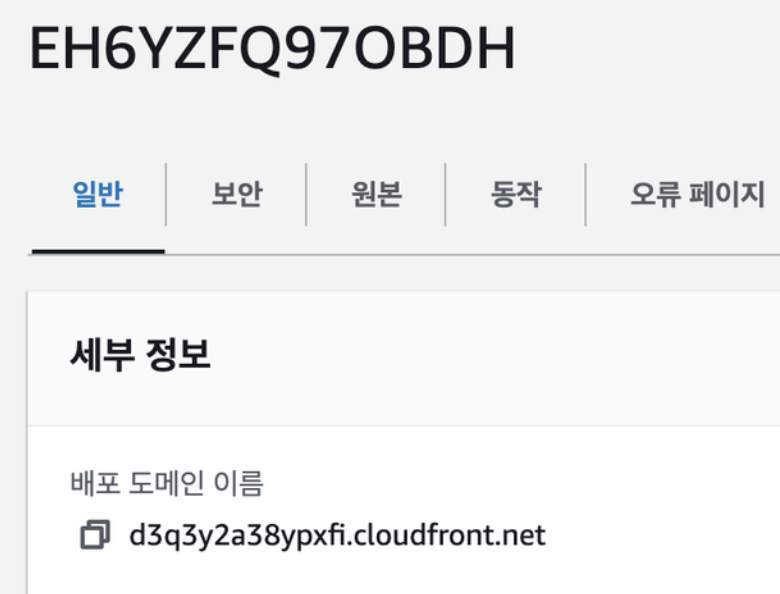 생성되는 도메인으로 접속하면 잘 연결이 된다. 이때 위에서 말한것처럼 바로 정보를 불러오지 않으니 조금 기다리면 곧 연결이 된다. 처음에는 없다고 뜬다!
생성되는 도메인으로 접속하면 잘 연결이 된다. 이때 위에서 말한것처럼 바로 정보를 불러오지 않으니 조금 기다리면 곧 연결이 된다. 처음에는 없다고 뜬다!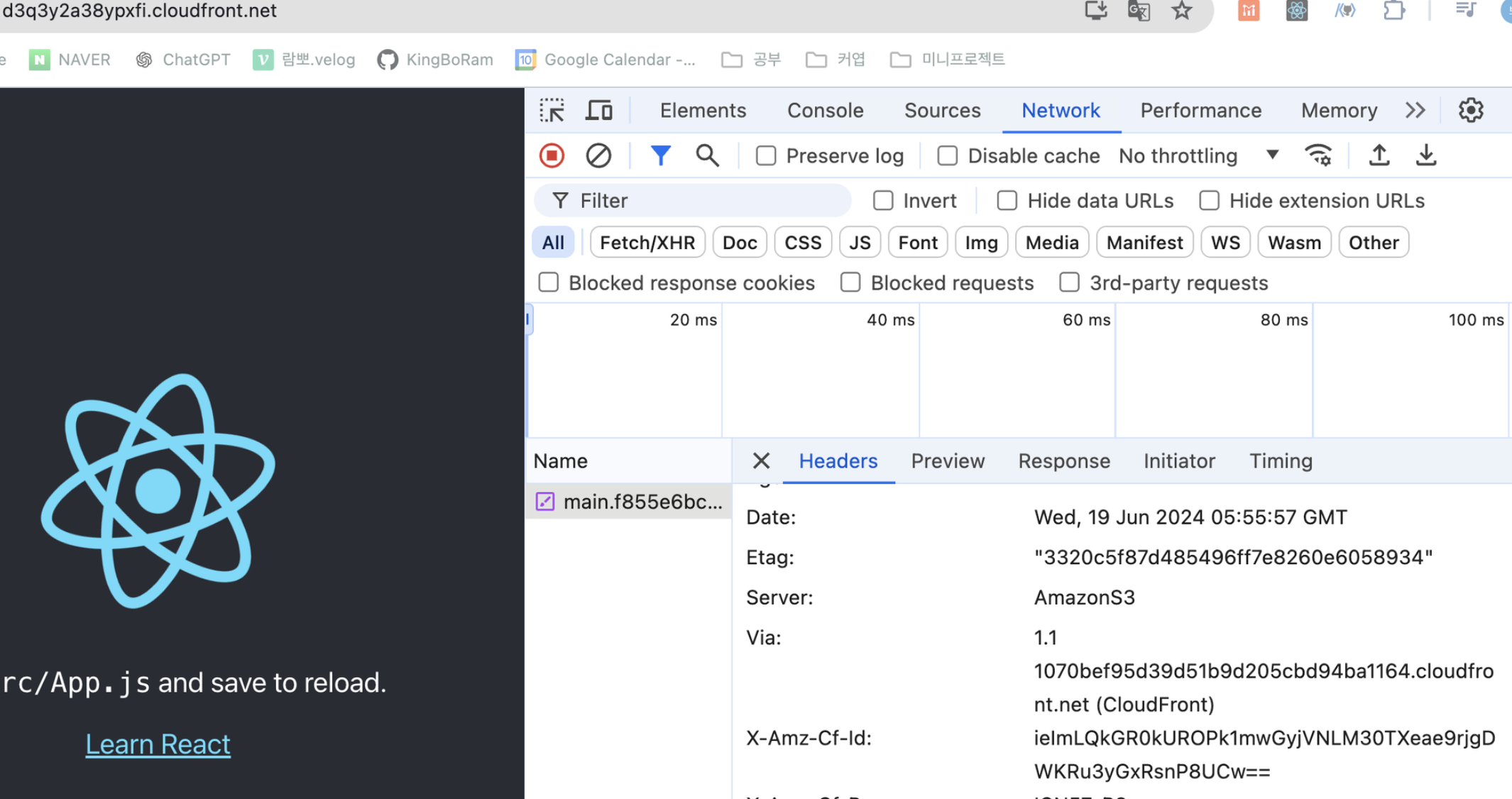 접속해서 응답헤더를 보면, 서버는 s3이지만 via=> cloud front를 경유했다고 잘 적혀 있다.
접속해서 응답헤더를 보면, 서버는 s3이지만 via=> cloud front를 경유했다고 잘 적혀 있다.
github action
vod에서는 추가로 github action을 통해서 배포를 하는 설정을 했다. 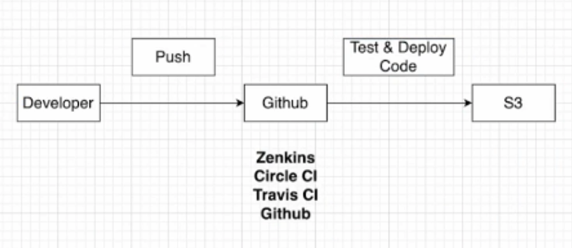 이런식으로 파일을 s3에 저장하기 전에 테스트와 build를 해주는 것을 ci라고 하고, 여러 제공 업체가 있지만 github을 사용할거다.
이런식으로 파일을 s3에 저장하기 전에 테스트와 build를 해주는 것을 ci라고 하고, 여러 제공 업체가 있지만 github을 사용할거다.
-
우선 저장소를 생성하고, 연동하고자 하는 파일의 폴더와 연결한다. (여기서 내 자신에게 말한다. 위 과정과 연속적으로 하면 안된다!@ 위 과정은 이미 s3에 파일을 넣어준거다. 깃허브와 연동해서 파일을 넣어주게 바꾸려면 기존의 파일을 삭제하고 이걸 추가로 하거나 아니면 s3를 새로 만들어라 ㅇㅅㅇ. 만약에 s3를 추가로 만들었따면 위에서 했던 권한설정만 그대로 다시 해주고 아래 작업들을 하면 된다. 이해가 안되면 노션에서 vod 강사님이 해준 부분을 보자)
-
깃허브에서 ci를 구축하려면 workflow에 작성을 해줘야 한다.
 깃허브 actions에 가서 node.js를 찾고 configure를 누른다.
깃허브 actions에 가서 node.js를 찾고 configure를 누른다.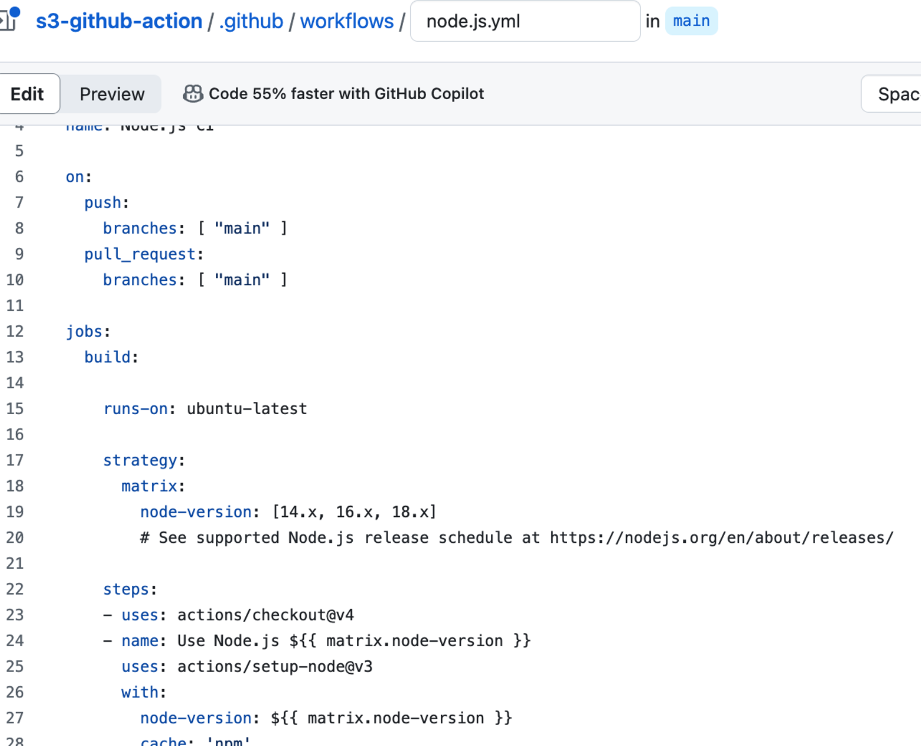 그러면 이런 파일들이 생긴다. 설정을 해주면 된다. on은 push를 했을 때 어디에 할것인지, 그리고 푸시를 하고나면 job의 작업을 실행하겠다 라는 의미이다. 유뷴투에서 돌아가며, node-version은 마지막꺼만 사용해도 된다.
