1. 서론
1.1 프로젝트 개요
ARMS의 AI모듈은 RAG를 활용하여 기업 내부의 문서 자료를 AI가 이해하고 활용할 수 있도록 설계되었습니다. 특히 PMBOK(Project Management Body of Knowledge)을 벡터 데이터베이스에 인덱싱하여 검색 가능한 지식 베이스로 구축하고 이를 기반으로 프로젝트 관리에 특화된 AI 어시스턴트 기능 제공을 목적으로 합니다.
1.2 핵심 기술 스택 소개
Spring AI
스프링 AI 프레임웍을 사용함으로서 얻는 이점은 크게 두가지로 볼 수 있는데 첫번째로는 기존 Java 애플리케이션과의 원활한 통합, 두번째로는 고성능 동시성 처리 지원으로 AI와 검색에 최적화된 Java의 기술적 장점 입니다.
WebFlux
Spring WebFlux는 AI의 긴 응답 시간을 효율적으로 처리할 수 있습니다.
주요 장점:
- 논블로킹 I/O: AI 응답 대기 중에도 다른 요청 처리 가능
- 스트리밍 응답: 토큰 단위 실시간 전송으로 즉각적인 사용자 피드백
- 리소스 효율성: 소수의 스레드로 다수의 동시 요청 처리
1.2.1 AI
Ollama
온프레미스 LLM 실행으로 데이터 보안과 비용 절감을 동시에 실현 가능합니다.
Ollama 서버 구조:
- 독립 서버: Ollama는 HTTP API 서버로 동작 (기본 포트 11434)
- SpringBoot 애플리케이션과 분리: AI 모듈은 클라이언트로서 Ollama 서버에 API 요청.
Opensearch
벡터 데이터베이스에 문서를 임베딩하여 저장하고 유사 검색을 수행합니다.
RAG에 대해 더 자세히 알고 싶으시면 아래의 글을 참고해 주세요.
[LLM] LLM 애플리케이션 개발하기: RAG
1.2.2 문서 처리 라이브러리
Apache Tika: 다양한 문서 형식 파싱
// MyPagePdfDocumentReader.java:31-37
TikaDocumentReader pdfReader = new TikaDocumentReader(
resourceLoader.getResource("classpath:/PMBOK_4th_Edition_한글판_UNLOCK.pdf")
);PDF Reader: 페이지/문단 단위 PDF 처리
// MyPagePdfDocumentReader.java:42-54
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(
"classpath:/preview-9781628255508_A36442031.pdf",
PdfDocumentReaderConfig.builder()
.withPagesPerDocument(1) // 페이지별 처리
.build()
);Token Text Splitter: LLM 토큰 제한을 고려한 텍스트 분할
// MyPagePdfDocumentReader.java:33-35
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
vectorStore.write(tokenTextSplitter.split(pdfReader.read()))2. WebFlux vs Spring MVC
Spring MVC는 스레드-블로킹 요청 처리 모델을 사용합니다. 요청마다 스레드를 점유하며, 전통적인 서블릿 방식과 친숙한 프로그래밍 모델을 제공합니다. 적당한 동시 요청 환경에서는 단순하고 안정적이지만, 연결 수가 폭증하거나 네트워크/DB I/O 대기가 많은 경우 스레드 자원이 빠르게 고갈될 수 있습니다.
Spring WebFlux는 논블로킹 이벤트 루프 모델을 기반으로 동작합니다. I/O 작업이 많은 환경에서 적은 스레드로도 많은 동시 요청을 처리할 수 있으며, 리액티브 스트림 API를 통해 데이터 스트림을 효율적으로 다룰 수 있습니다.
2.1 리액티브 프로그래밍
리액티브 프로그래밍은 데이터 스트림과 변화의 전파에 중점을 둔 프로그래밍 패러다임입니다. 비동기 데이터 스트림을 사용하여 논블로킹 방식으로 동작하며, 이벤트 기반의 프로그래밍 모델을 제공합니다.
핵심원칙 4가지
- 응답성(Responsive): 빠르고 일관된 응답 시간
- 회복력(Resilient): 장애 상황에서도 응답성 유지
- 탄력성(Elastic): 작업 부하에 따른 확장/축소
- 메시지 기반(Message Driven): 비동기 메시지 전달
2.2 Flux와 Mono
2.2.1 Flux: 0~N개의 데이터 스트림
Flux는 0개부터 N개까지의 요소를 방출할 수 있는 리액티브 스티림 입니다.
