review...
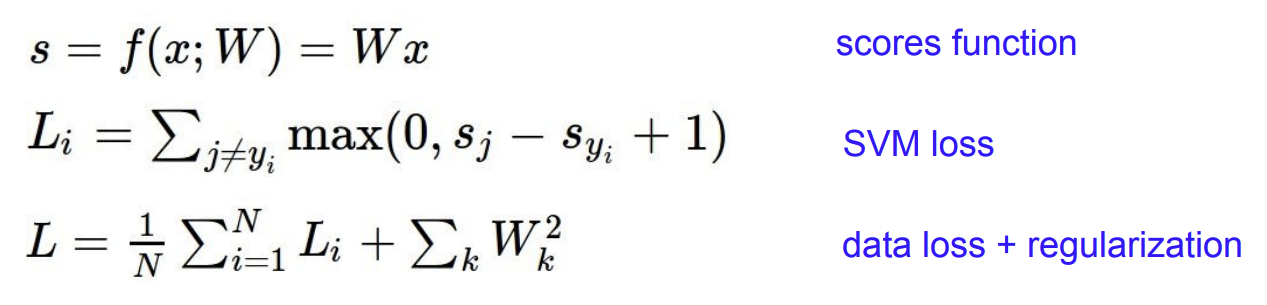
지난 3강에서 우리는 3가지를 배웠다
1. score vector : classifier를 통과해 나온 class의 크기
2. Loss function : 바로 분류한 결과와 실제 값의 차이를 정량적으로 확인하는 function이다.
3. regularization : model의 overfitting을 막기 위한 규제 기법
세 가지 기술은 최적화 기법을 통해 모델의 파라미터 W를 최적화 시켜줄 수 있다. 그럴러면 ∇WL을 알아야 한다.
1. Backpropagation
지난 강의의 마지막 부분에서 gradient를 해석적으로 계산하는 것이 더욱 정확하고 빠른 방법임을 설명을 통해 들었다.
그럼 다음과 같은 의문이 들 것이다.
Neural Network의 미분 계산을 어떻게 해야하지??
미분을 통해서 어떻게 가중치를 최적화시킨다는 말인가??
Computational graph
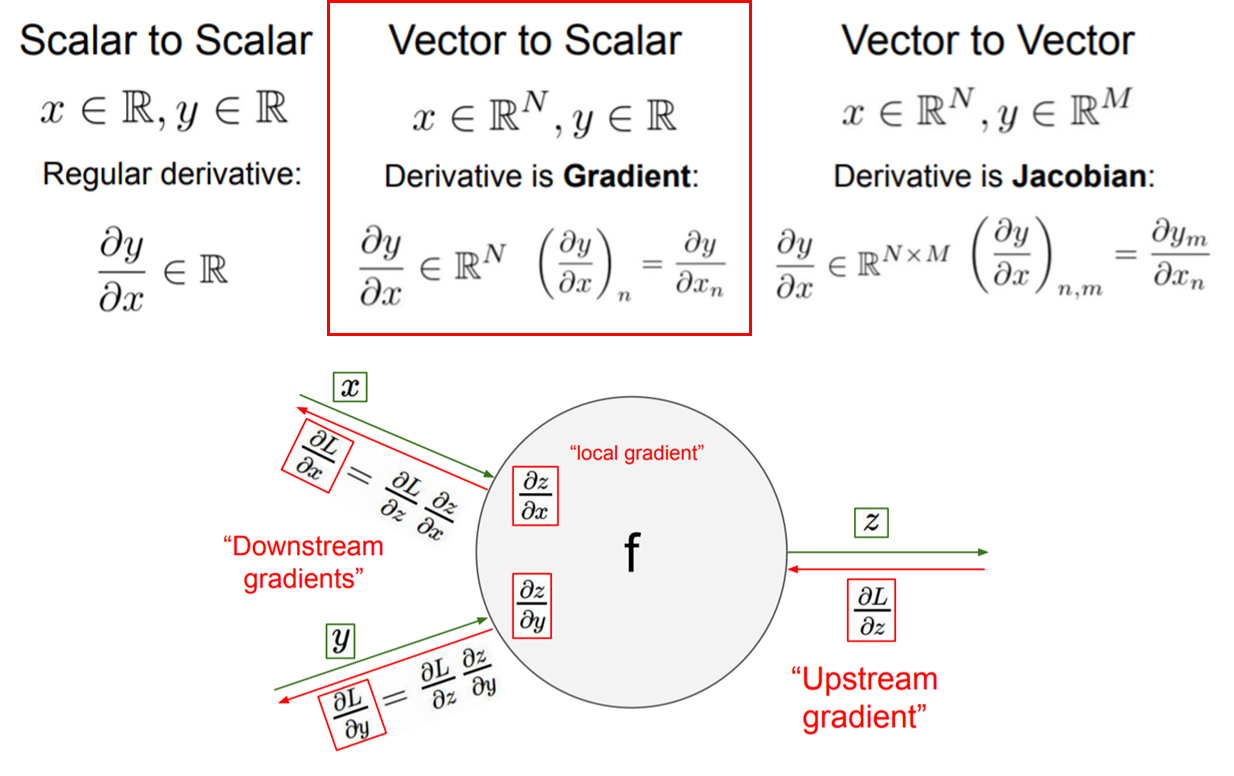
