ComputerVision
1.RetinaNet
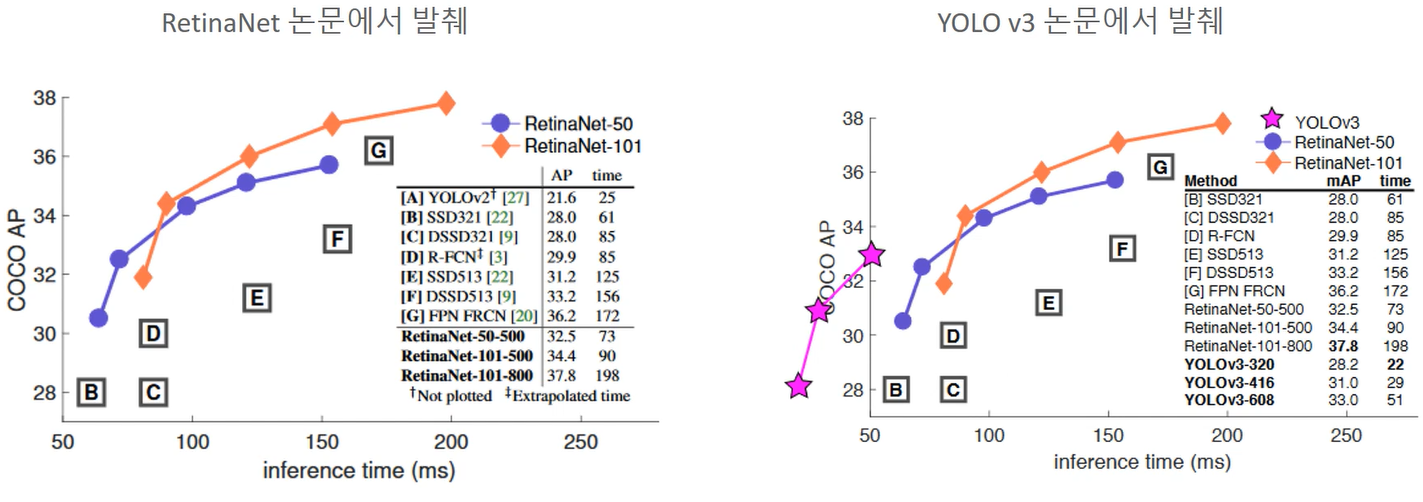
One Stage Detector의 Detection 성능 저하 문제를 개선함
2.EfficientDet
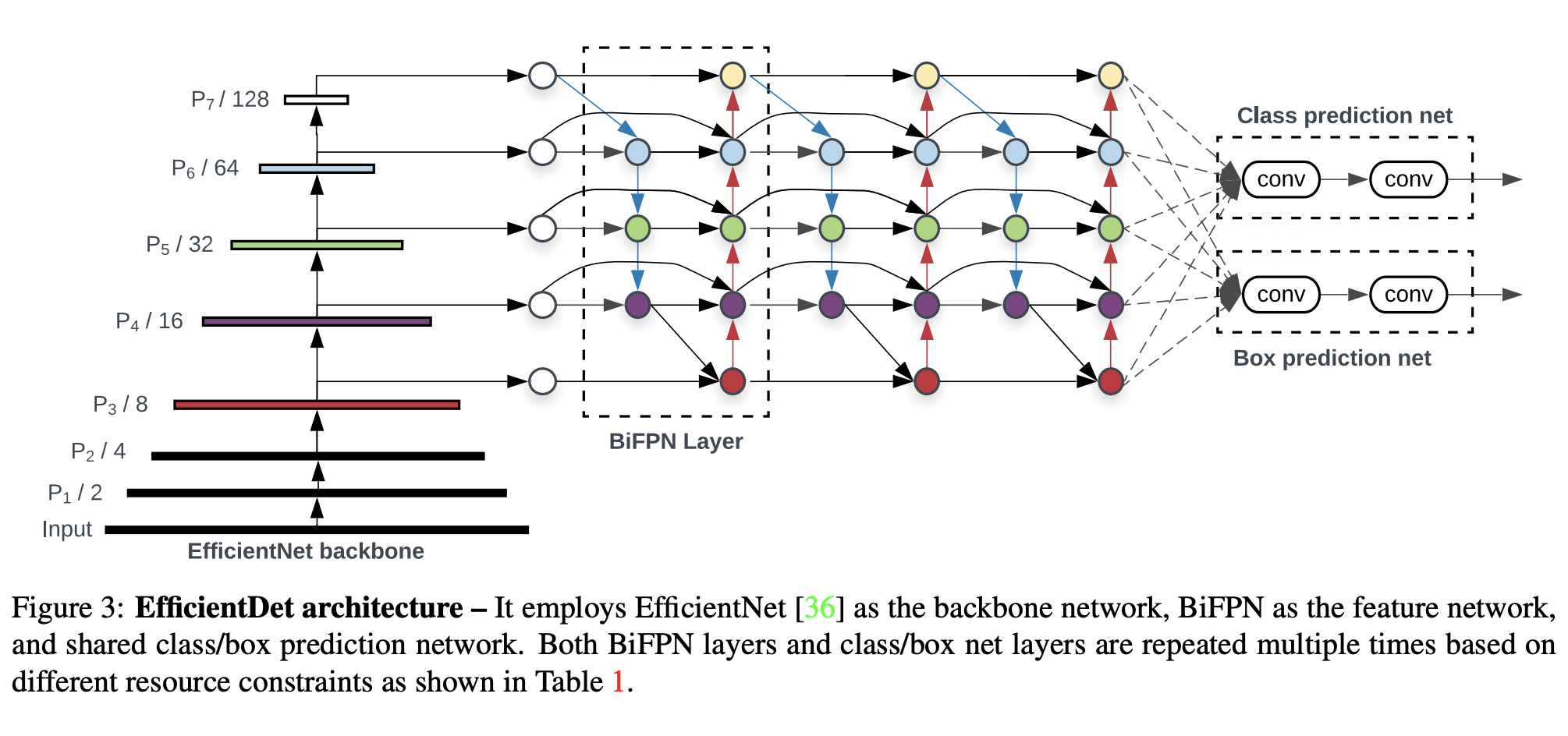
Backbone: EfficientNet을 썼음. Neck: BiFPN 채택함.
3.[python] Selective Search

Selective Search module 구현 selectivesearch 모듈을 임포트한다. 파라미터 img_rgb: 대상이되는 이미지들을 넣는다. scale: scale이 클수록 큰 object위주로 알고리즘이 실행된다. 반대로 작을수록 작은 object위주로 알고리즘이 실행된다. min_size: object 추천 최소사이즈. 위 코드에서는 20...
4.[ViT] Vision Transformer Quick Guide
유튜브 Vision Transformer Quick Guide Video Vision Transformer는 이미지 데이터를 위한 Transformer의 확장으로, 주로 인코더 부분을 사용하며, 디코더 부분은 순차적 생성에 사용된다. 입력을 숫자 벡터 또는 임베딩으로 변환해 입력 데이터를 벡터 공간에 투영시킨다. 이미지를 시퀀스로 변환하여 입력 임베딩을 만...
