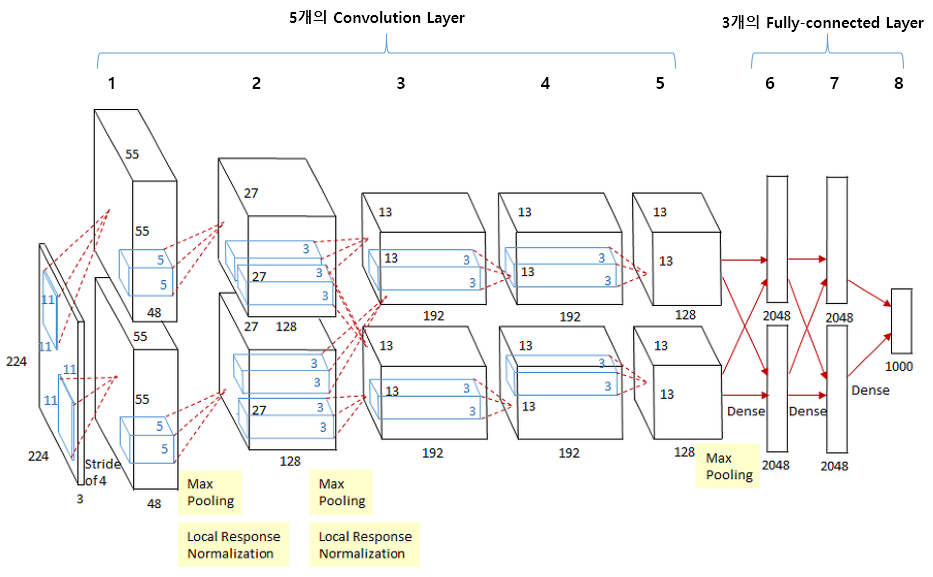
AlexNet은 2012년 ILSVRC 대회의 우승을 차지한 CNN 구조이다.(오차율 15.4~18.2%)
논문 명 : ImageNet Classification with Deep Convolution Neural Network"
이 논문의 첫번째 저자가 Alex Khrizevsky이기 때문에 AlexNet이라고 부른다.
AlexNet 구조
이전의 모델과는 다르게, 2개의 GPU로 병렬연산을 수행하기 위해 병렬적으로 설계되었고, 5개의 Conv-Layer와 3개의 Fc-Layer로 총 8개의 레이어로 구성되어 있다.
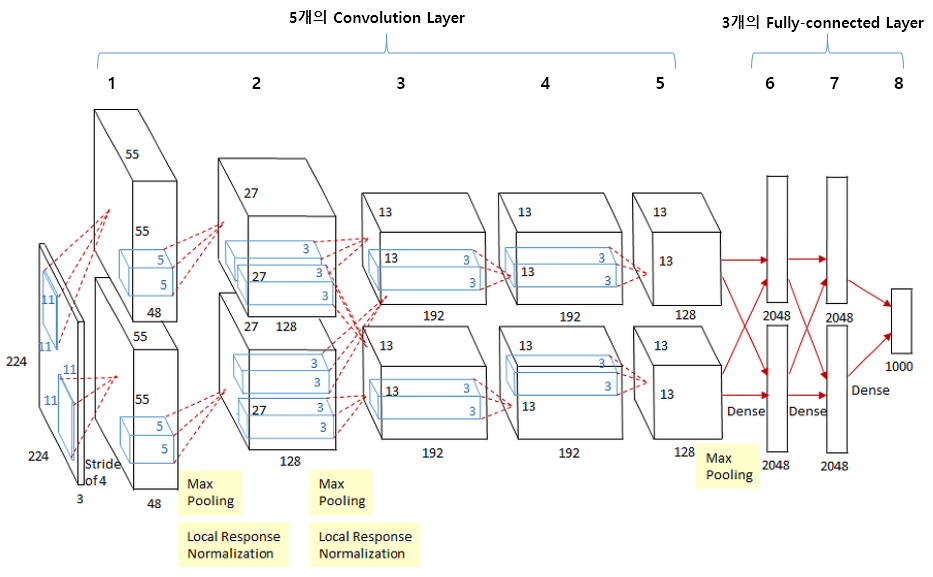
[이미지 출처: https://velog.io/@lighthouse97/AlexNet%EC%9D%98-%EC%9D%B4%ED%95%B4]
예시 구성.
