
2024.6.11
~ 2024.6.14
3tier-architecture
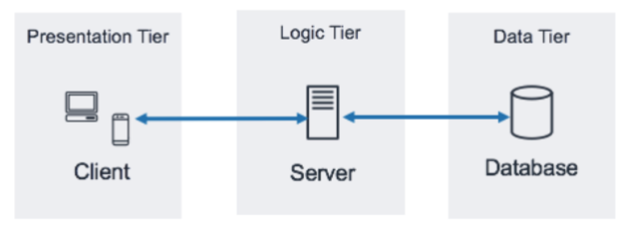
-
Presentation Tier (프레젠테이션 계층) : 첫번째 계층. Client.
일반 사용자가 직접 엑세스 할 수 있는 프레젠테이션 계층으로 컨텐츠를 HTML, CSS, JS 형식으로 브라우저에 전송하는 계층이다. -
Application Tier (애플리케이션 계층) : 두번째 계층. Application. = Logic tier
비즈니스 로직이 실행되는 계층으로 데이터 처리, 비즈니스 규칙, 데이터 변환 등의 기능을 수행한다. 프레젠테이션 계층과 데이터 계층을 중개하며 주로 서버측에서 동작한다. 웹서버, 애플리케이션 서버, api서버로 예를 들 수 있고, C#, java, python 등이 있다. -
Data Tier (데이터 계층) : 세번째 계층. 데이터 스토리지 계층.
db와의 상호작용을 담당하는 계층으로 데이터의 조회, 업데이트, 삭제 등의 작업을 수행한다. 일반적으로 DBMS(data base management system)을 사용한다. MySQL, PostgreSQL, Oracle DB등이 있다.
https://sunrise-min.tistory.com/entry/3-Tier-Architecture-정의-및-구성방식
백엔드라고 하면 보통 웹 서버와 데이터베이스로 나뉘고, 서버가 터진다 라는 말은 둘 중에 하나가 문제가 생겼다는 것을 의미한다.
오류를 발생시키지 않고 문제를 잘 해결하려면 데이터의 구조와 설계를 잘 알아야 한다.
Database, DB
데이터베이스에서 데이터는 말 그대로 특정 데이터를 의미하며 베이스는 창고라는 의미이다. 즉, 데이터를 저장하는 창고를 DB라고 한다.
특징
- 효율적인 데이터 관리
- 데이터를 통합하여 관리
- 데이터 누락 및 중복 방지
- 여러 사용자가 실시간으로 데이터 사용 가능
- DB 이전에는 파일 형태로 데이터를 관리 했고, 그래서 업데이트가 일어나면 이전 버전의 데이터를 알 수 없었다.
위에 적힌대로 DB에는 여러 사용자가 함께 접근해서 동시에 상호작용이 일어나게 될 수도 있다. 그럴 때 발생할 수 있는 여러 문제를 방지하기 위한 특징이 ACID이다.
-
Atomicity 원자성
- 일반적으로 원자성은 더이상 쪼갤 수 없는 무언가를 의미한다.
- GPT : 트랜잭션은 완전히 완료되거나 전혀 실행되지 않아야 합니다. 즉, 트랜잭션 내의 모든 작업이 성공적으로 완료되거나 모두 롤백되어야 합니다. 이로 인해 트랜잭션이 중간에 실패할 경우 데이터베이스가 일관성 없는 상태에 놓이는 것을 방지할 수 있습니다.
- Multi thread가 원자적인 연산을 실행할 때 다른 thread에서 절만만 완료된 연산을 관찰 할 수 없다. 그래서 실행 전과 후만 존재하는 경우를 의미한다.
그러나 ACID에서는 의미가 다르다. 누군가 계좌에서 돈을 타인에게 입금하려하면 자신의 계좌에서 인출 -> 타인의 계좌에 입금
두개의 과정을 거쳐야 하는데, 원자성에 따르면 이 두 작업중 하나라도 실패하면 전체가 롤백 되어야 한다. 이렇게 해서 인출만 일어나거나 입금만 일어나는 상황을 방지한다.
-
Consistency 일관성
- 테이블에 변경 사항을 적용할 때 미리 정의된, 예측할 수 있는 방식만 취한다. 일관성이 확보되면 데이터 손상이나 오류 때문에 테이블 무결성에 의도치 않은 결과가 생기지 않는다.
- 누군가 자신의 계좌에서 만원을 인출하려 하는데, 잔고가 천원 밖에 없다면 요청은 실패해야한다. 이렇게 은행 잔고는 마이너스가 될 수 없도록 규칙을 정하는 것이 일관성이다.
-
isolation 고립성
- DB에는 하나의 컴퓨터만 접속하지 않는다. 여러 Client가 접근하는데 이때 동일한 record(document)에 접근하면 동시성 문제가 생긴다. 만약 동시에 접근이 일어나더라도 서로 격리되는 것을 고립성 이라고 한다.
- 특정 게시물의 조회수를 갱신할 때, 현재 게시글의 조회수가 42인데 동시에 두 user가 게시물에 접근하면 44가 되어야 한다. 그러나 고립성이 보장되지 않으면 43이 된다. 그래서 격리성을 직렬성 이라고 표현하기도 한다. 다만 고립성을 보장하다보면 성능 손해가 생길 수 있다.
-
Durability 영구성
- 시스템 오류가 발생해도 디비에 접근하여 실행이 됐다면 데이터에 적용된 변경사항은 저장되도록 보장하는 것을 말한다. Data 가 손실될 염려 없이 안전한 저장소를 제공하는 것이다. 지속성은 성공적으로 commit 된 데이터는 H/W 결함이 발생하거나, DB 가 죽더라도 보존되어야 하며 SSD 와 같은 비휘발성 저장소에 기록됐다는 뜻이다.
- 누군가 타인의 계좌로 입금을 했고 성공했다면 이 그 내역은 영구적으로 저장되어야 한다. 서버가 갑자기 다운되거나 장애가 발생해도 완료된 결과는 손실되지 않아야 한다.
역사(?)
db가 어떻게 발전되었는지를 다 아는것은 하나도 중요하지 않지만 어떻게 발전 되었는지를 아는것은 db를 이해하는데 도움이 될 수 있다.
- 파일시스템 -> 네트워크 DBSM -> 계층 DBSM -> 관계 DBSM -> 객체 DBSM -> 객체관계 DBSM -> NoSQL DBSM -> NewSQL DBSM -> vector db
이중 관계형 DBMS가(이) 현재까지도 많이 사용되고 있다. 각각의 DBSM은 특징이 있으니 내가 필요한 db의 특성에 따라 사용하는 것이 좋다.
데이터 모델
역사에서 살펴본 것과 같이 데이터에도 여러 모델이 존재한다. 데이터를 어떻게 저장하고 관리하는지에 대한 방법의 차이이다.
-
계층형 데이터 모델
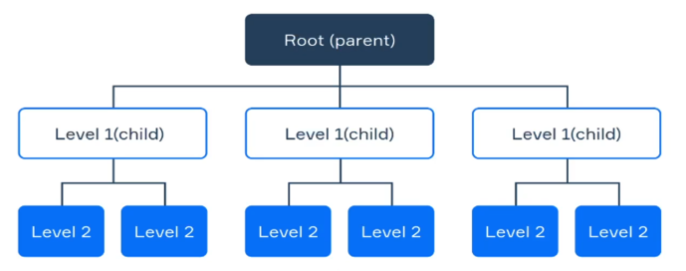 데이터를 트리 구조로 표현하며 각 레코드는 하나의 상위 레코드를 가진다. 즉, 부모-자식 관계가 정의되어있다. 윈도우 파일 시스템의 디렉터리 구조와 유사하다. 정보를 디렉터리 형태로 분류해서 북잡한 구조를 묘사 할 수 없다는 단점이 있다. 그래서 db로 활용되기 보다 데이터를 저장하는 방식이라고 생각하는게 맞다.
데이터를 트리 구조로 표현하며 각 레코드는 하나의 상위 레코드를 가진다. 즉, 부모-자식 관계가 정의되어있다. 윈도우 파일 시스템의 디렉터리 구조와 유사하다. 정보를 디렉터리 형태로 분류해서 북잡한 구조를 묘사 할 수 없다는 단점이 있다. 그래서 db로 활용되기 보다 데이터를 저장하는 방식이라고 생각하는게 맞다. -
네트워크형 데이터 모델
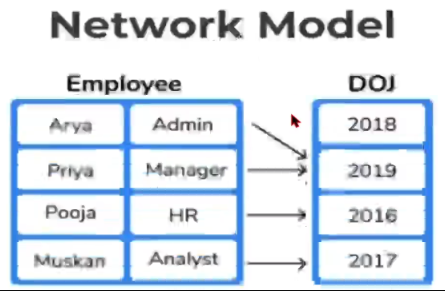
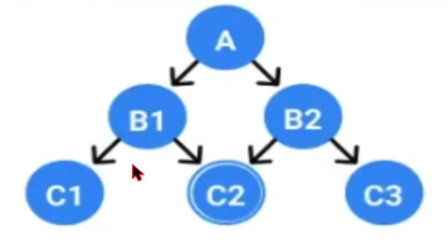
계층형 데이터 모델과 유사하지만, 각 레코드가 여러 부모 레코드를 가질 수 있어서 좀 더 복잡한 구조를 나타낼 수 있다. 계층형 데이터베이스의 단점을 보완하기 위해 자료간 연결을 망network형태로 자유롭게 연결하도록 개선했다. 각 레코드의 관계를 명시적으로 정의하며, 네트워크 형태의 그래프로 표시된다.