// SampleController.java:74
public Flux<String> generateStream(
@RequestParam(value = "message") String message,
@RequestParam("streamId") String streamId) {
// AI 응답을 Flux<String>으로 스트리밍
return chatClient.prompt()
.user(message)
.stream() // Flux<String> 생성
.content() // 각 토큰을 순차적으로 방출
// Flux 연산자들
.takeUntil(data -> streamStatus.get(streamId).get()) // 조건부 종료
.doOnComplete(() -> streamStatus.remove(streamId)) // 완료 처리
.doOnError(error -> streamStatus.remove(streamId)); // 에러 처리
}2.2.2 Mono: 0~1개의 데이터
이 프로젝트에는 없지만 Mono는 0개 또는 1개의 요소만 방출할 수 있는 리액티브 타입입니다.
정리하자면, Flux는 연속적 데이터에 Mono는 단일결과, 예를 들면 성공/실패, 존재/부재 등에 적용할 수 있습니다.
3. 스트리밍과 AI
3.1 스트리밍이란?
스트리밍은 데이터를 한 번에 모두 전송하는 것이 아니라, 작은 조각(청크) 단위로 나누오 연속적으로 전송하는 방식입니다. AI 서비스에서는 긴 응답 시간 문제를 해결하고 사용자 경험을 개선할 수 있습니다.
3.2 SSE(Server-Sent-Events)
3.2.1 SSE란?
SSE는 서버에서 클라이언트로 단방향 실시간 데이터 스트리밍을 가능하게 하는 HTML5 표준 기술입니다. WebSocket과 달리 HTTP 프로토콜(데이터 전송 규약)을 그대로 사용하며, 서버에서 클라이언트 방향으로만 데이터를 전송합니다.
SSE의 특징:
- 단방향 통신: 서버 -> 클라이언트 (AI응답에 적합)
- 자동 재연결: 연결이 끊어지면 자동으로 재연결
- 간단한 프로토콜: HTTP 기반, 방화벽 친화적
- 텍스트 기반: UTF-8 텍스트 전송
SSE 형식
HTTP/1.1 200 OK
Content-Type: text/event-stream
Cache-Control: no-cache
Connection: keep-alive
data: 첫 번째 메시지\n\n
data: 두 번째 메시지\n\n
event: close\n
data: 연결 종료\n\n3.2.2 SSE 구현 부분
서버 측 SampleController.java:73-122:
@GetMapping(value = "/ai/generateStream") // produces 속성 없음
public Flux<String> generateStream(
@RequestParam(value = "message", defaultValue = "오늘 날씨 어때?") String message,
@RequestParam("streamId") String streamId) { // streamId 파라미터 있음
streamStatus.put(streamId, new AtomicBoolean(false));
ChatClient chatClient = ChatClient.builder(chatModel).build();
// 프롬프트 템플릿 설정 PromptTemplate("""
Context information is below.
---------------------
{context}
---------------------
Given the context information and no prior knowledge, answer the query.
Follow these rules:
주어진 요청에 대한 제공된 내용은 정보를 바탕으로, 사전 지식 없이 사용자 댓글에 답변하세요.
그림이나 표가 들어가는 단어는 제외하고 찾아줘.
문장이 끝나면 개행해줘.
만약 요청에 답이 없다면, 영어로 대답하지 말고 한국어로 사용자에게 답변을 할 수 없다고 알려주세요.
Query: {query}
Answer:
""");
// RAG Advisor 설정 (103-113줄)
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.5)
.vectorStore(vectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.promptTemplate(promptTemplate)
.build())
.build();
return chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(message)
.stream()
.content()
.takeUntil(data -> streamStatus.get(streamId).get())
.doOnComplete(() -> streamStatus.remove(streamId))
.doOnError(error -> streamStatus.remove(streamId));
}4. RAG
4.1 ARMS의 RAG 구현 방식
4.1.1 문서 인덱싱 파이프라인
ARMS의 문서 인덱싱은 다양한 형식의 문서를 벡터 데이터베이스에 저장 가능한 형태로 변환하는 과정 입니다.