f라는 함수(computation)를 하나의 노드를 표현한 Computational graph를 통해 미분 계산과, 가중치 최적화를 보기 쉽게 표현할 수 있다.
노드의 입력 gradient를 Upstream gradient라고 하고, 노드의 local gradient에 의한 출력 gradient를 Downstream gradient라고 한다.
Downstream gradient는 chain rule에 의해서 Upstream gradient 정보를 가지게 된다.
위 사진에서 x에 대한 Downstream gradient는 이렇게 표현한다.
∂x∂L=∂z∂L×∂x∂z
Patterns in backward flow
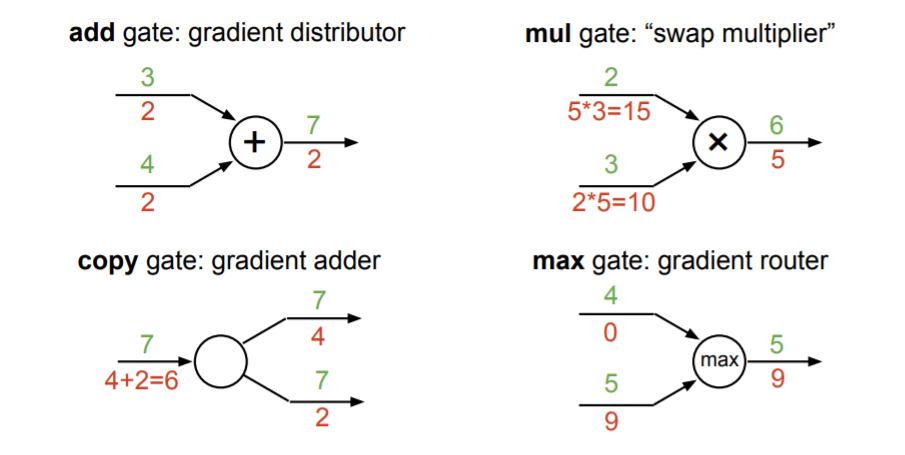
Add gate : 입력식 그대로 출력하여 주는 방식이다.
max gate : 비교되는 두 변수 중에서 max에 해당된 변수에 gradient 값을 통과시켜준다.
mul gate : 두 변수값을 switch해준다.
