1. Loss function
Loss function은 무엇인가?
바로 분류한 결과와 실제 값의 차이를 정량적으로 확인하는 function이다.
이를 통해 우리는 현재 분류 결과가 얼마나 좋은지 혹은 나쁜지를 판단할 수 있는 근거를 가지게 된다.
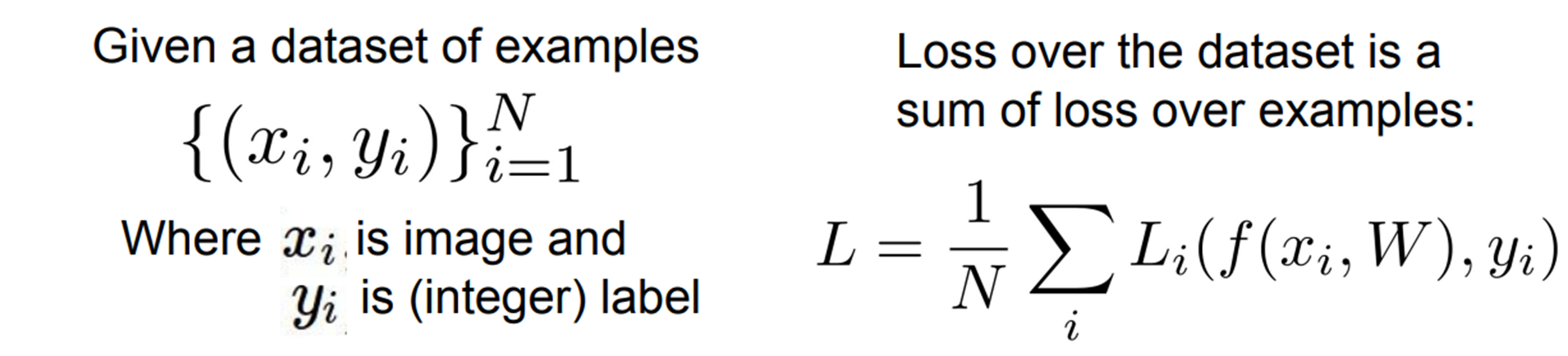
가 우리가 선택할 Loss function이 되고, 은 각 요소에 대한 Loss function의 평균값이 된다.
좋은 성능의 분류기를 설계하기 위해서 이 되도록 최적화작업을 해줘야한다.
"최적화"라는 의미를 곧 이따가 설명하도록 하겠다. 우선 Loss function부터!
cs231n에서 소개한 Loss function은 두 가지가 있다.
1) SVM Loss
2) Softmax
그리고 L2 norm Loss, L1 norm Loss 등이 있다.
모든 Loss function의 역할은 각각 다르고 이에 따라서 선택을 해줘야 한다.
이번 챕터에서는 '분류'라는 테마에 맞춰서 설명한 것 같다.
1) Multiclass SVM loss

Multiclass SVM loss는 각 class에 대한 score를 매겼을 때, score가 참에 해당된 class의 score와 얼마나 차이나는 지 함수이다.
자기 자신을 제외한 나머지 score vector와 ground truth에 해당하는 score vector 간의 차이와 margin term(+1)을 더한 값이 0보다 크면 손실이 발생한다
분류기를 통과해 나온 class에 따른 score는 다음과 같다.

첫번째 데이터인 고양이의 SVM Loss를 계산해보자
고양이의 score vector는 이다.
나머지 score vector는 각각 이다.
그럼 가 된다.
그 다음 데이터인 자동차의 SVM Loss를 계산해보자
자동차의 score vector는 이다.
나머지 score vector는 각각 이다.
그럼 가 된다.
매우 훌륭하게 분류되었음을 알 수 있다.
다음은 SVM Loss의 code를 함수로 나타낸 것이다
def L_i_vectorized(x,y,W): scores = W.dot(x) margins = np.maximum(0, scores-scores[y]+1) margin[y] = 0 loss_i = np.sum(margins) return loss_i
2) Softmax Loss
What is Softmax?
- 출력 vector들을 [0,1]사이로 배치해주고, 확률 분포로 나타내준다.
- softmax Function을 통과해 나온 class별 확률값들의 총합은 항상 '1'이다.
