이 글은 https://www.promptingguide.ai/ 에 나온 내용의 일부를 요약했습니다.
Large Language Model(LLM)으로부터 원하는 답변을 얻어내기 위한 질문을 prompt라고 합니다. ChatGPT와 같은 성능 좋은 LLM을 사용해보면 느끼겠지만, 모델 자체의 성능도 중요하지만 어떻게 질문을 하는지도 중요합니다. LLM 모델에게 어떻게 질문을 할까, 어떤 Prompt를 던질까를 고민하고 구성하는 과정이 필요합니다. 즉 Prompt Engineering은 LLM을 효율적으로 사용하기 위해 prompt를 발전시키고 최적화시키는 방법을 찾는 과정이라고 보면 될 것입니다. 이 글에서는 Prompt Engineering에 대한 설명과 함께 몇 가지 예시들을 소개하려고 합니다.
Prompt Engineering이란?
앞서 설명드렸듯이, Prompt Engineering은 LLM 모델에게 제공할 prompt를 구성하는 방법론입니다. 성능이 좋은 LLM일수록 어떤 prompt를 던지더라도 어느 정도는 좋은 결과를 줄 것이지만, Question Answering이나 수학 문제를 풀어달라는 등의 복잡한 테스크를 줄수록 LLM을 사용하는 것에 한계가 있을 것입니다. 따라서 복잡한 테스크에서 조금이라도 더 효율을 높이기 위해서는 좋은 prompt를 사용하는 것이 필요합니다. 또한 원하는 형태의 답변을 낼 수 있도록 유도함으로써 LLM의 답변을 이용하는 다른 툴에서도 효과적으로 LLM을 사용할 수 있게 할 수 있습니다.
Prompt를 LLM에 사용할 때 사전에 고려해야 할 정보들이 있습니다.
01. LLM 파라미터 설정
LLM을 사용할 때 조절할 수 있는 파라미터들이 몇 가지가 있습니다. 그 중 대표적인 파라미터 두 가지만 설명드리겠습니다.
Temperature
이 값이 낮을수록 모델은 토큰을 생성할 때 가능성이 높은 토큰만 선택하는 경향이 커집니다. 즉 이 값이 낮을수록 정형화된 답변을, 높을수록 새로운 답변을 만듭니다. 정확도가 높은 답변이 필요한 상황에서는 Temperature를 높여서 사용하고, 창의적인 답변이 필요한 상황에서는 높여서 사용하면 됩니다.
Top-P
Temperature와 유사합니다. 높을수록 다양한 답변을 내놓게 됩니다.
실제로 파라미터 조정을 할 때 Temperature와 Top-P는 유사한 역할을 하기 때문에 둘 중 하나만 조절하는 것이 권장된다고 합니다.
02. Prompt 분류
Prompt 사용 시 모델에게 예제를 주는지 아닌지에 따라서 크게 두 가지로 구분할 수 있습니다. 대표적으로 Zero-shot과 Few-shot이 있습니다.
Zero-shot prompting
모델에게 어떠한 예시나 구체적인 지시 없이 바로 질문을 하는 방법입니다. 성능이 좋은 GPT-3 이상의 최근 모델들은 이미 문맥을 이해하는 능력을 가지고 있기 때문에 사전에 어떤 예시를 주지 않고도 어느 정도는 질문에 대한 답을 할 수 있습니다. 따라서 Zero-shot을 했을 때 성능이 어느 정도까지 나오는지에 따라서 모델을 평가하기도 합니다. 하지만 테스크가 어려워서 전혀 예시를 주지 않은 상태에서 원하는 답변을 얻기가 어려운 경우 Few-shot을 통해 예시 몇 가지를 주어서 모델에게 원하는 답변을 얻을 수 있도록 유도해야 합니다.
Few-shot prompting
Zero-shot과 달리, 모델에게 질의-응답 쌍으로 구성되는 몇 가지 예시를 주는 방법입니다. 아래는 1-shot, 즉 예시 하나를 주는 few-shot 사례입니다.
