
1. Image classifier
이미지 분류기로 두 가지 기술을 소개하고 있다.
1) Nearest Neigbor
2) Linear Classification
두 기술에 대해서 가볍게 짚을 예정이다.
1) K-Nearest Neighbors
image의 Feature을 추출하여 만든 여러 data point들이 있다고 하자.
Distance Metirc을 이용해서 가까운 이웃을 K개 만큼 찾고, 이웃끼리 투표를 하는 방법이다.
그리고 가장 많은 득표수를 획득한 레이블로 예측한다.
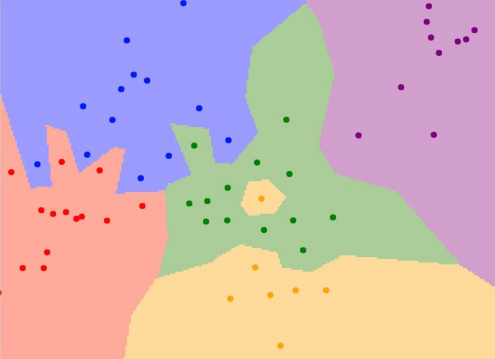
그럼 이제 우리는 두 가지 측면을 따져야 한다.
1) 그럼 두 벡터간의 거리는 어떻게 구할 것인지? => distance metric
2) 거리가 가까운 data point의 개수를 어떻게 설정할 것인지? => number of K
이는 알고리즘이 자동으로 선택이 불가하고, 사람이 직접 설정을 해줘야하는 문제이다. 이러한 파라미터들을 hyperparameter라고 한다.
(1) distance metric
벡터간의 거리를 구하는 방법은 L1 norm distance와 L2 norm distance로 나눠져 있다.
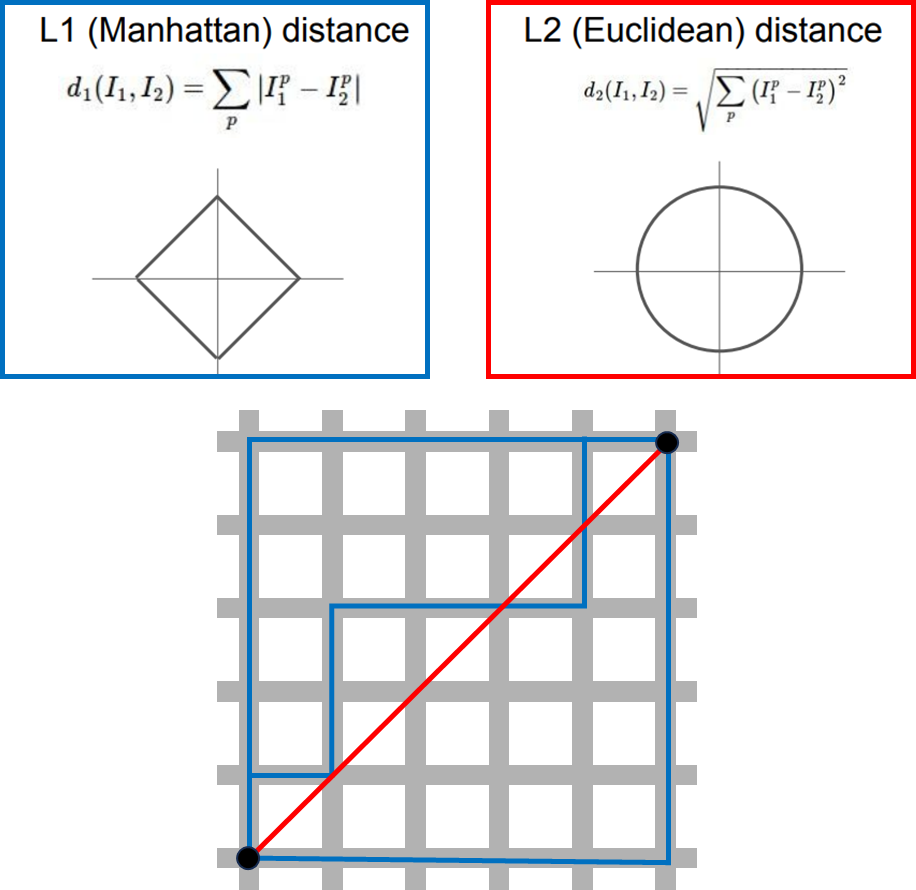
L1 norm은 두 벡터의 원소 차이를 절댓값으로 나타내어 합한 형태,
L2 norm은 원소 차이를 절댓값의 제곱항 형태로 합한 형태이다.
벡터가 개별적인 의미를 가지고 있다면(ex. 키, 몸무게) L1 Distance를, 일반적인 벡터 요소들의 의미를 모르거나 의미가 별로 없을 때는 L2 Distance를 사용한다.
