이 글은 https://www.promptingguide.ai/ 에 나온 내용의 일부를 요약했습니다.
Large Language Model(LLM)을 효과적으로 활용하기 위해 다양한 prompt engineering 방법들이 제안되었습니다. 크게 두 가지로 나눈다면 예시를 주는 Few-Shot Prompting과 예시를 주지 않고 물어보는 Zero-Shot Prompting이 있겠지만, 어떻게 예시를 주고 어떻게 질문을 하는지에 따라서 LLM의 결과는 상당히 많이 달라지게 되며, 몇 가지 예시를 드리려고 합니다.
Zero-Shot & Few-Shot Prompting
Zero-Shot Prompting은 어떤 예시를 주지 않고 바로 질문을 주는 prompting 방법입니다. Zero-Shot 상황에서는 모델이 질문의 문맥을 이해하고 답을 해야 하기 때문에 Zero-Shot의 결과를 보고 모델의 성능을 판단하기도 합니다. 하지만 Zero-Shot이 가능한 모델이더라도 예시를 주어 문맥 정보를 더 줄수록 모델은 더 적절한 답을 줄 확률이 높아집니다. 따라서 보다 복잡한 테스크에서는 여전히 Few-Shot Prompting이 요구됩니다.
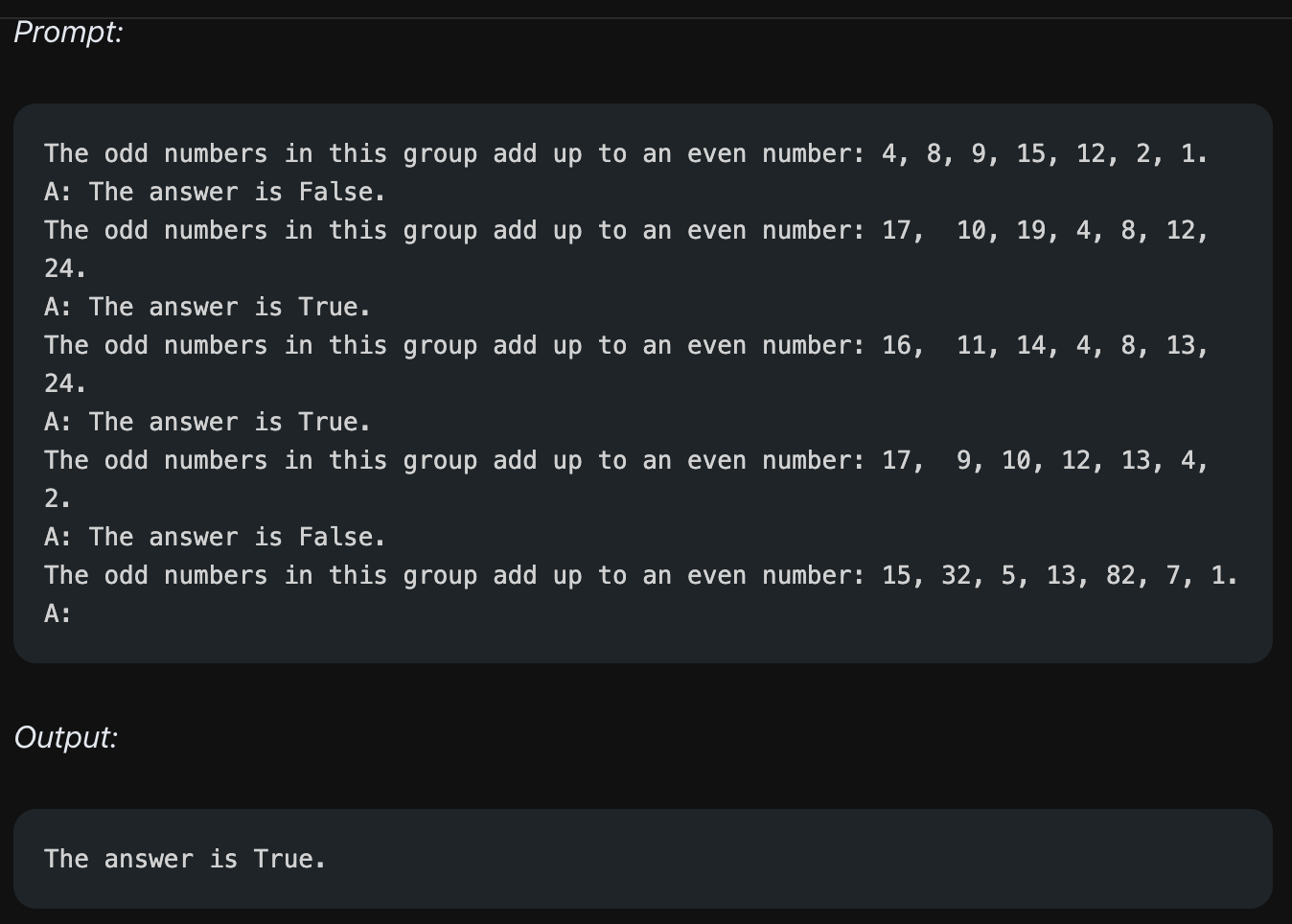
하지만 Few-Shot Prompting도 아무리 많은 예시를 주더라도 복잡한 테스크에서는 한계를 보이기도 합니다.