자료구조 변경시 디스크에 저장된 데이터의 물리적 구조를 재구성 해야하는 번거로움이 존재한다. -
관계형 데이터 모델
표 형태로 데이터를 저장하고 SQL(Structured Query Language)를 사용하여 데이터를 조작한다. 가장 널리 사용되는 데이터 모델 중 하나로 관계형 데이터베이스 시스템 RDBMS에서 지원한다.
테이블의 형태로 데이터를 저장하며 각 테이블은 레코드(행)와 필드(열)로 구성된다. 테이블 간의 관계를 정의하여 데이터를 관리한다.
굉장히 심플하며 복잡한 구조를 쉽게 나타낼 수 있기 때문에 사용승이 뛰어나다. 보통 사용성이 높으면 속도가 느리다거나 하는 단점이 있지만 그런것도 없다. 그래서 현재로서는 관계형 데이터 모델을 대체할 이유가 없기 때문에 지금도 널리 사용되고 있다.
엑셀의 형태를 생각하면 이해하기 쉽다. -
객체 지향형 데이터 모델
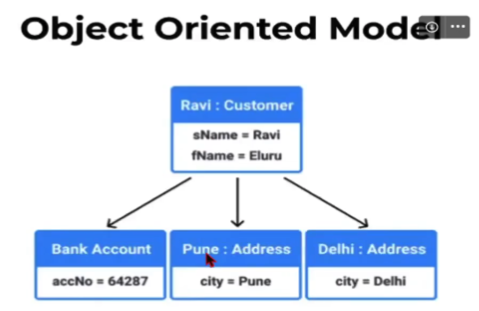 현실 세계의 개체와 그들간의 상호작용을 모델링한다. 객체지향 언어가 퍼지면서 디비도 객체 그 자체를 저장하면 되겠다는 아이디어로 생겨났다. 그래서 클래스와 객체의 개념을 기반으로 하며 데이터와 동작을 캡슐화하고 객체 간의 관계를 강조한다.
현실 세계의 개체와 그들간의 상호작용을 모델링한다. 객체지향 언어가 퍼지면서 디비도 객체 그 자체를 저장하면 되겠다는 아이디어로 생겨났다. 그래서 클래스와 객체의 개념을 기반으로 하며 데이터와 동작을 캡슐화하고 객체 간의 관계를 강조한다.
위 예시로 보면 라비라는 소비자의 데이터에 성과 이름이 들어있고, 해당 고객 데이터 객체는 두개의 주소객체 + 하나의 은행객체와 연결되어 있다. 이렇게 객체 지향형 데이터 모델은 한 객체가 여러 객체와 관계를 맺을 수 있다.
관계 지향형 데이터 모델과 비슷해보이는데, 객체간의 관계인지 테이블 간의 관계인지의 차이가 있다.
-> 결론적으로는 관계형 데이터베이스가 2차원의 이해하기 쉬운 표 형태로 데이터를 저장하면서도 복잡한 자료의 데이터를 정교하게 조합할 수 있는 특징이 있어서 많이 사용되고 있다.
DBMS
Database Management System
DBMS는 말그대로 데이터베이스 관리 시스템이다. 데이터의 저장, 검색, 업데이트, 관리를 위한 소프트웨어로 대용량 데이터의 효율적인 처리와 접근, 무결성, 보안, 백업및 복구 기능을 제공한다.
우리가 보통 db를 사용한다고 할 때 진짜 의미는 DBMS를 사용하는 거다. 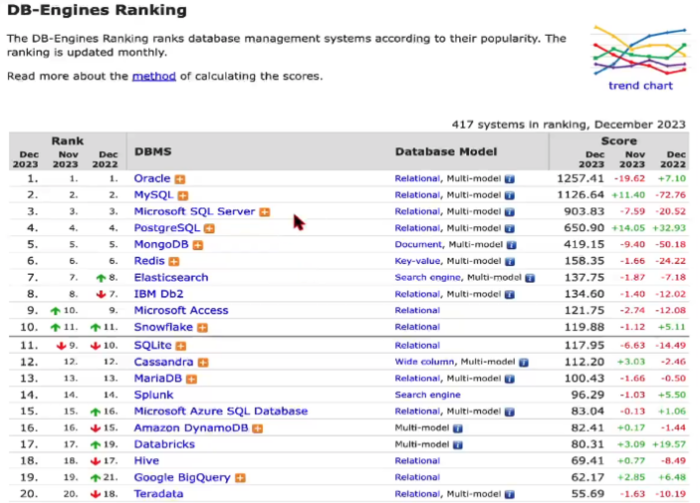 DB자체는 어떠한 데이터의 저장소를 말하는거고 그 데이터를 관리 할 수 있도록 서비스를 제공하는것이 DBMS이다.
DB자체는 어떠한 데이터의 저장소를 말하는거고 그 데이터를 관리 할 수 있도록 서비스를 제공하는것이 DBMS이다.
위 이미지는 DBMS랭킹이다. 강사님이 정리해주신 순위별 특징은 아래와 같다. 여기에 설명해주신 첨언을 붙여본다.
1. Oracle Database
- 용도: 대형 기업이나 복잡한 애플리케이션에 적합하며, 고성능, 대규모의 트랜잭션 처리와 데이터 웨어하우징에 자주 사용됩니다.
- 특징:
- 강력한 트랜잭션 관리, 높은 데이터 무결성 및 보안 기능을 제공합니다.
- 확장성이 뛰어나며, 다양한 운영 체제에서 실행됩니다.
- PL/SQL이라는 Oracle 전용 프로그래밍 언어를 사용합니다.
- 비싼 라이선스 비용이 있지만, 대규모 엔터프라이즈 환경에서의 신뢰성과 성능은 매우 높습니다.
오라클은 오픈소스로 제공되던 2위인 MySQL을 인수했다. 그래서 현재 1위로 보이는 것이다. 기업들이 오라클을 사용하는 이유는 디비를 관리하기 위함이다. 예를들어서 은행같은 곳은 디비가 굉장히 중요하다. 그래서 실제로 관리에 많은 비용을 들이고 디비 마스터 같은 자격증도 있을 정도이다. 이렇게 중요하기 때문에 큰 비용을 내서라도 관리를 해주는 회사와 조인을 해서 관리를 받는다.
2. MySQL
- 용도: 주로 웹 애플리케이션 및 소규모에서 중간 규모의 프로젝트에 사용됩니다.
- 특징:
- 오픈 소스이며, 사용이 쉬워 소규모 애플리케이션에 인기가 많습니다.
- PHP와의 통합이 용이하여 웹 개발에 자주 쓰입니다. (LEMP Stack)
- 비교적 가벼우면서도 성능이 좋으며, 다양한 운영 체제를 지원합니다.
- 대규모 데이터베이스와 고급 기능이 필요한 환경에는 다소 제한적일 수 있습니다.
오픈소스이다보니 데이터를 관리하는 측면에서 조금 약하다. ( 여기서 데이터를 관리한다는 것은 뒷부분에도 나오지만 데이터 분석, 속도, 보안 등을 말한다. ) 하지만 라이센스가 무료라는 장점이 있어서 보통 개발자를 준비하는 사람들이 많이 이용한다. 하지만 회사에서 사용할 때는 비용을 지불해야 한다.
추가로 이렇게 처음에 백앤드를 구축 할 때 가장 기본적으로 사용되는 오픈소스로 구성되는것을 LEMP스택 이라고 한다. Lginx, MySQL, PHP를 활용한 웹 애플리케이션을 위한 오픈 소스 소프트 웨어 스택 서비스이다.
3. Microsoft SQL Server
- 용도: 주로 중대형 기업에서 사용되며, .NET과 같은 Microsoft 기술과 잘 통합됩니다.
- 특징:
- Windows 기반 시스템에 최적화되어 있어, Microsoft 환경에서 뛰어난 성능을 발휘합니다.
- 사용자 친화적인 관리 도구와 강력한 보안 기능을 제공합니다.
- 데이터 웨어하우징, 비즈니스 인텔리전스, 데이터 분석에 유용한 기능을 포함하고 있습니다.
마지막 특징이 핵심이다. 만약 mysql과 같은 오픈소스를 사용하면 데이터 분석 등은 직접 해야하는 경우게 많은데, 그것을 지원해주는 디비를 사용하면 굳이 그런 기능을 직접 구현하지 않아도 된다. (유료닉가)
4. PostgreSQL
- 용도: 복잡한 쿼리와 대규모 데이터베이스 관리가 필요한 경우에 적합합니다.