그러면 이런 파일들이 생긴다. 설정을 해주면 된다. on은 push를 했을 때 어디에 할것인지, 그리고 푸시를 하고나면 job의 작업을 실행하겠다 라는 의미이다. 유뷴투에서 돌아가며, node-version은 마지막꺼만 사용해도 된다.
steps는 해당 과정을 거친다는 의미이다. ci라고 되어있는걸 install로 고치고, 여기서는 test까지 해준다. cra는 test를 기본적으로 생성하지만 vite는 그렇지 않다는걸 유의해서 넣어주자.
ci라고 되어있는걸 install로 고치고, 여기서는 test까지 해준다. cra는 test를 기본적으로 생성하지만 vite는 그렇지 않다는걸 유의해서 넣어주자. -
https://github.com/awact/s3-action 그리고 여기로 이동해서 깃허브 액션으로 s3에 연결할때 어떤 설정을 추가해야하는지 나와있는걸 복사해온다.
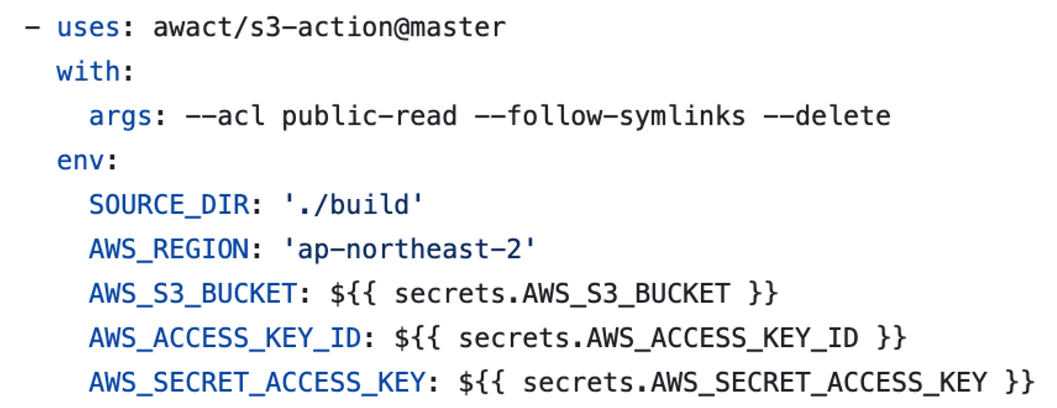 이 부분을 가장 아래에 줄을 맞춰서 추가하면 된다. 소스 dir과 지역도 자신이 사용하고 있는곳에 잘 넣어준다.
이 부분을 가장 아래에 줄을 맞춰서 추가하면 된다. 소스 dir과 지역도 자신이 사용하고 있는곳에 잘 넣어준다. -
그리고 시크릿 키들을 깃허브 설정에 추가해야한다. 버킷네임은 말그대로 만들어둔 버킷의 이름을 추가하면 되는데 여기서 키를 발급받는 과정이 필요하다.
IAM
identify and access management
기본적으로 이메일과 비밀번호를 이용해서 aws에서 유저를 만들면 root 유저가 된다. 이 root유저는 모든 aws를 사용 할 수 있는 기능을 가지고 있게 된다.
즉, root를 하나 탈취하면 모든 서비스가 다운될 수 있다. 그래서 실제로 서비스를 배포 할 때는 iam user를 만든다. root 유저로부터 특정 권한을 부여받고, 그것을 통해서 서비스에 접근을 하는것이다. 우리가 만들 iam user는 s3에 대한 권한을 받게 될거고 깃허브 액션에 그것을 명시 해줄 것이다.
-
iam을 검색 -> 사용자탭 -> 이름적고 -> 직접 정책 연결 -> s3 검색
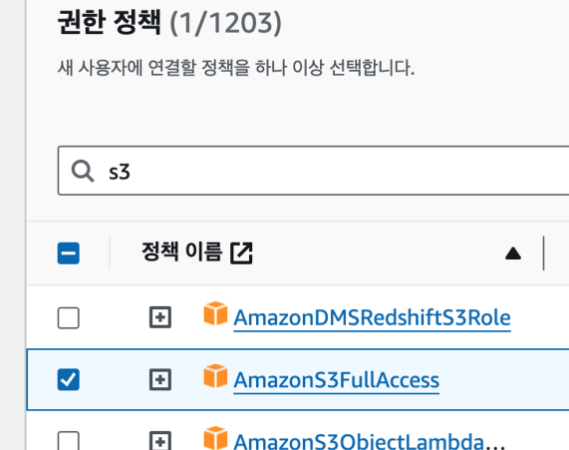 부여할 권한을 선택한다. -> 다음 -> 생성
부여할 권한을 선택한다. -> 다음 -> 생성 -
생성되면 생성된 이름을 클릭해서 상세정보로 들어가서 액세스키 만들기를 누른다. 서드파티서비스를 선택하고 다음 -> 생성을 하면 액세스키가 발급이 된다. 이걸 깃허브 시크릿에 추가하면 된다.

-
이렇게 해놓고 아까 작성하던 파일로 돌아가서 커밋을 해주면 된다.
 그러면 이런 작업 파일이 생기고
그러면 이런 작업 파일이 생기고  깃허브 액션탭을 가보면 설정해준대로 열라뤼 작동을 하고 있는 모습이다.
깃허브 액션탭을 가보면 설정해준대로 열라뤼 작동을 하고 있는 모습이다. -
이런식으로 푸시를 하면 깃허브가 s3에 파일을 넣어줄 수있다. 위에서는 그 파일을 직접 넣은것이고, 여기서는 깃허브를 통해서 한거다. 이렇게 하면 우리는 파일을 push할 때마다 배포가 새롭게 될거다.
도메인 생성하기(가비아)
-
위에서 cloud front를 사용해서 배포를 했어도 여전이 도메인이 못생겼다.
-
예전에는 무료로 하는 사이트가 있었는데 지금은 안된다고한다. 그래서 가비아라는 사이트를 이용했다. 가비아에서 할인 이벤트로 500원에 도메인을 구매했다. (1년간 사용 가능하다고 한다.)
-
https://www.gabia.com/?utm_source=google&utm_medium=cpc&utm_term=가비아&utm_campaign=가비아
-
https://hi-rambo.store/ 구입한 도메인
-
가비아에 회원가입하고 로그인하면 도메인을 검색 할 수 있다.
 어떤 주소를 사용할거냐에 따라서 값이 다르다. 나는 500원짜리를 샀다. 선택을 누르고 사용자 정보만 입력하고 입금을 하면 된다. 등록까지느 약 10분정도 소요되니까 기다리면 된다. 만들어지면 문자가 온다.
어떤 주소를 사용할거냐에 따라서 값이 다르다. 나는 500원짜리를 샀다. 선택을 누르고 사용자 정보만 입력하고 입금을 하면 된다. 등록까지느 약 10분정도 소요되니까 기다리면 된다. 만들어지면 문자가 온다.
-
구입한 도메인과 만들어둔 s3버킷을 연결해야한다. cloud front로 들어가서 처음 나오는 화면에서 설정부분에 편집버튼을 누른다.
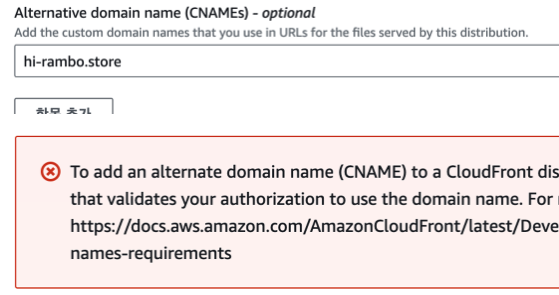 여기에 그냥 이렇게 등록을 하면 오류가 난다. 해당 도메인이 옳은지 인증 절차가 필요하기 때문이다.
여기에 그냥 이렇게 등록을 하면 오류가 난다. 해당 도메인이 옳은지 인증 절차가 필요하기 때문이다. -
조금 스크롤을 위에 올리면 있는 request certificate 인증 절차를 눌러서 이동한다
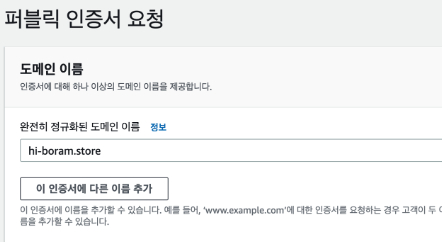 도메인 이름은 제대로 쓰자 ^_^.. 람보인데 보람이라고 썻다가 첨에 왜 안되는지 30분간 헤맸다..이름을 쓰고 나면 dns로 인증하기를 하면 된다. (선택되어있다.)
