Convolutional Neural Networks
Fully Connected Layer
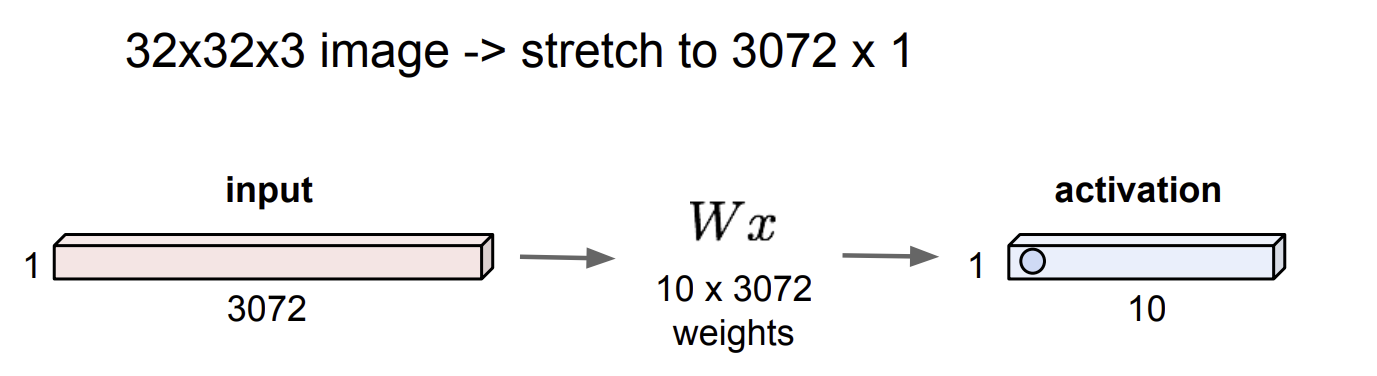
다층으로 구성된 퍼셉트론을 주로 Fully connected layer라고 부른다.
- 3차원 이미지를 1차원 벡터로 늘려뜨려 내적 연산을 통해 10 class로 이뤄진 activation layer에 출력한다.
Convolution Layer
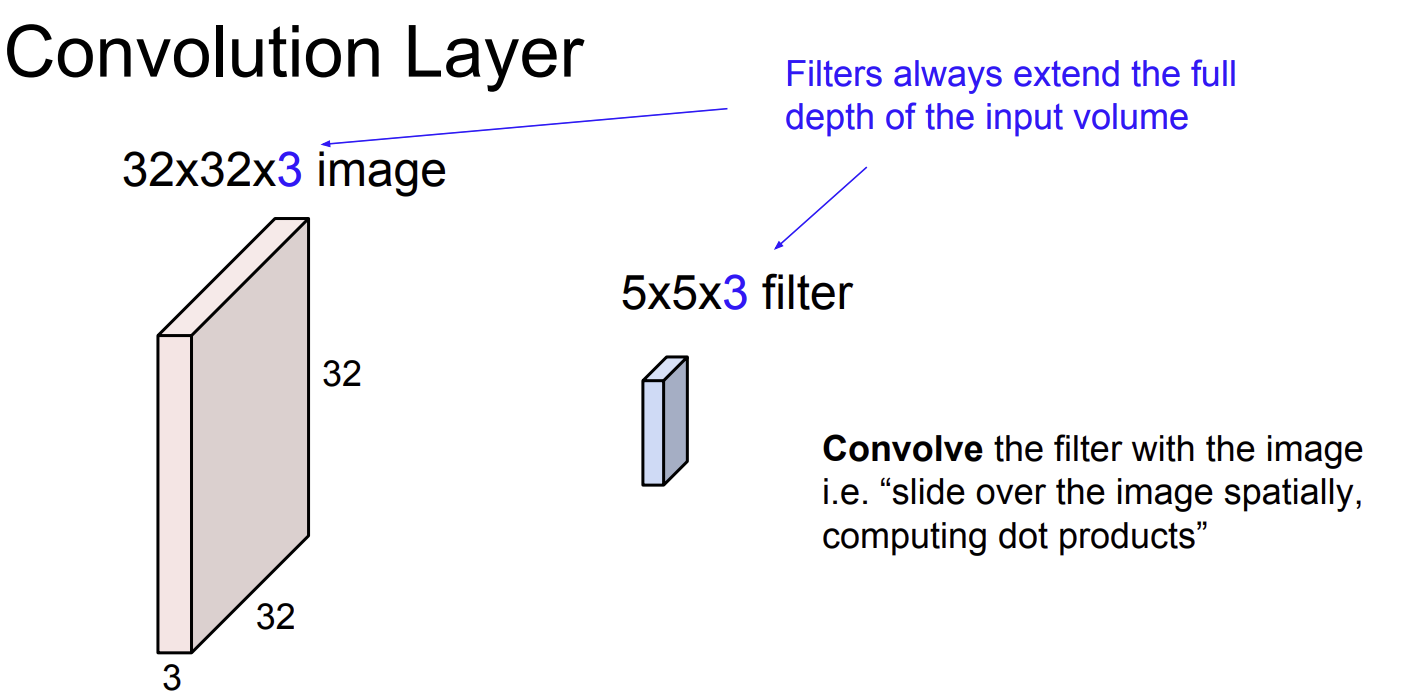
Convoluation layer는 기존의 이미지 차원을 보존하면서 filter와의 공간적 내적 (spatial convolution)을 통해 계산한다.