Scalar operation
example 1
f(x,y,z)=(x+y)z
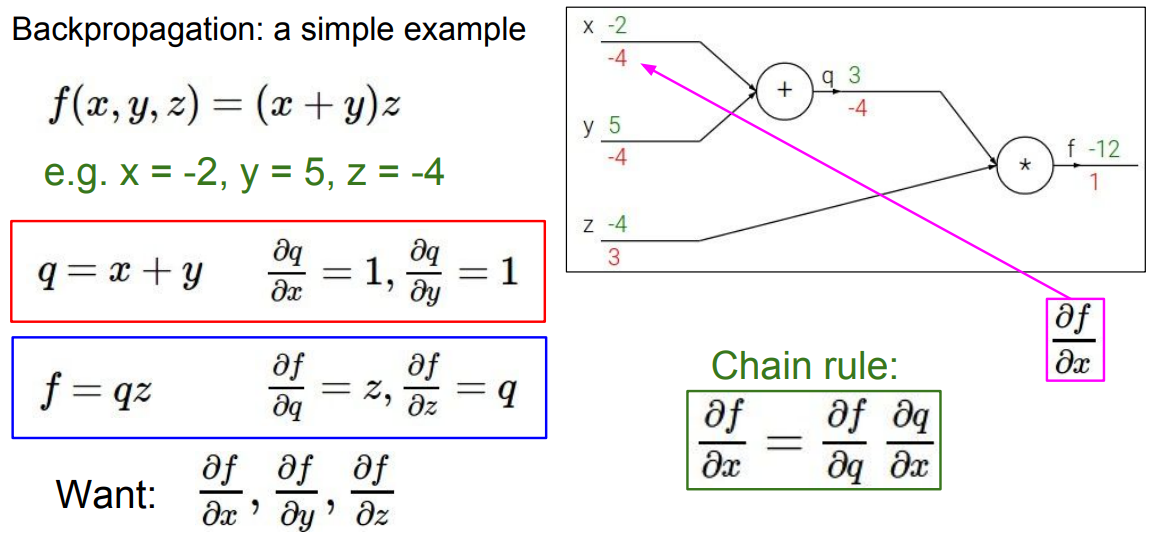
x=−2,y=5,z=−4라고 예시가 주어졌다고 하자
함수 f는 위의 그래프로 나타낼 수 있다.
이제부터 변수 x,y,z에 대한 gradient를 계산해야한다. 각각의 노드를 표현하게 된다면 다음과 같음 함수로 이뤄진다.
f=qzq=x+y
각각의 backpropagation을 구하기 위해 chain rule를 적용하면 다음과 같이 계산된다.
example 2
f(w,x)=1+e−(w0x0+w1x1+w2x2)1
에 대한 backpropagation은? 먼저 computational graph로 표현해보자
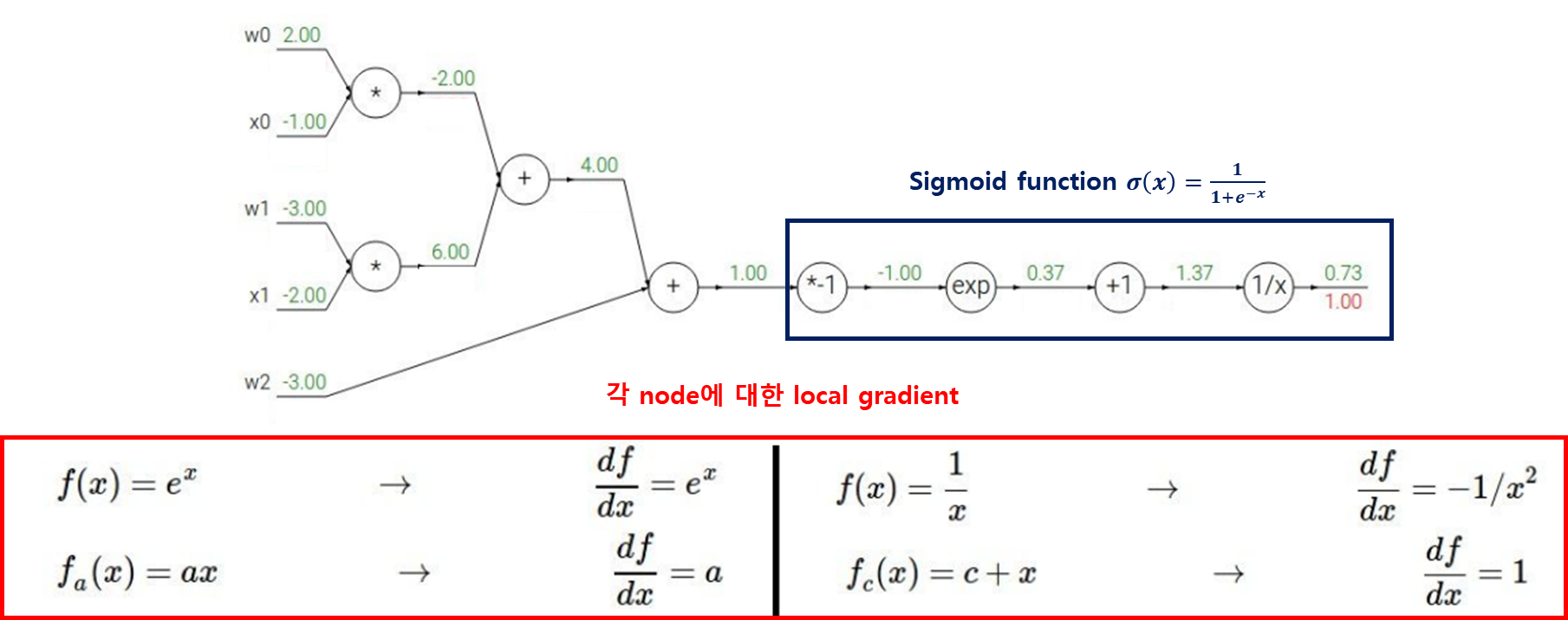
σ(x)=1+e−x1는 sigmoid function으로써 classification에서 쓰이는 activation function 중에 하나이다.