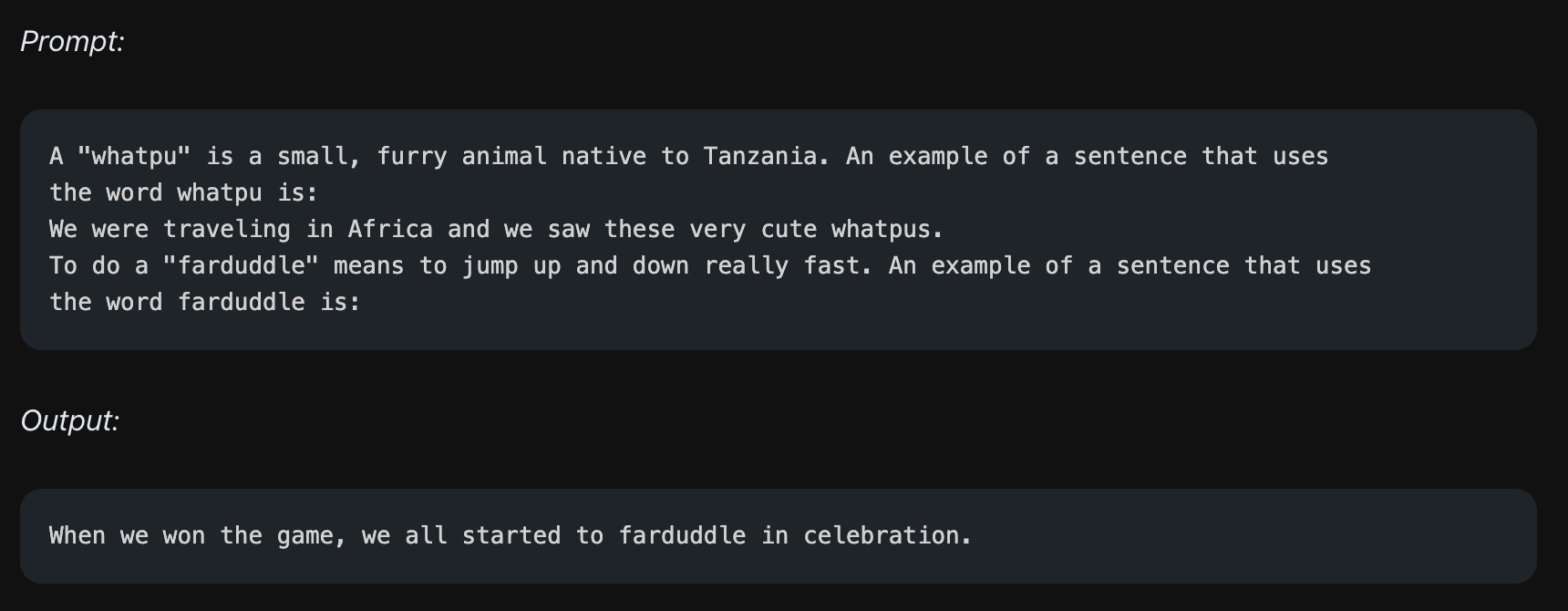
'"whatpu" is a small, ...'과 같은 문장이 주어졌을 때 'the word whatpu is:'라는 질문이 주어지면 'We were traveling in Africa and we saw these very cute whatpus.'라는 'whatpu'라는 단어를 포함하는 예시 문장을 만드는 예시를 하나 줍니다. 그리고 본격적으로 질문을 합니다. 'To do a "farduddle" means to...'라는 문장을 주고, 'the word farduddle is:'라는 질문을 합니다. 그러면 모델은 앞선 예시와 비슷하게 "farduddle"라는 단어를 포함하는 예시 문장을 만드는 테스크를 수행하게 됩니다. 즉 예시 하나를 힌트로 주어서 원하는 형태의 답변을 만드는 과정을 수행합니다.
위에서는 1-shot 예시를 주었지만, 모델이 허용하는 범위 내에서 여러 개의 예시를 주는 것도 가능합니다.