도메인 이름은 제대로 쓰자 ^_^.. 람보인데 보람이라고 썻다가 첨에 왜 안되는지 30분간 헤맸다..이름을 쓰고 나면 dns로 인증하기를 하면 된다. (선택되어있다.) -
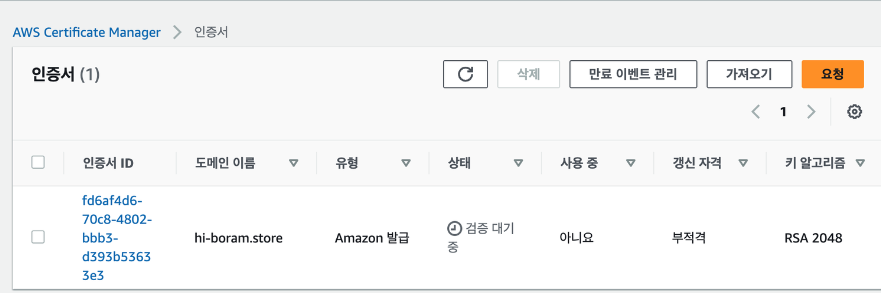
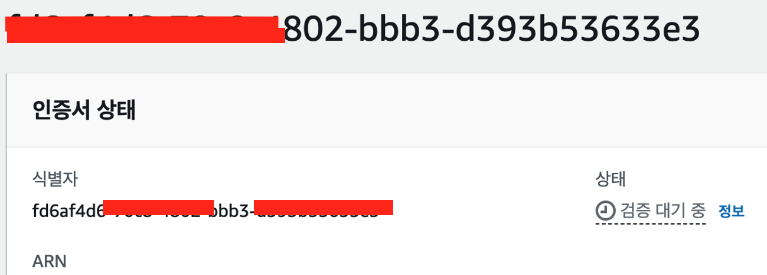 인증서를 선택해서 들어가면 검증 대기중이라고 뜬다. 여기서 발급해주는 키를 가비아에서도 등록해야 검증이 된다.
인증서를 선택해서 들어가면 검증 대기중이라고 뜬다. 여기서 발급해주는 키를 가비아에서도 등록해야 검증이 된다. -
가비아에서 내정보 -> dns관리툴 -> 설정 -> 레코드추가
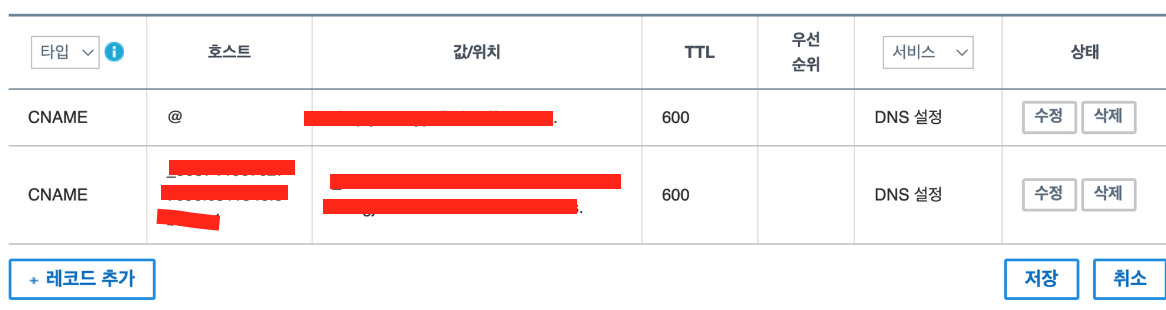 그러면 위와 같이 타입을 선택하고 호스트와 값을 넣어주면 된다. 위의 cname에는 내 클라우드프론트 도메인을 넣으면 되고, 아래에는 발급해주는 cname이름과 cname값을 넣어주면 된다.
그러면 위와 같이 타입을 선택하고 호스트와 값을 넣어주면 된다. 위의 cname에는 내 클라우드프론트 도메인을 넣으면 되고, 아래에는 발급해주는 cname이름과 cname값을 넣어주면 된다. -
A타입은 숫자 형태로 된 서버 ip주소를 뜻하고, c레코드는 도메인을 입력하면 된다. cname레코드는 마침표로 끝나야 한다.
-
마침표가 중요하다! 그래서 값부분은 둘 다 마침표로 끝난다. 그런데 호스트 부분은 위에는 @인데 주소가 www로 시작하면 www를 넣고 우리 도메인 hi-rambo처럼 www가 없으면 @를 넣으면 된다.
-
이것까지 하고 나서도 한 5분정도 기다리면 검증대기중 상태에서 완료됨으로 뜬다.
-
그러면 다시 돌아가서 설정 -> 편집
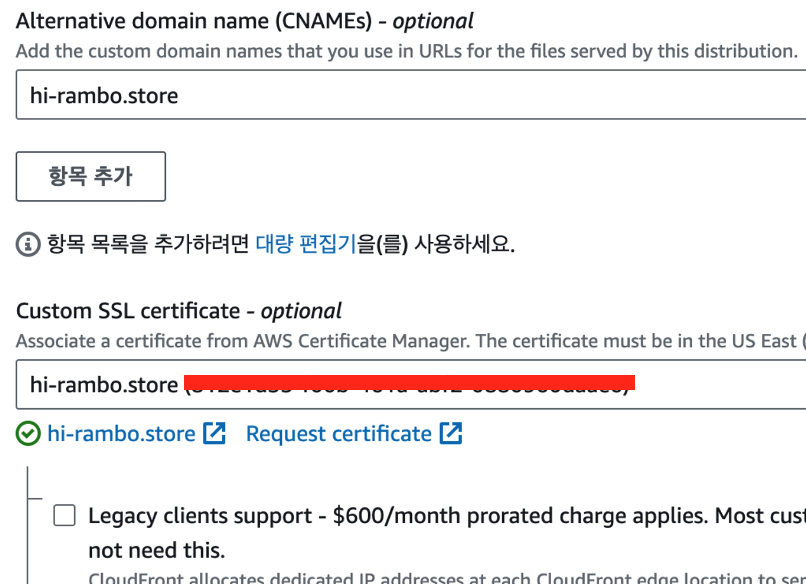 이번에는 이렇게 주소를 넣어주고 생성을 누르면 잘 된다.
이번에는 이렇게 주소를 넣어주고 생성을 누르면 잘 된다. -
그러면 이제 생성한 예쁜 도메인으로 접속을 하면 cloudfront로 접속이 된다. cloudfront는 s3에서 받아와서 화면을 그릴거다 \^_\^
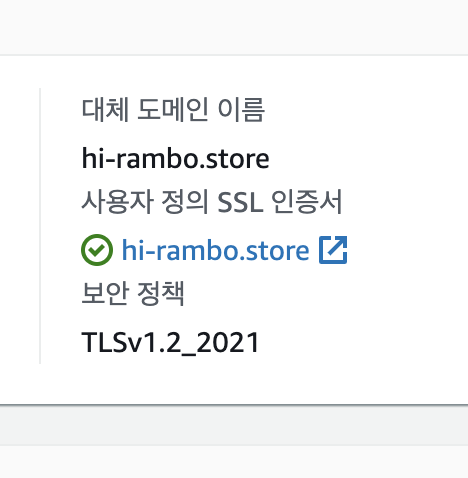 클라우듶 프론트에서도 잘 등록 되어있는 모습
클라우듶 프론트에서도 잘 등록 되어있는 모습 -
추가로 현재 정적인 웹사이트가 배포되어있고, 다시 배포했을 때 캐시된 화면이 그려질 수 있다. 그것을 무효화 하려면 클라우드프론트에서
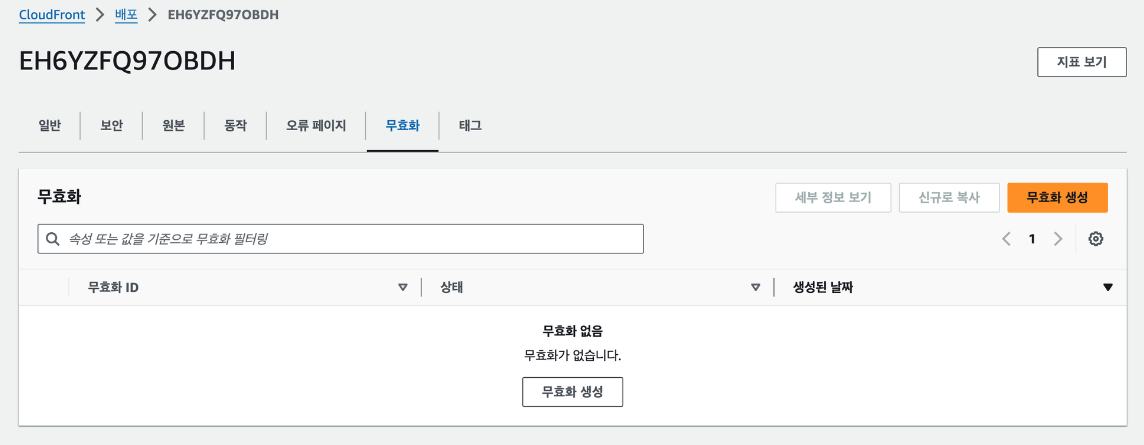 무효화 탭에 들어가고
무효화 탭에 들어가고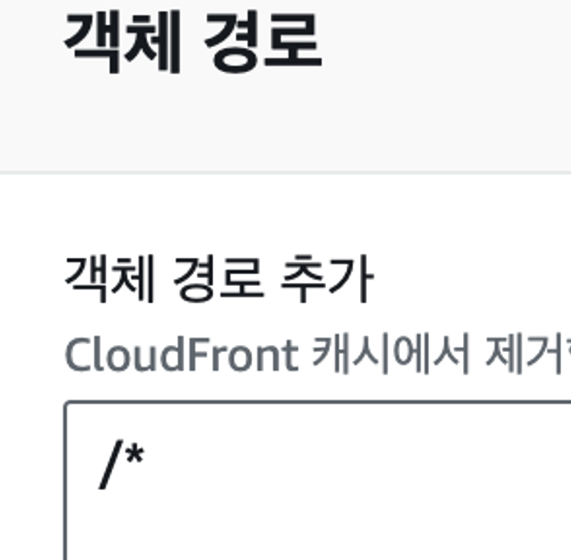 객체 경로에 위와 같이 입력하면 매번 새로운 데이터로 받아 올 수 있다. 위는 전체 경로를 매번 새롭게 받아오도록 한거고 특정 경로를 지정해도 된다.