(2) number of K
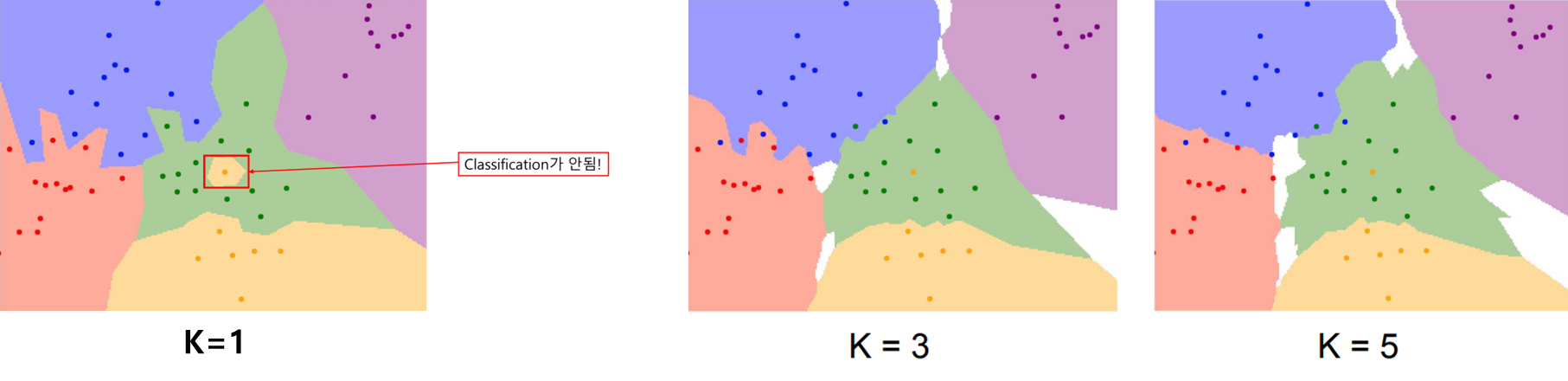
K=1의 경우에는, 초록색 점들사이에서 중간에 노란 점이 끼어있다. 또한 초록색 영역이 파란색 영역을 침범하고 있다. 이는 잡음 noise 이거나 가짜 spurious이다.
K=3의 경우에는, 초록색 영역 한가운데에 존재하던 노란색 영역이 사라졌다. 그리고 중앙은 초록색이 점령하였다. 그리고 파란색과 빨간색 사이의 뾰족한 영역도 부드러워졌다.
K=5의 경우에는 파란색과 빨간색 영역이 아주 부드러워졌다.
대체로 NN 분류기를 사용하면, K는 적어도 1 보다는 큰 값으로 사용해야 한다.
2) Linear Classification
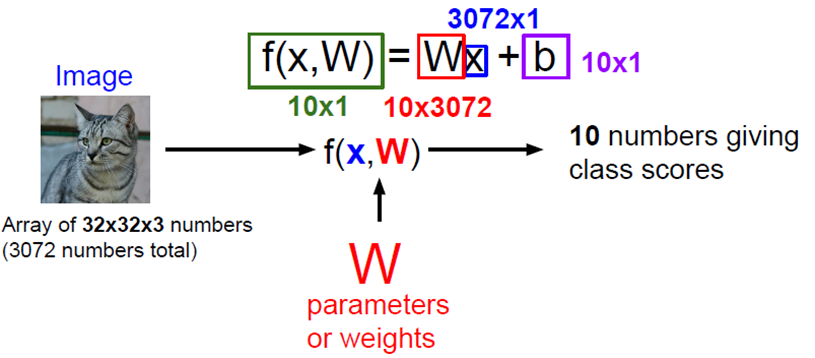
Linear classification은 이미지 분류 정보를 가중치 에 저장을 하는 Parametric Approach이다.
으로 계산이 된다.
는 bias으로 특정 카테고리에 우선권을 주도록 한다.
Ex) 고양이 데이터 > 개 데이터에서는 고양이 클래스에 상응하는 bias가 더 커지게 된다
Linear Classification은 K-NN에 비해 test 모델에서 계산 복잡도가 현저히 낮다는 장점을 가지고 있다.
- K-NN은 train model없이 test model에서 입력 데이터 포인트와 나머지 데이터 포인트 간의 거리를 계산해야 하므로 실시간 적용이 어렵다.
- 반면 Linear Classification은 train model에서 학습한 가중치 를 활용하여 test model에서는 입력 데이터에 대한 계산만 수행하면 되므로 계산 복잡도가 현저히 낮아진다.