5.[CLIP] CLIP CODE review: Preparation
paper link previous review 논문을 읽다가 48페이지의 분량에 압도당한 boyamie.. 논문의 중요한 부분..만 읽고 코드를 먼저 보는 우회로에 들어서게 되는데.. CLIP 모델을 다운로드하고 실행하기 위해 필요한 패키지들을 설치한다. GPU 런타임을 사용하는 것을 전제로 하고 있다. 1. GPU 런타임 설정 Hardware acc...
6.[CLIP] CLIP CODE review 2
Loading the model CLIP 모델 나열 & 로드 clip 라이브러리를 임포트한다. >CLIP은 OpenAI에서 개발했다. 이미지와 텍스트를 함께 이해하는 모델이다. 사용 가능한 CLIP 모델 나열 clip.available_models()는 사용 가능한 CLIP 모델의 이름을 리스트로 반환한다. 반환된 모델 목록: 각 항목은 CLI...
7.[CLIP] CLIP CODE review 3
Building features 특징 추출 및 유사도 계산 이미지 집합 확인 np.stack(images): images 리스트를 쌓아서 4차원 배열을 만든다. print(f"dimension : {batch.ndim}, shape: {batch.shape}"): 배열의 차원 수와 형태를 출력한다. 텍스트 집합 확인 sentenc...