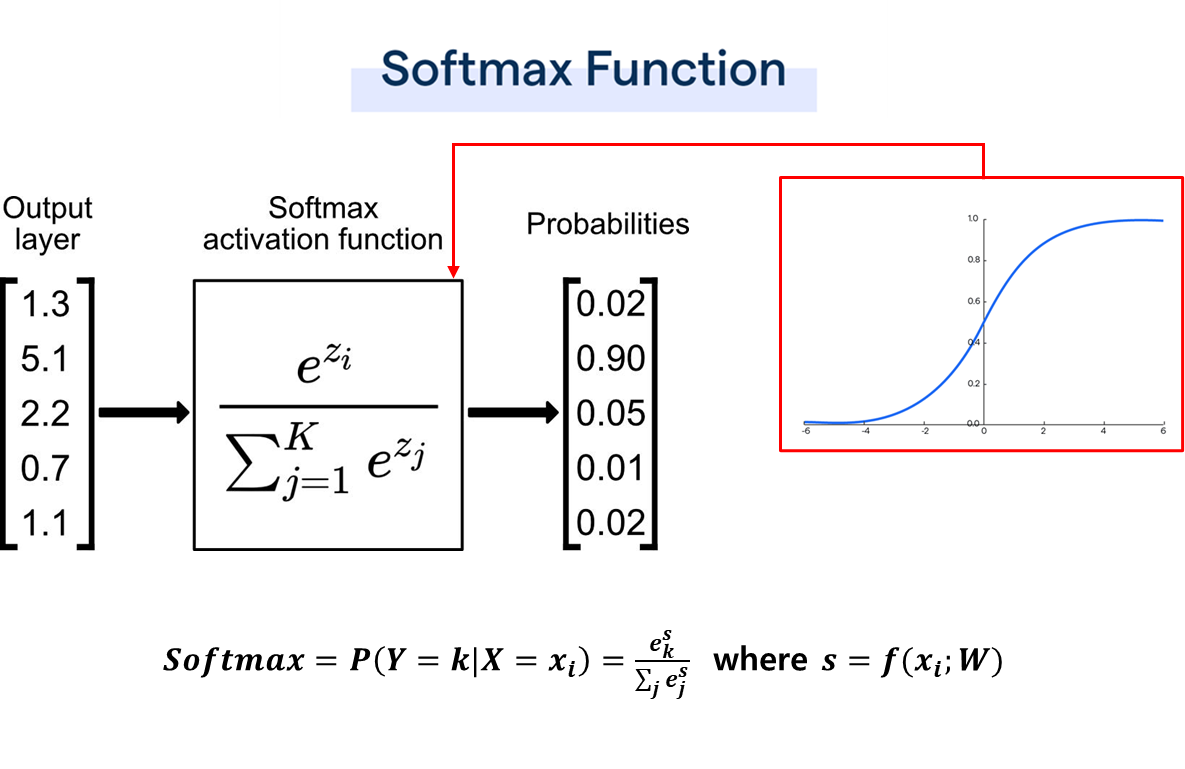
softmax Loss는 softmax를 negative log likelihood로 표현하도록 한다.
(loss 값은 양의 범위에서 일어나야하므로 negative이다.)

3) SVM Loss vs Softmax Loss
그럼 분류를 위해서 쓰인 두 Loss function은 어떤 특성을 보이는 가? 이를 표로 정리해보았다.

- score가 변화에 따라 Loss에 변화됨은 Loss function마다 다르다
- Multiclass SVM Loss는 class score의 차이만 고려하기 때문에 Loss가 0이면 더 이상 학습하지 않는다.
- softmax Loss는 score를 확률 기반으로 다루기 때문에 score의 변화를 적극적으로 반영한다. 따라서 복잡한 task를 처리하려고 할 때는 대부분 softmax loss를 사용한다.
- train model에서 이 되는 가중치 는 유일하지 않다
- train data에서 추정한 은 혹은 모두 좋은 성능을 낼 수 있다.
- 그러나 그 말이 test data에서도 올바른 성능을 낼 거라는 가능성은 매우 낮다.
그렇다면 수 많은 중에서 '우리가 선택해야하는 은?'
Regularization을 이용해 train을 통해 추정한 가 test data에도 유효한 성능을 내는지 확인한다.