위의 예시는 숫자 리스트에 있는 홀수를 모두 더했을 때 짝수가 되는지 판단하는 문제이며, 모델은 True라는 틀린 답변을 줍니다. 예시에서처럼 추론 과정(홀수를 추려내고, 홀수들을 더하고, 합계가 짝수인지 판단)이 필요한 예시들을 줄 경우 모델은 틀린 답을 주기도 합니다. 즉 단순히 예시만 주는 Few-Shot Prompting도 한계가 있기 때문에 이어서 나올 Prompting 방법들이 제안됩니다.
Chain-of-Thought (CoT) Prompting
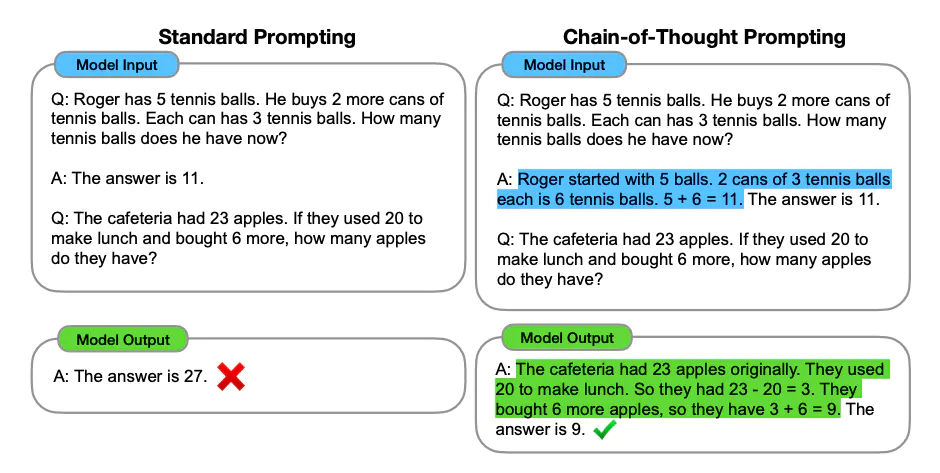
앞서 Few-Shot Prompting에서 별도의 추론 과정이 필요한 경우 아무리 많은 예시를 주더라도 모델은 옳지 못한 답을 줄 수도 있다고 했습니다. 이를 해결하기 위해 나온 방법이 Chain-of-Thought Prompting(CoT prompting)입니다. 위의 이미지에서처럼 예시에 Q(Question), A(Answer)가 있을 때, Answer로 단순히 답만 말하도록 하는 것이 아니라 몇 가지 추론 과정을 거쳐서 답을 내는 예시를 주는 것입니다.
홀수를 더했을 때 짝수인지 판단하라는 동일한 예시를 주었을 때, 이번에는 Answer에서 홀수를 선택하고, 이들을 더하고, 더했을 때 값이 무엇이며, 이것이 홀수인지 아닌지 판단하는 추론 과정을 줍니다. CoT prompt 예시를 준 결과 모델은 예시와 동일한 추론 과정을 거치게 되고, 정확한 답변을 주게 됩니다.
