특징
- One Stage Detector의 빠른 Detection 시간의 장점을 가짐
- One Stage Detector의 Dectection 성능 저하 문제를 개선함
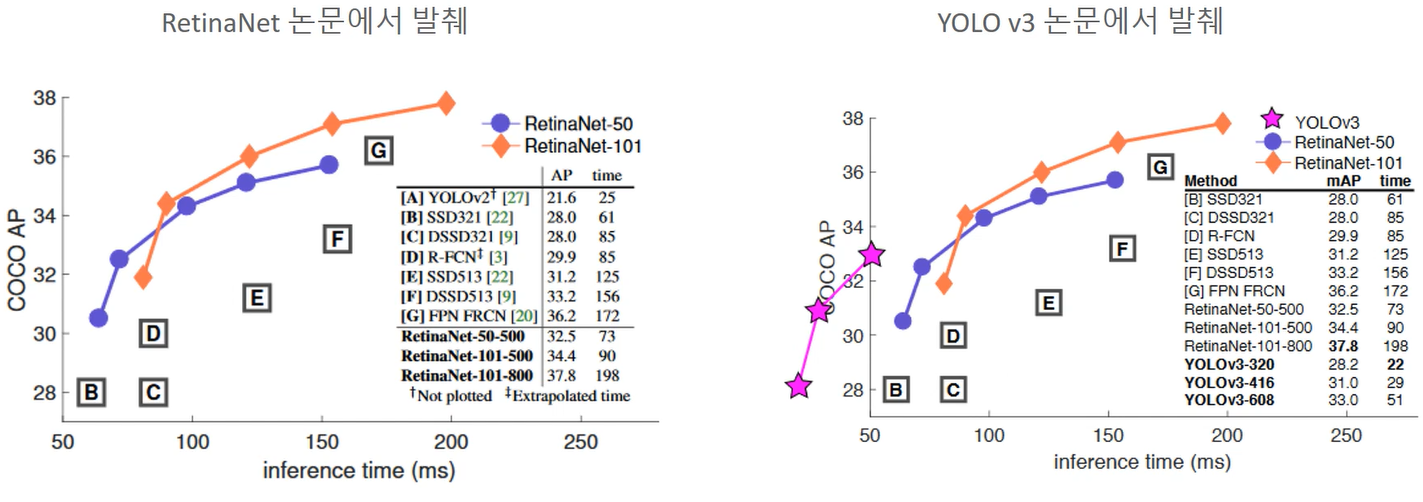
- 수행 시간: YOLO나 SSD보다 느리지만 Faster RCNN보다 빠름
- 수행 성능: 다른 Detection 모델보다 뛰어남. 다른 One Stage Detector보다 작은 오브젝트에 대한 Detection 능력이 뛰어남
2017년에 One Stage Detection이 빠르지만 Faster RCNN보다 성능이 떨어진다는 인식이 있었음. One Stage Detector의 고질적인 문제는 작은 문제를 Dectect하는 것이 어렵다는 것이었음. 이때 등장한 RetinaNet ,,
Loss Funtion: Focal Loss라는 Cross entropy를 대체한 새로운 Loss함수
Backbone: Feature Pyramid Network
성능
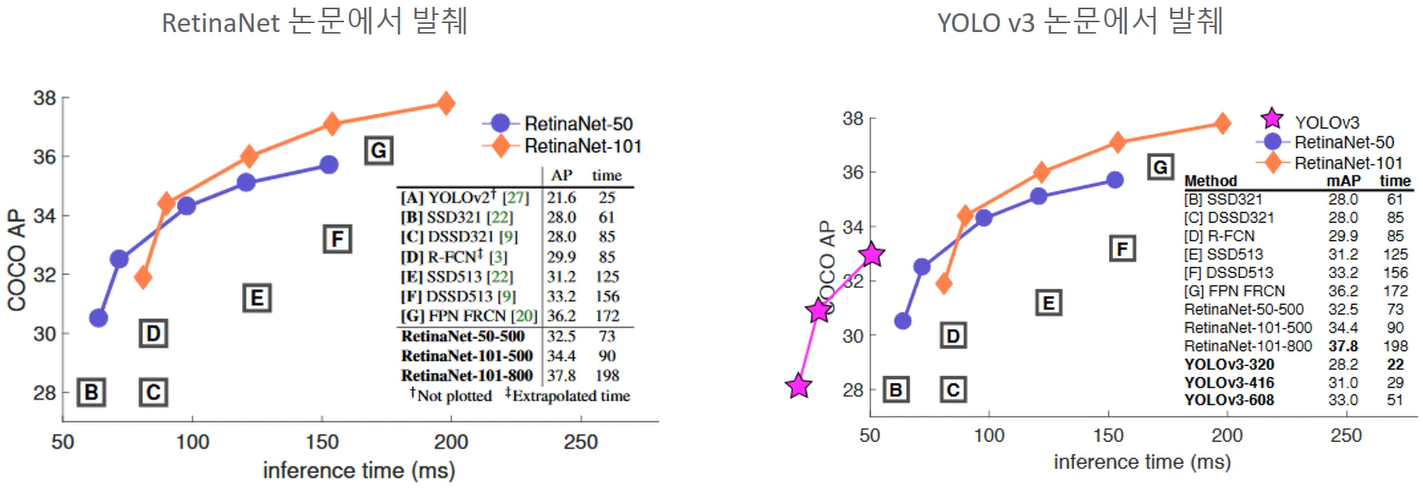
Detection성능과 time을 모두 잡았다고 평가받는 YOLO v3과 비교를 해보면
작은 object detect하는 것에서는 retina net이 많이 활용됨.
Focal Loss
cross entropy의 변형이라고 생각하면 됨.
Cross Entropy

ground truth에서 예측값q, 실제값p