03. Prompt 사용예시
문서 요약 (Text Summarization)
문서로부터 빠르게 읽을 수 있는 쉬운 요약본을 만드는 작업입니다.
위의 예시에서 모델은 질문에 대한 답을 했으나, 글이 너무 길어 읽기 힘들 수 있습니다. 이 때 이를 요약해달라고 아래와 같이 다시 질문을 할 수 있습니다.

정보 추출 (Information Extraction)
 긴 본문이 있을 때, 우리는 document로부터 원하는 부분만 찾고 싶을 때가 있습니다. 그 때 본문과 함께 정보 추출을 해달라는 prompt를 모델에게 줄 수 있습니다. 위의 예시에서도 마찬가지로 본문과 함께 "Mention the large language model based product mentioned in the paragraph above"라는 질문을 합니다. 그러면 모델은 이에 대한 답을 하게 됩니다.
긴 본문이 있을 때, 우리는 document로부터 원하는 부분만 찾고 싶을 때가 있습니다. 그 때 본문과 함께 정보 추출을 해달라는 prompt를 모델에게 줄 수 있습니다. 위의 예시에서도 마찬가지로 본문과 함께 "Mention the large language model based product mentioned in the paragraph above"라는 질문을 합니다. 그러면 모델은 이에 대한 답을 하게 됩니다.
질의응답 (Question Answering)
 정보 추출과 비슷하게, Context를 제공한 상태에서 질문을 던지고 이에 대한 답을 할 수 있게 prompt를 구성할 수 있습니다.
정보 추출과 비슷하게, Context를 제공한 상태에서 질문을 던지고 이에 대한 답을 할 수 있게 prompt를 구성할 수 있습니다.
텍스트 분류 (Text Classification)
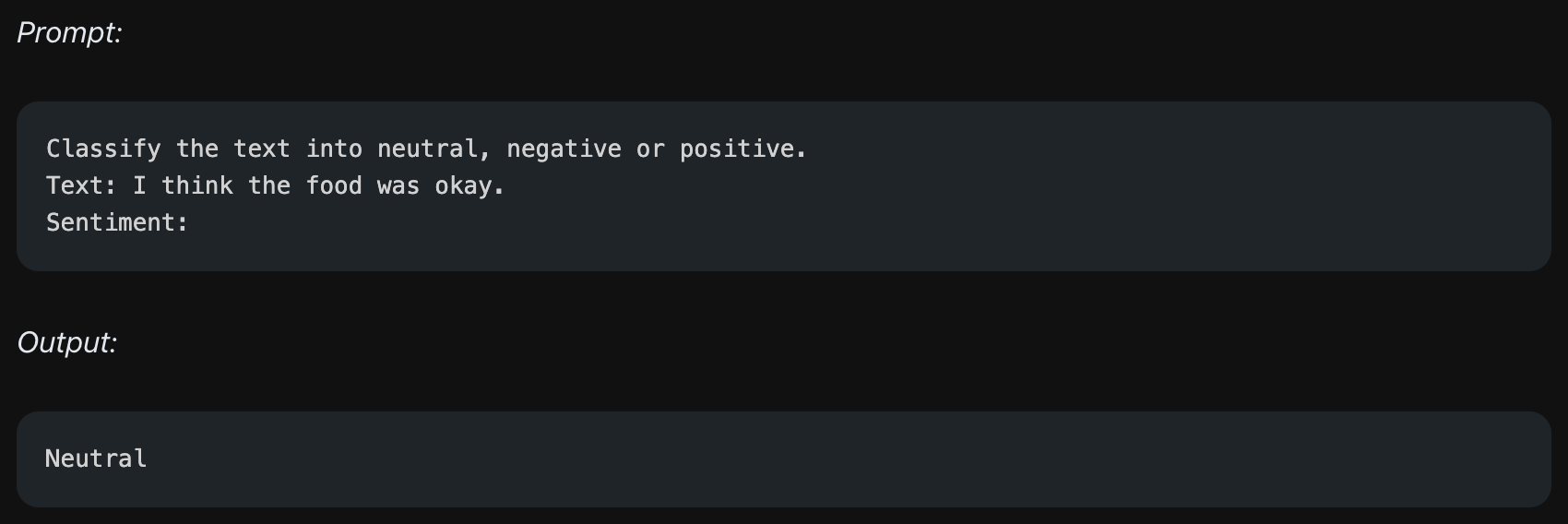 감성분석이 대표적인 예시이며, 텍스트에 대해 카테고리를 나누어 분류하는 테스크를 줄 수 있습니다.