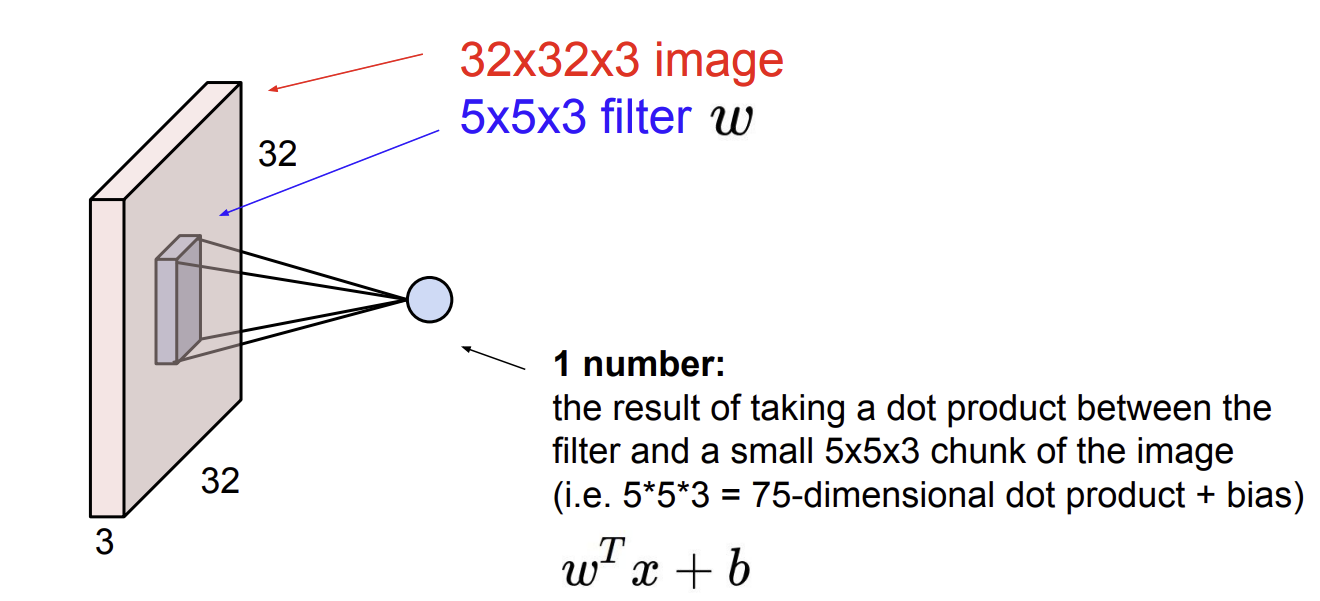
입력 이미지와 filter를 convolve하면 1개의 숫자가 나온다.
- 즉, filter와 입력 차원의 일부 (filter의 크기)를 내적하여 1개의 숫자가 나오게 된다.
- 1개의 숫자가 나오는 식은 이다. 여기서 는 553=75이고, b는 bias이다.
만약 filter가 10번 슬라이딩(convolve)하면 10개의 숫자가 나온다.
여기서 계산 형태가 유사함을 빌미로 Convolution이라고 지칭한거지, 실제 Convolution의 정의와는 약간의 차이가 있다.
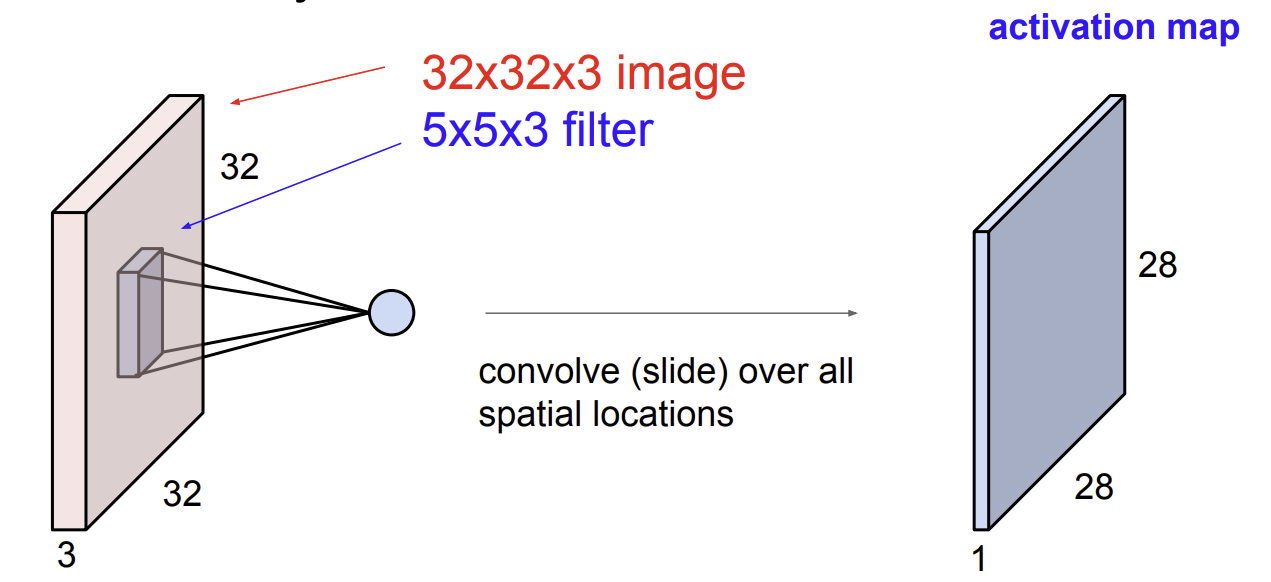
슬라이딩을 통해서 크기의 activation map이 만들어진다.
하지만 공간적인 특징을 더 다채롭게 추출하기 위해서는 가중치가 서로 다른 필터를 추가로 슬라이딩 해줘야한다.