2. Regularization
쉽게 말하자면, 모델의 복잡도가 증가하는 걸을 막기 위해 학습 과정에서 별도의 규제를 추가하는 기술이다.
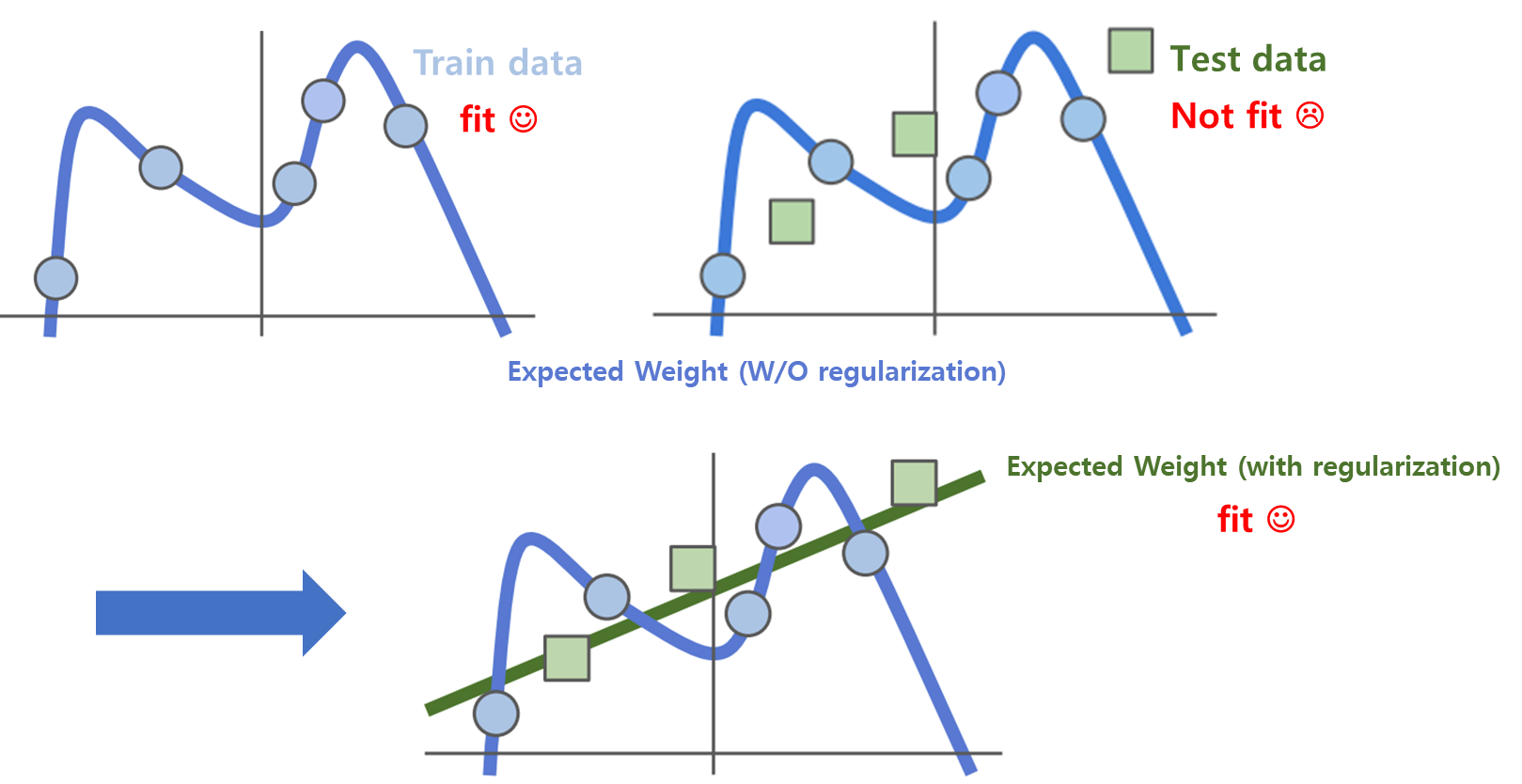
train data의 정확도가 얼마나 좋은 지는 중요하지 않다. test data의 예측이 얼마나 정확한지가 중요하다.