감성분석이 대표적인 예시이며, 텍스트에 대해 카테고리를 나누어 분류하는 테스크를 줄 수 있습니다.
대화 (Conversation)
임의의 챗봇을 만들어 모델과 직접 대화할 수 있습니다. 이 때 챗봇의 역할을 지정해주면 다른 결과를 가져올 수도 있습니다.
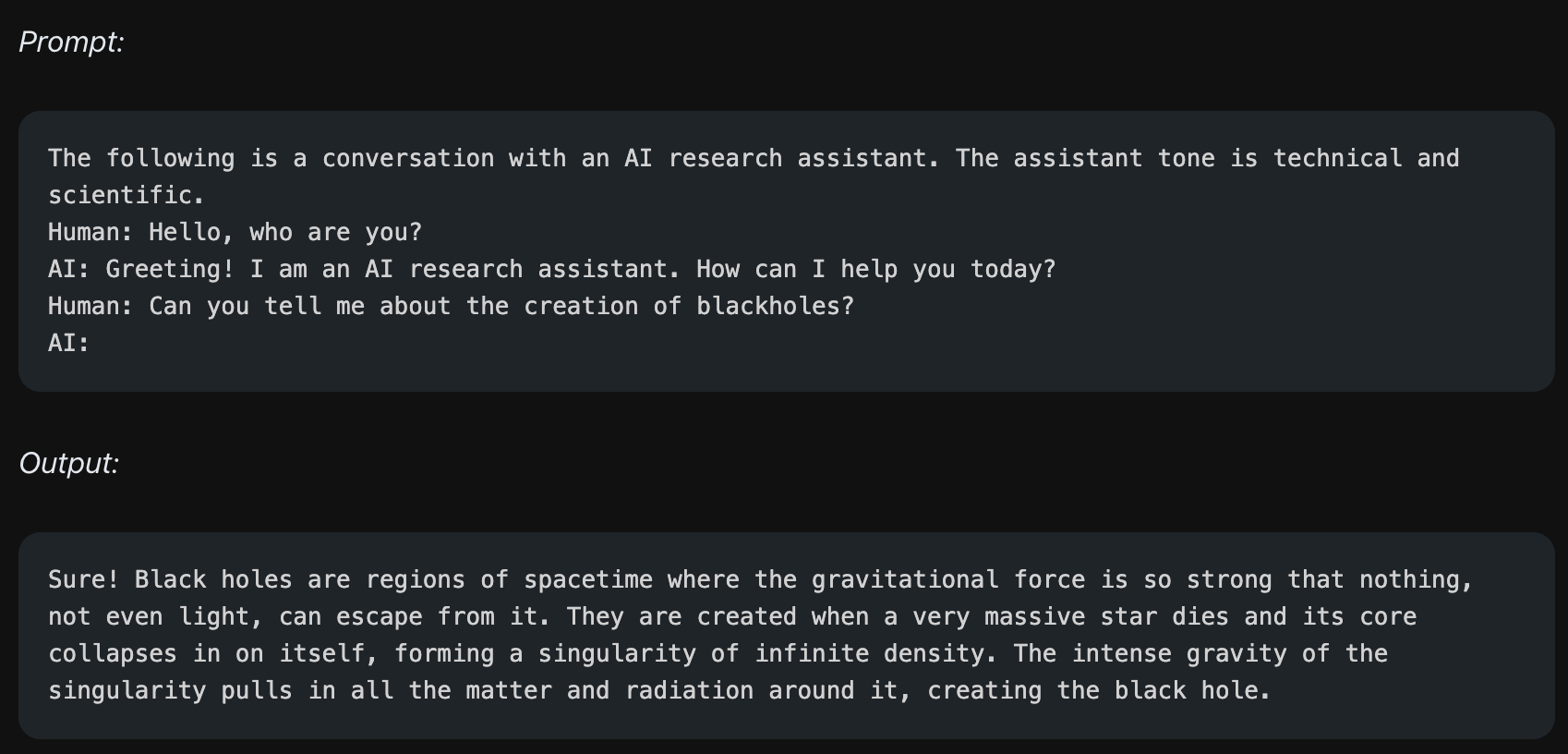
위의 예시는 모델에게 technical하고 scientific한 비서 역할을 하라고 지시합니다. 그러면 모델은 보다 전문적이고 기술적인 용어를 많이 사용하여 답변을 합니다.