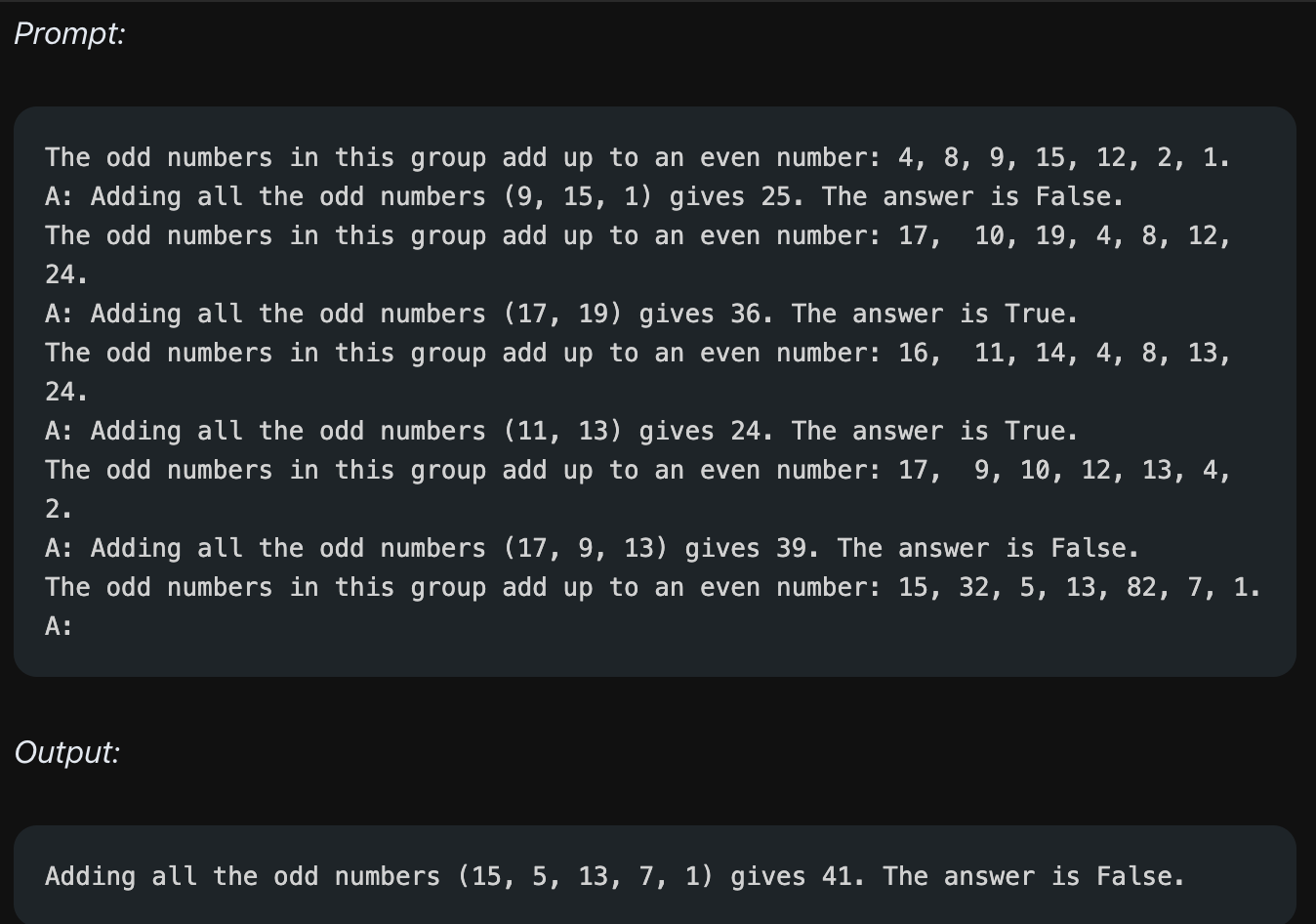

CoT는 Few-Shot Prompt 말고 Zero-Shot Prompting에서도 적용할 수 있습니다. 방법 자체는 단순합니다. "단계적으로 생각해보자(Let's think step by step)"라는 문장 하나만 추가하는 것입니다. 위의 이미지에서처럼 문장 하나를 추가했을 뿐인데 모델은 Zero-Shot 상황에서도 추론 과정을 거쳐서 올바른 답을 내는 것을 볼 수 있습니다.