- 특징:
- 객체-관계형 DBMS로, 확장 가능한 고급 기능을 제공합니다.
- 오픈 소스이며, SQL 표준을 잘 준수합니다.
- 복잡한 데이터 타입과 사용자 정의 함수를 지원합니다.
- 거대한 데이터 세트와 복잡한 쿼리에 적합하며, 높은 확장성과 성능을 자랑합니다.
강사님피셜 꼭 사용해봤으면 하는 DBSM중 하나이다. 쿼리가 살짝 다르다. ( 배우기 어렵다는 소리 )
5. MongoDB
- 용도: 실시간 분석, 대규모 데이터 처리가 필요한 애플리케이션에 적합합니다.
- 특징:
- NoSQL 데이터베이스 중 하나로, 문서 지향적 구조를 갖고 있습니다.
- 스키마가 없어 데이터 구조가 유연하고, 개발과 확장이 쉽습니다.
- JSON 형식의 문서를 사용하여 데이터를 저장하며, 데이터 샤딩을 지원합니다.
- 대용량 데이터 처리와 실시간 분석에 최적화되어 있습니다.
nosql이다. document 베이스의 데이터 구조로, 디비를 만들때는 원래 스키마로 구조를 반드시 설정해줘야하는데 그렇지 않은것들을 nosql이라고 한다. ( node.js할 때 생각해보면 그때그때 필요한 형태로 만들어서 사용했지 고정된 구조가 없었다. ) 빅데이터를 겨냥하고 만들어진 DBSM이라 데이터샤딩(분산)을 기본적으로 지원한다. 로그 데이터가 빠르게 쌓일수록 실시간으로 분석해서 빠르게 대응 할 수 있도록 도와준다.
6. Redis (Remote Dictionary Server)
- 용도: 고성능 키-값 저장소로, 주로 캐싱, 세션 관리, 게임 리더보드, 실시간 애플리케이션 등에서 사용됩니다.
- 특징:
- 인메모리 데이터 스토어로, 매우 빠른 읽기와 쓰기 속도를 제공합니다.
- 간단한 키-값 구조부터 리스트, 세트, 해시, 정렬된 세트 등 다양한 데이터 타입을 지원합니다.
- 데이터 지속성을 위해 디스크에 스냅샷을 저장하거나 변경 사항을 기록합니다.
- 마스터-슬레이브 복제, 자동 파티셔닝 기능을 지원하여 확장성이 뛰어납니다.
레디스도 nosql이다. 주로 키 밸류 형태로 캐싱한다라고 말한다. 예를들어, 게임에서 랭킹이 수시로 바뀌는데 그것들을 유저에게 공급하기 위해서 = 데이터를 전송하기 위해서 키 밸류 형태의 캐시서버를 사용한다.
배달의 민족에서 보면 라이더의 현재 위치를 보여주는데 그것이 부드럽게 이어지지 않고 몇초단위로 끊겨서 나타나게 된다. 즉 실시간 까지는 아니다. 이때 래디스 같은 캐시 서버를 이용해서 푸시로 계속해서 요청을 보내면 5초마다 요청을 보내고 업데이트하는 식이다. 인메모리가포인트다. 매우 빠르지만 데이터에 대한 유실이 조금 높다.
7. Elasticsearch
- 용도: 분산 검색 엔진으로, 복잡한 검색, 데이터 분석, 로그 및 데이터 집계에 사용됩니다.
- 특징:
- RESTful API를 통해 데이터 인덱싱, 검색, 분석 기능을 제공합니다.
- JSON 형식의 문서를 인덱싱하며, 풀 텍스트 검색 기능이 강력합니다.
- 높은 확장성과 실시간 분석 능력을 갖고 있습니다.
- ELK(Elasticsearch, Logstash, Kibana) 스택으로 널리 사용되며, 대용량 데이터에 적합합니다.
Elasticsearch는 로그 데이터를 쌓고 나서 그것을 분석할 때 많이 사용한다. ELK스택은 Elasticsearch에 데이터를 저장하고, Logstash로 그것을 불러오고, Kibana로 시각화 하는것을 말한다. 백엔드를 목표로 하고 있다면 꼭 사용해봤으면 하는 것 중 하나이다.
키바나 대시보드로 검색해보면 이렇게 예시들이 많이 나온다. 시피유 점유율이나 서비스가 잘 돌아가고 있는지 전체적인 구성 상황에 대해 볼 수 있는 기능을 제공한다. 좀 더 나아가면 요즘에는 grafana도 많이 사용한다. 대부분 기술력이 높은 회사들은 이런것들을 모니터링 한다. 백엔드는 결국 트래픽을 관리하는게 중요하기 때문에 이런것들을 알아놓는것이 좋다.
8. SQLite
- 용도: 경량, 자체 포함, 서버리스, 제로-구성 데이터베이스로, 임베디드 시스템 및 모바일 애플리케이션에 주로 사용됩니다.
- 특징:
- 파일 기반의 데이터베이스로, 별도의 서버 설정이 필요 없습니다.
- 작고 가볍지만, SQL 표준을 상당 부분 지원합니다.
- ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션을 지원합니다.
- 설치가 필요 없으며, 매우 적은 리소스를 사용합니다.
가볍게 구축할 수 있는 DBSM으로 가벼워서 빠르게 적용해서 사용 할 수 있다.
9. Snowflake
- 용도: 클라우드 기반의 데이터 웨어하우스로, 대규모의 데이터 저장, 분석 및 공유에 사용됩니다.
- 특징:
- 클라우드에서 완전 관리되는 서비스로, 유연한 확장성을 제공합니다.
- 데이터 웨어하우징 및 빅데이터 분석에 최적화되어 있습니다.
- 별도의 하드웨어나 소프트웨어 설치 없이 사용할 수 있습니다.
- 고유한 아키텍처를 사용하여, 저장, 컴퓨팅, 서비스 계층을 분리합니다.
유료이며, 저장에 특화되어 있다. 굉장히 만은 데이터를 빠르게 저장할 수 있게 지원한다. SASS베이스로 설치없이 사용 할 수 있다. 원래 데이터 엔지니어를 이용해서 데이터를 저장하고 관리하는데, 그러한 비용을 줄여주는 셈이다. (인권비다운..쩝)
10. Cassandra
- 용도: 대규모 분산 데이터베이스로, 큰 규모의 데이터를 관리하고, 높은 가용성과 확장성이 필요한 환경에서 사용됩니다.
- 특징:
- NoSQL 데이터베이스로, 분산 환경에서 뛰어난 확장성과 성능을 제공합니다.
- 데이터는 여러 노드에 걸쳐 분산 저장되며, 하나의 노드가 실패해도 데이터 손실 없이 운영됩니다.
- 컬럼 기반의 데이터 스토리지 모델을 사용하며, 행의 각 열은 독립적으로 저장됩니다.
- 높은 쓰기 및 읽기 처리량을 지원하며, 데이터 복제를 통해 고가용성을 보장합니다.
- 특히, 대규모 온라인 서비스, IoT, 시계열 데이터 등의 처리에 적합합니다.
대규모다. 분산이라는게 들어가면 보통 빅데이터로 저장할때 많이 사용한다고 보면 된다.
카산드라 아키텍쳐라고 검색해보면 이미지들이 많이 나온다. 아키텍쳐만 봐도 어느정도 이해하는데 도움이 된다. 카산드라는 위 이미지처럼 각 노드가 존재하고, 노드끼리 연결이 되어있음으로 빠르게 정보를 주고 받을 수 있다.
11. MariaDB
- 용도: MySQL의 포크로, 웹 기반 애플리케이션, 데이터 웨어하우징, 개인 및 소규모 기업용 데이터베이스로 사용됩니다.
- 특징:
- 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)입니다.
- MySQL과의 높은 호환성을 유지하면서도, 여러 가지 새로운 기능과 최적화가 추가되었습니다.
- 스토리지 엔진의 다양성을 지원하며, 성능과 보안 면에서 개선되었습니다.
- 강력한 쿼리 최적화, 복제 및 샤딩 기능을 제공합니다.
- 커뮤니티 중심의 개발 모델을 따르며, MySQL 대비 개방적이고 확장성 있는 대안으로 자리잡고 있습니다.
오라클이 무료 서비스들을 인수해서 유료로 만드는 경우가 많아서, 그것을 대항하기 위해 무료로 만들어진 DBMS이다. MySQL을 포크해서 만들었어도 결국에는 mariadb에는 지원되지 않는 기능도 많기 때문에 한번 써보는건 추천하지만 그냥 흐름만 파악하고 넘어가길 바란다.
12. Apache Hive
- 용도: Hive는 Hadoop 위에 구축된 데이터 웨어하우스 시스템(조직의 의사결정 과정을 지원하기 위해 대량의 데이터를 통합, 저장 및 관리하는 중앙 저장소)으로, 대규모 데이터 세트의 저장, 쿼리 및 분석에 사용됩니다.
- 특징:
- Hadoop의 저장 시스템인 HDFS(Hadoop Distributed File System) 위에서 작동합니다.