이렇게 예측된 loss 값을 줄이는 방향으로 학습이 진행됨
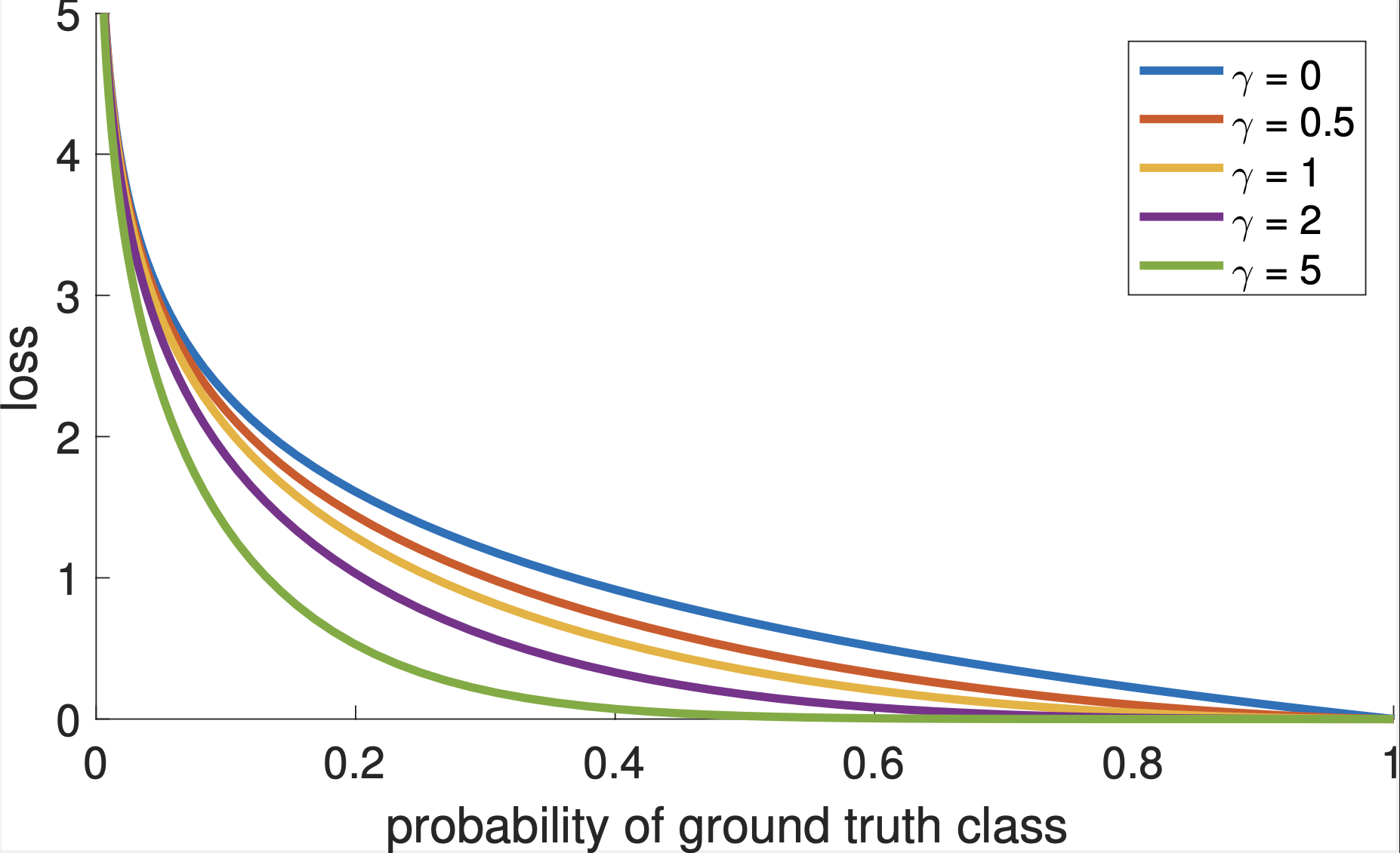
0.8을 기준으로 생각해보면 (Loss대충 0.2) 어느정도 확실하기 때문에 덜 Loss를 줘도 됨
Loss 1.2인 곳에서는 더 Loss를 부여해야 함
Class imbalance
앵커박스를 사용하는데, object가 있을만한 곳 힌트를 얻음.
앵커 5개,4개,9개 이런식으로 구성하기 때문에 SSD만해도 8000여개가 생기게 됨.
그러나 여기선 앵커들이 백그라운드 학습에 치중이 됨
포어그라운드 예시들을 가져오는데 백그라운드 학습에 압도가 되어버림
kite 60% person58% 사람있는데 찾지도못함 kite 두개 찾지못함
Easy Example: 찾기 쉬운 대상들. Background나 크고 선명한 대상 오브젝트. 이미 높은 예측 확률을 가지고 있음.
Hard Example: 찾기 어려운 대상들. 작고 형태가 불분명하여 낮은 예측 확률을 가지고 있음
Easy Example이 많고 Hard Example이 적은 Class imbalance이슈는 Object Detection이 안고 있는 고유 문제임.
Two Stage Detector의 경우는 Region Proposal Network에서 오브젝트가 있을만한 높은 확률 순으로 필터링을 먼저 수행할 수 있음.