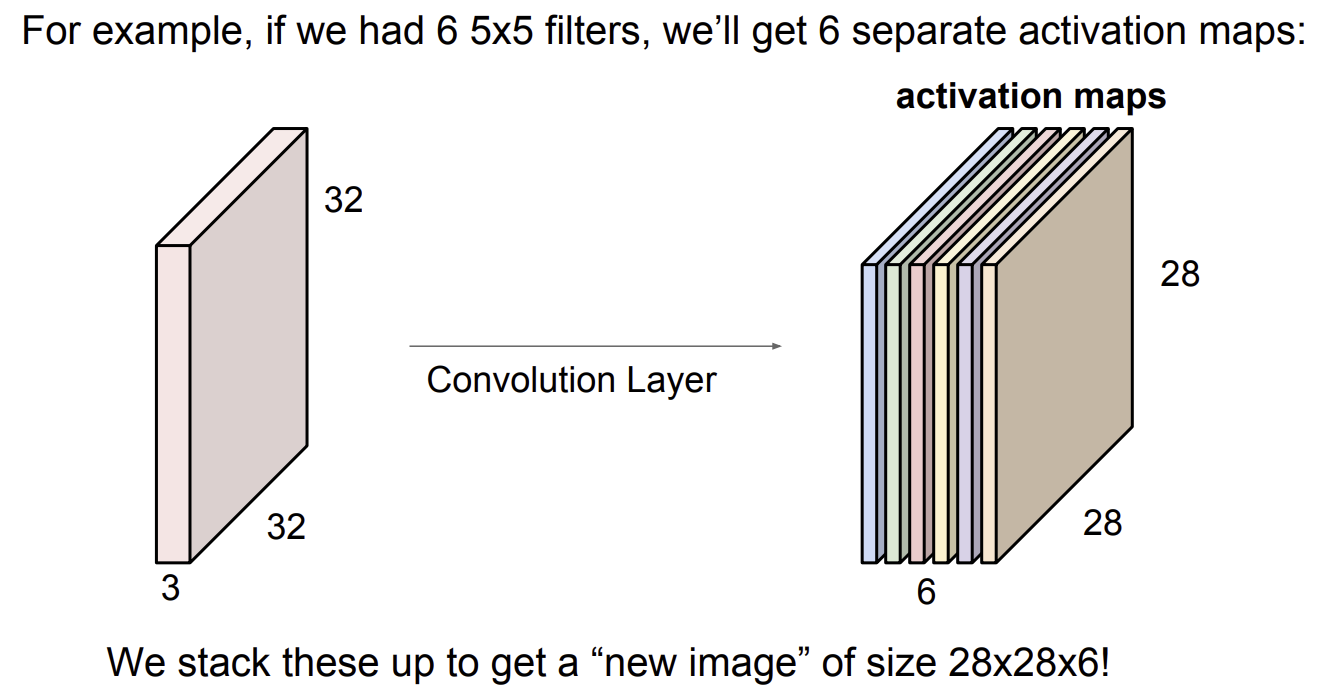
이렇게 필터 6개를 사용한다면, 입력 이미지와의 내적 계산이 6번 반복되므로 activation map의 크기는 이다.
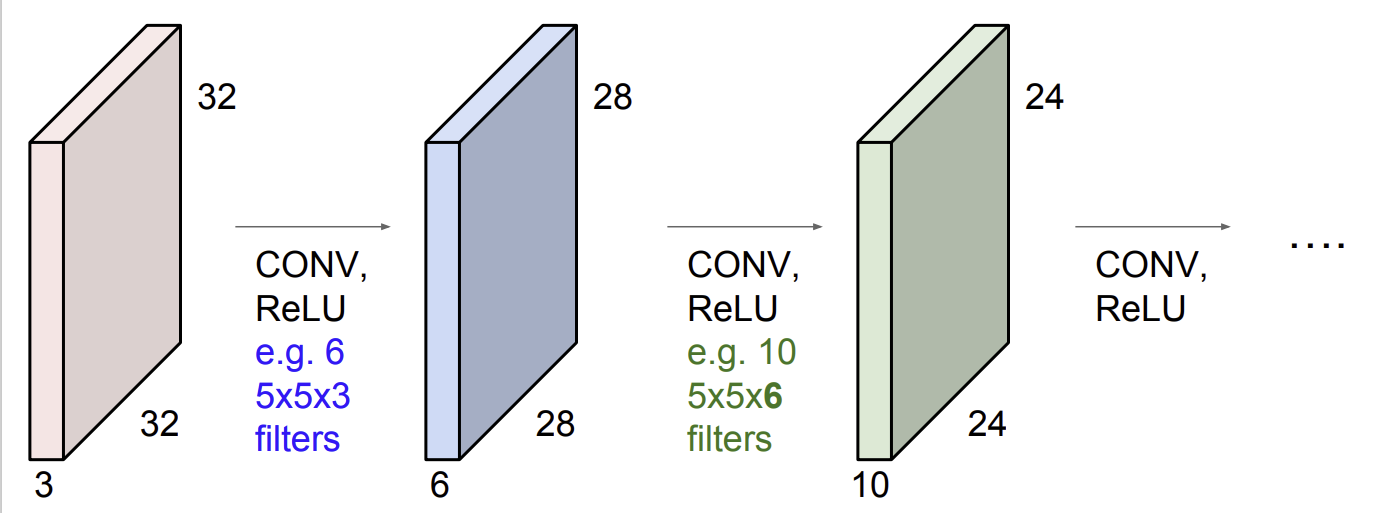
크기의 activation map은 다음 layer에서 입력 데이터로 취급하게 된다.
- 필터의 크기는 depth는 입력 데이터의 depth와 동일해야한다.
- 10개의 필터를 사용할 때, 필터의 크기는 이다.