여기서 sigmoid function에 대한 미분 계산을 사전에 정의해줄 수 있다면 계산 비용도 아낄 수 있지 않을까?
dxdσ(x)=1+e−xe−x=(1+e−x1+e−x−1)(1+e−x1)=(1−σ(x))(σ(x))
이렇게 sigmoid function을 하나의 big node로 볼 수 있다.
Vectorized operations
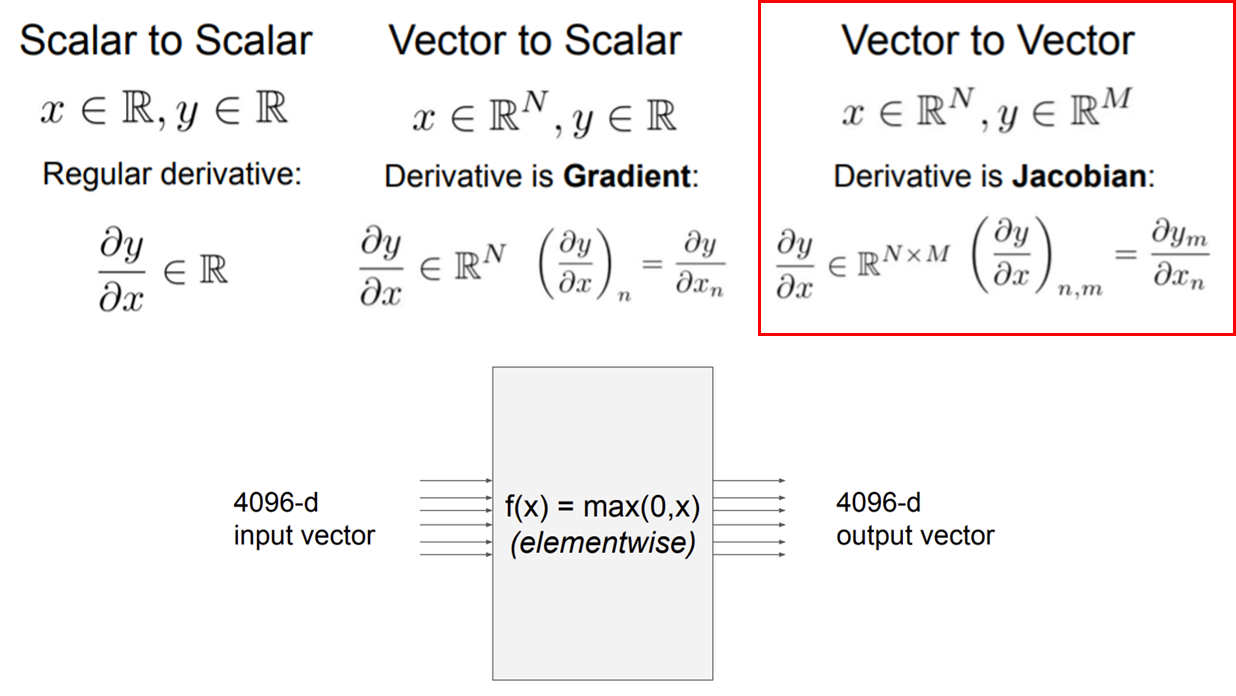
모든 Neural Network의 경우에는 벡터(행렬) 형식의 입력과 출력이 진행된다. 이러한 경우에서는 어떻게 backpropagation이 진행될 것인가?
dx1df=[dx1df,0,…,0]dx2df=[0,dx2df,…,0]
dx4096df=[0,…,dx4096df]
4096×4096 크기의 Jacobian 행렬 계산을 해줘야한다.
