- 유튜브
Vision Transformer Quick Guide Video
Vision Transformer는 이미지 데이터를 위한 Transformer의 확장으로, 주로 인코더 부분을 사용하며, 디코더 부분은 순차적 생성에 사용된다.
입력을 숫자 벡터 또는 임베딩으로 변환해 입력 데이터를 벡터 공간에 투영시킨다.
이미지를 시퀀스로 변환하여 입력 임베딩을 만들거나 패치로 변환하고 트랜스포머 블록에 통과시켜 최종적으로 이미지를 분류한다.
Vision Transformer는 CNN과 비교해 보다 유연하고 데이터가 풍부할 때 효과적이다. - 이론과 코드에 대한 설명이 더 자세한 논문
Do Vision Transformers See Like Convolutional Neural Networks?
- ViT가 소개된 논문
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Multi-head Self-attention Model 구현
1) Self-attention:
2) Multi-head Self-attention의 개념
3) 알고리즘 구현
CustomMultiHeadAttention클래스를 정의
이 클래스는 MLP(Multi-Head Attention)를 구현한다. 이는 Transformer 모델의 핵심 구성 요소 중 하나로, 다양한 헤드로 정보를 나누어 병렬적으로 처리하는 방법을 제공한다.
클래스 초기화 (__init__ 메서드)
def __init__(self, num_heads, model_dim):
super().__init__()
self.num_heads = num_heads
self.head_dim = model_dim // num_heads
self.all_heads_dim = self.head_dim * num_heads
self.query_proj = nn.Linear(model_dim, self.all_heads_dim)
self.key_proj = nn.Linear(model_dim, self.all_heads_dim)
self.value_proj = nn.Linear(model_dim, self.all_heads_dim)
# Output projection layer
self.out_proj = nn.Linear(self.all_heads_dim, model_dim)num_heads: 어텐션에서 몇 개의 헤드를 사용할지 정하는 변수이다.
보통 8 또는 16으로 설정된다.model_dim: 입력 벡터의 차원 수이다.
이 값은 모델의 전체 차원을 의미한다.head_dim: 각 헤드가 처리할 차원 수를 나타낸다.model_dim을num_heads로 나눈 값이다.query_proj,key_proj,value_proj: 각각 쿼리, 키, 값에 대해 선형 변환을 적용하는 레이어다. 이들은 입력 데이터를 각 헤드로 나누기 전에 변환하기 위해 사용된다.out_proj: 모든 헤드의 출력을 결합한 후, 다시 원래 모델 차원으로 투영하는 선형 변환 레이어이다.
split_heads 메서드
def split_heads(self, tensor):
batch_size, seq_len, _ = tensor.size()
tensor = tensor.view(batch_size, seq_len, self.num_heads, self.head_dim)
return tensor.permute(0, 2, 1, 3)- 이 메서드는 입력 텐서를 여러 헤드로 분리한다.
tensor.view(batch_size, seq_len, self.num_heads, self.head_dim): 입력 텐서를batch_size,seq_len,num_heads,head_dim의 형태로 변환한다. 각 헤드가 처리할 차원으로 나누는 것이다.tensor.permute(0, 2, 1, 3): 텐서의 차원을 재배열하여 헤드를 첫 번째 차원으로 이동시킨다. 배열은 이후 행렬 연산을 효율적으로 수행하기 위함이다.
forward 메서드
def forward(self, x):
Q = self.split_heads(self.query_proj(x))
K = self.split_heads(self.key_proj(x))
V = self.split_heads(self.value_proj(x))
attn_weights = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(self.head_dim)
attn_weights = nn.Softmax(dim=-1)(attn_weights)
attn_output = torch.matmul(attn_weights, V)
# Concatenate all heads
attn_output = attn_output.permute(0, 2, 1, 3).contiguous()
concat_output = attn_output.view(attn_output.size(0), attn_output.size(1), -1)
final_output = self.out_proj(concat_output)
return final_output-
쿼리(Q), 키(K), 값(V) 계산
Q = self.split_heads(self.query_proj(x))K = self.split_heads(self.key_proj(x))V = self.split_heads(self.value_proj(x))- 입력
x에 대해 각각의 선형 변환(query_proj,key_proj,value_proj)을 통해 쿼리, 키, 값을 계산한다. 그런 다음,split_heads메서드를 통해 각 텐서를 여러 헤드로 분리한다.
-
어텐션 가중치 계산
attn_weights = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(self.head_dim)- 쿼리 Q와 키 K의 내적(dot product)을 통해 어텐션 가중치(스코어)를 계산합니다. 이때, 내적 결과는
head_dim의 제곱근으로 나누어 스케일링합니다. 이는 수치 안정성을 높이기 위한 방법이다. attn_weights = nn.Softmax(dim=-1)(attn_weights)- 소프트맥스 함수를 적용하여 어텐션 가중치를 확률로 변환한다. 각 가중치는 0과 1 사이의 값이 되며, 합은 1이 된다.