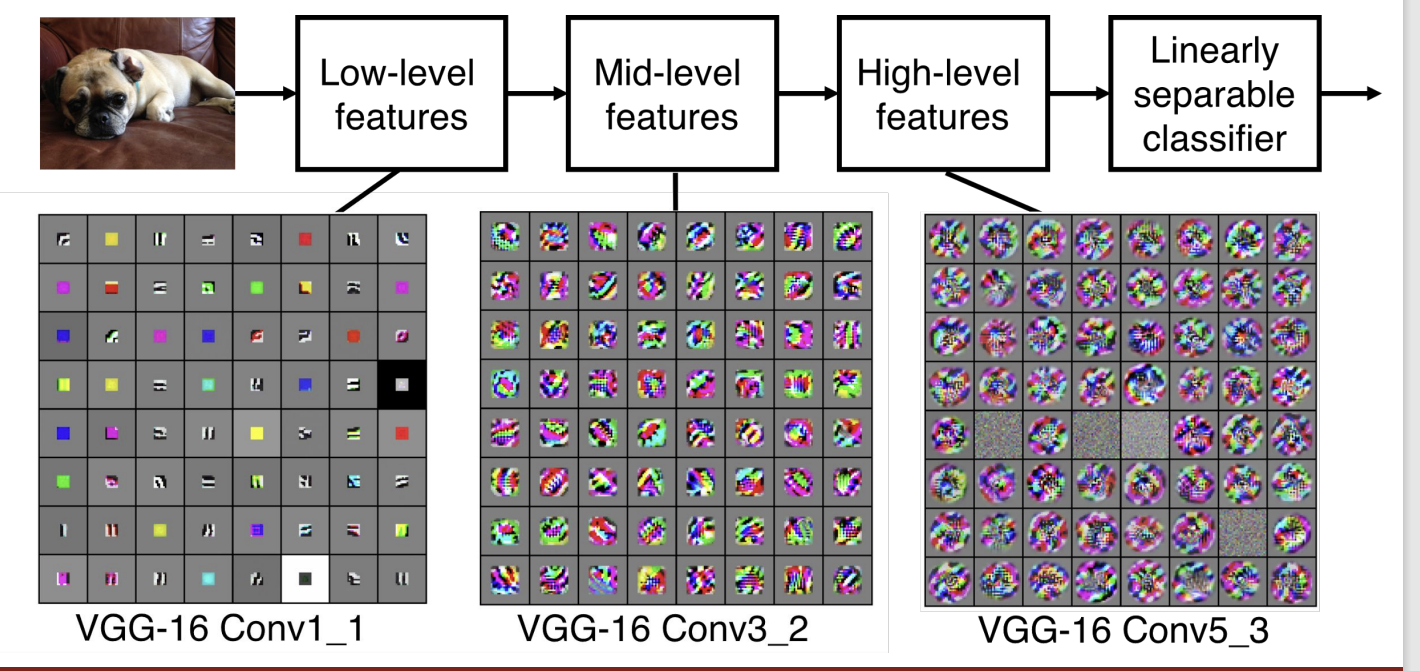
Convolution Layer가 깊어짐에 따라 입력 이미지의 어떠한 특징을 추출해주는지 잘 보여주는 그림이다.
- 초반 Layer (Low-level feature) : 객체의 color & edge들을 추출해준다.
- 중반 Layer (Mid-level feature) : 객체의 corner & blob들을 추출해준다.
- 후반 Layer (High-level feature) : 객체의 디테일한 구조적 특징들을 추출해준다.
이를 통해 CNN이 계층 구조를 가지는 뉴런과 유사하다는 것을 보여준다.
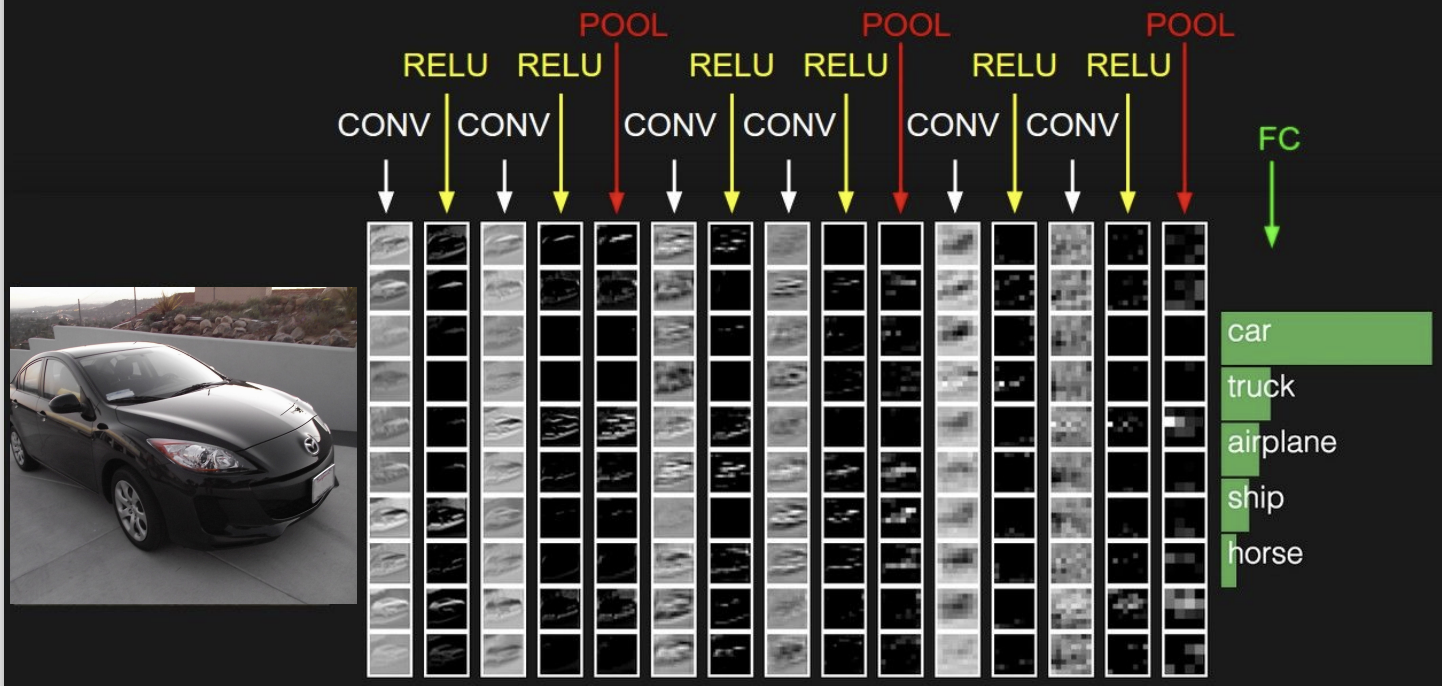
다음 그림은 CNN이 어떻게 구성되는 지 보여주고 있다.