객체 경로에 위와 같이 입력하면 매번 새로운 데이터로 받아 올 수 있다. 위는 전체 경로를 매번 새롭게 받아오도록 한거고 특정 경로를 지정해도 된다.
Docker
+) 이후에 추가하는 내용! 아래에서 도커는 프로그램을 다운받기 쉽게 하기위해서다~ 라고 설명이 되어있는데, 그러면 이걸 왜 배포에까지 쓰는지 설명이 안된다. 그걸 주희님 발표를 들으면서 알게 됐다. 만약에 내가 개발하는 환경은 mac인데 사용자는 window이거나 linux라면 내가 지금 사용하는 의존성이나 버전과 달라서 실행이 안될 수도 있다. 그런데 만약에 도커라는 가상환경에 아예 운영체제를 통일시켜놓고, 그 운영체제에 맞게 프로그램들을 다 설치를 한 후에 결과물을 유저에게 보여주면 환경에 따라서 차이가 생길 일이 없다! 그리고 운영체제별로 파일을 생성해서 사용자들에게 제공할 필요도 없다. 어차피 가상환경에 따라서 제공하는거니까. 신기하구만! 그래서 배포를 할 때도 배포할 파일을 도커를 통해서 제공하면 사용자들이 다 동일한 환경에서 만들어져서 제공되는 애플리케이션을 사용 할 수 있게 된다.
그리고 사용자 입장에서도 원래 사용자가 프로그램을 다운 받아서 실행하고 그게 화면에 그려지는건데, 도커가 완성시켜서 보내주면 설치 과정도 줄어든다. 또 다운로드 하게 되는 프로그램이 사용자와 맞지 않아도 상관없다 어차피 도커가 다 실행해서 제공해주니까
-
도커는 결론 부터 얘기하면 어떤 프로그램을 다운 받는 과정을 간단하게 만들기 위해서 사용한다.
 예를들어 레디스를 설치하려고해서 공식페이지에 방문하면 이렇게 설치를 하라고 한다. 그런데 wget이 없어서 안된다고 한다. 그러면 wget도 설치를 해줘야한다.
예를들어 레디스를 설치하려고해서 공식페이지에 방문하면 이렇게 설치를 하라고 한다. 그런데 wget이 없어서 안된다고 한다. 그러면 wget도 설치를 해줘야한다. -
이렇게 프로그램을 받을 때 운영체제를 확인해야 하는 경우도 있고, 종속성도 받아야하고, 버전도 확인해야하고 고려해야 할 사항이 많다. 또 오류가 생길 수도 있다.
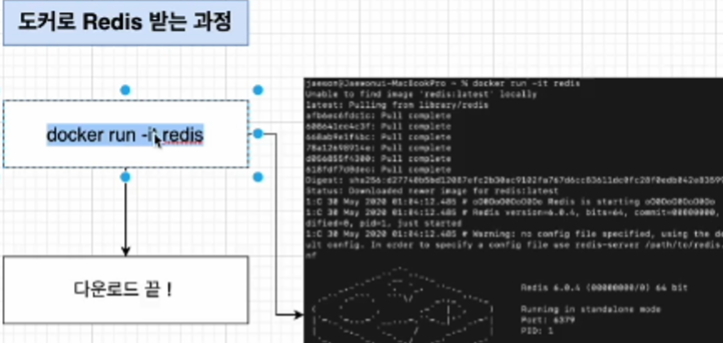 하지만 도커로 받을때는 그냥 명령어로 docker run -it redis하면 오류 없이 다운로드를 해준다. 당연히 도커를 이용하지 않고 하나씩 확인하며 받아도 된다 그것은 선택 사항이다.
하지만 도커로 받을때는 그냥 명령어로 docker run -it redis하면 오류 없이 다운로드를 해준다. 당연히 도커를 이용하지 않고 하나씩 확인하며 받아도 된다 그것은 선택 사항이다. -
도커를 정리하면, 컨테이너를 사용하여 응용프로그램을 더 쉽게 만들고 배포하고 실행할 수 있도록 설계된 도구이며 컨테이너 기반의 오픈소스 가상화 플랫폼이다.
-
컨테이너는 일반적인 개념의 컨테이너를 생각하면 이해하기 쉽다. 보통 컨테이너는 여러 물건을 넣고 운송하는 수단으로 사용된다. 도커에서도 마찬가지다. 컨테이너 안에 다양한 프로그램, 실행환경을 추상화 하여 넣어두고 배포를 할 때 한번에 할 수 있도록 해준다. 이것을 aws, azure, google cloud등 어디서든 사용 할 수 있다.
-
설치 : https://www.docker.com/ -> get started -> 운영체제에 맞는 버전 선택하여 다운로드 -> 회원가입은 굳이 안해도 된다.
 터미널에서 버전을 확인하면 설치가 됐는지 확인 할 수 있고,
터미널에서 버전을 확인하면 설치가 됐는지 확인 할 수 있고,  이렇게 running 중이라는 녹색 바가 뜨면 실행도 잘 되고 있는거다.
이렇게 running 중이라는 녹색 바가 뜨면 실행도 잘 되고 있는거다.
사용 방법
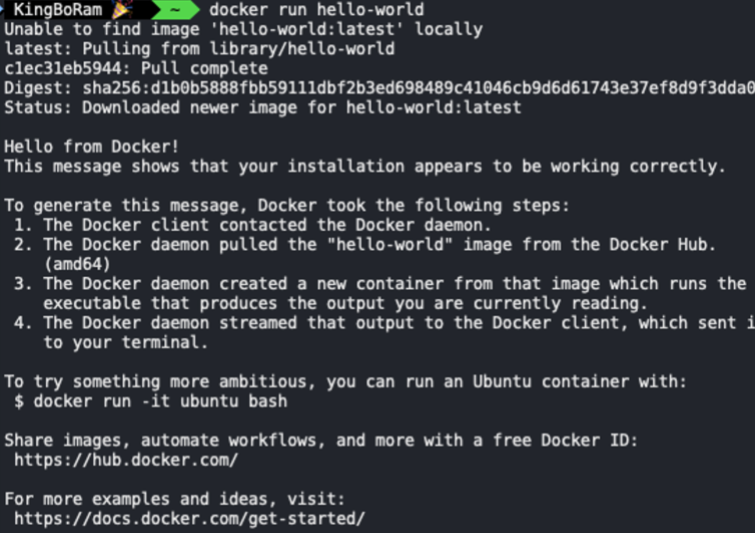 CLI환경에서 커맨드를 입력하면 도커 서버가 그 커맨드를 받아서 이미지를 실행하든 컨테이너를 실행하든 어떠한 작업을 하게 된다.
CLI환경에서 커맨드를 입력하면 도커 서버가 그 커맨드를 받아서 이미지를 실행하든 컨테이너를 실행하든 어떠한 작업을 하게 된다.
위 이미지는 도커를 사용해서 hello-world를 실행한 모습이다. hello from docker라고 되어있는 부분이 hello-world를 실행하면 나타나는 메세지이다. 이 메세지를 만들기 위해서 도커가 어떤 순서를 따랐는지 설명이 되어 있다.
1. 도커 클라이언트에 커맨드를 입력하면 도커 서버로 요청을 보낸다.
2. 서버에서 hello-world라는 이미지가 이미 로컬에 있는지 확인한다.
3. 현재는 없으니까 첫번째 줄에 unable to find image라는 문구가 뜬다.
4. 그러면 도커 허브라는 이미지들이 저장되어 있는 곳에가서 그것을 받아오고 로컬에 cache로 보관한다.
5. 이미지를 토대로 컨테이너를 생성하고, 만들어진 컨테이너는 프로그램을 실행한다.
여기서 이미지라는 말이 계속 나오는데, 이미지는 컨테이너가 실행할 파일들이 어떤것들이 있는지 그에 대한 정보가 담겨있는 일종의 설계도이다. 도커 허브에는 굉장히 많은 이미지들이 존재하고, 거기서 설계도를 하나 가져와서 설계도에 따라서 컨테이너를 만들고, 그 컨테이너를 실행시키는 것이다.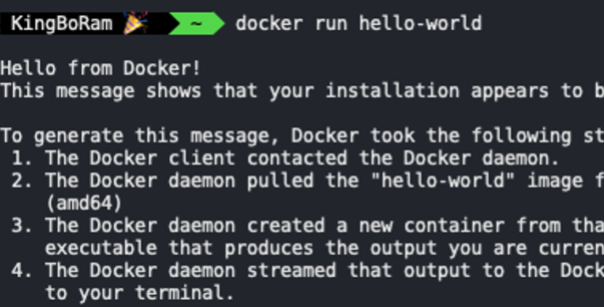 다시 실행시켜보면, 이번에는 캐시되어 있기 때문에 unable to find image가 뜨지 않고 바로 실행이 된다.
다시 실행시켜보면, 이번에는 캐시되어 있기 때문에 unable to find image가 뜨지 않고 바로 실행이 된다.
이미지
위에서 이미지는 일종의 설계도라고 표현했다. 이렇게 이미지에는 소스코드, 라이브러리, 종속성, 도구 등 응용프로그램을 실행하는데 필요한 기타 파일들이 포함된 '파일'이다. 이것들을 하나하나 표현하면 기니까 이미지라고 통칭해서 묶어둔 것 같다. 즉 이미지란 소프트웨어를 실행하는데 필요한 모든 파일들을 포함하는 패키지를 의미한다. (참고1, 참고2)
처음에 redis를 설치하는데 다른 프로그램들을 설치할 필요가 없었던것도 어떤 파일을 설치하는데 필요한 종속성이나 패키지들이 모두 이미지에 저장이 되어있고 그것이 도커허브에 존재하기 때문에 그것을 받아와서 한번에 설치 할 수 있는 것이다.