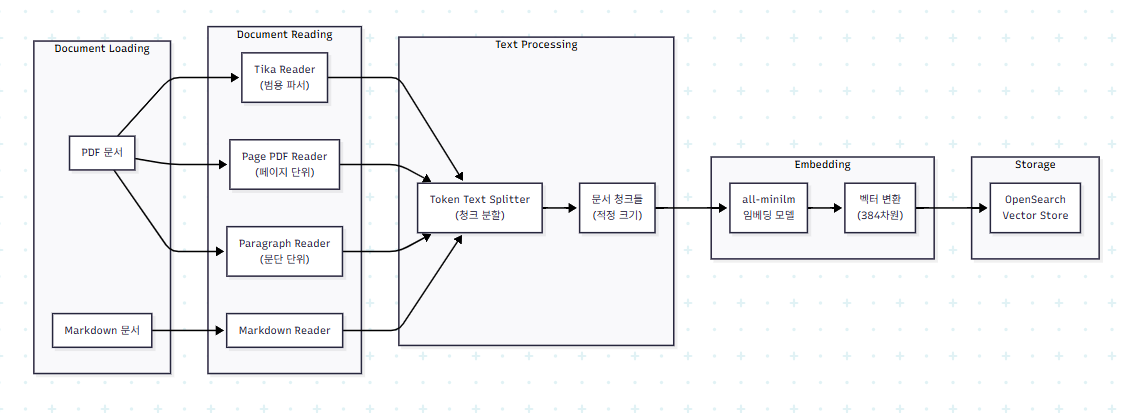
4.1.2 벡터 저장소(Opensearch)
OpenSearch는 ES 기반의 오픈소스 검색 엔진으로 벡터 검색 기능을 제공합니다.
설정 구성:
//application-dev.yml:18-24
spring:
ai:
vectorstore:
opensearch:
uris: http://www.313.co.kr:9292
initialize-schema: true
index-name: spring-ai-document-index
similarity-function: cosinesimil // 코사인 유사도 사용4.2 RAG 처리 흐름
4.2.1 문서 전처리 단계
문서를 AI가 이해할 수 있는 형태로 변환하는 과정입니다.
// MyPagePdfDocumentReader.java:42-49
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/preview-9781628255508_A36442031.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());전처리 최적화:
- 불필요한 메타데이터 제거
- 적절한 청크 크기 설정 (토큰 제한 고려)
- 문서 구조 정보 보존
4.2.2 쿼리 처리 단계
사용자 질문을 받아 관련 문서를 검색하고 컨텍스트를 구성합니다.
// SampleController.java:103-113
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(
VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.5) // 유사도 임계값
.vectorStore(vectorStore)
.build()
)
.queryAugmenter(
ContextualQueryAugmenter.builder()
.allowEmptyContext(false) // 빈 컨텍스트 방지
.promptTemplate(promptTemplate)
.build()
)
.build();쿼리 처리 과정:
- 벡터 변환: 사용자 질문을 임베딩 벡터로 변환
- 유사도 검색: 0.5 이상의 유사도를 가진 문서 검색
- 컨텍스트 구성: 검색된 문서를 프롬프트에 포함
4.2.3 응답 생성 단계
검색된 컨텍스트를 기반으로 LLM이 답변을 생성합니다.
// 프롬프트 템플릿 (SampleController.java:81-100)
PromptTemplate promptTemplate = new PromptTemplate("""
Context information is below.
---------------------
{context}
---------------------
Given the context information and no prior knowledge, answer the query.