- Convolution layer에 activation function인 ReLU를 쌓고,
activation map의 크기를 줄여주는 pooling layer를 쌓는 방식을 여러 번 진행한다. - 마지막에 Fully connected layer를 쌓아 이미지의 클래스를 예측한다.
(여기서 행(column)은 volume이고 열(row)은 activation map이다.)
filter가 어떻게 슬라이딩하는지에 따라서 출력 차원의 결과를 한 번 살펴보자
7x7 input assume 3x3 filter
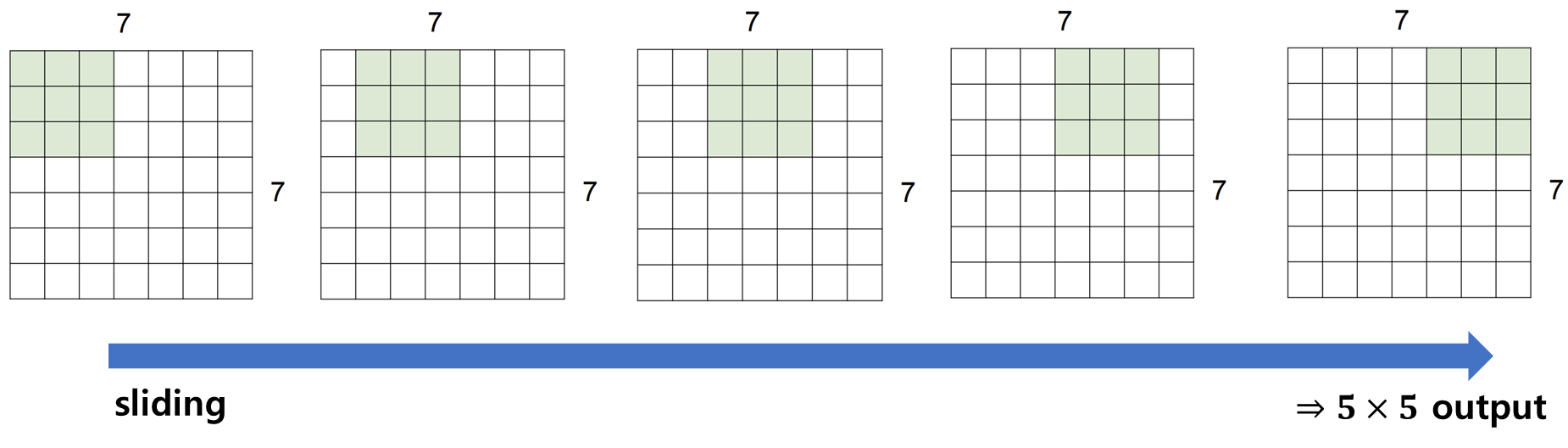
filter가 입력 이미지를 어떻게 슬라이딩하는 지에 대한 예를 들어보자
- 입력 이미지의 크기 = 7x7, 필터의 크기 = 3x3, stride(보폭) = 1
- 이렇게 슬라이딩을 하게 된다면 출력 차원은 가 될 것이다.
7x7 input assume 3x3 filter applied with stride 2
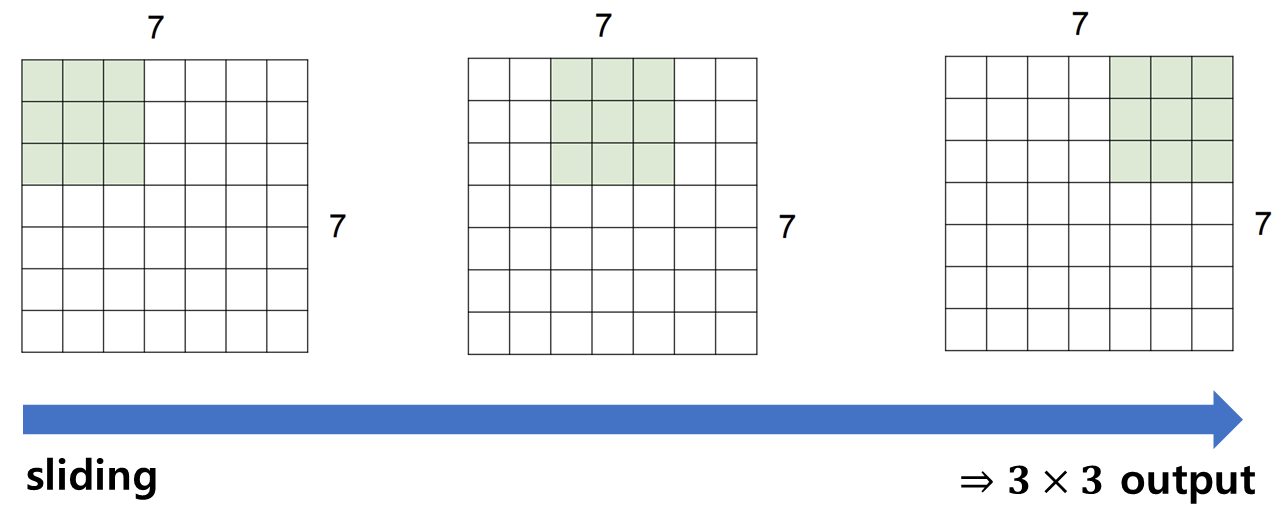
이제부터는 filter가 2칸 씩 슬라이딩 하면서 내적 계산을 한
- CNN에서 중요한 것은 공간적 복잡도와 시간적 복잡도를 낮추는 것이기 때문에 2칸 씩 슬라이딩 하는 것을 자주 이용한다고 한다.