-
어텐션 출력 계산
attn_output = torch.matmul(attn_weights, V)- 계산된 어텐션 가중치와 값 V의 곱을 통해 어텐션 출력을 계산한다. 이는 각 헤드에 대한 출력이다.
-
헤드 결합 및 최종 출력 계산:
attn_output = attn_output.permute(0, 2, 1, 3).contiguous()concat_output = attn_output.view(attn_output.size(0), attn_output.size(1), -1)- 여러 헤드의 출력을 하나의 텐서로 결합하기 위해 차원을 다시 정렬하고, 이어서
view메서드를 사용하여 원래의 형태로 재배열한다. final_output = self.out_proj(concat_output)- 결합된 출력을 다시 원래 모델 차원으로 변환하여 최종 출력을 생성한다.
알고리즘
- 쿼리, 키, 값 계산: 입력 데이터를 쿼리(Q), 키(K), 값(V)로 변환한다.
- 헤드 분할: Q, K, V를 다중 헤드로 분리한다.
- 어텐션 가중치 계산: Q와 K를 내적하여 어텐션 가중치를 계산하고, 소프트맥스 함수를 통해 확률 분포로 변환한다.
- 어텐션 출력 계산: 가중치와 V를 곱하여 각 헤드의 어텐션 출력을 생성한다.
- 헤드 결합: 각 헤드의 출력을 결합하여 하나의 텐서로 만들고, 최종 선형 변환을 통해 모델 차원으로 복원한다.
Vision Transformer의 임베딩
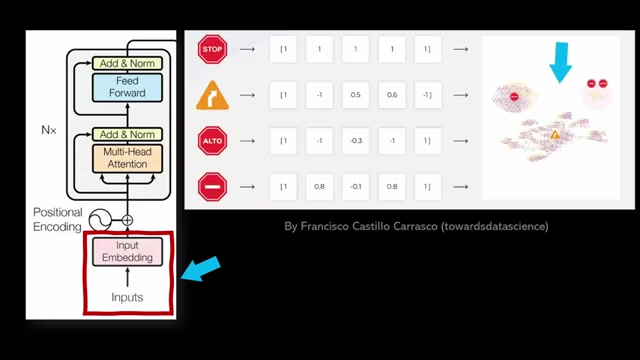
Classic Transformer의 임베딩 공간에서, 이미지 입력은 이미지 패치를 활용해 표현된다.
Vision Transformer에서, 이미지는 시퀀스로 변환되어 처리된다.
예를 들어 16x16 픽셀 타일로 이미지를 분할하고 각 패치를 Transformer 인코더의 첫 번째 구성 요소를 통과시켜 임베딩을 얻는다.
인코더 블록은 이러한 임베딩을 생성하는데 사용되며, 실제로는 완전히 연결된 신경망이다.
이 과정은 각 색상값이 뉴런에 입력되고 몇 개의 선형 계층을 통해 처리되어 임베딩이 생성된다.
시각 트랜스포머 구현,이미지 patching

이미지 입력은 RGB 컬러 채널과 너비, 높이, 그리고 배치 차원을 가질 수 있다.
이미지를 패치 크기에 맞게 재배치하여 트랜스포머 입력으로 사용하는 방법은 inops를 활용한다.
이를 통해 다차원 배열과 텐서를 다양한 방식으로 재배열할 수 있다.
최종 재배치 형태는 FC 레이어를 사용할 때와 Conv 레이어를 사용할 때에 따라 다르며, 이는 각 패치의 크기에 따라 달라진다.
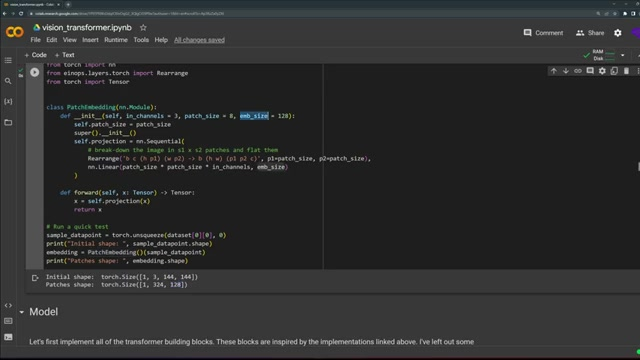
ViT component & patch 임베딩
여기서 사용한 옥스포드 애완동물 데이터셋은 총 37개 클래스의 다양한 애완동물로 구성되어 있고 데이터포인트가 적은 편이다.