-
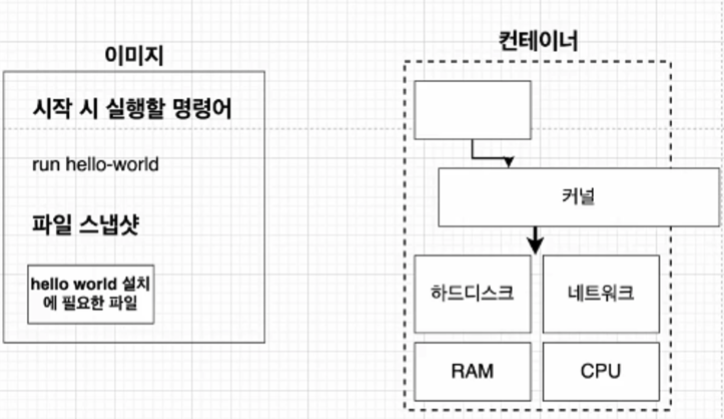
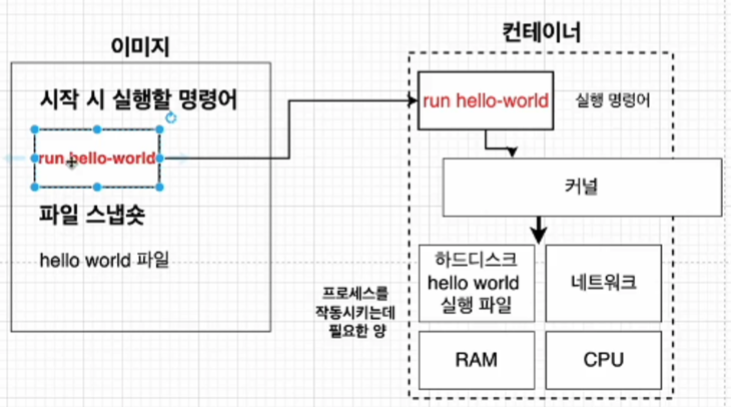
즉 이미지는 응용프로그램을 실행하는데 필요한 모든 것을 포함하고 있다. 그리고 컨테이너는 이미지를 이용해서 생성된다. 그렇다면 그 '필요한 모든 것' 에는 어떤게 있을까?
- 컨테이너를 실행할 명령어 (ex. run hello-world)
- 파일 스냅샷 (헬로월드를 실행하고 싶다면 헬로월드를 실행하는데 필요한 파일들이 있어야 한다. 보통 특정 시점의 파일 시스템을 캡처하는 걸 스냅샷이라고한다. 이미지도 파일의 특정 파일 시스템을 보관하고 있다.)
 이미지에서 컨테이너를 생성하는데 필요한 모든것은 위와 같다. 컨테이너를 생성하고 컨테이너가 실행되려면 그것을 호출할 명령어와 파일들이 필요하니까 어떻게 보면 당연한 이야기다!
이미지에서 컨테이너를 생성하는데 필요한 모든것은 위와 같다. 컨테이너를 생성하고 컨테이너가 실행되려면 그것을 호출할 명령어와 파일들이 필요하니까 어떻게 보면 당연한 이야기다!
-
정리하면 위와 같이 컨테이너가 실행된 결과물을 얻으려면, 이미지라는게 필요하고 그걸 허브에서 받아올 수 있고, 그걸 기반으로 컨테이너가 만들어지고 실행되며 결과물은 위와 같이 나타나게 된다. 순서를 정리하자면
- docker클라이언트에 docker run <이미지> 를 입력한다.
- 도커 이미지에 있는 파일 스냅샷을 컨테이너의 하드 디스크에 옮긴다.
- 컨테이너 내부에서 설치 및 실행을 위해 컨테이너 내부의 하드디스크로 파일을 옮긴다.
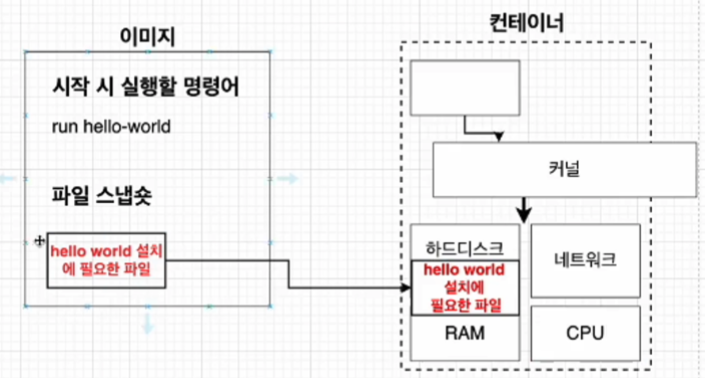
- 이미지에 가지고 있는 실행 명령어를 컨테이너로 옮기고 컨테이너는 그것을 하드디스크로 전달하여 실행한다.
이미지 생성하기
허브에서 이미지를 받아와서 사용 할 수도 있지만 원하는 이미지를 직접 만들어 사용하거나 허브에 올릴 수 있다.
이미지를 생성하기 위해서는 우선 도커파일을 작성해야한다. 도커파일은 이미지의 설정 파일로, 컨테이너가 이미지를 받아서 어떻게 행동해야 하는가에 대한 내용을 기입해야 한다.
-
docker file 만들기 : 도커파일에는 베이스 이미지, 필요한 파일을 다운받기 위한 명령어, 컨테이너 실행 명령어를 포함시켜야 한다. (베이스이미지, 파일다운명령어는 이미지에서 파일스냅샷에 해당하고, 실행명령어는 커맨드에 해당한다.)
-
베이스 이미지는 운영체제에 해당한다. 어떤 프로그램이 돌아가려면 운영체제가 필요하니까 os가 무엇인지 명시를 해야한다. mac, window 같은것들
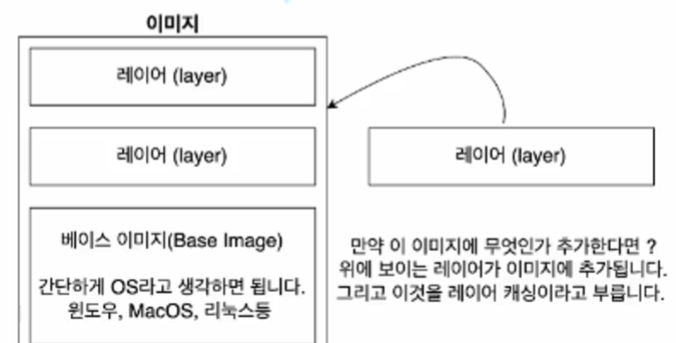 그 상태로 잇다가 보면 알겠지만 도커 파일에 RUN과 같은 명령어를 작성할 수 있는데 그럴 때마다 레이어라는게 생겨난다. 레이어는 각 명령어에 따른 발드과정에서 변경사항을 캡쳐해두는 것을 말한다. 그 레이어들이 베이스 이미지 위에 쌓이게 되는 형태다.
그 상태로 잇다가 보면 알겠지만 도커 파일에 RUN과 같은 명령어를 작성할 수 있는데 그럴 때마다 레이어라는게 생겨난다. 레이어는 각 명령어에 따른 발드과정에서 변경사항을 캡쳐해두는 것을 말한다. 그 레이어들이 베이스 이미지 위에 쌓이게 되는 형태다. 이렇게 레이어가 생기는 이유는 아마도 캐싱때문인 것 같다. 이것도 잇다가 보면 알겠지만 docker file을 생성하고 사용하기전에 build를 해야하는데, 어차피 안에 내용이 바뀌면 build를 다시 해야한다. 즉 build를 한번 하고나면 만들어진 레이어들은 만들어진채로 계속 사용해야 하기때문에 그때마다 만드는것보다 처음에 만든것을 캐싱해서 사용하는게 더 빠르기 때문이다. 또 만약에 이렇게 만들어진 레이어를 다른 이미지에서도 사용하면 캐싱한걸 그대로 가져가서 사용하면 된다.
-
아래는 도커 파일을 만들고, 임시로 안에 내용까지 작성한 모습이다.
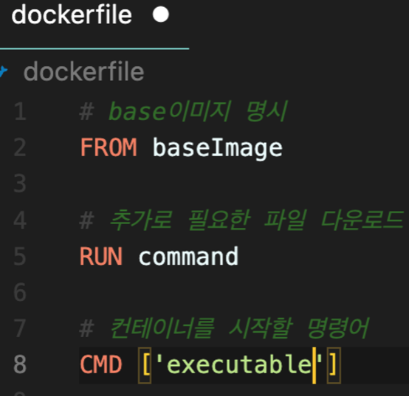
- from에는 baseimage가 들어간다. 즉 운영체제를 넣으면 된다. ubuntu:14.04와같이 운영체제와 버전을 명시하면 되는데 버전을 안쓰면 가장 최신 버전으로 사용한다.
- run은 도커이미지가 생성되기 전에 레이어를 쌓는 부분이다. 위의 베이스 url이나 혹은 컨테이너를 동작시키는데 필요한 패키지를 설치하거나 환경 설정을 수행하는데 사용한다.
- cmd는 컨테이너를 실행할 명령어를 명시하는 부분이다.

-
실제로 도커 파일에 사용할 이미지를 완성시켰다. os가 낯선데, 유분투와 같은 운영체제는 아주 큰 파일들을 다루는 프로그램이라 알파인이라는 운영체제를 사용한다.
-
실행하면 터미널에 hello라는 텍스트를 띄워야 한다. 그러면 콘솔에 텍스트를 띄우는 프로그램이 필요한데, 알파인에서 그런 기능을 하는 echo를 사용할 수 있는 파일이 이미 존재하기 때문에 추가로 다운받아서 레이어를 쌓을 필요는 없어서 그냥 주석처리 했다.