- SQL과 유사한 HiveQL 쿼리 언어를 제공하여, SQL 사용자가 Hadoop 데이터를 쉽게 쿼리할 수 있게 해줍니다.
- Hive는 대량의 데이터를 처리할 수 있으나, 실시간 쿼리 처리에는 최적화되어 있지 않습니다.
- 배치 처리와 데이터 분석, 보고서 생성에 적합합니다.
- 데이터는 빅 데이터 환경에서의 병렬 처리를 위해 여러 노드에 분산 저장됩니다.
- Hadoop 생태계의 일부로서 복잡한 배치 처리 작업에 적합하며, 자체 인프라 관리가 필요합니다.
데이터를 그냥 저장하면 되지 뭐 잘할게있나? 라고 생각 할 수도 있는데, 대규모로 동시에 많은 유저가 쿼리를 발생시킨다고 생각해보면 그걸 처리 할 때 DB에는 많은 부담이 된다. 부담을 줄이기 위한 분산을 하둡이 굉장히 잘 처리한다. 보통 하둡 관련 엔지니어를 그 회사에서 뽑냐 안뽑냐로 이 회사가 빅데이터를 다루는지 아닌지를 판단해도 될정도로다.
쿼리(Query)는 데이터베이스에서 데이터를 검색하거나 조작하기 위해 사용되는 명령어
13. Google BigQuery
- 용도: BigQuery는 Google Cloud Platform의 완전 관리형 엔터프라이즈 데이터 웨어하우스로, 대용량 데이터 분석 및 SQL 쿼리 실행에 사용됩니다.
- 특징:
- 서버리스이며, 사용자는 인프라 관리에 대해 걱정할 필요가 없습니다.
- 빠른 속도로 대규모 데이터 세트에 대한 SQL 쿼리를 실행할 수 있습니다.
- 데이터 샤딩 및 복제를 자동으로 관리하며, 고가용성을 제공합니다.
- 대용량 데이터 세트에 대한 실시간 분석 및 인터랙티브한 데이터 탐색이 가능합니다.
- BigQuery ML을 통해 SQL 쿼리 내에서 머신러닝 모델을 생성하고 실행할 수 있습니다.
- BigQuery는 완전 관리형 서비스로서 복잡한 인프라 관리 없이 즉각적인 분석을 가능하게 합니다.
구글에서 사용한다고 한다. 머신러닝 모델을 생성하고 실행한다는게 중요한 부분이다. 머신 러닝 모델을 만든다면 직접 만들어도 되지만 위와 같은 빅쿼리엔진을 사용해서 모델링을 빠르게 구현 할 수도 있다
-> 결론적으로, 어떤 구조를 사용하고 싶으냐에 따라서 다른 DBSM을 사용해보는걸 추천한다.
RDBSM
특징
R은 relatinal이라는 뜻으로, 위에서 언급한 관계형 데이터 모델을 지원하는 관계형 데이터 베이스 관리 시스템이다. 우리는 앞으로 이것으로 DB를 공부한다. 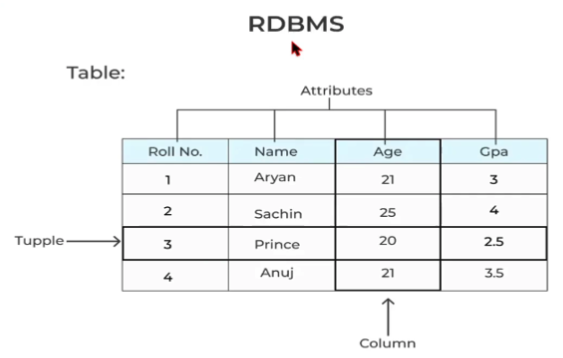
관계형 데이터베이스는 아까 말한것처럼 2차원 테이블 형태로 데이터를 구조화 하는 방식이다.
데이터는 속성과 해당 속성에 대응하는 데이터 값으로 이뤄져있다. 이미지와 같이 열Column과 행Row으로 구성되어 있다.
- column = attribute = field
- row = record = tuple
정리하면 데이터 베이스안에 데이터에 따라서 여러 테이블로 관리 할 수 있고, 그 안에 컬럼과 로우로 데이터를 세부적으로 구분한다.
스키마 Schema
스키마란 데이터베이스의 구조와 제약조건에 관해 전반적인 명세를 기술한 것 입니다. 상세하게 말하면, 개체의 특성을 나타내는 속성(Attribute)과 속성들의 집합으로 이루어진 개체(Entity), 개체 사이에 존재하는 관계(Relation)에 대한 정의와 이들이 유지해야 할 제약조건들을 기술한 것입니다.
쉽게 정리하여, DB내에 어떤 구조로 데이터가 저장되는가를 나타내는 데이터베이스 구조를 스키마라고 합니다.
출처: https://jwprogramming.tistory.com/47 [개발자를 꿈꾸는 프로그래머:티스토리]
테이블이 몇개고 행은 몇 고 열은 몇개고 컬럼에는 어떤 값이고 그게 문자열인지 숫자형인지같은 구조를 명시할 수 있다. (나중에 수정 가능) 즉, 테이블의 설계도라고 하면 될 것 같다.
-
물리적 스키마 : 데이터의 실제 저장과 관련된 부분으로 디스크에 올릴거냐 클라우드에 올릴거냐 저장 방식을 말한다.
-
논리적 스키마 : 테이블 간의 관계, 각 테이블의 속성과 데이터 타입, 제약 조건등을 정의하는 것을 말한다.
예를들어, 유저 네임을 중복 가능하게 할것인지, 중복이 되어도 문제가 없게 할것인지, 문자 수를 100으로 제한한다던지 등을 지정하는게 논리적 스키마다.
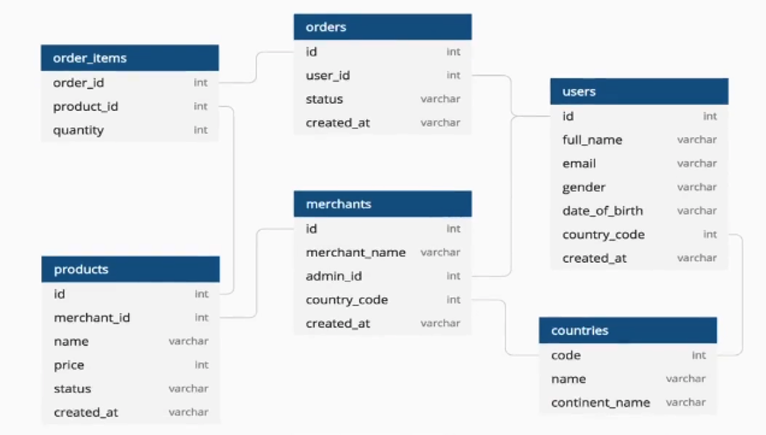
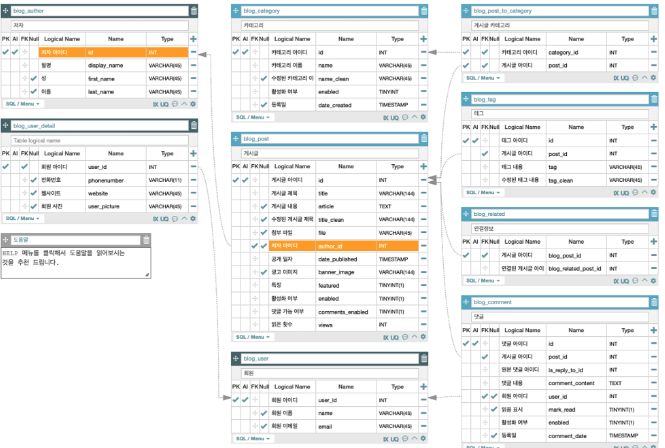
스키마는 이렇게 데이터의 구조만을 정의함으로 데이터 구조를 동일하게 만드는데 사용 된다. 위 이미지에는 6개의 테이블 안에 각각 어떤 컬럼이 들어가야하고 어떻게 FK로 연결되어있는지 확인 할 수 있다. 스키마를 만들 수 있는 여러 툴이 존재한다. (나중에 배울것.)
Structured Query Language SQL
데이터베이스에서 데이터를 관리하기 위해 사용되는 언어이다. SQL을 이용해서 데이터베이스에 질의, 업데이트, 삭제 등의 작업을 수행할 수 있다.
직역하면 구조화된 쿼리 언어 라는 뜻인데 결국에는 RDBMS에서 데이터를 조회하는 방법을 뜻한다.
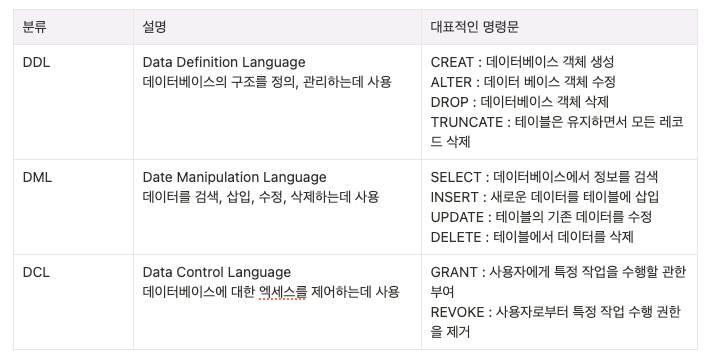
원래는 4가지지만 이렇게 크게 3가지로 분류하기도 한다.