One stage는 Region Proposal과 Detection을 같이 수행하므로 매우 많은 오브젝트 후보들에 대해서 Detection을 수행해야 하므로 Class imbalance로 인한 성능 저하 영향이 큼.
여러개의 이미지가 있기 때문에 만개 vs 50개
만개는 loss=0.1 (10배 차이로 만개가 더 큼)
hard는 loss=2
ex) 모든 방향성이 만개쪽으로 가버리는 문제가 발생함. 예측이 불확실한 애들보다 예측이 이미 잘된애들 쪽으로 계속 치우치는 문제가 발생함
예측이 불확실한 Object들을 개선하려는 방향성으로 학습이 진행되지 않고,
이미 높은 예측 확률을 가진 easy example인 background나 확실한 object들에 대해서 더 정호가한 예측을 하기 위해 학습이 진행됨
Class imbalance 해결 방안
- 기존 One stage detector의 class imbalance 해결 방안
: 학습 시 경험치에 기반한 샘플링이나 data augmentation에 집중 - RetinaNet의 class imbalance 해결 방안
: 동적으로 Cross entropy를 조절할 방법을 찾음 -> Focal Loss
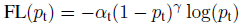
가중치 값: 1-p
ex) p가 0.99면 0.01의 제곱으로해서 0.0001이 가중치로 부여됨
FocalLosss는 매우 쉽게 판별한거에서 Loss가 완전히 떨어짐
보통 알파는 0.25, 감마를 2로 함.