사실 이 뿐만 아니라 병렬로 100개의 인풋을 받는다고 하면 input vector는 100×4096이 될 것이고, Jacobian 행렬의 크기는 무려 [409,600×409,600]가 될 것이다.
그러나 행렬식을 잘 보면 Jacobian 행렬은 대각행렬이므로 굳이 행렬 전체를 계산해줄 필요가 없고, 출력에 해당된 요소에만 backpropagation을 진행해주면 된다.
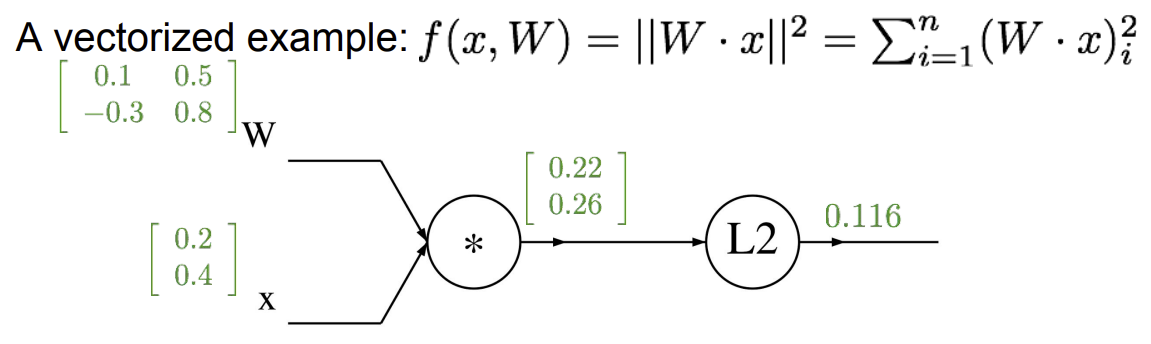
q=W⋅x=⎝⎜⎜⎛W1,1x1+Wn,1x1+⋯⋮⋯+W1,nxn+Wn,nxn⎠⎟⎟⎞ <Vector>f(q)=∥q∥2=q12+⋯+qn2 <scalar>
요소 별(W,x) gradient는 다음과 같이 표현된다.
∂x∂L=∂q∂L×∂x∂q∂W∂L=∂q∂L×∂W∂q
∂q∂L은 gradient를 구하면 되는데, ∂x∂q&∂W∂q는 어떻게 계산해야할까?