- DDL
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), hire_date DATE );ALTER TABLE employees ADD COLUMN department VARCHAR(50);DROP TABLE employees;TRUNCATE TABLE employees; - DML
SELECT first_name, last_name FROM employees WHERE department = 'IT';INSERT INTO employees (employee_id, first_name, last_name, hire_date, department) VALUES (1, 'John', 'Doe', '2022-01-01', 'IT');UPDATE employees SET department = 'HR' WHERE employee_id = 1;DELETE FROM employees WHERE employee_id = 1; - DCL
GRANT SELECT ON employees TO username;REVOKE SELECT ON employees FROM username;
Index
데이터베이스에서 데이터 검색 속도를 빠르게 하기 위해 사용되는 객체로 특정 열에 대한 포인터를 포함한다.
트랜잭션
데이터의 상태를 변화시키는 하나의 작업 단위이다.
장점
데이터의 구조화와 언정성 측면에서 강력하다. 사용하기 쉽다.
단점
- 성능 : 대용량 데이터 처리나 복잡한 쿼리에 대한 성능이 다른 모델에 비해 낮다.
- 확장 어려움 : 수직적 확장이 한계가 있고, 수평적 확장은 복잡하고 비용이 많이 든다.
- 유연성 부족 : 스키마 변경이 어려워서 요구 사항 변경에 대응하기 어려울 수 있다.
- 복잡한 조인 : 복잡한 테이블 간의 조인은 성능에 부정적인 영향을 미친다.
- 고비용 : 서버 하드웨어 및 라이선스 비용이 상대적으로 높다.
예를들어, 기존의 게시글에 원래 좋아요가 없었는데 추가를 한다면 게시글 테이블 안에 좋아요를 추가해야 한다. 이렇게 이후에 기능을 추가하면 column이 늘어나게 되는데 그때마다 스키마를 변경해야하고 외부 테이블과 연결이 되어있으면 그것까지 고려해야하기 때문에 힘들어 질 수 있다.
구성요소
- 데이터베이스
- 테이블
- 열
- 행
- 키
이중에서 키는 PK primary Key와 FK Foreign Key가 있다.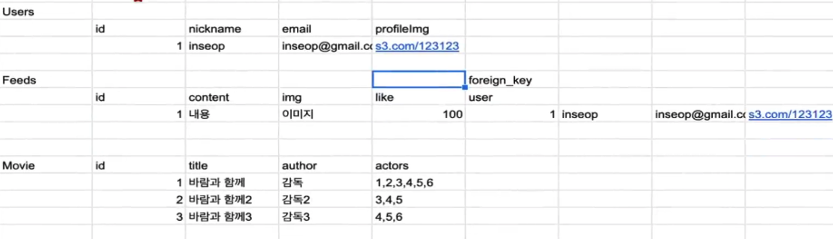 이게 현재 나의 DB라고 생각해보자. 각각 Users, Feeds, Movie라는 table이 존재한다. 위에 있는 id가 PK다.
이게 현재 나의 DB라고 생각해보자. 각각 Users, Feeds, Movie라는 table이 존재한다. 위에 있는 id가 PK다.
- PK : 테이블 내에서 중복 할 수 없고, 행(=하나의 데이터)를 식별할 수 있는 유일한 값이다. 유니크한 값이면 사용 할 수 있다. 보통 id라고 만들거나 테이블이름_id로 만든다. (예. Users_id)
그리고 Feeds에서 현재 게시글을 작성한 유저에 대한 정보를 받아오고 싶으면 해당 유저의 PK를 가져와서 사용한다. 그러면 그게 FK가 된다. 이렇게 해서 테이블마다 데이터를 참조 할 수 있다.
- FK : 다른 테이블의 기본키를 참조하는 열이다. 즉, 두 테이블 간의 관계를 설정하는데 사용된다.
대표적인 RDBMS
-
MySQL
- 장점 : 오픈소스(무료)이고 사용방법이 간단해서 소규모 앱에 인기가 많다. PHP와의 통합웹 개발에 자주 쓰인다. 비교적 가벼우며 성능이 좋고 다양한 운영체제를 지원한다.
- 단점 : 대규모 데이터 베이스와 고급 기능이 필요한 환경에서 다소 제한적이다. 오픈소스라서 데이터 관리적인 측면에서 약하다. 회사규모에서 사용 할 때는 관리비를 내야한다.
-
PostgreSQL
- 장점 : 오픈소스(무료)이고 커뮤니티 지원이 활달하다. 고급 기능을 제공하며 복잡한 데이터 타입과 정의 함수를 지원한다. SQL 표준을 잘 준수하며 거대한 데이터 세트와 복잡한 쿼리에 적합하다. 높은 확장성과 성능을 자랑한다.
- 단점 : 설정이 복잡해서 초보자에게는 설정 및 최적화가 다소 복잡할 수 있으며 특정 읽기 작업에서 MySQL보다 성능이 낮아 질 수 있다.
-
Microsoft SQL Server
- 장점 : .NET과 같은 Microsoft기술과 잘 통합된다. Windows 기반 시스템에 최적화 되어있어서 Microsotf 환경에서 뛰어난 성능을 발휘한다. 사용자 친화적인 관리 도구와 강력한 보안 기능을 제공한다. 데이터 웨어하우징, 비지니스 인텔리전스. 데이터 분석에 유용한 기능을 포함한다. (유료라서 ㅋ)
- 단점 : 라이선스 비용이 높다. 주로 Windows환경에서 최적화 되어있어 다른 운영체제에서는 제약이 있을 수 있다.
-
Oracle Database
- 장점 : 강력한 트랜잭션 관리, 높은 데이터 무결성 및 보안기능 제공, 확장성이 뛰어나며 다양한 운영체제에서 실행, 대구묘 엔터프라이즈 환경에서의 신뢰성과 성능이 매우 높음.
- 단점 : PL/SQL이라는 Oracle 전용 프로그래밍 언어 사용함으로 초보자가 배우기 어렵다. 고도의 전문 지식이 필요하며 관리 해주는만큼 라이선스 비용이 매우 비싸다. 그래서 주로 금융권같이 DB가 매우 중요한 기업에서 사용한다.
-
SQLite
- 장점 : 오픈소스(무료)이고 파일 기반의 DB로 별도의 서버 설정이 필요없고 작고 가볍지만 SQL 표준을 상당부분 지원한다. ACID 트랜잭션을 지원하며 매우 적은 리소스를 사용한다. 설치가 필요 없다.
- 단점 : 고급 기능이나 병렬 처리 기능등이 부족하여 대규모 애플리케이션에는 적합하지 않고 동시 쓰기 작업에 대한 제약이 있다.
-> 강사님께서는 이중에 위의 2개는 꼭 사용해봤으면 좋겠다고 하셨다. 쿼리도 날려보고 아키텍쳐도 확인해보라.
MySQL
강의에서는 mysql을 배운다.
Workbench
 GUI환경에서 mysql을 다룰 수 있다.
GUI환경에서 mysql을 다룰 수 있다.
- 설치방법
- Homebrew 설치
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" - MySQL 설치
brew install mysql - MySQL 시작
brew services start mysql brew services stop mysql (끝낼 때) - 루트 비밀번호 설정
mysql -u root -pALTER USER 'root'@'localhost' IDENTIFIED BY 'class-password'; - 새로운 비밀번호를 설정한 후 MySQL을 끝냄
exit - mysql workbench 설치 https://www.mysql.com/products/workbench/
테이블만들기
 저 벤치 표시를 누르면 아래 같은 이미지가 뜸.
저 벤치 표시를 누르면 아래 같은 이미지가 뜸. 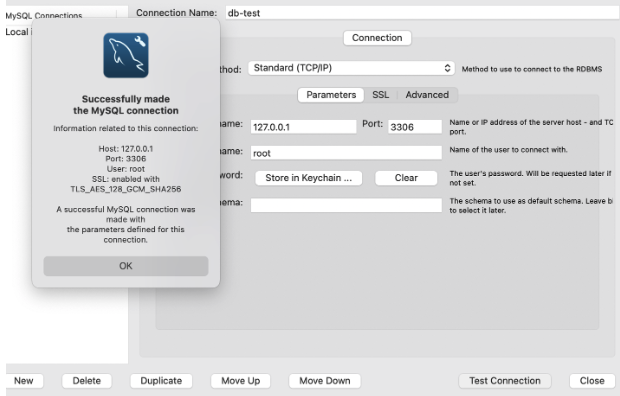 db와 연결되어있는지 확인도 할 수 있고 새로운 mysql 디비를 만들 수 있음. 위에는 현재 디비의 이름과 포트, 이름, root, 비밀번호도 입력하면 됨.
db와 연결되어있는지 확인도 할 수 있고 새로운 mysql 디비를 만들 수 있음. 위에는 현재 디비의 이름과 포트, 이름, root, 비밀번호도 입력하면 됨.