Follow these rules:
- 제공된 내용만을 바탕으로 답변
- 그림이나 표 관련 내용 제외
- 문장 끝 개행 처리
- 답변 불가시 한국어로 안내
Query: {query}
Answer
""");스트리밍 응답 구현:
// SampleController.java:115-122
return chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(message)
.stream() // 스트리밍
.content()
.takeUntil(data -> streamStatus.get(streamId).get()) // 중단 가능
.doOnComplete(() -> streamStatus.remove(streamId))
.doOnError(error -> streamStatus.remove(streamId));RAG 응답 생성 특징:
- 실시간 스트리밍: Flux를 통한 토큰 단위 전송
- 중단 가능: 스트림 ID로 응답 중단 제어
전체 RAG 플로우:
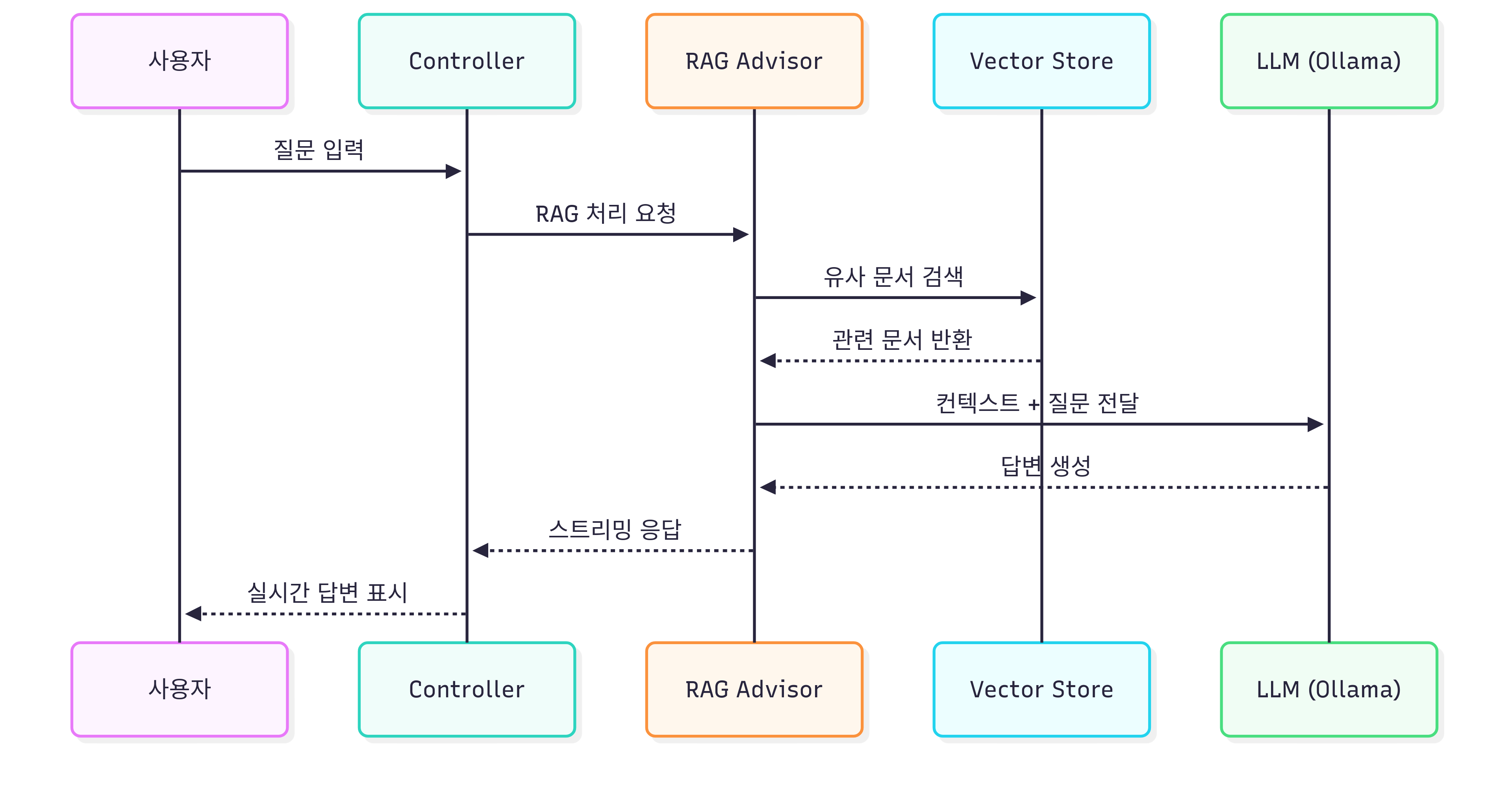
6. 핵심 코드 분석
6.2 SampleController.java
6.2.1 generateStream 메서드
SampleController의 핵심은 generateStream 메서드입니다. 이 메서드는 사용자의 질문을 받아 AI가 실시간으로 답변을 스트리밍하는 기능을 담당합니다. 특히 주목할 점은 각 스트림마다 고유한 ID를 부여하여 관리한다는 것입니다. 이를 통해 여러 사용자가 동시에 서비스를 사용하더라도 각자의 스트림을 독립적으로 제어할 수 있습니다.
메서드가 실행되면 먼저 스트림 상태를 관리하기 위한 초기화가 이루어집니다. ConcurrentHashMap을 사용하여 멀티스레드 환경에서도 안전하게 각 스트림의 상태를 추적합니다. 이후 ChatClient를 생성하고 프롬프트 템플릿을 정의합니다.