8.CV review
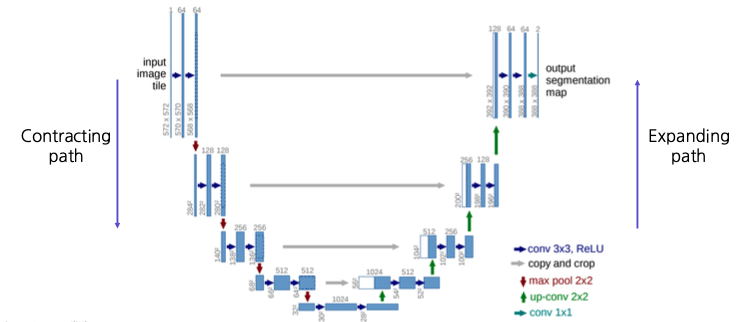
Fully Convolutional Networks (FCN) 공간정보가 유지되어있는 featuremap Fully Connected vs. Fully Convolutional 완전 연결층(Fully Connected Layer)은 고정된 차원의 벡터를 출력하
9.Computational Image
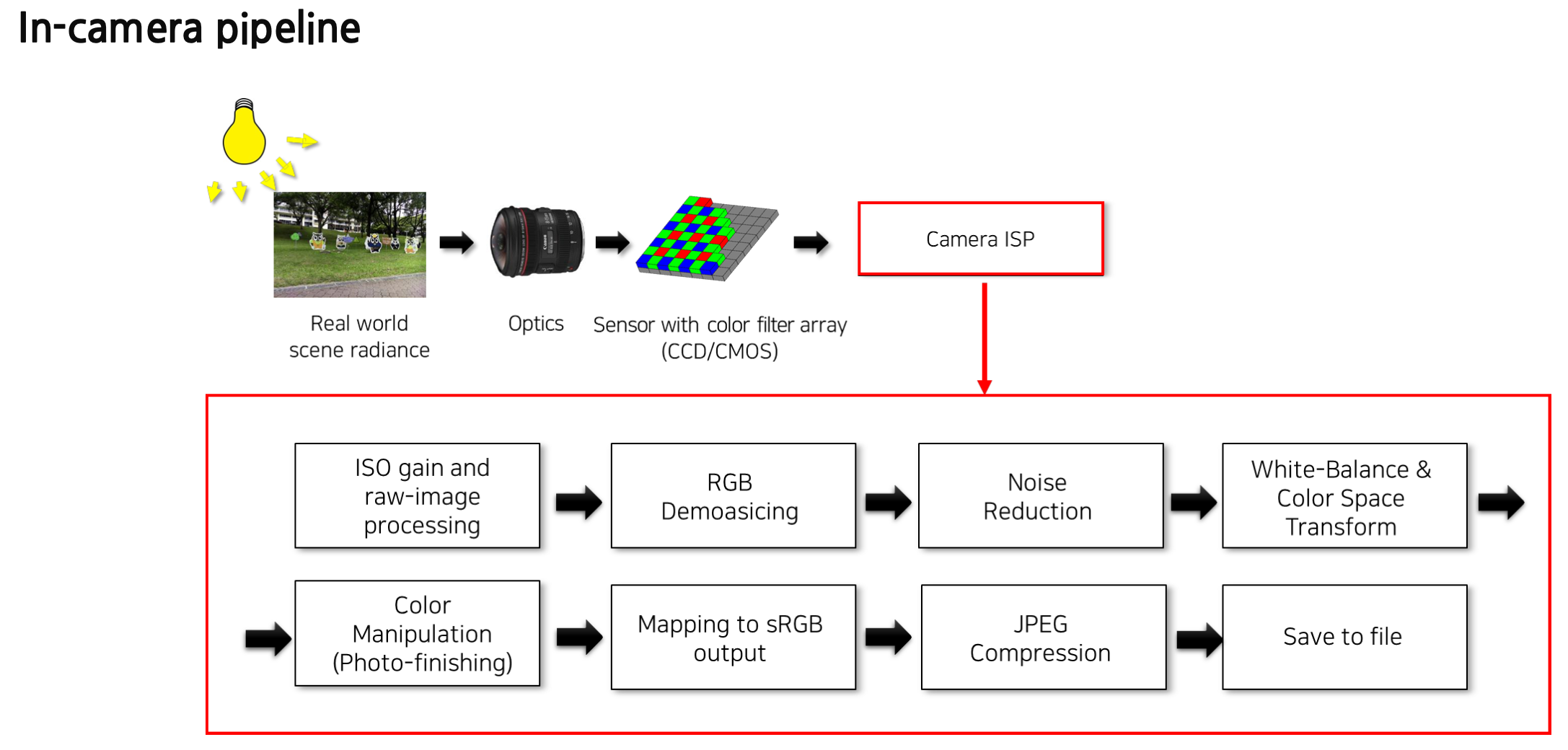
Deep learning based computational imaging
10.CV trend ; master class
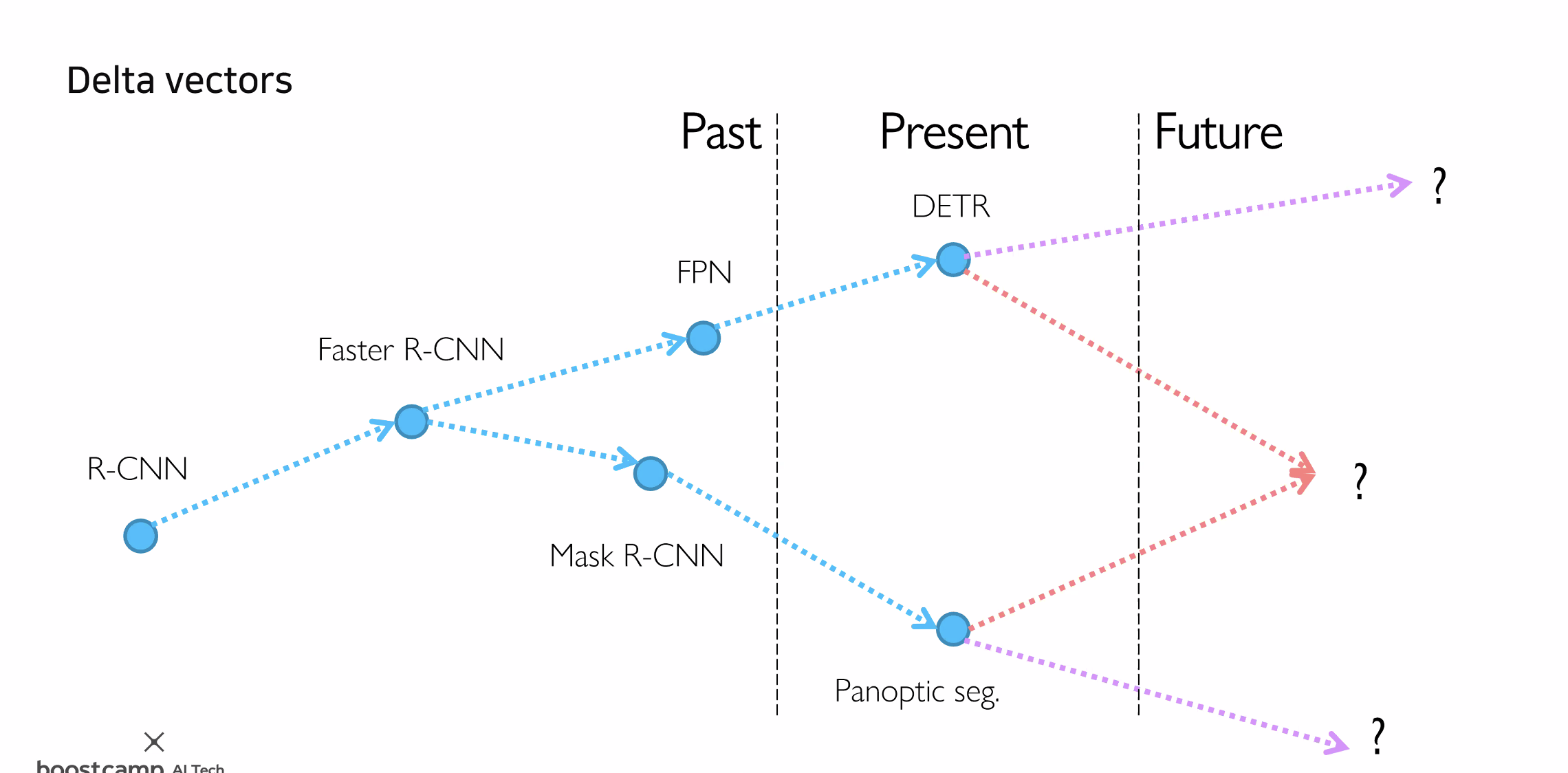
Detection (예시) 역사적으로 step by step 으로 개발됨 배웠던 서로 다른 개념을 합치면 어떻게될지 고찰해보기 내가 봐야하는 논문 선정법 아카이브에 매일 논문들이 쏟아지는데 다 볼순 없음 Related work에서 타고올라가며 과거에 중요한 몇개
11.3D
3D상에선 같은 점 교점이 projection point직선의 교점으로 대응할 수 있는 기법 : tringulation input image와 비교하며 super rendering 12.2 선형 삼각측량 방법 이 섹션에서는 간단한 선형 삼각측량 방법을 설명합니다. 일반적으로 추정된 점은 기하학적 관계를 정확히 만족하지 않으며, 이는 최적 추정치가 아닙...