 그러면 이렇게 db를 gui로 볼 수 있음. 이제 SQL문을 사용해서 디비를 다루면 된다.
그러면 이렇게 db를 gui로 볼 수 있음. 이제 SQL문을 사용해서 디비를 다루면 된다.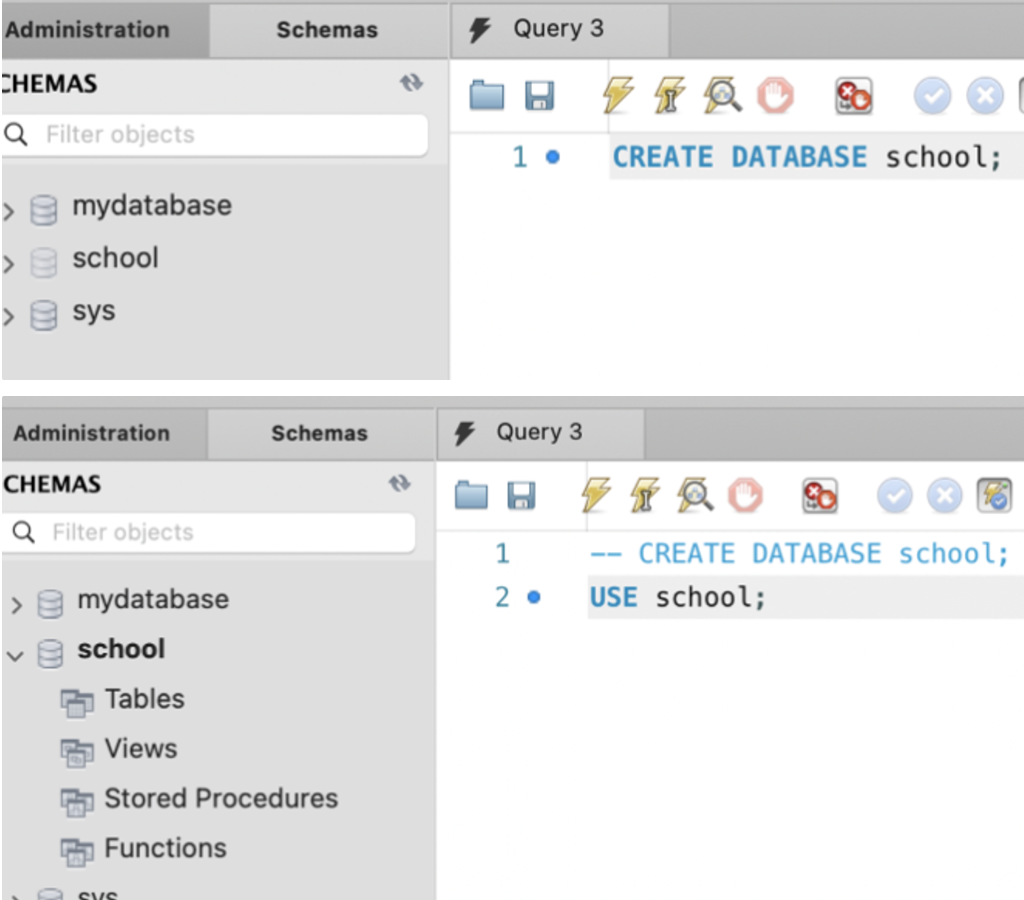 디비를 생성하고 디비에 접근함.
디비를 생성하고 디비에 접근함. 테이블을 만듬.
테이블을 만듬.
실제로 데이터를 삽입함.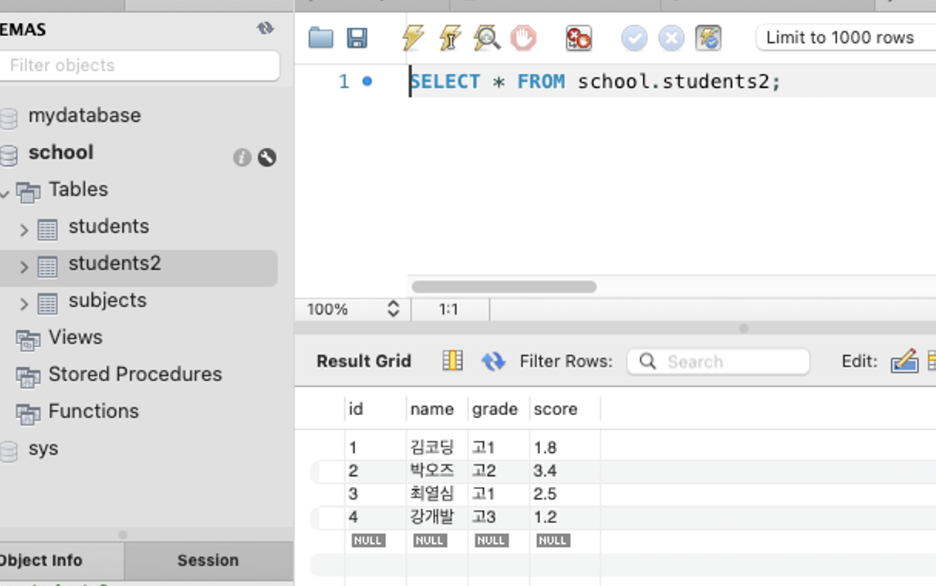 조회해봄
조회해봄
user만들기
여기서 말하는 users는 db를 사용할 사람을 말한다. 디비에 접근하고,
디비에 접근하고,
 모든 현재 사용중인 user를 검색함.
모든 현재 사용중인 user를 검색함.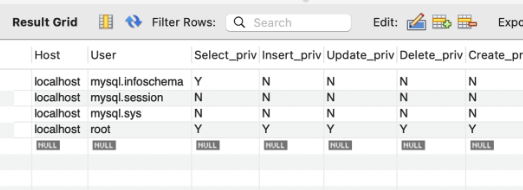 그러면 이렇게 현재 어디에 서버가 열려있고, 유저는 누구고 권한은 어떤지 알려준다. (아까 디비를 127.0.0.1에 열었으니까 localhost다.)
그러면 이렇게 현재 어디에 서버가 열려있고, 유저는 누구고 권한은 어떤지 알려준다. (아까 디비를 127.0.0.1에 열었으니까 localhost다.) 유저는 이렇게 생성함. 비번도 함께 추가함.
유저는 이렇게 생성함. 비번도 함께 추가함.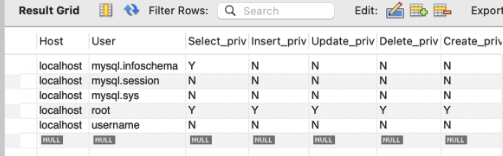 추가된 모습.
추가된 모습. 권한 부여할 때 사용하는 SQL
권한 부여할 때 사용하는 SQL 유저 삭제
유저 삭제
MySQL 데이터타입
공식사이트에 가면 사용할 수 있는 데이터타입에 대해서 자세히 나와있다.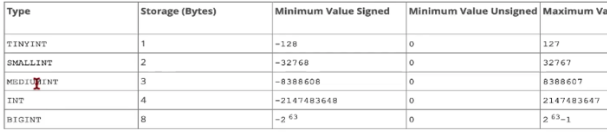 보면 알 수 있지만 같은 숫자라도 타입에 따라서 크기가 다르다. 데이터가 많아질수록 공간이 중요해지기 때문에 치밀하게 짜는게 중요하다. 과거에는 그랬다.
보면 알 수 있지만 같은 숫자라도 타입에 따라서 크기가 다르다. 데이터가 많아질수록 공간이 중요해지기 때문에 치밀하게 짜는게 중요하다. 과거에는 그랬다.
요즘에는 그거보다는 서비스를 빠르게 구축하고 배포하고 수정할 줄 아는 능력이 더 중요한거 같다고 강사님이 말했다.
숫자형
 표를 보면 불리언도 숫자로 나타낸다. 노란색이 주로 사용하는 데이터타입이다.
표를 보면 불리언도 숫자로 나타낸다. 노란색이 주로 사용하는 데이터타입이다.
왜 그냥 INT를 사용하냐면, INT뒤에 있는 괄호에서 알 수 있듯이 숫자를 몇자리를 받을지 결정 할 수 있다. 만약에 공간이 남으면 없애주는 최적화 작업을 해준다.
문자형
 문자형도 마찬가지다. VARCHAR가 INT와 같이 최적화를 해주기때문에 주로 많이 사용한다. 그래서 가변 길이 문자열 저장이라고 되어있다.
문자형도 마찬가지다. VARCHAR가 INT와 같이 최적화를 해주기때문에 주로 많이 사용한다. 그래서 가변 길이 문자열 저장이라고 되어있다.
다만 최적화 작업이라는 것도 결국에는 별도의 과정이 필요하기 때문에 char를 정확하게 쓰는것이 더 속도가 빠를 수는 있다.