7x7 input assume 3x3 filter applied with stride 3
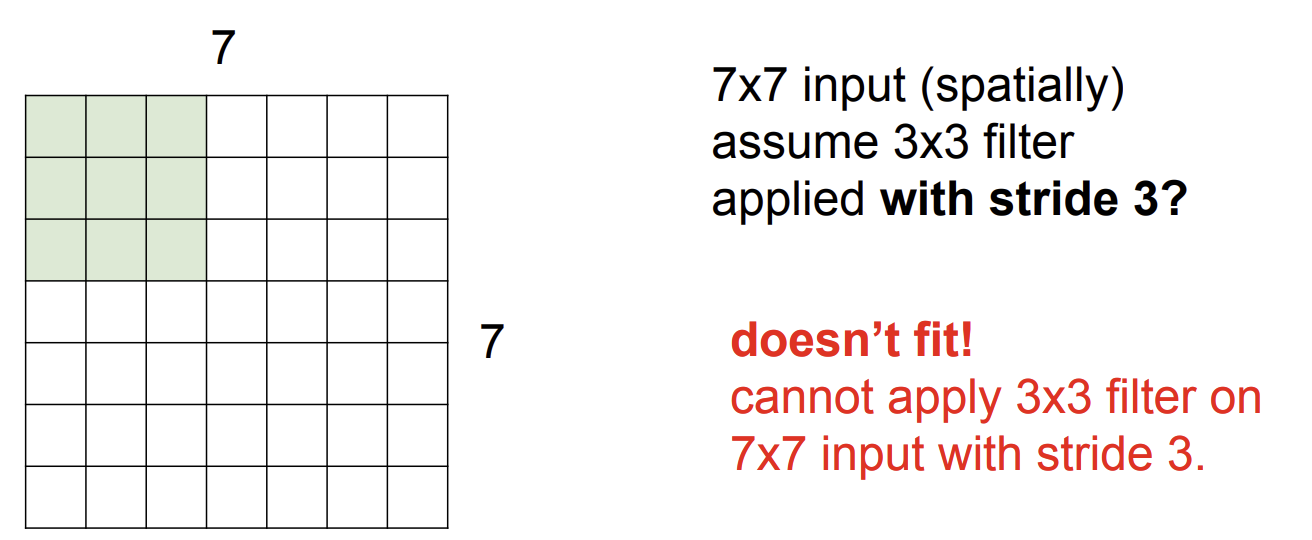
filter가 3칸 씩 슬라이딩 한다면 전체 입력 이미지를 표현할 수 없기 때문에 적용할 수 없다.
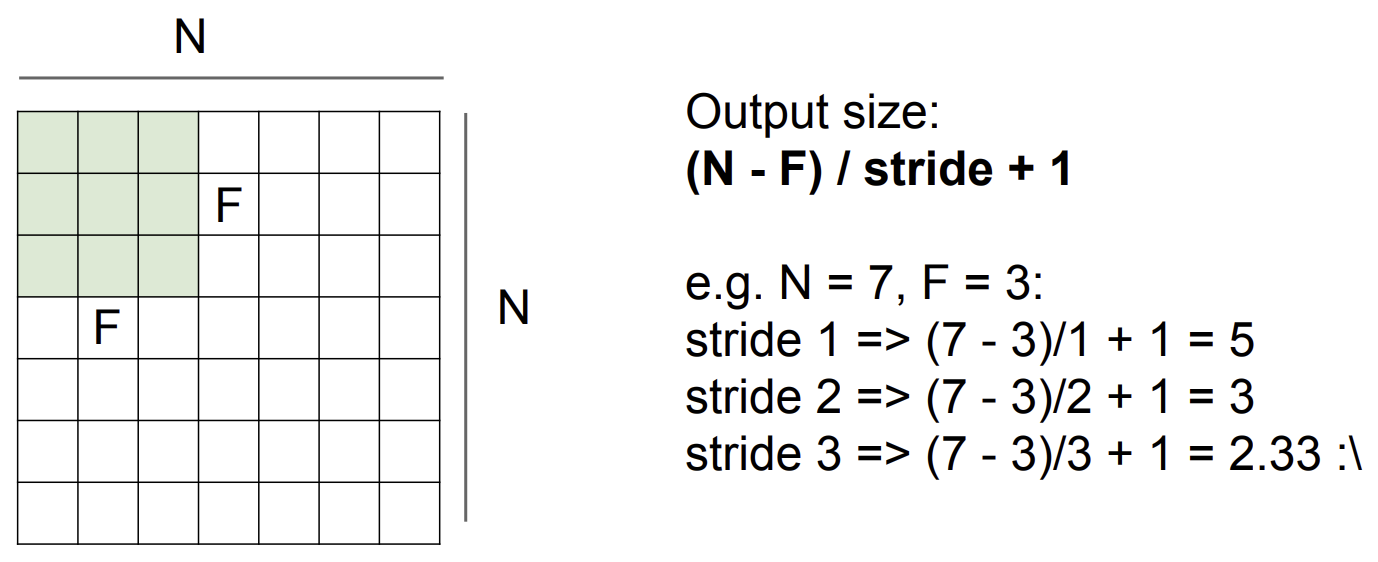
결국 입력 차원과 filter 차원 그리고 stride에 따른 출력 차원의 크기는 다음과 같이 공식화할 수 있다.