코드를Input (224x224x3)
→ Conv1 → ReLU → MaxPool1
→ Conv2 → ReLU → MaxPool2
→ Conv3 → ReLU
→ Conv4 → ReLU
→ Conv5 → ReLU → MaxPool3
→ Flatten → FC1 → ReLU → Dropout
→ FC2 → ReLU → Dropout
→ FC3 → Softmax
입력하세요각 레이어 특성
🔹 Conv1
필터 크기: 11×11, 스트라이드: 4, 패딩: 0
출력 채널 수: 96
출력 크기: 55×55×96
📌 알아야 할 것:
커널 크기가 크고, stride도 크다 → 계산량 감소 목적
ReLU 적용 후 Max Pooling
🔹 MaxPool1
필터: 3×3, stride: 2
출력 크기: 27×27×96
📌 알아야 할 것:
풀링을 통해 공간 정보를 압축하고, 연산량을 줄이고, 과적합 방지
🔹 Conv2
필터 크기: 5×5, padding: 2
출력 채널 수: 256
출력 크기: 27×27×256
📌 알아야 할 것:
이 레이어는 GPU 2개에 나눠서 연산함 → 당시 하드웨어 한계 때문
🔹 MaxPool2
필터: 3×3, stride: 2
출력 크기: 13×13×256
📌 알아야 할 것:
풀링을 통해 공간 정보를 압축하고, 연산량을 줄이고, 과적합 방지
🔹 Conv3
필터 크기: 3×3, padding: 1
출력 채널 수: 384
출력 크기: 13×13×384
📌 알아야 할 것:
작은 커널을 사용해서 심층 특징 추출
🔹 Conv4
필터: 3×3, padding: 1
출력 채널 수: 384
출력 크기: 13×13×384
📌 알아야 할 것:
이전 레이어와 유사하지만, GPU 간 분산 학습 고려됨
🔹 Conv5
필터: 3×3, padding: 1
출력 채널 수: 256
출력 크기: 13×13×256
📌 알아야 할 것:
마지막 Conv layer → 특징 맵을 최종적으로 추출
🔹 MaxPool3
필터: 3×3, stride: 2
출력 크기: 6×6×256
🔹 Flatten
6×6×256 = 9216 차원의 벡터로 변환
📌 완전연결층(FC)에 넣기 위해 1D로 변환함
🔹 FC1 (Fully Connected Layer 1)
입력: 9216
출력: 4096
📌 알아야 할 것:
큰 파라미터 수 → 과적합 방지 위해 Dropout 적용
🔹 Dropout (0.5)
과적합 방지를 위한 랜덤 뉴런 비활성화
🔹 FC2
입력: 4096
출력: 4096
📌 FC1과 구조 동일, dropout 반복 적용
🔹 FC3 (Output Layer)
출력: 1000 (ImageNet 클래스 수)
Softmax 적용 → 확률 출력
✅ 요약표
| Layer | Kernel | Stride | Padding | Output Size | 특이사항 |
|---|---|---|---|---|---|
| Conv1 | 11×11×3×96 | 4 | 0 | 55×55×96 | 큰 stride, 연산 절약 |
| Pool1 | 3×3 | 2 | - | 27×27×96 | |
| Conv2 | 5×5×96×256 | 1 | 2 | 27×27×256 | GPU 분산 |
| Pool2 | 3×3 | 2 | - | 13×13×256 | |
| Conv3 | 3×3×256×384 | 1 | 1 | 13×13×384 | |
| Conv4 | 3×3×384×384 | 1 | 1 | 13×13×384 | |
| Conv5 | 3×3×384×256 | 1 | 1 | 13×13×256 | |
| Pool3 | 3×3 | 2 | - | 6×6×256 | |
| FC1 | - | - | - | 4096 | Dropout(0.5) |
| FC2 | - | - | - | 4096 | Dropout(0.5) |
| FC3 | - | - | - | 1000 | Softmax |
✅ 핵심 요약
- AlexNet은 12년 당시 오차가 가장 적은 성능의 CNN모델이었다.
- AlexNet은 8개의 레이어로 (5개 conv, 3개 fc)이루어져 있다.
- 당시 기술적 한계 극복을 위한 GPU 병렬처리.
- ReLu : 딥러닝 학습을 빠르게 만든 핵심이다.
- Dropout : 대형 FC 층의 레이어에서 과적합을 방지.
- 커널 크기 : 초반 큰 커널(1111), 이후 작은 커널(33)로 맥스 풀링.