Self-Consistency
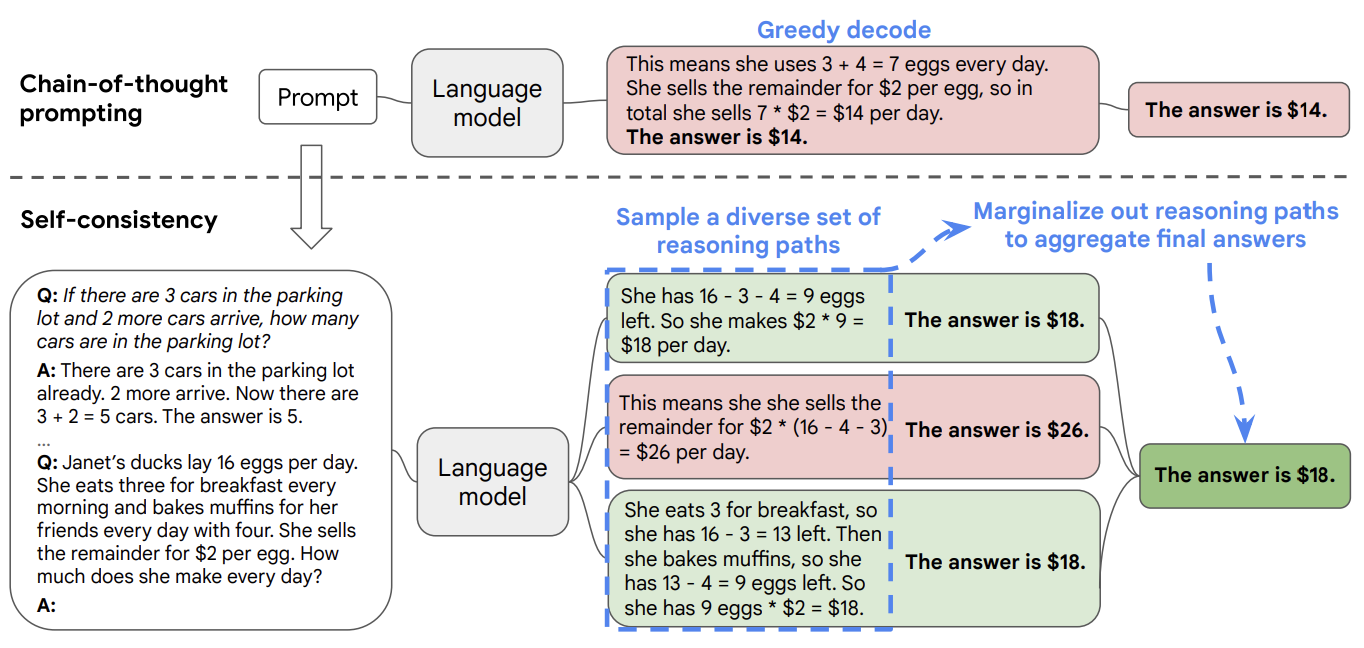
LLM에게 요청할 수 있는 테스크 중에는 예시로 많이 들었듯이 수학 문제를 푸는 것과 같이 정확한 답변을 요구하는 테스크들이 있습니다. 하지만 CoT prompting만으로도 모델이 틀린 답을 주는 경우도 있습니다. 이 때 신뢰도를 높이기 위한 방법이 Self-Consistency입니다. 방법은 아래와 같습니다.
- 동일한 Few-Shot CoT를 여러 번 수행한다.
- 모델이 낸 답변에서 추론 과정을 제외하고 답만 추려낸다.
- 가장 많이 등장한 답변을 채택한다.
Prompting을 여러 번 수행해서 보다 더 정확한 답을 얻으려는 방법이라고 볼 수 있습니다.