practice1
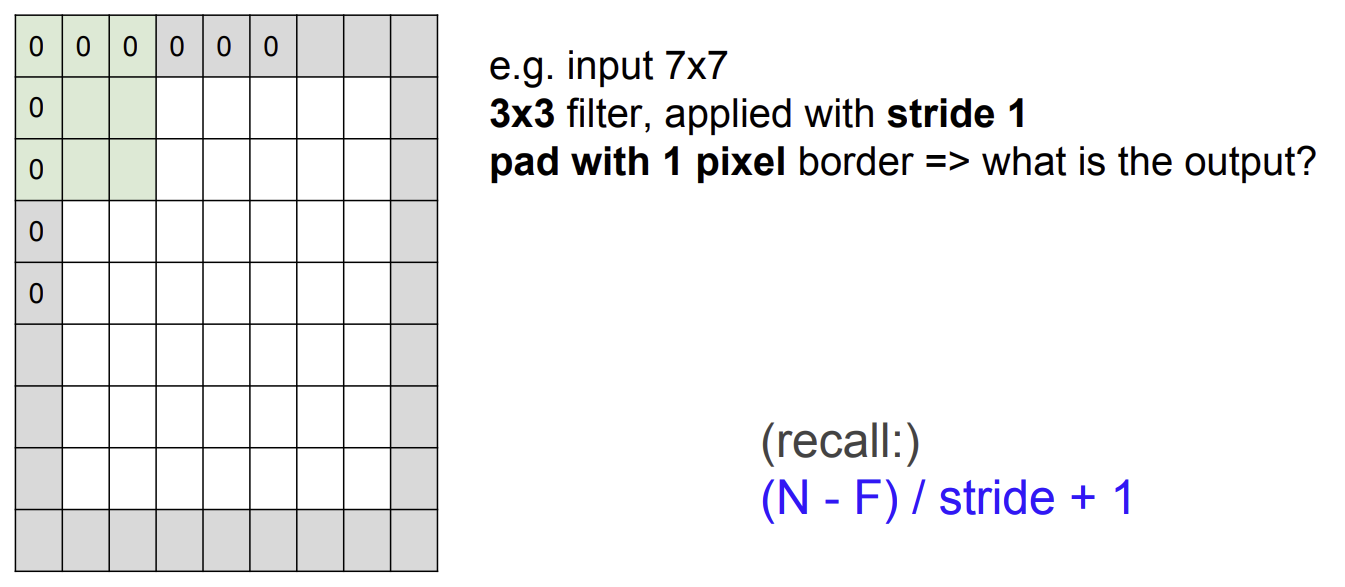
1 pixel만큼 zero padding을 해주었기 때문에 입력 이미지의 크기는 이다.
- 일 때, 출력 차원의 크기는 이다.
practice2

filter의 depth 3이 생략되어 있는데 입력 이미지의 color (RGB)를 내적하는 것은 당연하기 때문이다.
모든 사이드에 2 pixel만큼 padding 시켜줬기 때문에 이다.
이므로, 출력 차원은 이고, 이러한 필터가 10개 있으므로,
최종적으로 이 출력된다.
그럼 파라미터 개수는?
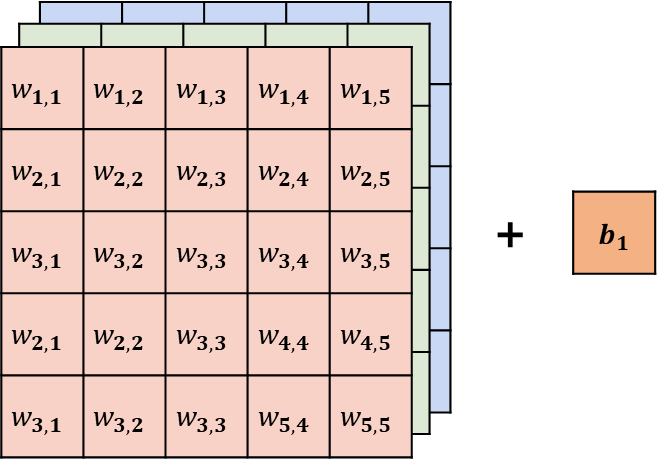
filter의 파라미터 개수는 다음과 같다. 하나의 filter에 대한 파리미터 개수는 76개 이다.
해당 Layer에서의 전체 파라미터는 개가 된다.
1x1 convolution layers

1x1xD filter의 convolution은 차원을 줄여주는 역할을 한다.
- 84x84x64의 입력 이미지를 D개의 1x1x64 필터로 convolve하면 출력 이미지의 크기는 84x84xD이 된다.
- D개의 1x1x64 필터는 수학적으로 FC layer와 같다.
따라서 FC layer와 D개의 1x1x64 필터는 서로 대체할 수 있다. - 다만 FC layer는 고정된 크기를 가지는 입력 이미지를 가지지만 convolution layer는 84x84과 비슷하거나 공간적으로 더 큰 입력 이미지를 받아들인다는 점이 다르다.