-
즉 위 이미지는 알파인으로 hello라는 단어가 출력되도록 할것이다. 그리고 그것을 위한 추가적인 파일은 필요없다.
-
위처럼 작성하고나서 만든 이미지를 도커 클라이언트가 인식을 해야 그것을 도커 서버에게 전달하고 실행할수있다. 그러기 위해서 빌드를 해야한다.
-
docker build ./(현재디렉토리) 이 때 도커가 실행되고 있는지 확인해야함!
-
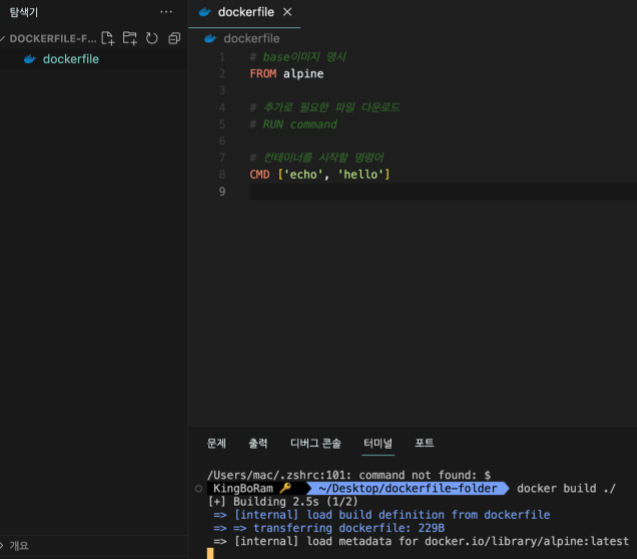 빌드가 잘 되는 모습이다.
빌드가 잘 되는 모습이다. -
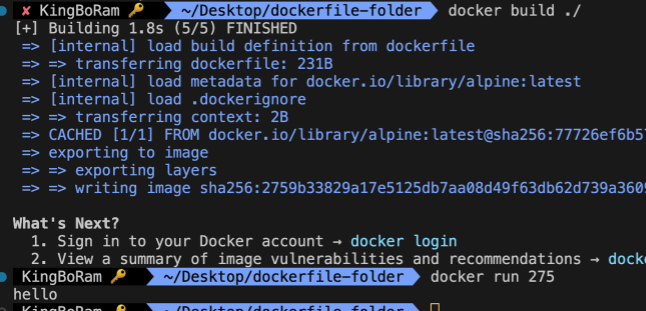 마지막에 숫자가 이미지의 id값인데, 다 입력할 필요는 없고 앞에꺼만 해도 잘 된다. 실행하면 콘솔에 hello가 잘 찍힌다.
마지막에 숫자가 이미지의 id값인데, 다 입력할 필요는 없고 앞에꺼만 해도 잘 된다. 실행하면 콘솔에 hello가 잘 찍힌다. -
여기서 주의 할게..
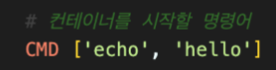 처음에 이렇게 했더니 실행이 잘 안됐다. 차이라면 대괄호 안쪽 양옆에 공백을 넣느냐 아니면 작은따옴표이냐 하는건데 아마도 작은따옴표로 했더니 안된것 같다 ㅜ. 꼭 큰따옴표로 하자
처음에 이렇게 했더니 실행이 잘 안됐다. 차이라면 대괄호 안쪽 양옆에 공백을 넣느냐 아니면 작은따옴표이냐 하는건데 아마도 작은따옴표로 했더니 안된것 같다 ㅜ. 꼭 큰따옴표로 하자 -
중요한건 오늘 도커를 왜 배웠냐면, 다음시간부터 도커 + ec2 배포 그리고 그 다음에는 도커 + aws 엘라스틱..? 깃허브를 이용해서 ci/cd를 모두 구현한 배포까지 해볼 예정이라서 그렇다고 한다.
리액트를 위한 도커 파일 작성
위에서도 말했겠..? 지만 도커파일은 개발환경, 운영환경에 따라서 두개의 도커파일을 생성해야한다. 리액트를 위한 도커파일을 환경에따라 작성해보자.
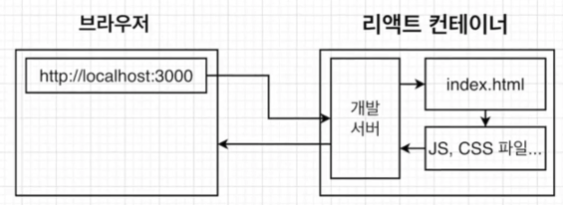 개발환경에서 리액트는 위와같이 실행된다. 사용자가 해당 경로로 접속을 하면, 개발서버가 따로 존재해서 개발 서버에서 그에 맞는 파일들을 제공해준다.
개발환경에서 리액트는 위와같이 실행된다. 사용자가 해당 경로로 접속을 하면, 개발서버가 따로 존재해서 개발 서버에서 그에 맞는 파일들을 제공해준다.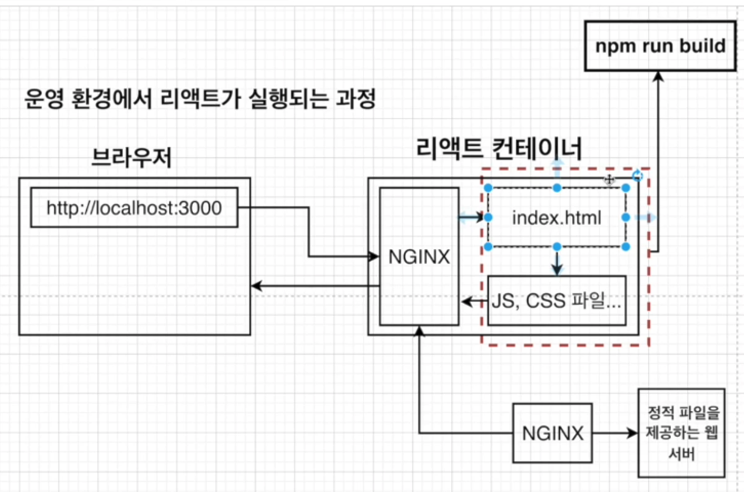 운영환경에서는 위와 같다. 일단 build 파일을 사용한다. 그리고 개발 서버가 따로 존재하지 않기 때문에 유저가 접속했을 때 해당 경로에 일치하는 파일을 제공하는 서버가 따로 필요하고, 그것을 nginx가 담당하도록 만들거다. (앞으로) 즉, docker로 앱을 사용 할 때 nginx가 운영환경에서 해당 파일을 제공하도록 하려면 별도의 설정을 해주어야 한다.
운영환경에서는 위와 같다. 일단 build 파일을 사용한다. 그리고 개발 서버가 따로 존재하지 않기 때문에 유저가 접속했을 때 해당 경로에 일치하는 파일을 제공하는 서버가 따로 필요하고, 그것을 nginx가 담당하도록 만들거다. (앞으로) 즉, docker로 앱을 사용 할 때 nginx가 운영환경에서 해당 파일을 제공하도록 하려면 별도의 설정을 해주어야 한다.
이렇게 환경에 따라서 웹애플리케이션이 실행되는 과정에 차이가 있기 때문에 도커파일도 따로 작성해야 한다.
그런데 도커 파일을 작성하기전에 해줘야 할 설정이 있다. 위에서 nginx를 통해서 파일을 제공할거라고 했는데, nginx가 그 역할을 하면된다! 라는 설정을 해야한다.
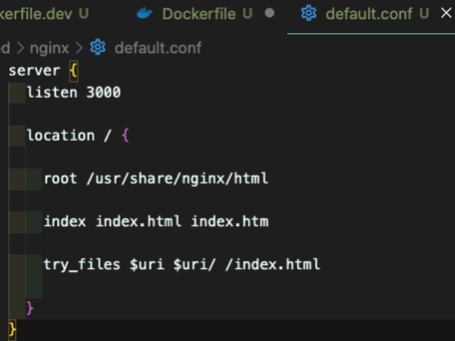 그게 위 코드다. 해석하면 nginx server 는 3000번 포트에 있고, 요청 경로가
그게 위 코드다. 해석하면 nginx server 는 3000번 포트에 있고, 요청 경로가 /일 경우에 아래와 같이 동작한다라는 의미이다.
루트는 제공될 html 파일이 존재하는 경로 = /경로로 요청이 오면 제공할 파일을 의미한다.
index도 말 그대로 index로 제공할 파일명을 의미한다
try_files는 리액트만의 설정값이다. 리액트는 SPA이기 때문에 페이지가 index.html 하나다. 그래서 일반적인 방법으로는 nginx가 경로를 인식하지 못하기 때문에, 특정 경로로 요청이 왔을 때 해당하는 파일이 없는경우에 대안책으로 index.html을 제공하여 특정 경로로 라우팅을 할 수 있게 임의 설정을 해주는 방법이다.
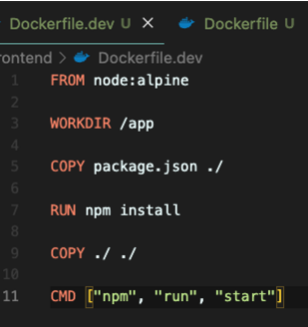 개발환경에서는 nginx를 쓰지 않기 때문에 그냥 위와 같이 작성하면 된다.
개발환경에서는 nginx를 쓰지 않기 때문에 그냥 위와 같이 작성하면 된다.