RAG Advisor 구성 부분에서 벡터 데이터베이스와의 연동이 이루어집니다. 유사도 임계값을 0.5로 설정하였습니다.
마지막으로 리액티브 스트림 체인을 구성합니다. takeUntil 연산자를 통해 언제든 스트림을 중단할 수 있도록 하고, doOnComplete와 doOnError로 스트림 종료 시 리소스를 정리합니다. 이러한 구조는 사용자 경험을 크게 향상시키는데 AI의 답변을 기다리는 동안에도 실시간으로 부분적인 응답을 볼 수 있기 때문입니다.
6.2.2 stopStream 메서드
스트림 중단 기능을 발견하였는데 이는 AI의 답변이 길어지거나 원하는 답변이 아닐 때 즉시 중단할 수 있기 위한 것으로 보여집니다.
이 메서드의 동작 원리는 스트림 ID를 받아서 해당 스트림의 상태를 변경하는 것이 전부이지만
내부적으로는 동시성 제어가 이루어집니다. AtomicBoolean을 사용하여 원자적 연산을 하고, 이 값의 변경이 즉시 generateStream의 takeUntil 연산자에 전파되어 스트림이 중단됩니다.
흥미로운 점은 스트림이 존재하지 않는 경우에 대한 처리도 포함되어 있다는 것입니다. 이미 완료된 스트림이나 잘못된 ID에 대해서는 적절한 메시지를 반환하여 클라이언트가 현재 상태를 파악할 수 있도록 합니다.
6.2.3 문서 읽기 메서드들
ARMS 프로젝트는 다양한 문서 읽기 방식을 실험하고 비교할 수 있도록 여러 엔드포인트를 제공합니다. 각 메서드는 서로 다른 Document Reader를 사용하여 같은 문서를 다르게 처리합니다.
첫 번째 /ai/test 엔드포인트는 가장 기본적인 기능으로, 입력받은 메시지와 유사한 문서를 벡터 저장소에서 직접 검색합니다.
나머지 네 개의 엔드포인트는 각각 다른 문서 읽기 전략을 보여줍니다. TikaReader를 사용하는 첫 번째 메서드는 PMBOK 같은 대용량 PDF를 처리하는 데 적합하고, PagePdfReader는 각 페이지의 레이아웃을 보존해야 할 때 유용합니다. ParagraphPdfReader는 더 세밀한 단위로 문서를 분할하여 정확한 컨텍스트 매칭이 필요한 경우에 활용되며, MarkdownReader는 기술 문서나 README 파일 처리에 최적화되어 있습니다.
6.3 MyPagePdfDocumentReader.java
MyPagePdfDocumentReader 클래스는 문서 처리의 핵심 로직을 담고 있습니다. Spring의 @Component 어노테이션으로 빈으로 등록되어 있으며, @AllArgsConstructor를 통해 의존성 주입을 간결하게 처리합니다. ResourceLoader와 VectorStore를 주입받아 파일 읽기와 벡터 저장을 수행합니다.
각 메서드는 동일한 패턴을 따라 적절한 Document Reader를 생성하고, 문서를 읽은 후 TokenTextSplitter로 분할하며 마지막으로 벡터 저장소에 저장합니다.
특히 TokenTextSplitter는 LLM의 토큰 제한을 고려하여 문서를 적절한 크기로 분할합니다.
각 Reader의 설정도 살펴보면, PagePdfReader에서는 withPageTopMargin(0)으로 불필요한 여백을 제거하고, withPagesPerDocument(1)로 각 페이지를 독립적인 문서로 처리합니다. MarkdownReader에서는 withIncludeCodeBlock(false)로 코드 블록을 제외하여 일반 텍스트에 집중하도록 설정했습니다.
6.4 설정 파일 정리
개발 환경에서는 외부에서 접근 가능한 Ollama 서버를 사용합니다. Temperature는 0.1로 매우 낮게 설정하여, 창의적인 답변보다는 일관성과 정확성을 우선시하도록 했습니다. PMBOK 같은 전문 문서를 기반으로 답변할 때는 창의성보다 정확성이 더 중요하기 때문입니다.
운영 환경에서는 내부 네트워크를 통해 접근하도록 설정되어 있습니다.
Ollama: http://:11434
OpenSearch: http://:9200
Java 설정 파일:
Config.java → RestClient 빈을 정의하여 HTTP 통신을 담당
OpenApiConfig.java → Swagger UI를 통한 API 문서화를 구성