뇌/뉴런 관점에서 convolution layer
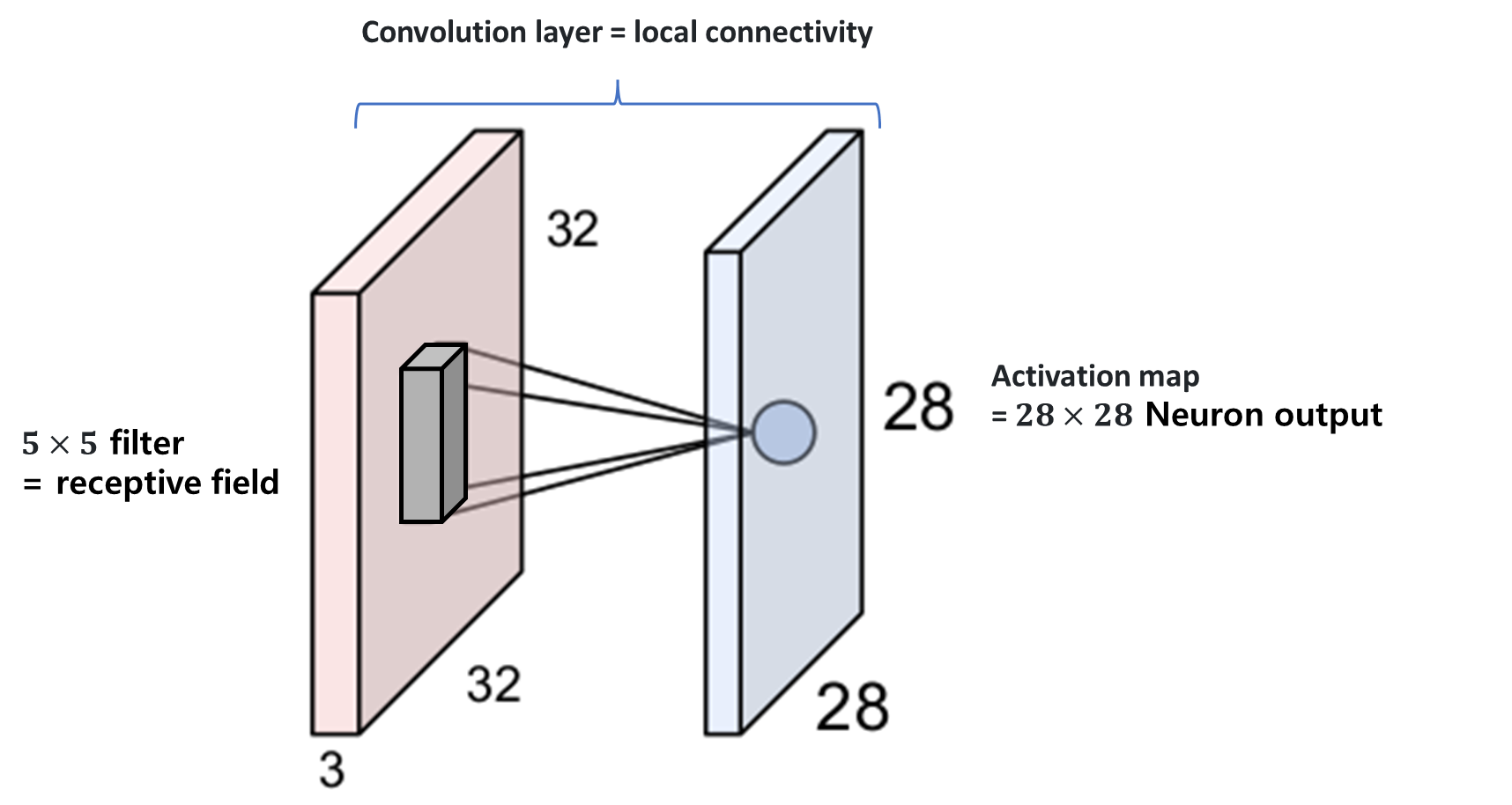
Convolution layer는 입력 이미지를 국소적으로 여러 번 바라보고, FC layer는 입력 이미지를 전체적으로 1번 보는 것과 같다.
- Convolution layer는 입력 이미지를 필터와 convolution을 통해 activation map을 얻는다.
- 입력 이미지 일부분에서 feature을 추출하므로 전체 이미지에서는 여러 개의 특징을 추출한다. 따라서 이미지 확대, 축소, 이동해도 이미지의 특징을 잘 찾을 수 있다. - FC layer는 32x32x3의 이미지를 3072x1의 벡터로 만든 후, 가중치 W와 내적해 1개의 숫자를 추출한다.
- 이미지 전체 feature를 추출하므로 효과적이지 않다.
Pooling layer
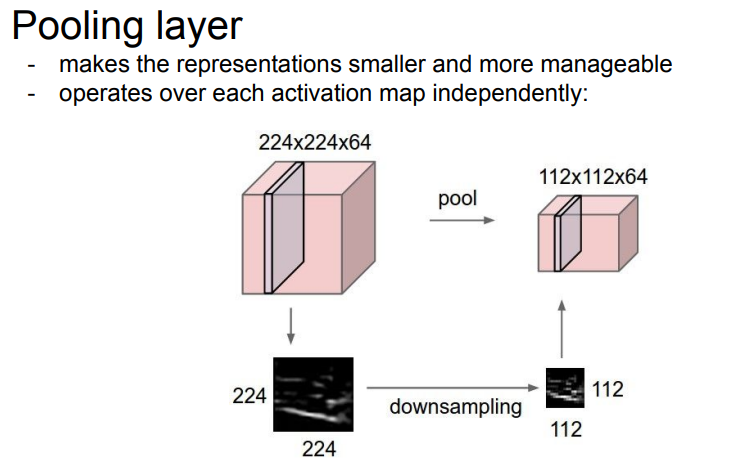
- Pooling layer는 representaions를 downsampling을 통해 공간 & 시간 복잡도를 낮추도록 한다.
주의할 점은 depth는 줄이지 못한다는 것이다.
또한, pooling할 때 padding하지는 않는다.
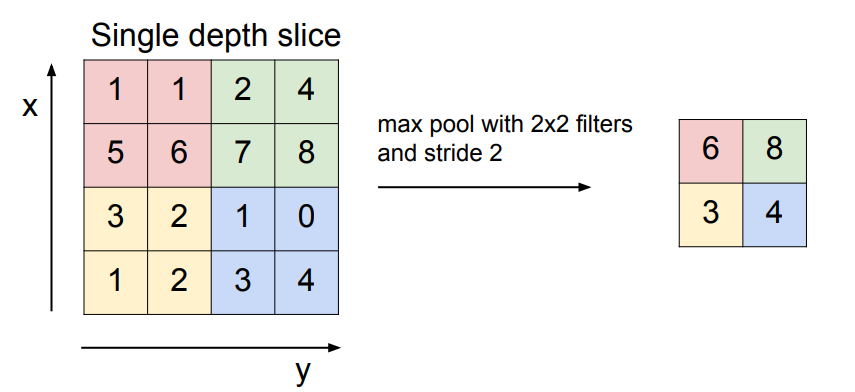
filter의 크기와 stride을 선택하여 입력 이미지를 downsampling하는 것을 Max Pooling이라고 한다.
- filter 안에 존재하는 숫자 중 가장 큰 값을 선택하여 출력 데이터의 크기를 줄인다.
이 또한 test model의 성능을 높여주는 regularization 기법의 일종이다.


보통의 경우에 pooling을 위한 filter의 크기와 stride의 크기는 다음과 같이 설정한다.