패치 임베딩이라는 PyTorch 모듈을 정의하여 이미지를 동일한 크기로 변환한 다음 텐서로 변환한다.
이를 통해 144x144 크기의 이미지가 324개의 패치로 변환되고, 각 패치는 128 차원의 임베딩 크기를 갖게 된다.
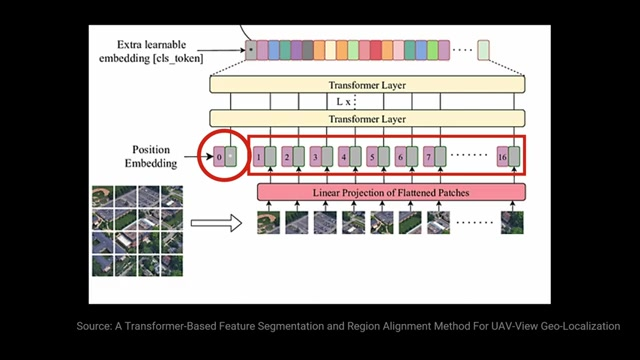
CLS 토큰
CLS 토큰은 네트워크의 마지막에 위치한다.
모든 정보를 하나의 표현으로 모아 분류에 사용하는 중요한 요소다.
트랜스포머 모델은 시퀀스를 시퀀스로 변환하는 모델이기 때문에 여러 출력이 나온다.
CLS 토큰을 통해 이를 하나의 전역 표현으로 얻는다.
CLS 토큰은 모든 패치 이미지에서 나오는 벡터들과 함께 사용되며, 모든 다른 입력에서 모은 정보로 후에 채워지는 더미 입력으로 볼 수 있다.
ViT의 위치 임베딩
임의의 값으로 초기화된 후 조정되며, 학습 가능한 벡터로 활용되어 전체 이미지를 대표하는 전역 특징 추출기(global feature extractor)역할을 한다.
각 입력 이미지에는 위치 임베딩이 추가되며, 비전 트랜스포머도 위치 임베딩을 활용한다.
트랜스포머의 attention은 위치에 독립적이므로, 각 패치의 원본 이미지 내 위치를 모델에 이해시킨다.
위치 임베딩은 벡터로 구성되어 있으며, 입력 사이의 거리가 다른 길이에 대해 일관된 거리를 유지한다.
이러한 벡터는 sin, cos 함수의 혼합으로 구성되어 입력 사이의 거리가 더 일관되게 유지되게한다.
숫자가 아닌 벡터를 사용하는 이유는 너무 커질 수 있는 숫자의 비효율성과 훈련 세트에서 매우 큰 숫자가 드물어 이 위치 정보를 학습하기 어렵기 때문이다.
ViT 구성 요소 & 구현 방법
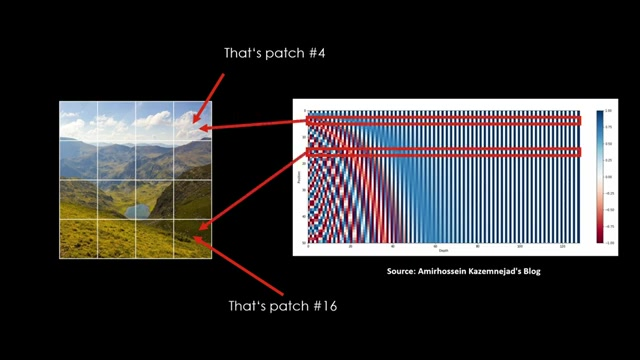
비전 트랜스포머에서는 여러 입력(queries, keys, values) 사이의 정보 공유를 허용하는 Multi-head attention 블록이 구현된다.
입력에는 위치 임베딩이 포함되며, 각 임베딩 벡터가 연결되는 것이 아니라 각각의 위치 임베딩은 단독 학습 가능한 파라미터 벡터이다.
ViT의 마지막 구성 요소는 실제 트랜스포머 인코더로, 다수의 멀티헤드 어텐션 블록, 정규화, 피드 포워드 네트워크, 잔여 연결이 필요하다.
멀티헤드 어텐션은 트랜스포머의 스케일 닷 프로덕트 어텐션 메커니즘이며, 키, 쿼리, 밸류로 구성된 세 가지 입력 간의 정보 공유를 가능하게 한다.
Transformer의 레이어 정규화 및 Norm 선택
Transformer의 정규화 블록은 레이어 정규화다.
레이어 정규화는 각각의 샘플에 대해 레이어의 모든 입력을 정규화한다.
Transformer는 순차열에 최적화되어 있는데, 이에 맞게 일반적으로 사용되는 배치 정규화가 아닌 레이어 정규화를 사용한다.