행렬의 미분 (from data science school)
q=W⋅x=⎝⎜⎜⎜⎜⎛W1,1x1+W2,1x1+Wn,1x1+W1,2x2+W2,2x2+Wn,2x2+⋯⋯⋮⋯+W1,nxn+W2,nxn+Wn,nxn⎠⎟⎟⎟⎟⎞f(q)=∥q∥2=q12+⋯+qn2
일 때, 행렬 W와 x에 대한 미분 결과는 다음과 같다.
1. ∂x∂q 에 대한 미분
∂x∂q=⎝⎜⎜⎜⎜⎜⎛∂x1∂q∂x2∂q⋮∂xn∂q⎠⎟⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎛W1,1W1,2W1,nW2,1W2,2W2,n⋯⋯⋮⋯Wn,1Wn,2Wn,n⎠⎟⎟⎟⎟⎞=WT
2. ∂W∂q 에 대한 미분
∂W∂q=⎝⎜⎜⎜⎜⎜⎛∂W1,1∂q∂W2,1∂q∂Wn,1∂q∂W1,2∂q∂W2,2∂q∂Wn,2∂q⋯⋯⋮⋯∂W1,n∂q∂W2,n∂q∂Wn,n∂q⎠⎟⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎛x1x1x1x2x2x2⋯⋯⋮⋯xnxnxn⎠⎟⎟⎟⎟⎞=(x1x2⋯xn)=xT
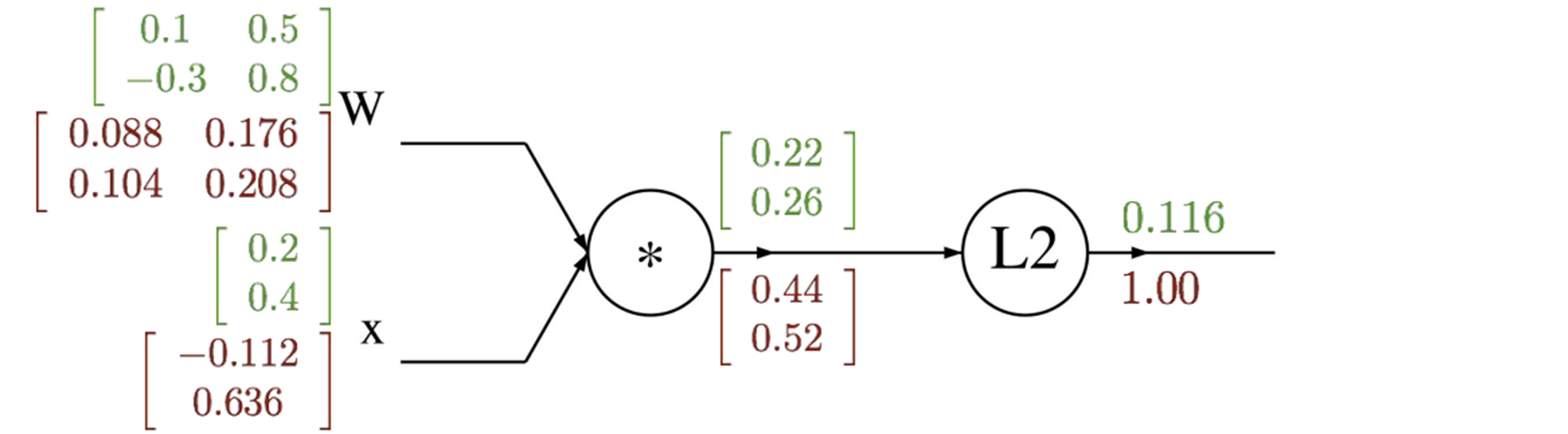
행렬 미분의 법칙을 알기만 한다면 다음과 같이 계산이 가능하다
∂x∂L=∂q∂L×∂x∂q=∂q∂L WT∂W∂L=∂q∂L×∂W∂q=xT ∂q∂L
Conclusion
이번 챕터는 수학적인 내용이 매우 많이 나왔다.
그러나 차근차근 되짚어 본다면 또 어려운 내용이 아니므로 걱정은 하지 않도록한다! (나에게 하는 말이다)!