컨테이너의 환경은 linux의 버전중 하나인 alpine인데 거기에 node가 설치된 운영체제일거고, 컨테이너에 생성 될 경로는 /app이고 거기에 리액트 파일들을 넣어둘거다.(원하는대로 지정하면 된다) 거기에 package.json을 복사해서 저장하고, npm install을 해서 dependency들을 설치한다. 그리고 나머지 파일들도 모두 카피해서 가져가고, npm run start (cra앱이었다)하면 된다.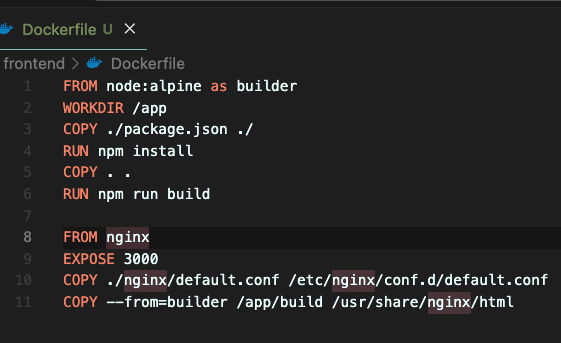 운영환경에서의 도커파일은 위와 같다. 운영환경에서는 아까 말햇던것처럼 파일을 build해야하고 build한 파일을 nginx가 제공하도록 해야 하기 때문에 위와같이 두 부분으로 나뉠 수 있다.
운영환경에서의 도커파일은 위와 같다. 운영환경에서는 아까 말햇던것처럼 파일을 build해야하고 build한 파일을 nginx가 제공하도록 해야 하기 때문에 위와같이 두 부분으로 나뉠 수 있다.
위에는 똑같은데 npm run build한다는거만 다르고, nginx부분을 보면 3000번 포트이고, 위의 COPY는 도커 내에도 설정을 해줘야하니까 설정파일을 복제해주는거고 아래 COPY는 제일 뒤에서 부터 보면 아까 default파일에 root에 써준거랑 같은데, 즉 윗영역에서 build한 파일을 root에 넣어둔 경로에 저장하고 nginx가 제공해라 라는 뜻이다.
builder라는건...스테이지라고한다... 그냥 이름 붙이는 느낌인가..? 따로 찾아보진 않았다..
추가로 위에서 공부한 파일은, 풀스택으로 서버는 node.js로 입력한 웹앱이다. 하지만 프론트만 했다고 생각하자.. 일단은..
그러면 이제 도커 켜서 running중인지 확인하고 터미널에서 docker build ./ 하면 이미지가 생성이 된다. 그러면 이미지를 실행해보면
그러면 이미지를 실행해보면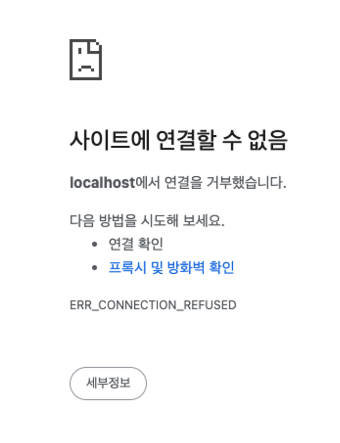 실행은 되는데 아무것도 안뜬다.
실행은 되는데 아무것도 안뜬다.
이건 왜냐면 지금 내 컴퓨터에서 앱을 실행한게 아니라 도커 환경에서 실행한거기 때문이다. 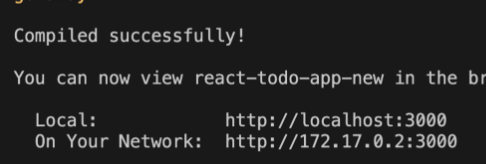 그래서 이렇게 삼천번에서 잘 켰다~ 라고 떠도 이게 내 컴퓨터가 아니라 도커의 가상환경의 localhost3000번에서 떳다는 소리다. 그래서 내 컴퓨터의 로컬환경과 도커의 로컬환경을 연결해주는 작업이 필요하다.
그래서 이렇게 삼천번에서 잘 켰다~ 라고 떠도 이게 내 컴퓨터가 아니라 도커의 가상환경의 localhost3000번에서 떳다는 소리다. 그래서 내 컴퓨터의 로컬환경과 도커의 로컬환경을 연결해주는 작업이 필요하다. 어렵지 않다 도커 이미지를 실행 할 때 -p 3000:3000을 추가해주면 된다. 그러면 이제 내 로컬 환경에서도 3000번으로 접속하면 만든 앱이 잘 보인다.
어렵지 않다 도커 이미지를 실행 할 때 -p 3000:3000을 추가해주면 된다. 그러면 이제 내 로컬 환경에서도 3000번으로 접속하면 만든 앱이 잘 보인다.
node.js의 도커파일 생성
바로 위에서 사용한 앱은 풀스택앱이라서 node.js파일이있다. 여기도 마찬가지로 개발환경, 운영환경 두개의 도커파일을 작성해주면 된다.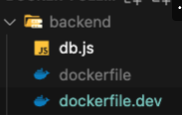
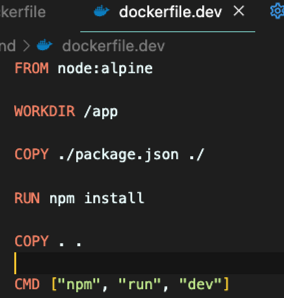
 프론트를 하고 나서 보면 허접이다 ㅋ 여기서 dev가 있는 이유는 위 앱에 package.json의 script에
프론트를 하고 나서 보면 허접이다 ㅋ 여기서 dev가 있는 이유는 위 앱에 package.json의 script에 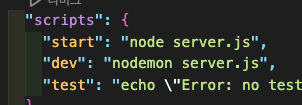 dev하면 nodemon으로 실행되게 해놔서 그렇다.
dev하면 nodemon으로 실행되게 해놔서 그렇다.
EC2에 도커 설치하기
또~~~ 추가로~~~ 위의 풀스택 앱은 ec2에 배포할 예정이다. 그래서 ec2의 컴퓨터에도 도커를 설치해놔야한다.
인스턴스 생성하고,, 키페어 발급받고,, 아무튼 똑같이 만들어주고,,  사용할 ec2를 선택해서 연결을 누른다.
사용할 ec2를 선택해서 연결을 누른다.
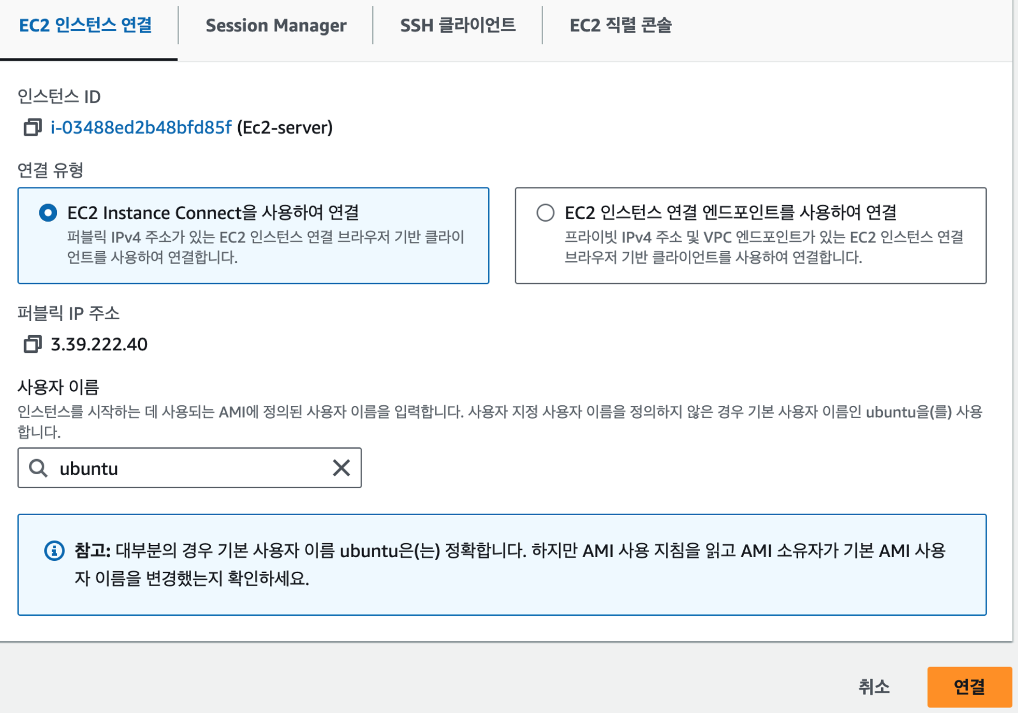 그러면 이런 창이 뜬다. 원래는 키페어를 써서 ssh로 연결해야하는데, 번거로우니까 지금은 그냥 인스턴스 연결을 한다. 유분투를 선택하고 연결을 누르면 된다.
그러면 이런 창이 뜬다. 원래는 키페어를 써서 ssh로 연결해야하는데, 번거로우니까 지금은 그냥 인스턴스 연결을 한다. 유분투를 선택하고 연결을 누르면 된다.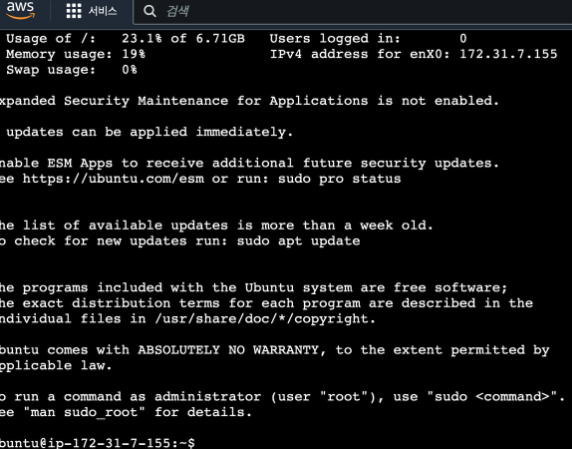 그러면 이렇게 터미널 같은 새창이 뜬다. aws에 존재하는 내가 빌린 ec2 컴퓨터의 터미널에 들어간거다.