정규화에는 사전 정규화(prenorm)를 사용하는데, 이는 어떤 함수를 취한 후에 Slayer Norm을 적용하는 모듈이다.
이 블록은 간단히 함수를 정규화하여 함수를 적용하기 전에 정규화가 적용되도록 한다.
여기서 선형 레이어는 어텐션 가중 벡터를 입력으로 받아 다음 레이어나 출력을 위해 변환한다.
ViT의 구성과 기능
ViT에는 Linear Layer 두 개가 있으며 가우시안 화살표로 연결된 Linear Units인 활성 함수를 사용한다.
과적합을 피하기 위해 드롭아웃을 사용하고, Transformer 내에서 residual 또는 skip 연결이 사용되어 정보 흐름을 개선한다.
이런 연결은 정보 흐름을 개선하고 Vanishing gradients를 피하기 위해 사용된다.
다양한 컴포넌트들을 함께 블록화하여 비전 Transformer의 최종 버전을 얻을 수 있다.
이미지 처리를 위한 Transformer 블록
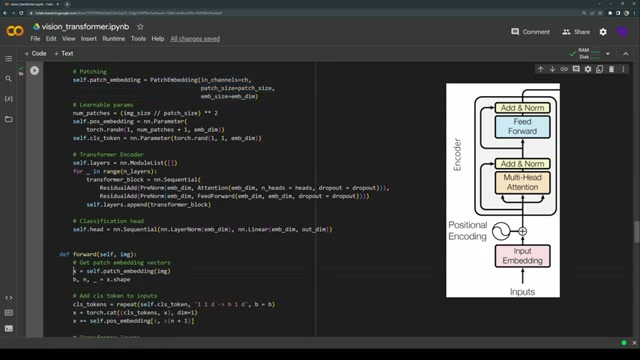
이미지를 입력으로 사용하며 위치 임베딩 및 글로벌 표현을 위한 CLS 토큰을 추가하여 각 배치에 포함한다.
CLS 토큰은 추가 토큰으로 각 배치에 반복적으로 사용되며 위치 임베딩은 각 배치 이미지의 각 토큰에 추가된다.
Transformer 레이어를 거치게 되는데, 멀티헤드 어텐션과 잔차, 포워드 블록이 사용되는 것으로 보여진다.
마지막으로 classification token을 통해 예측하고 출력된 차원은 클래스의 수와 같다.
Vision Transformer와 CNN의 차이
CNN은 변이에 강한 induction bias를 갖고 있어 이미지 상에서 학습 가능한 커널을 슬라이딩하는 것에서 나오는 반면, Vision Transformer는 Transformer 모델처럼 유연하며 강한 편향이 없다.
CNN은 데이터에 대한 강한 요구가 적고 Vision Transformer는 데이터의 기본 규칙을 모두 학습해야하는 경향이 있다.
'viewed 데이터가 있는 경우 CNN을 사용하고 수백만 장의 이미지에만 접근할 수 있는 경우 Vision Transformer를 사용해야 한다'
viewed 데이터가 있는 경우 CNN을 고수하고 그렇지 않으면 CNN이 더 나은 결과를 얻을 가능성이 높다.
ViT 장점

비전 트랜스포머는 점진적으로 커지는 수용 영역을 통해 계층적으로 학습한다.
이 모델은 이미지의 모든 구성 요소에 항상 액세스할 수 있어서 보다 전역적인 학습 방식을 갖는다.
비전 트랜스포머와 합성곱 신경망을 비교한 논문을 '디비전 트랜스포머'라고 한다.
비전 트랜스포머의 장점 중 하나는 해석 가능성이 내장되어 있다는 것이다.
주의를 집중시키는 '어텐션 맵'을 시각화할 수 있어서, 입력 영역에서 가장 큰 영향을 미치는 부분을 강조할 수 있다.
비전 트랜스포머 확장 및 모델

비전 트랜스포머의 확장으로 'swin Transformer'가 등장했다. 'shifted window'를 의미한다.
Swing Transformer의 주요 구성 요소는 계층적 표현을 만드는데 초점을 두며, 패치를 반복적으로 병합하여 네트워크를 깊게 만든다.
윈도우에 주로 적용되는 어텐션 메커니즘으로, 글로벌 어텐션보다 효율적이며, 시프트된 윈도우로 윈도우 간 정보를 학습할 수 있다.
지식 증류를 활용한 데이터 효율적 이미지 트랜스포머도 있으며, 학습된 개념을 학생에게 가르치는 또 다른 모델을 사용한다.
작은 데이터 세트에서의 예측 성능이 향상된다.