다시 말해, train data 뿐만 아니라 test data도 일반적으로 표현할 수 있는 모델을 우리는 원한다.
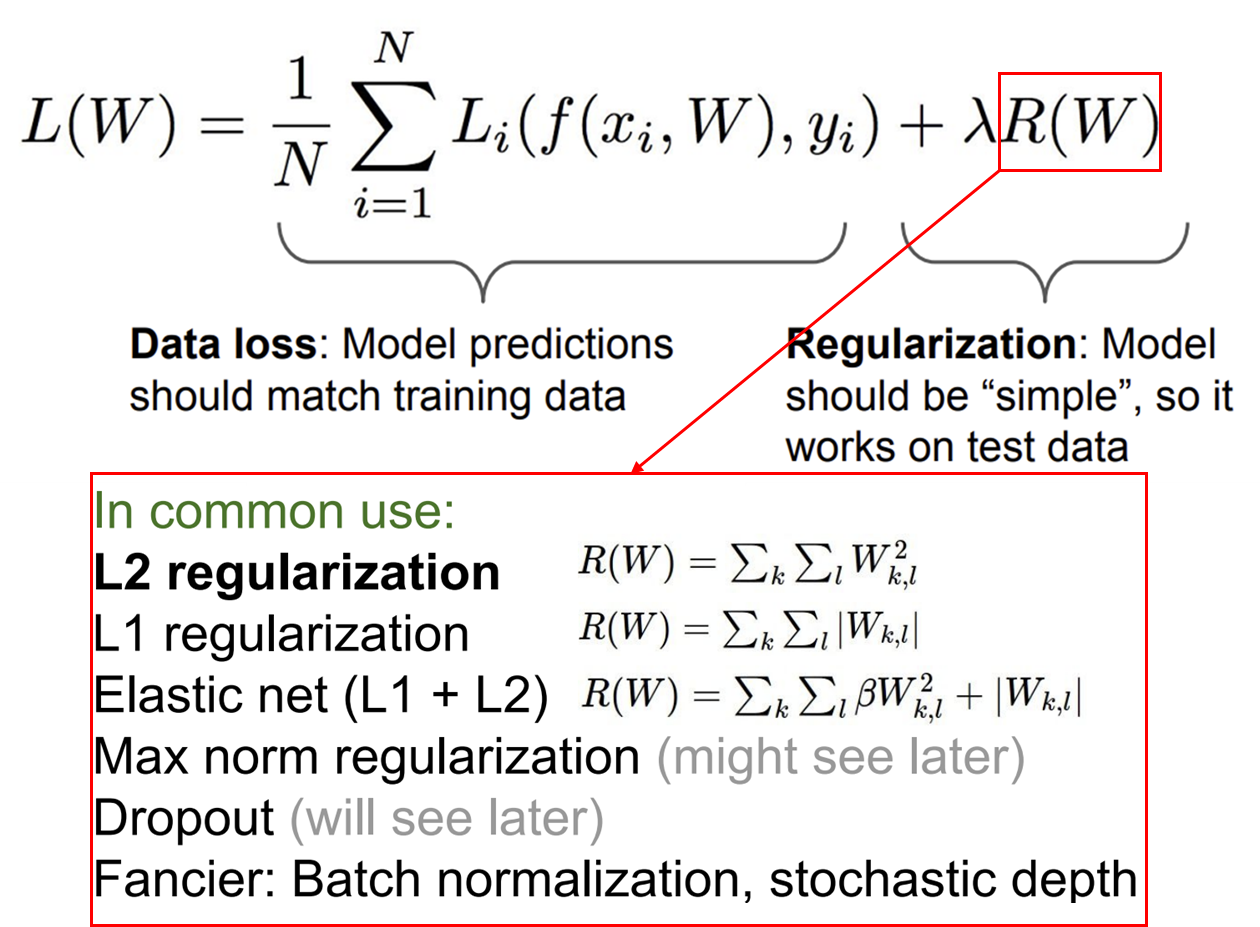
다음과 같이 표현되며, 는 hyperparameter이다.
혹시, 이게 어떠한 과정을 통해 규제가 이뤄지는지 궁금할 수 있겠는데, 꽤나 고급진 수학 전개가 필요하다.