ENUM은 리스트 형태로 몇가지 문자열을 고정해놓고 그중에 하나만 사용 할 수 있도록 하는것.
날짜형
 날짜형은 DATE나 DATETIME을 많이 쓴다.
날짜형은 DATE나 DATETIME을 많이 쓴다.
데이트타임이 나타낼수있는 범위가 더 크다. 타입스탬프는 그에 비해서 좁다.
DATETIME
- 범위:
1000-01-01 00:00:00부터9999-12-31 23:59:59까지. - 저장 크기: 8바이트.
- 시간대에 무관:
DATETIME값은 시간대 변환 없이 그대로 저장된다. - 사용 사례: 특정 사건이 발생한 정확한 시점을 기록할 때 사용. 예를 들어, 사용자의 생일이나 기념일 등.
TIMESTAMP
- 범위:
1970-01-01 00:00:00부터2037-01-19 03:14:07까지. - 저장 크기: 4바이트.
- 시간대 인식:
TIMESTAMP는 UTC로 저장되며, 조회 시 서버의 시간대 설정에 따라 변환된다. - 자동 갱신:
INSERT나UPDATE연산 시 현재 시간으로 자동 갱신될 수 있다. - 사용 사례: 레코드의 생성 또는 수정 시간을 기록할 때 주로 사용. 예를 들어, 게시물의 작성 시간이나 마지막 수정 시간 등.
보통은 타입스탬프를 쓴다. 서비스를 만들 때 글로벌화를 고려해야 하기 때문이다. UTC를 기반으로 그 국가에 맞는 시간을 보여줘야한다. 자동갱신도 좋다. 예를들어 어떤 게시글을 수정하면 그 날짜도 변경해야하는데 그럴 때 타임스탬프가 더 유리하다.
-
DATETIME 사용 예시: 사용자 프로필
date_of_birth DATETIME: 사용자의 생일 데이터의 경우 회원 가입 이후 변경되지 않으며, 시간대에 영향을 받지 않는다.
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), email VARCHAR(100), date_of_birth DATETIME );
-
TIMESTAMP 사용 예시: 블로그 게시물
created_at TIMESTAMP: 게시물이 처음 생성된 시간. 이 필드는 게시물이 만들어질 때 현재 시간으로 자동 설정된다updated_at TIMESTAMP: 게시물이 마지막으로 수정된 시간. 이 필드는 게시물이 수정될 때마다 현재 시간으로 자동 갱신된다.
CREATE TABLE blog_posts ( id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(255), content TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP );
SQL
앞에서 테이블과 유저 만드는 방법을 살짝 알아봤는데, 다시 정리해보자.
테이블 생성
CREATE TABLE users (
user_id INTEGER PRIMARY KEY AUTO_INCREMENT,
username TEXT NOT NULL,
email TEXT NOT NULL,
age INTEGER
);데이터 생성
# 기본적인 INSERT문
INSERT INTO users (username, email, age) VALUES ('john_doe', 'john@example.com', 25);# 일부 컬럼에만 값 적용
INSERT INTO users (username, email) VALUES ('jane_doe', 'jane@example.com');#다수의 레코드 한번에 추가
INSERT INTO users (username, email, age) VALUES
('alice', 'alice@example.com', 30),
('bob', 'bob@example.com', 28),
('charlie', 'charlie@example.com', 35);# 중복된 레코드일 경우 레코드를 추가하지않도록 해서 에러 방지
INSERT IGNORE INTO users (username, email, age) VALUES ('john_doe', 'john@example.com', 25);
-> 이경우는 삽입하려는 레코드에 UNIQUE 제약이 있을 때 그것을 검사하여 존재하면 값을 수정하고, 아니면 똑같은 값이라도 추가한다.# 중복된 값이 있는 경우 해당 레코드를 업데이트
INSERT INTO users (username, email, age) VALUES ('john_doe', 'john@example.com', 25)
ON DUPLICATE KEY UPDATE age = 100;
-> 마찬가지로 유니크가 존재할 경우에 값을 업데이트 한다.# SET을 이용해서 데이터 삽입. 똑같음.
INSERT INTO users SET username='john', email='john@example.com', age=25;데이터 조회
# 모든 컬럼 조회
SELECT * FROM users;
# 특정 컬럼만 조회
SELECT user_id, username, email FROM users;# 중복 제거한 나이 조회
SELECT DISTINCT age FROM users;# 나이와 나이에 100을 곱한 값을 조회
SELECT age, age * 100 FROM users;
# AS를 사용하여 새로운 컬럼명 정의
SELECT age, age * 100 AS age100 FROM users;
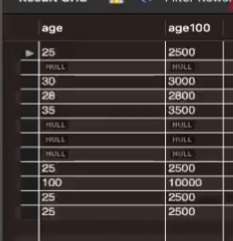 이렇게 AS로 이름 붙여서 컬럼으로 삼고 조회 할 수 있음.
이렇게 AS로 이름 붙여서 컬럼으로 삼고 조회 할 수 있음.
# 나이순으로 오름차순 정렬
SELECT * FROM users ORDER BY age;
# 나이순으로 내림차순 정렬
SELECT * FROM users ORDER BY age DESC;
# 여러 기준으로 정렬 (ASC: 오름차순, DESC: 내림차순)
SELECT * FROM users ORDER BY age ASC, created DESC;# 특정 조건에 맞는 데이터 조회
SELECT * FROM users WHERE age = 30;
# 특정 조건 이상 데이터 조회
SELECT * FROM users WHERE age >= 30;
# AND, OR를 사용한 복합 조건
SELECT * FROM users WHERE age = 33 AND name = 'Leo';
SELECT * FROM users WHERE age = 33 OR name = 'Leo';
# NOT을 사용한 부정 조건
SELECT * FROM users WHERE NOT age = 33;
# BETWEEN을 사용한 범위 지정
SELECT * FROM users WHERE age BETWEEN 20 AND 25;# 상위 5개의 데이터 조회
SELECT * FROM users LIMIT 5;
# 10번째부터 5개의 데이터 조회 (페이징)
SELECT * FROM users LIMIT 10, 5;# 나이별로 그룹화하여 그룹별 데이터 개수 조회 같은 값을 가진 행끼리 그룹으로 묶어준다.
SELECT age, COUNT(*) as user_count FROM users GROUP BY age; 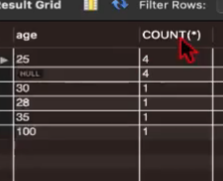 각 나이별로 몇명있는지 조회해줌.
각 나이별로 몇명있는지 조회해줌.
