머신러닝을 위한 매우 대양한 알고리즘과 개발을 위해 편리한 프레임워크와 API를 제공한다.
많은 환경에서 사용되는 성숙한 라이브러리이다. 주로 Numpy와 Scipy(science.확률,통계,과학적인 연산들)위에서 구축된 라이브러리이다.
머신러닝 용어정리
feature: 데이터 세트의 일반 속성이다. 머신러닝은 2차원 이상의 다차원 데이터에서도 많이 사용되므로 타겟값을 제외한 속성을 모두 feature로 지칭한다.
레이블, 클래스, 타겟값, 결정값: 다 같은말이다. 타겟값 또는 결정값은 지도 학습 시 데이터의 학습을 위해 주어지는 정답 데이터이다. 지도 학습 중 분류의 경우에는 이 결정값을 레이블 또는 클래스로 지칭한다.
data classification
머신러닝의 helloworld인 iris로 시작해보자!
iris dataset으로 예측 모델을 만들어 볼 것이다.
supervised learning
classification은 대표적인 supervised learning 방법의 하나이다. 지도학습은 학습을 위한 다양한 feature와 분류 결정값인 label데이터로 모델을 학습한 뒤, 별도의 test set에서 미지의 label을 예측한다.
학습세트: 학습을 위해 주어진 dataset
데이터세트: 머신러닝 모델의 예측 성능을 평가하기 위해 주어진 dataset
process
- 데이터 세트 분리: 데이터를 학습 데이터와 테스트 데이터로 분리한다.
- 모델 학습: 학습 데이터를 기반으로 머신러닝 알고리즘을 적용해 모델을 학습시킨다.
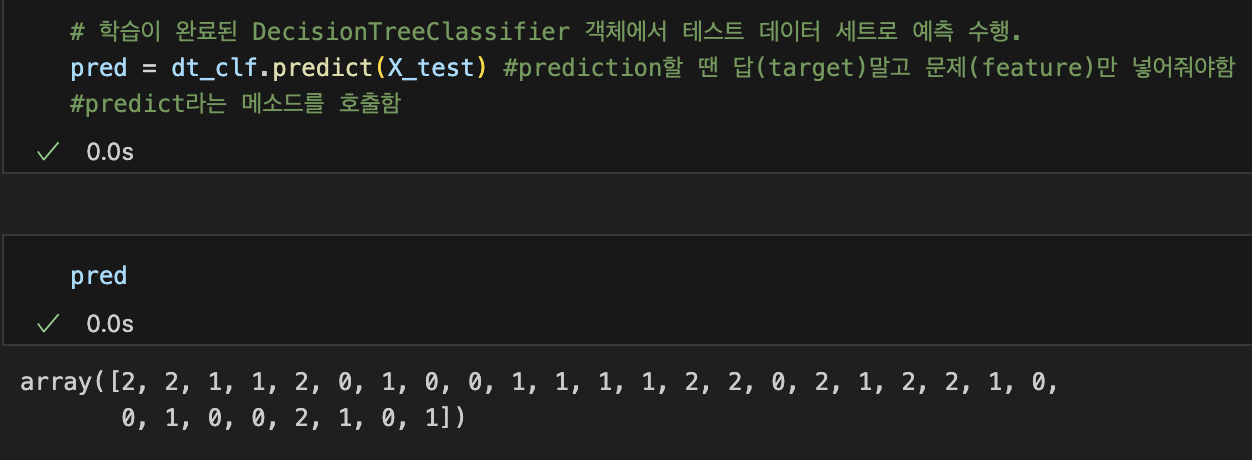
- 예측 수행: 학습된 머신러닝 모델을 이용해 테스트 데이터의 분류를 예측한다. 여기선 iris종류다.
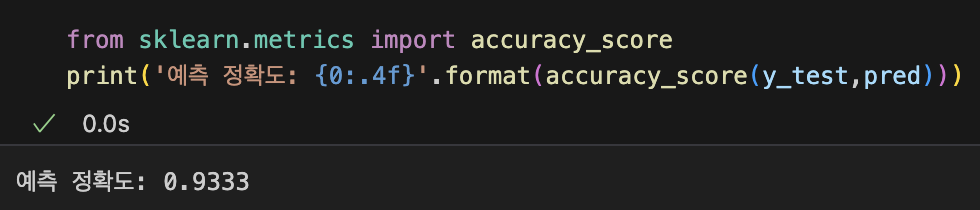
- 평가: 예측된 결과값과 테스트 데이터의 실제 결과값을 비교해서 머신러닝 모델의 성능을 평가한다.
model


