로컬 장비에서 돌릴 수 있는 LLM 중 최근 BitNet이 성능이 괜찮다고 들어 직접 사용해본 후기를 정리해봅니다. BitNet이 무엇인지에 대한 짧은 (사실 논문을 제대로 보진 않아서 짧을 수밖에 없는) 설명과 함께 매우매우 쉽지만 사용법까지 간략하게 정리해봅니다.
BitNet이란?
관련논문:
BitNet: Scaling 1-bit Transformers for Large Language Models
1-bit AI Infra: Part 1.1, Fast and Lossless
BitNet b1.58 Inference on CPUs
LLM을 조금이라도 더 적은 리소스로 빠르게 사용하고자 하는 접근은 다양하고, 그 중 하나는 양자화입니다. LLM 양자화란 모델의 파라미터를 낮은 비트 표현으로 변환하는 기술로, 32비트 부동소수점으로 표현되어 있는 파라미터를 16비트, 8비트 그리고 그 이하로 축소시켜서 모델 연산을 최적화하는 방법입니다. 이렇게 되었을 경우 메모리 사용량이 줄게 되어 모델을 메모리가 적은 환경에서도 구동할 수 있게 됩니다.
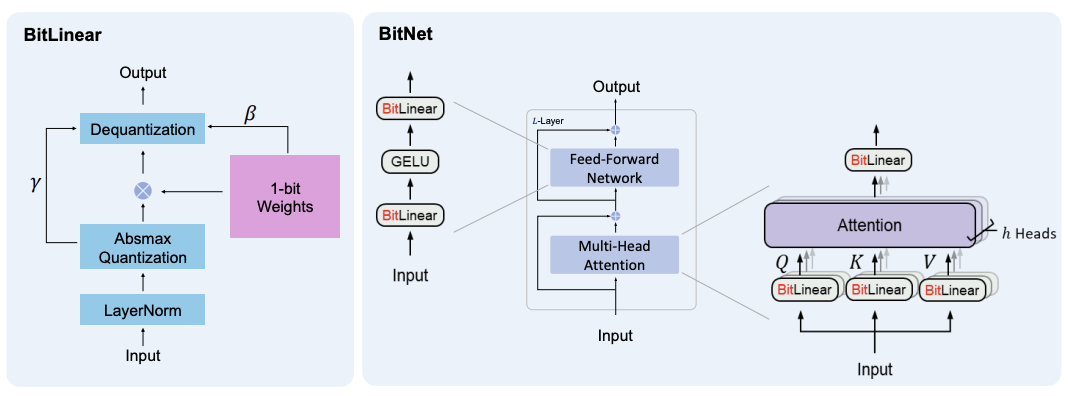
그 중 1비트 양자화는 가중치를 1비트(0 또는 1)로 표현하는 극단적인 방법입니다. 이를 제안한 모델이 BitNet인데, 간략하게만 설명드리면 일반적인 transformer 구조에서 BitLinear라는 이진화된 가중치를 사용하는 레이어를 사용합니다. 이 경우 일반적으로는 성능이 저하될 수밖에 없게 됩니다. 따라서 표현을 하나 더 늘려서 -1, 0, 1로 표현할 수 있도록 하는, 즉 log₂3 = 1.58 비트로 표현하게 하자는 방법이 1.58비트 양자화입니다.
1.58비트 양자화로 만들어진 BitNet, 즉 BitNet b1.58을 사용할 수 있는 소프트웨어 프레임워크 bitnet.cpp를 마이크로소프트에서 공개했습니다.
이제 이 BitNet을 사용하는 방법을 정리해보겠습니다.
BitNet 사용하기 (M1 기준)
사실 깃허브에 설명이 잘 나와있기도 하지만, 그럼에도 정리해봅니다.
맥os M1 환경에서 실행했는데, 동일한 Mac OS이거나 리눅스 기반이라면 동일할 거라고 봅니다.
BitNet 설치 및 모델 다운로드
깃허브에서 BitNet을 가져옵니다.
이 때 --recursive 옵션 주는 거 깜박하지 말아주세요...! (라고 그냥 클론한 멍청이가 말합니다)
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet깃허브 가이드에서도 conda 환경에서 진행하는 것을 추천하기에 저도 동일하게 먼저 conda activate 했습니다.
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpp그 다음 필요한 라이브러리들을 설치합니다.
pip install -r requirements.txt마지막으로 원하는 모델을 불러옵니다. 이 때 가이드에 나온 이 코드를 그대로 실행하면 모델은 models 폴더 안으로 다운받아집니다.