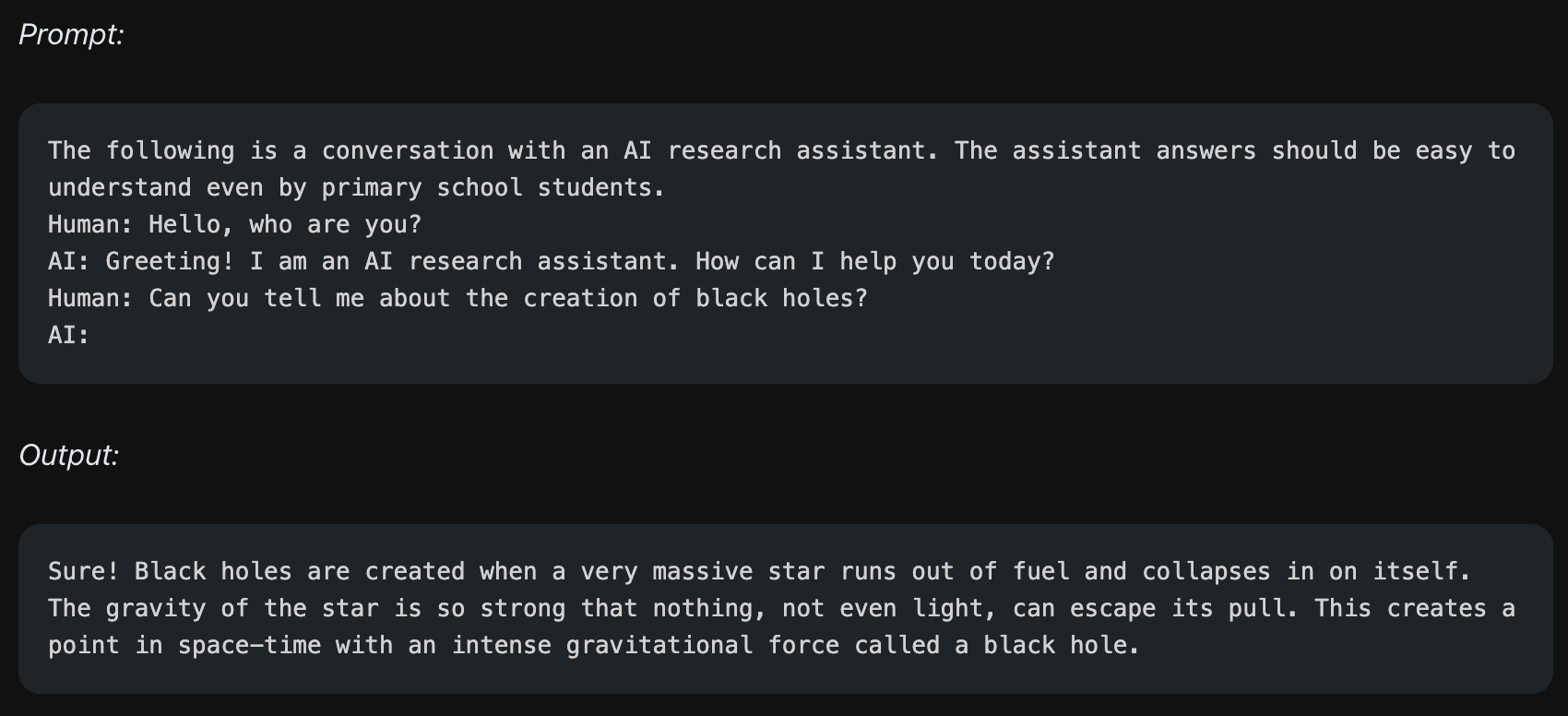
반대로 모델에게 "초등학생이 이해할 수 있는 수준"으로 답할 수 있는 비서 역할을 지시하면, 상대적으로 쉬운 어휘를 구사하는 것을 볼 수 있습니다.