# 나이가 30 이상인 경우 '성인', 미만인 경우 '미성년자'로 변환하여 조회
SELECT
name,
age,
CASE WHEN age >= 30 THEN '성인' ELSE '미성년자' END AS age_group
FROM users;# users 테이블과 orders 테이블을 user_id를 기준으로 조인
SELECT users.name, users.age, orders.order_id
FROM users
JOIN orders ON users.user_id = orders.user_id;
-> 살짝 이해가 어려운데, users랑 orders table을 연결을 할건데, users의 userid랑 orders의 orderid랑 같은거니까 그렇게 매치해서 유저네임, 유저나이, 올더아이디를 보여줘라. 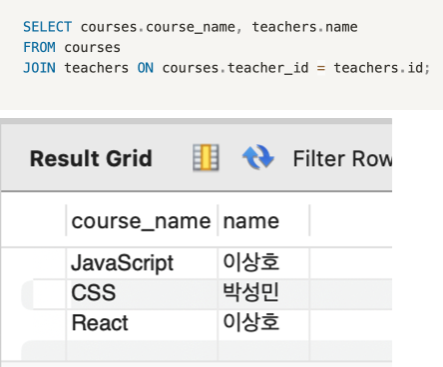 조금 다른 예시지만 결과보면 좀 이해될지도
조금 다른 예시지만 결과보면 좀 이해될지도
# 나이에 따라 내림차순으로 순위 부여하여 조회
SELECT
name,
age,
ROW_NUMBER() OVER (ORDER BY age DESC) AS rank
FROM users;
-> users에서 나이랑 이름이랑 가져와서 내림차순으로 rank라는 이름으로 정렬해줘 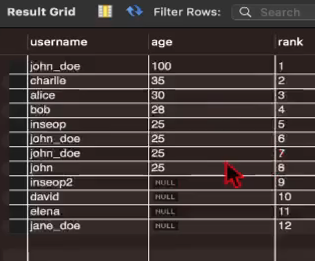
데이터 업데이트(수정)
SET SQL_SAFE_UPDATES = 0; (세이프 모드 비활성화)
-> 데이터를 수정하는건 되돌릴 수 없기 때문에 기본적으로 막혀있음. 0=false로 바꿔주면 적용됨.# users 테이블에서 id가 1인 레코드의 이름을 'John'으로 수정
UPDATE users
SET name = 'John'
WHERE id = 1;# age가 25 이상인 모든 레코드의 salary를 50000으로 수정
UPDATE users
SET username = 'senior'
WHERE age >= 60;# 업데이트된 레코드 수 반환
SELECT ROW_COUNT(); 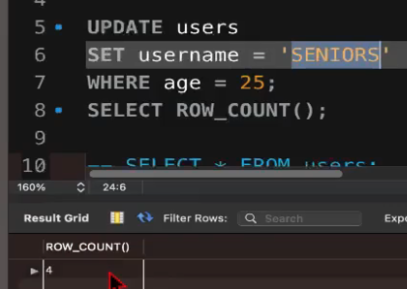
# user의 age가 60 이상인 경우 'senior'로 username 설정,
# 그 외의 경우 username은 'young'로 설정
UPDATE users
SET username = CASE
WHEN age >= 60 THEN 'senior'
ELSE 'young'
END;# age가 30인 레코드 중에서 가장 나이가 어린 5명의 salary를 60000으로 수정
UPDATE users
SET username = 'top5_young_people'
WHERE age = 30
LIMIT 5;
-> 위에서부터 5개만 딱 센다.# 다른 서브쿼리 결과에 따라 업데이트
UPDATE products
SET price = price * 1.1
WHERE category_id IN (SELECT id FROM categories WHERE name = 'Electronics');
-> WHERE 뒤에 IN을 써서 서브쿼리를 하나 더 만듬.# 정규 표현식을 활용하여 업데이트
UPDATE users
SET email = CONCAT(email, '_new')
WHERE email REGEXP '@example\.com$';
-> 이메일란인데 이이디부분만 받았을 때 뒤에 이메일 추가# 다양한 조건에 따라 다른 업데이트 수행
UPDATE products
SET price = CASE
WHEN stock < 10 THEN price * 1.1
WHEN stock >= 10 AND stock < 50 THEN price * 1.05
ELSE price
END;데이터 삭제
# 특정 테이블에서 모든 행 삭제
DELETE FROM users;# 특정 조건을 만족하는 행 삭제
DELETE FROM users WHERE age < 18;# 특정 개수 이상의 행을 삭제하지 않도록 제한
DELETE FROM orders WHERE status = 'canceled' LIMIT 100;# 다른 테이블과 조인하여 삭제
DELETE e FROM employees AS e
JOIN departments AS d ON e.department_id = d.id
WHERE d.name = 'Marketing';
-> 임플로이는 e고 이팔트먼트는 d인데, 걔네둘이 id가 같다고 연결한다. 그리고 나서 d의 name이 marketing인거만 지워라. 즉 고용인과 부서를 연결하고 고용인의 부서중에서 마켓팅 부서인사람은 다 지워라.ERD
Entity Relationship Diagram
db구조를 한눈에 볼 수 있도록 시각적으로 표현하는 도구
-
Draw.io https://app.diagrams.net/, https://dbdiagram.io/home
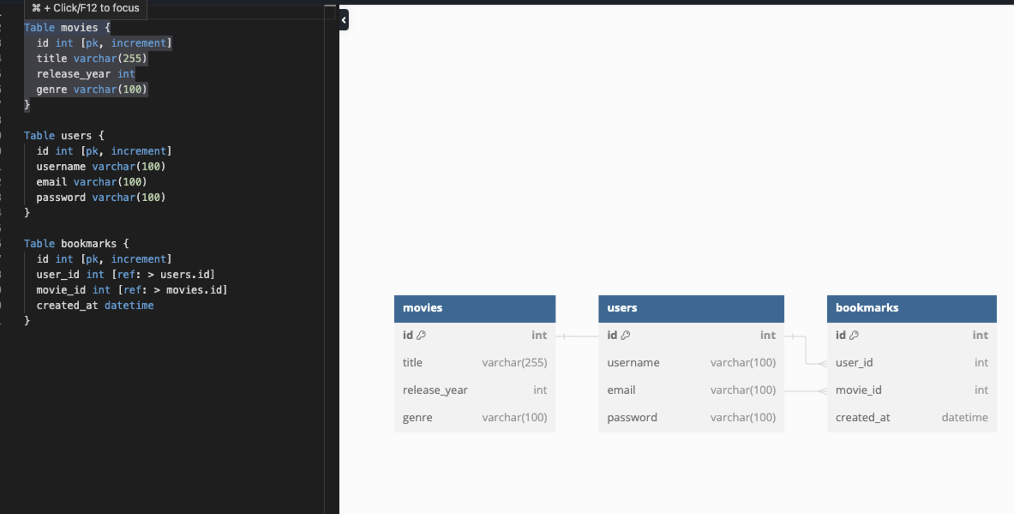
-
workbench
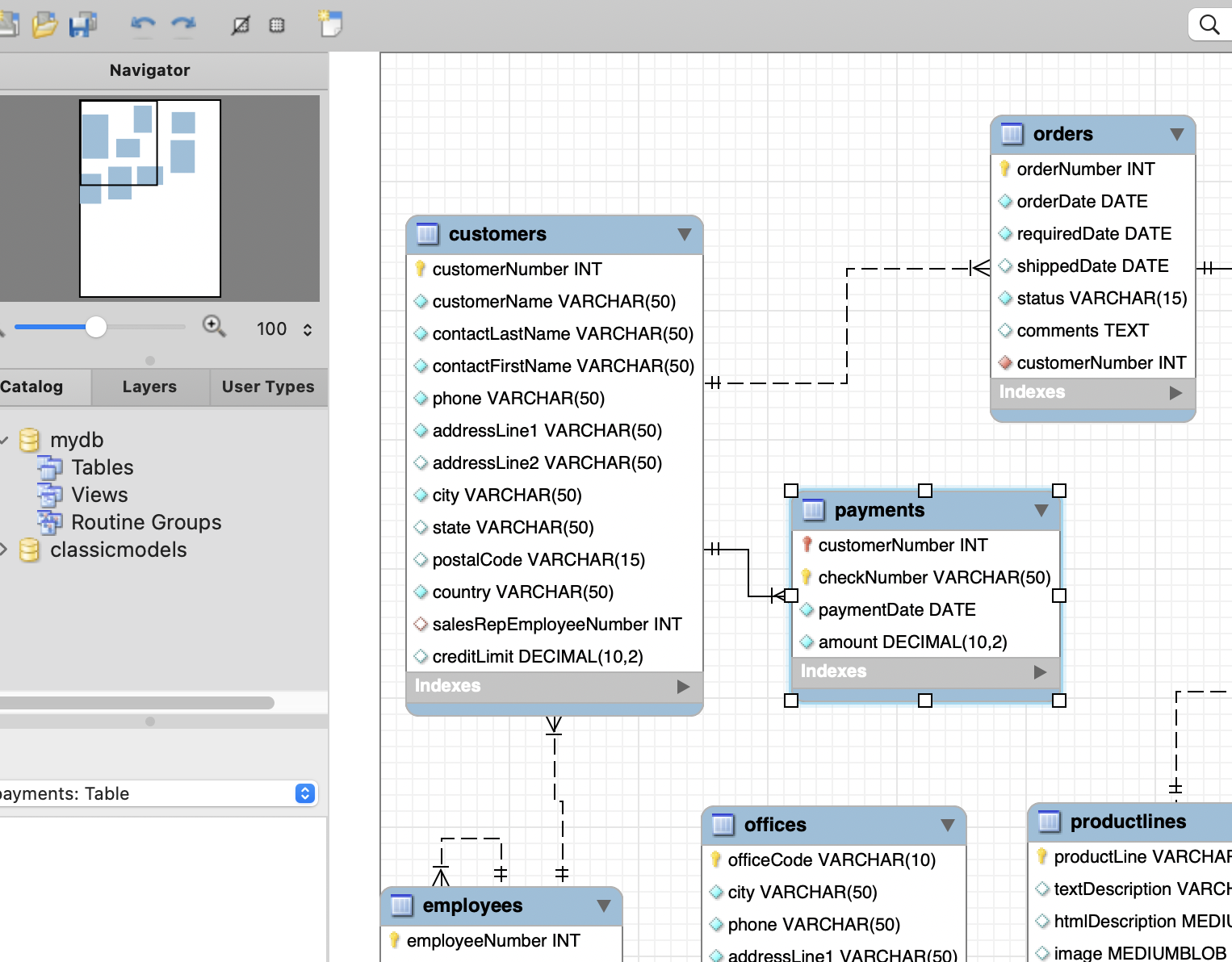
-
Aquery table 5개 까지만 무료
6.11 데이터베이스 첫 날 후기. 굉장히 낯선 느낌이다. 낯가리는 중 ㅎ;
평소에 잘 안쓰는 단어라서 무슨말인지 잘 모르겠고 ㅇㅅㅇ;; 내가 node.js할 때 얼마나 날림으로 했는지 알겠다. mongo db를 그래도 써봤는데도 하나도 못알아 듣겠다니! ( 물론 nosql과 mysql이 상당히 다르다는건 알겠다. ) 재밌었으면 좋겠다..
6.12 오늘도 잘 모르겠다.. 약간 재미 없는거 같기도 하고..
6.13 언젠간 가~~~겠지~~ 푸르른 이~~~청춘~~~~