앵커박스를 많이 한 이유: Focal Loss가 있기 때문에
FPN(Feature Pyramid Network)
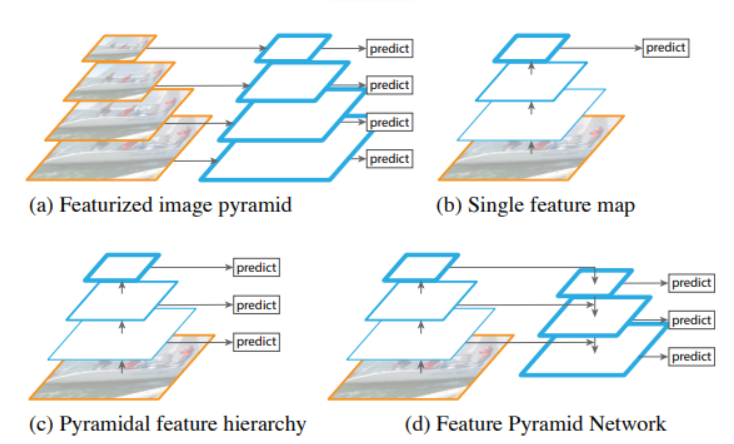
(로마의 휴일 사진)
(a) 서로 다른 크기를 가지는 오브젝트를 디텍트하기 위해서 이미지 사이즈를 줄여나감. 큰 오브젝트를 디텍트 할 수 있지만 시간이 너무 오래걸린다는 단점이 있음.
(b) 위치적 정보 특성이 소멸되어 정확도가 떨어짐
(c) 일반적으로 각 레벨의 feature map을 prediction함 (대표적으로 SSD가 있음)
(d) 위로 올라갈수록 semantic적인 것은 강하지만 resolution 측면에선 떨어짐. 이 측면을 skip 커넥션으로 보완해서 커넥트함.(skip connection: 입력데이터가 네트워크 출력 레이어에 직접 연결되는 방식) 이 때 upsampling을 하게 됨.
서로 다른 크기를 가지는 Object들을 효과적으로 Detection하기 위하여 bottom up과 top down방식으로 추출된 feature map들을 lateral connection으로 연결하는 방식
FPN 구조
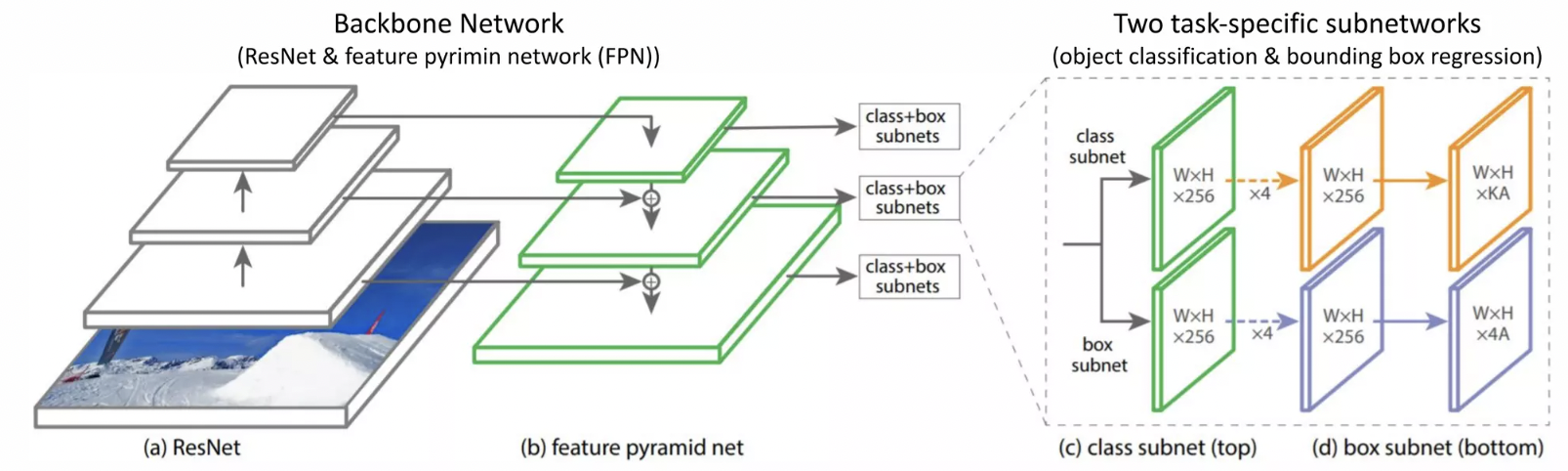
class probability와 bounding box를 개별적으로 계산함(class subnet을 통해)
resnet이 bottom up이 되는 거고 fpn이 topdown 구조가 되는 것임.