이는 나중에 다뤄보겠다.
다음과 같은 input data와 가중치가 있다고 하자

두 가중치 모두 input data와의 행렬곱은 1로 동일하다.
- L1 Regularization 에 최적화
- L1 Regularization는 가중치의 요소가 희소 (sparse)할 때 최적화되어 있다.
- L2 Regularization 에 최적화
- L2 Regularization는 모든 가중치 요소에 골고루 영향을 미치게 된다.
모델과 데이터 특성에 따라서 올바른 Regularization 전략을 선택해야한다.
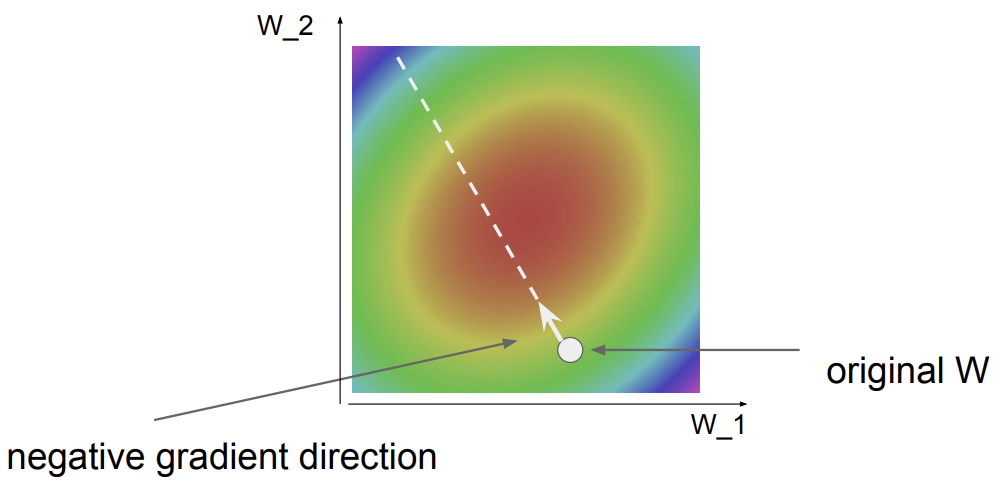
3. Optimization
Optimization은 최적의 classifier를 만족하는 가중치 를 찾기 위한 기법이다.
Loss function은 그 자체로 classifier의 성능을 높이진 않는다.
하지만 최적화 기법을 이용하여 이 되는 가중치 를 탐색할 수 있다.
가장 일반적인 전략은 gradient descent이다.
함수 그래프의 미분식을 통해 특정 값에서의 함수의 기울기를 계산할 수 있었다는 것을 알고 있다.
여기서 문제를 드리도록 하겠다.
- 기울기가 0이 되는 값으로 이동할려면 어떻게 해야하는가?
(hint : 기울기를 경사로 생각해보자. 경사가 없는 평지로 이동할려면?)
- 기울기(경사)가 낮은 방향으로 이동하면 된다.
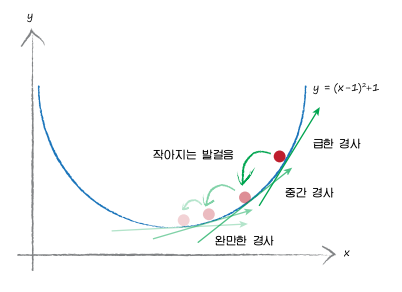
우리는 1차원 스칼라 함수가 아닌 N-차원 벡터 함수에 대한 gradient를 구할려고 한다면, 다변수 미분을 진행하면 된다.
미분 계산하는 것에는 두 가지 방법이 있다.
1.수치적 미분 방법(numerical gradient) : 근사적인 풀이일 뿐더러 계산이 느리단 단점이 있어 거의 안쓴다.

2.해석적 미분 방법(analytic gradient) : 정확하고 빠르지만 오류가 날 가능성이 존재한다.
함수 을 변수 에 대해서 미분한 식은 이 된다.
미분식에 변수를 대입하면 해당 함수의 기울기가 나온다.

일반적으로 해석적 방법을 사용하지만, 미분이 가능한지를 수치적으로 볼 경우에는 수치적 방법을 사용한다.