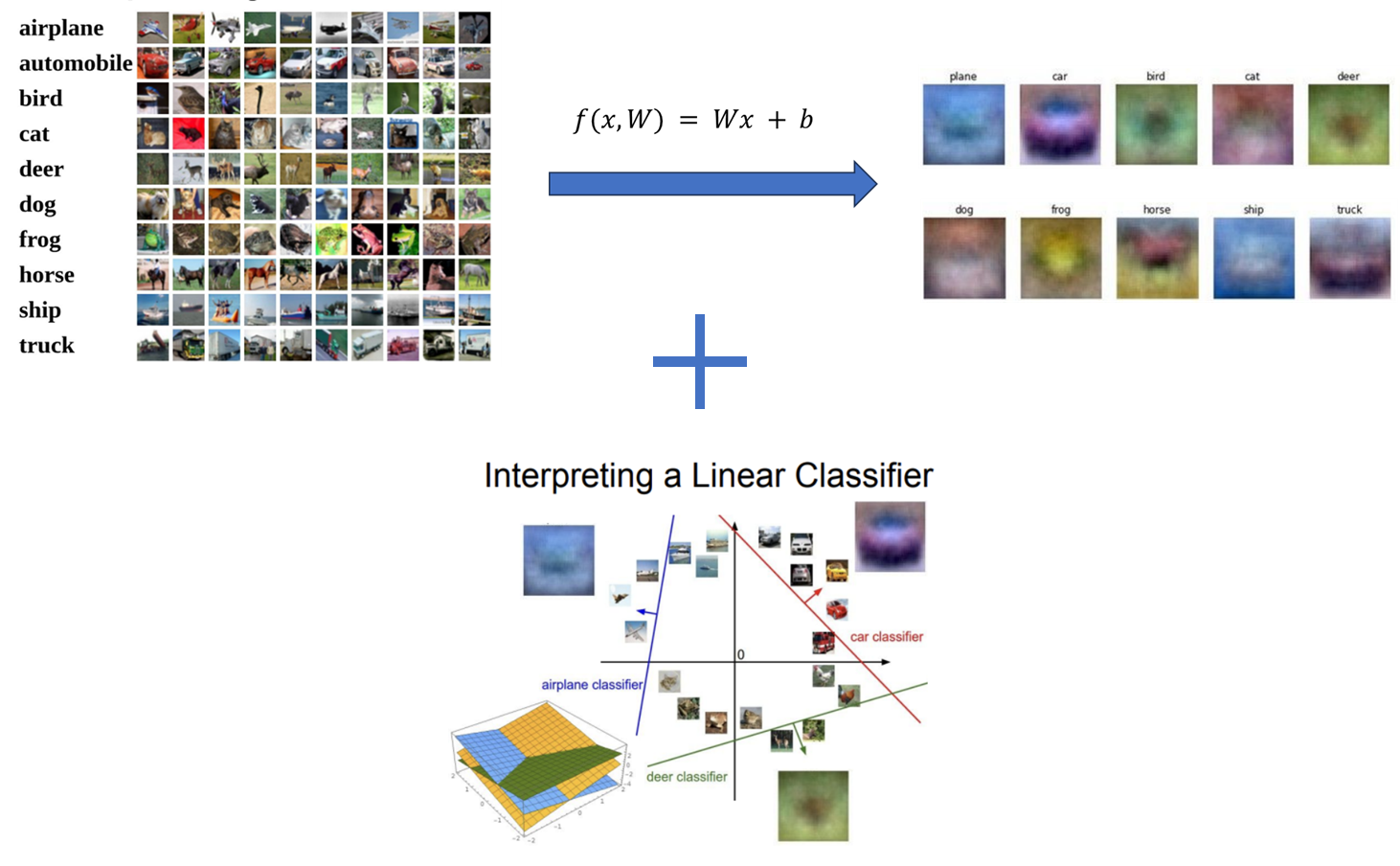
학습한 가중치 를 이용해 input data를 행렬곱하게 된다면 각 카테고리에 해당하는 score가 계산이 될 것이다. 우리는 이 중에서 가장 높은 score에 해당한 카테고리를 선택하면 된다.
이를 선형 분류기로 해석하는 관점도 가지고 있다.
다만 Linear Classifier는 각 클래스에 따라 하나의 템플릿만 학습한다는 한계점이 존재한다.

오른쪽을 보고 있는 말, 왼쪽을 보고 있는 말의 이미지를 학습한다면, 머리가 두개 달린 말의 이미지가 가중치 에 쌓일 수도 있다.
데이터 분포가 하나의 형태로 모여지는 것이 아닌 다양한 형태로 존재하는 경우에 Linear Classification이 제대로 구별이 힘들다.
3) Setting Hyperparameters
K-NN에서만 hyperparameter를 다뤘지만, 추후에 나올 모델들 모두가 이러한 과정을 걸쳐야하므로 일부로 뒤로 뺐다.

- train data : 모델을 학습하기 위함
- validation data : 학습한 모델이 충분한 성능을 내는 지 검증하기 위한 데이터
- test data : 실제 적용할 데이터
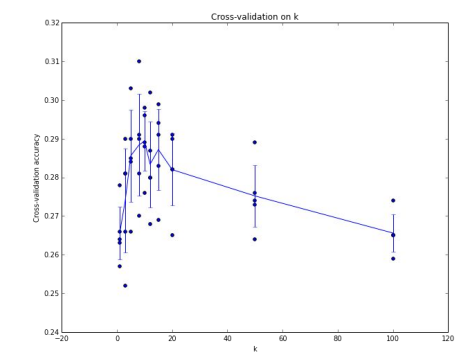
이러한 방식을 통해 최적의 hyperparameter를 결정할 수 있다
2. Conclusion
Linear Classification을 학습하기 위해서는 Loss function에 대해서 알아야 한다. 하지만 2강은 두 classifier를 소개하는 것으로 마무리했기 때문에 다음 강의 정리에서 소개하도록 하겠다.