Generate Knowledge Prompting
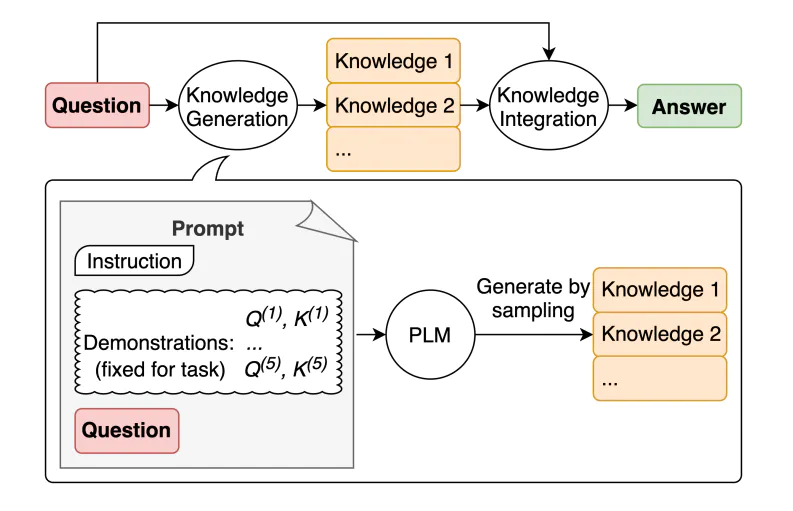
Generate Knowledge Prompting은 모델로부터 답을 얻어내기 전에 먼저 모델이 직접 관련 정보를 가져오도록 한 다음 이를 활용해서 답을 가져오도록 하는 prompting 방법입니다.
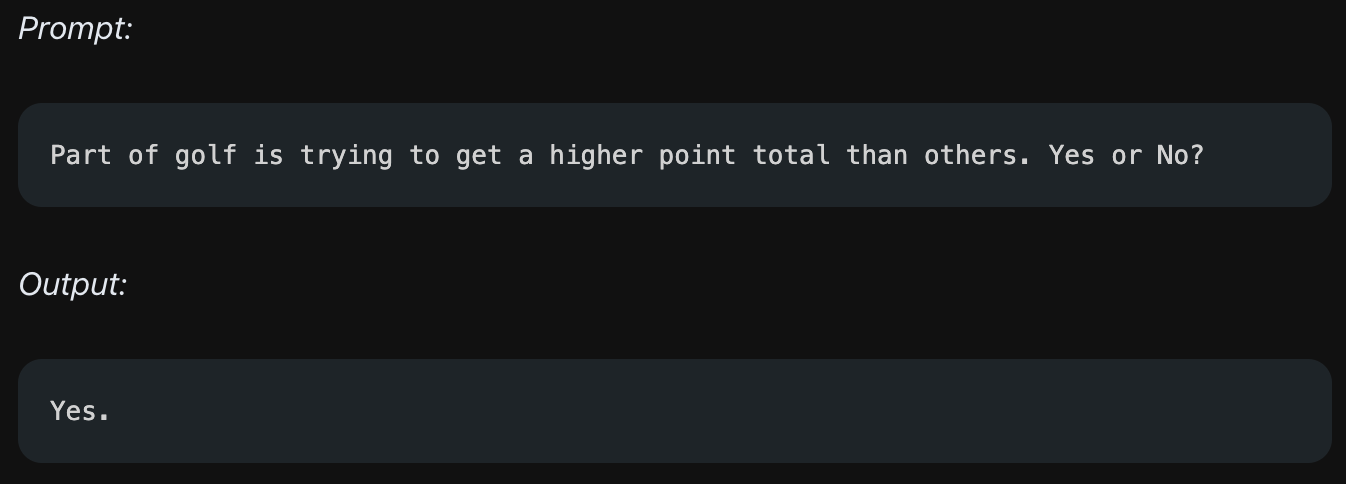
"골프는 점수를 더 많이 내는 사람이 이기는 게임이다"에 대해 맞는지 아닌지를 판단하는 예시가 있다고 합시다. 그냥 물어봤을 때 모델은 "맞다"라는 틀린 답변을 가져왔습니다. 이제 이것을 Generate Knowledge Prompting으로 개선해봅시다.