top down된 구조를 3x3 Conv한 결과를 가지고 class probability와 bounding box regression을 계산함
개별 앵커박스는 k개의 classification 확률을 가지기 때문에
if k==20 (pascal VOC)
20개 + 4(regression 좌표) = 24개 값을 개별 앵커박스들이 가지게 되는 것
이 학습된 앵커박스를 기반으로
0.5 씩 size가 계속 줄어듦
1x1 Conv해서 사이즈가 그대로 내려옴
M5에서 M4로 올 때는 사이즈가 2배로 upsampling을 함.(두배하고 더하고 두배하고 더하고..)
M5를 3x3한 결과를 가지고 prediction 하는 것
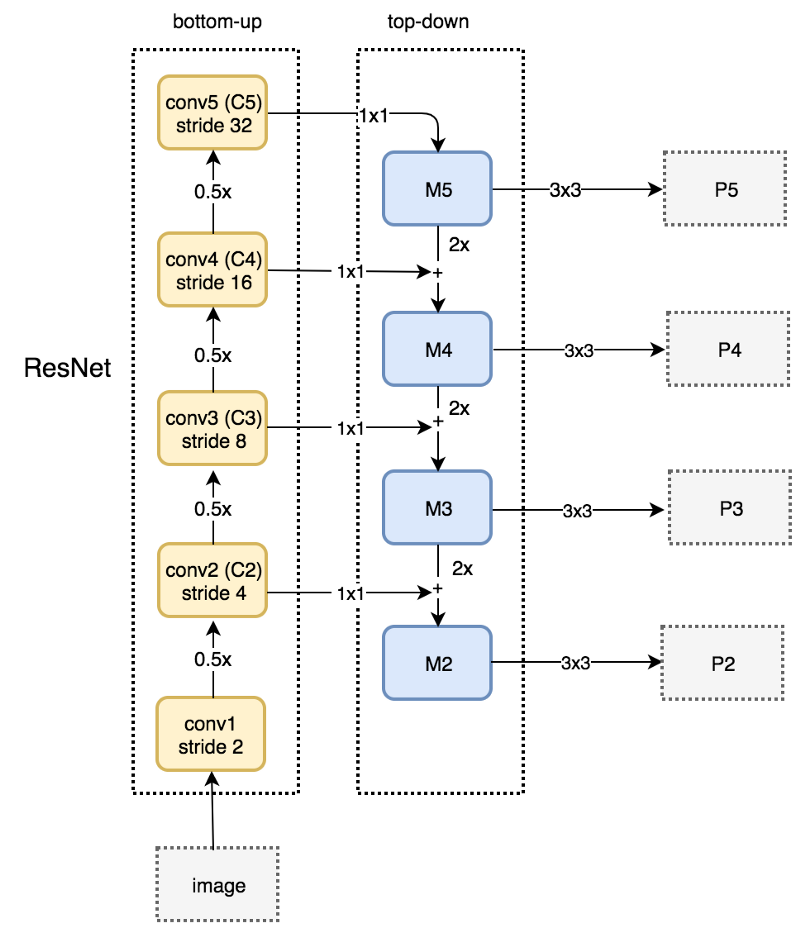
레터널 커넥션이 resnet에서 올라갔던게 앞에서 만들어졌던 featuremap이 두배를 해줌
(오른쪽)3x3Conv하는 이유 (aliasing 에일리어싱 effect: 서로 다른 두개 시그널이 섞이면 혼동되어 원래 가지고 있는 특성을 잊어버리는 현상이 있는데 3x3하면 그 현상이 희석된다고 함.
앵커는 개별 레벨별로 9개의 앵커가 개별 포인트에 찍힘. 포인트별로 9개씩 있는 것.
밑으로 내려갈수록 사이즈가 커짐(feature map size)
1. 9개의 anchor box가 P2~P5의 개별 Layer의 개별 grid에 할당.
2. 3개의 서로 다른 크기와 3개의 서로 다른 스케일을 가짐.
3. 약 십만개의 anchor box들
4. 개별 anchor box는 Classification을 위한 K개의 클래스 확률값과 Bounding box regression을 위한 4개 좌표 값을 가짐.