# HuggingFace에 있는 모델을 불러와 gguf 포맷으로 양자화시킨 뒤 빌드
python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s만약 다른 모델을 받고 싶거나, 직접 폴더를 지정해서 로드하고 싶다면 아래 코드를 참고하시면 됩니다.
huggingface-cli download HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens
python setup_env.py -md models/Llama3-8B-1.58-100B-tokens -q i2_s사용 가능한 모델은 github Readme에 나와 있습니다. 방금 받은 모델이 현재 시점에선 제일 큰 모델이네요.
여기까지 환경을 만드는 데 한 10분 정도로 오래 걸리지는 않았습니다.
BitNet 사용하기
사용법은 매우 쉽습니다. 원하는 질문을 넣은 상태에서 파라미터를 지정하고 run_inference.py를 실행하면 됩니다.
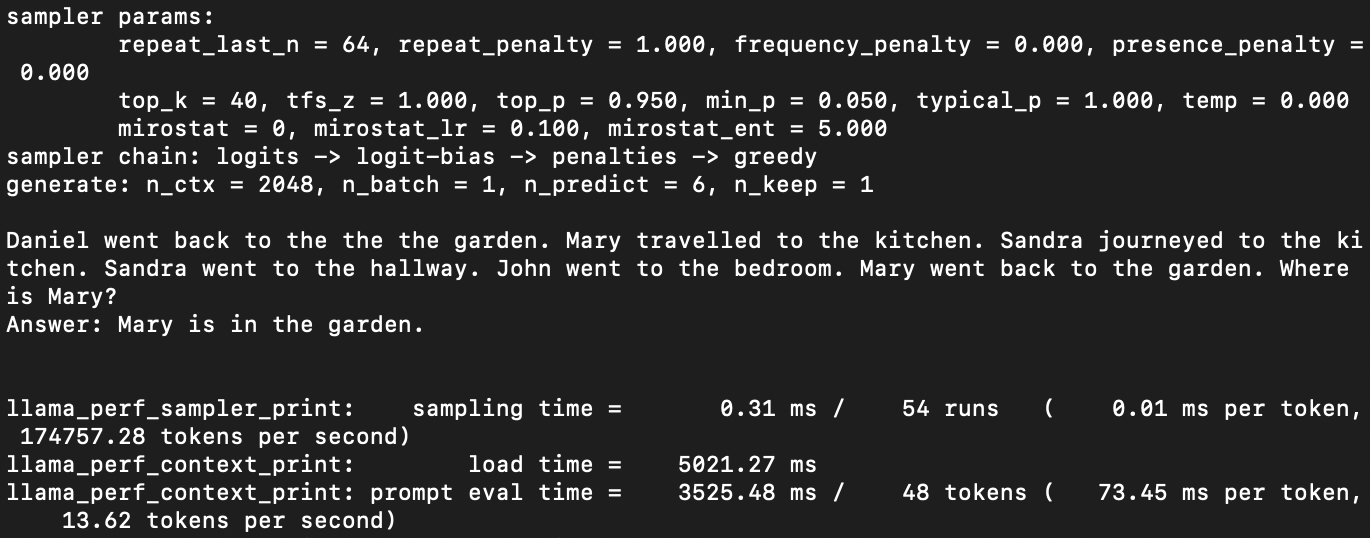
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?\nAnswer:" -n 6 -temp 0그럼 이것저것 로그가 뜨다가 원하는 답변을 모델이 뱉어냅니다.
궁금해서 다른 질문도 이것저것 해봤는데,
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Can you tell me about llm quantization?\nAnswer:" -n 6 -temp 0
기대했던 답변이 나오지는 않았네요...
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Do you know who is faster, rabbit or turtle?\nAnswer:" -n 6 -temp 0
어느 정도 context가 주어져있는 상황에서 더 잘 돌아가는 것 같습니다.
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Rabbit is faster than human, and turtle is slower than human. Who is faster, rabbit or turtle?\nAnswer:" -n 6 -temp 0
BitNet을 써본 결과
약 10분에서 20분 만에 테스트까지 해볼 수 있을 정도로 사용법은 매우 간단했습니다. 일단 로컬 노트북에서 8B 사이즈의 LLM이 이렇게 빠르게 돌아갈 수 있다는 게 가장 신기했습니다.
다만 아직 성능이 괜찮은가에 대해서는 의구심이 들긴 합니다. 질문만 보고 답을 유추할 수 있는 답변은 잘 하는데, 어느 정도의 배경지식으로부터 답을 가져와야 하는 질문에는 답을 못 하는 모습을 보여줬거든요. (토끼가 빨라 거북이가 빨라? -> 토끼는 거북이다...) 그럼에도 어느 정도 문장 생성 능력이 있다는 것은 확실하며, 보다 더 좋은 학습방법이나 적절한 모델이 나온다면 로컬PC로도 충분히 쓸 만한 LLM을 사용하는 날이 오지 않을까 기대해봅니다.