코드 생성 (Code Generation)
최근 제가 GPT-4에게 많이 질문하는 부분인데, 원하는 코드를 생성하도록 지시할 수 있습니다.
Reasoning
LLM에게 추상적인 질문이 아닌, 수학 문제와 같이 정답이 정해져 있는 질문을 하는 경우도 있습니다. 이 때 어떤 조건 없이 답을 달라고 하면 모델은 틀린 답을 줄 확률이 높습니다.
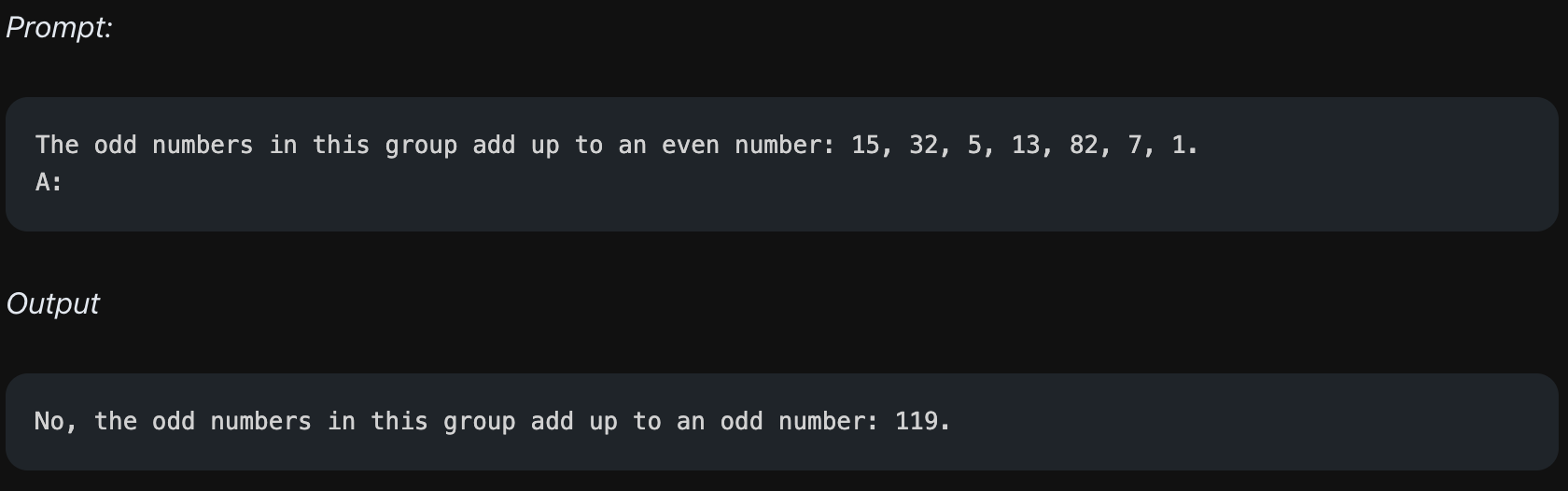
위에서 "홀수를 모두 더하면 짝수인지 판단하라"라는 문제를 줍니다. 위의 리스트의 홀수들을 모두 더하면 41이 나오며, 이는 홀수가 맞습니다. 하지만 모델의 output은 맞는 답을 주기는 했으나, 전혀 관계 없는 숫자인 119를 언급하며 추론에 실패하는 것을 볼 수 있습니다.