desiontreeclassifier:사이킷런이 많은 머신러닝 알고리즘을 구현했는데 그중에서 결정트리분류모델을 구현한 클래스이다.
모듈명은 sklearn으로 시작을 한다.
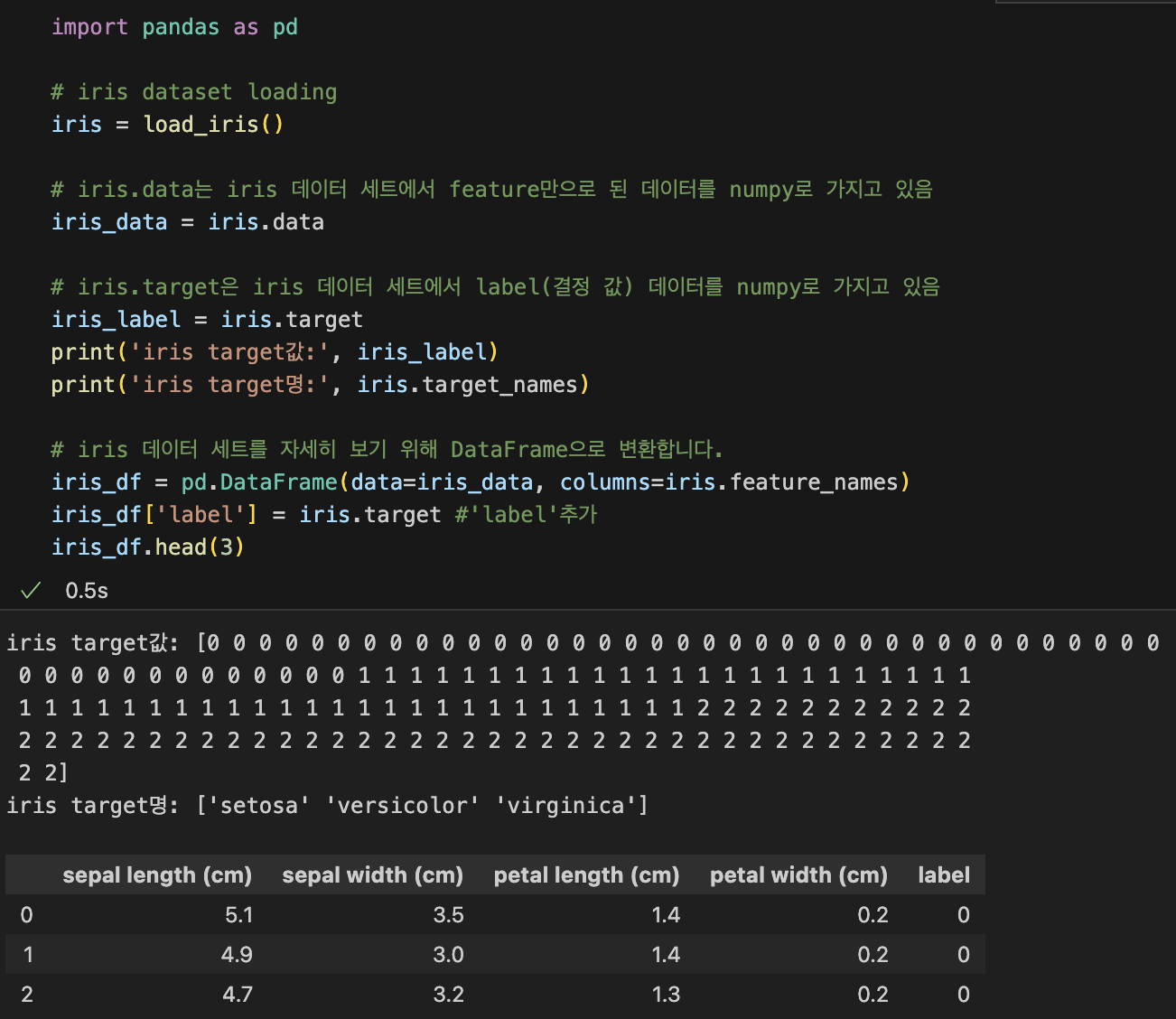
iris_data: feature dataset
feature_names:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
dataset loading
split(train,test)

test_size: 전체 data에서 test dataset크기를 얼마로 sampling할건지 결정한다. 디폴트값은 0.25다.
train_size: 전체 data에서 train dataset 크기를 얼마로 sampling할건지 결정한다. test_size parameter를 통상적으로 사용하기 때문에 train_size는 잘 사용되지 않는다.
shuffle: data를 분리하기 전에 미리 섞을지를 결정한다. 디폴트는 True이다.(데이터 분산)
random_state: 호출할 때마다 동일한 학습/테스트용 dataset를 생성하기 위해 주어지는 난수값이다. train_test_split()는 호출 시 무작위로 데이터를 분리한다. 따라서 random_state를 지정하지 않으면 수행할 때마다 다른 학습/테스트 용 데이터를 생성한다.
train dataset -> train

test dataset -> predict
accuracy