그러면 이렇게 터미널 같은 새창이 뜬다. aws에 존재하는 내가 빌린 ec2 컴퓨터의 터미널에 들어간거다.
https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-20-04
이 사이트에 가면 정~~말 정리가 잘 되어있다. 순서대로 따라하면 된다. 그리고 이걸 하면 설치가 잘 됐는지 확인할수있다.
그리고 이걸 하면 설치가 잘 됐는지 확인할수있다.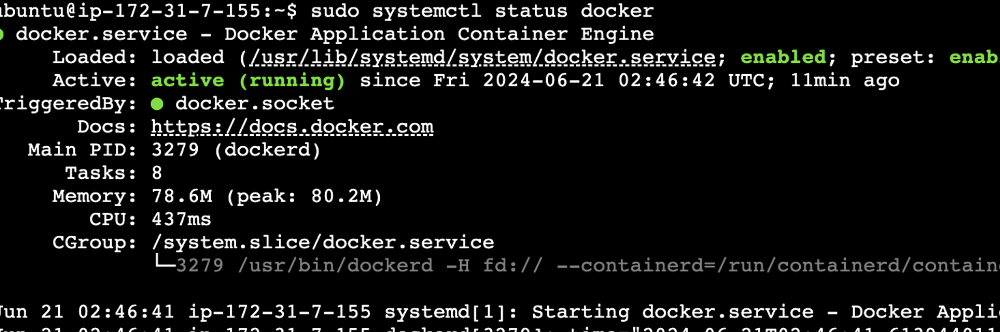 러닝 되어있으면 잘 된거다.
러닝 되어있으면 잘 된거다.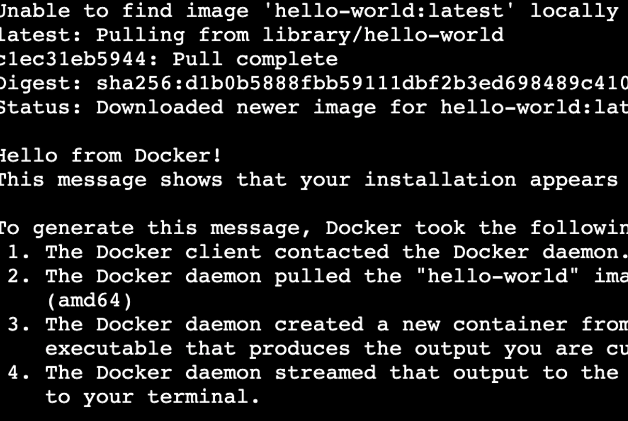 전에 해본 hello-world 이미지도 잘 실행된다. = 도커가 ec2 컴퓨터에 잘 설치됐다는 뜻
전에 해본 hello-world 이미지도 잘 실행된다. = 도커가 ec2 컴퓨터에 잘 설치됐다는 뜻
생략
이후 aws 5일차 수업은 ElasticBeansTalk + docker + RBS를 이용해서 fullstack app을 배포하는 강의였으나 강의가 너무 오래되고 중간에 생략된 부분이 많아서 배포까지 완료는 했으나 제대로 동작하지 않고, 위의 이용 프로그램들에 대한 설명을 들은게 아니라 배포 과정을 훔쳐보며 따라하는 수준이라 이해한 것도 없다.
+) 추가로 바로 앞에서 ec2+docker로 풀스택 앱 배포할거라고 설정만 한거는 배포하지도 않는다. 강의에 없다. 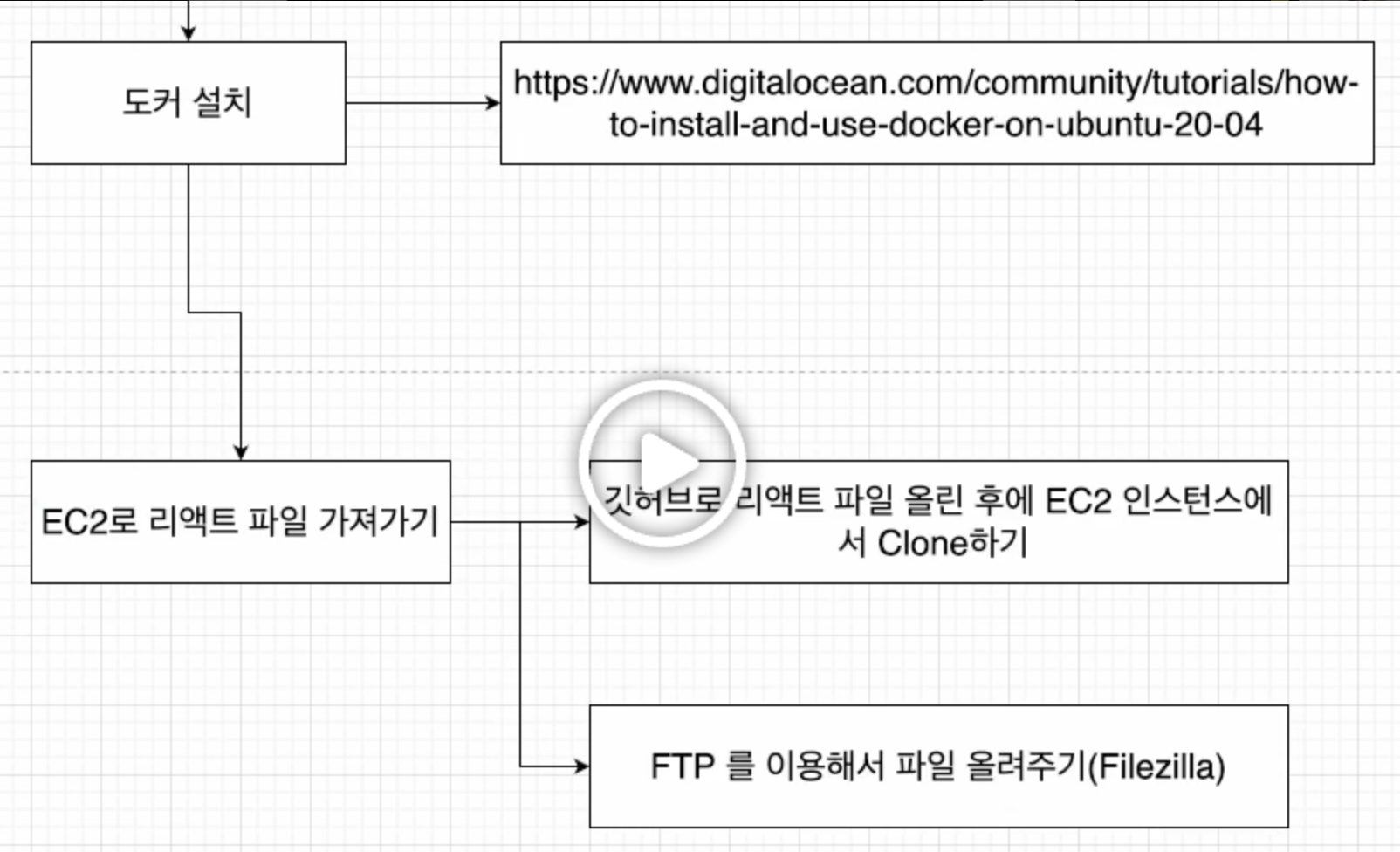 위가 강의에서 처음에 나오는 흐름인데, 도커설치까지만 하고 뒷부분이 없다. 조교님께 여쭤봤더니 강사님이 아예 강의 자료를 제공을 안했다고 한다.
위가 강의에서 처음에 나오는 흐름인데, 도커설치까지만 하고 뒷부분이 없다. 조교님께 여쭤봤더니 강사님이 아예 강의 자료를 제공을 안했다고 한다.
 강의 순서가 이렇게 진행이 되는데, 그러면 ec2 배포는 3강에서 끝난거고 그 다음꺼는 자연스럽게 elb로 넘어간거다. 근데 나는 그것도 모르고 4강 전체의 내용이 다 ec2구나.. 갑자기 근데 이게 뭔소리지 하면서 억지로 ec2로 이해하면서 들었다.
강의 순서가 이렇게 진행이 되는데, 그러면 ec2 배포는 3강에서 끝난거고 그 다음꺼는 자연스럽게 elb로 넘어간거다. 근데 나는 그것도 모르고 4강 전체의 내용이 다 ec2구나.. 갑자기 근데 이게 뭔소리지 하면서 억지로 ec2로 이해하면서 들었다.
무슨말이냐면 위에서 ec2로 배포하기~ 어쩌구저쩌구 한것도 결국에 중간부터는 그게 아니고 elb를 위한 준비를 한거였다는 소리다. 나는 elb가 아니라 ec2를 위한것으로 이해하고 학습을 계속 했는데 대체 어디서부터 섞였는지 잘못 이해한건지도 모르겠다.
6.18 진짜 많이 들어본 aws를 공부했다. 사실 aws가 대단하다고는 하는데 그게 뭔지 잘 몰랐고, 공부 하고나서도 잘 모르겠다. 아마도 트래픽이 많은 서비스를 운영해보거나 만들어보지 않아서 감이 잘 안오는 것 같지만.. 공부한 내용만 봐도 왜 직접 서버컴퓨터를 만들지 않고 aws를 운영하는지 알 것도 같다. 나만해도 내 방에서 직접 서버를 만들고 배포까지 한거니까.. 세상은 넓고 똑똑한 사람도 참 많다..
6.20 라이브 강의에서 aws를 왜쓰는지! s3는 뭔지! 옵션들은 왜 있는건지에 대해서 배울 수 있었다. 또 어떻게 학습하면 좋은지도 많이 알려주셨다. 이유를 알고 사용하니까 확실히 이해가 잘됐고, 수업도 재미있었다.
6.21 도커를..배우긴 했는데.. 그냥 사용법을 배웠다.. 그래서 이걸 지금 내가 왜 쓰고있는지 쓰면 뭐가 좋은지는 잘 모르겠다.. 흠
6.24 이게 뭐지 싶다