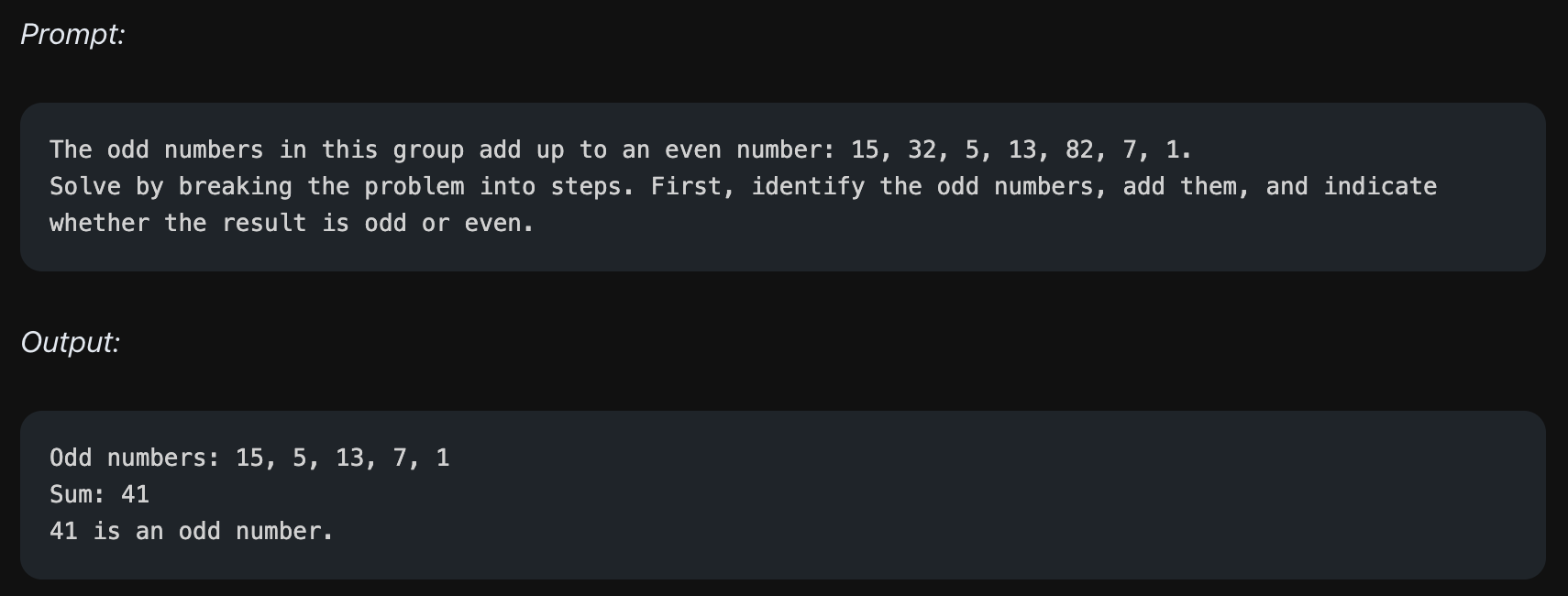
하지만 모델에게 위의 예제에서처럼 어떤 방식으로 단계적으로 문제를 풀지 미리 지시를 하는 prompt를 제공했을 경우, 단계적으로 옳은 답변을 추론해내는 것을 볼 수 있습니다.
이처럼 어떤 prompt를 사용하는지에 따라 같은 모델도 다양한 결과를 가져오게 됩니다. 즉 좋은 모델을 만드는 것도 중요하지만, 질문을 잘 던지는 것 역시 중요합니다.


제가 너무 원하던 정보에요~!! 감사합니다ㅎㅎ