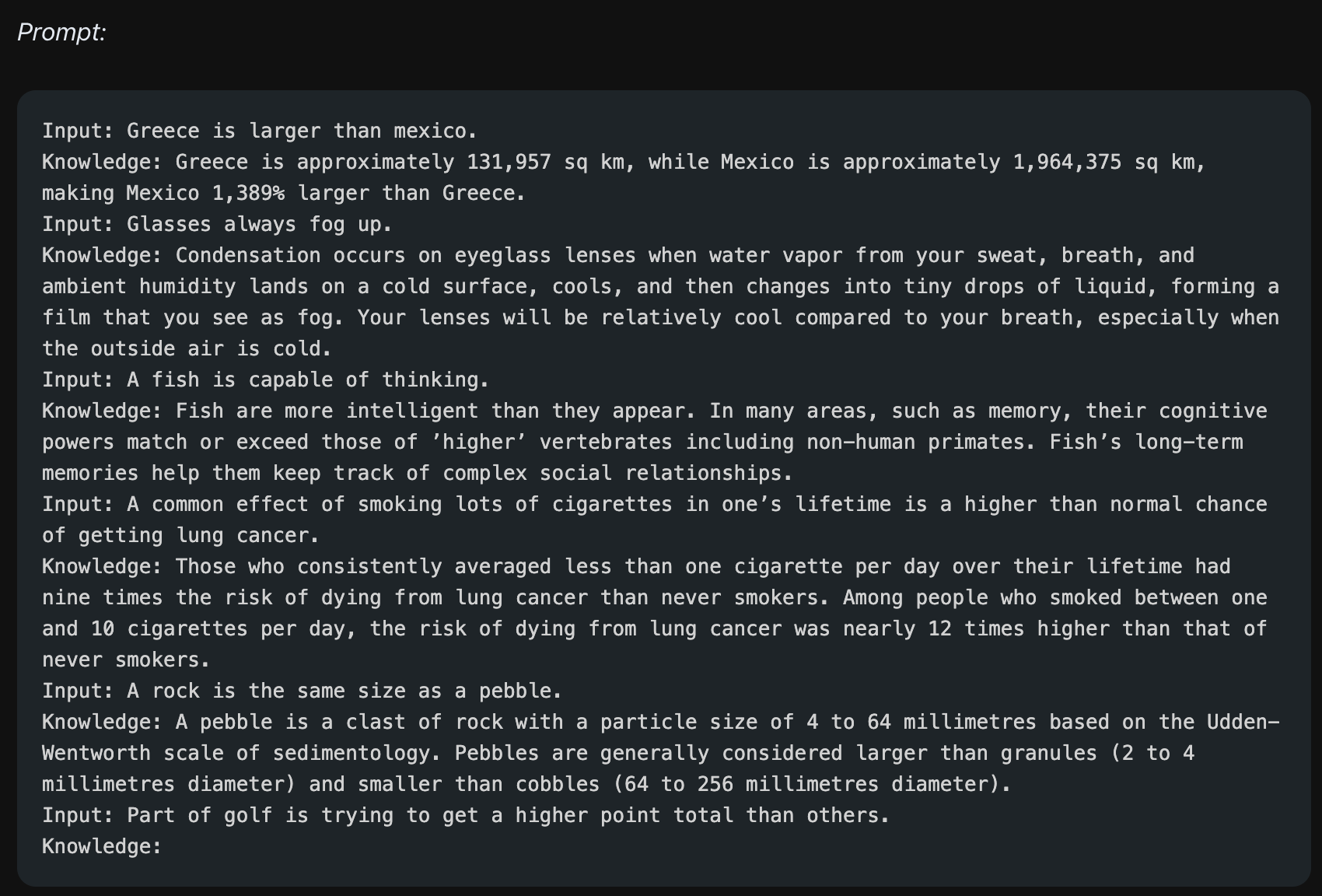
먼저 Few-Shot Prompting을 진행합니다. 이 때 "맞다, 아니다"라는 정답이 아닌 Knowledge, 즉 정보를 만드는 예시를 줍니다. 정답을 만드는 테스크를 준 것이기 때문에 모델은 골프의 점수 계산 방식과 관련된 정보를 답변으로 내놓게 됩니다. 여러 번 수행하면 서로 다른 답을 주겠지만, 모두 골프에 대한 정보를 가져옵니다.
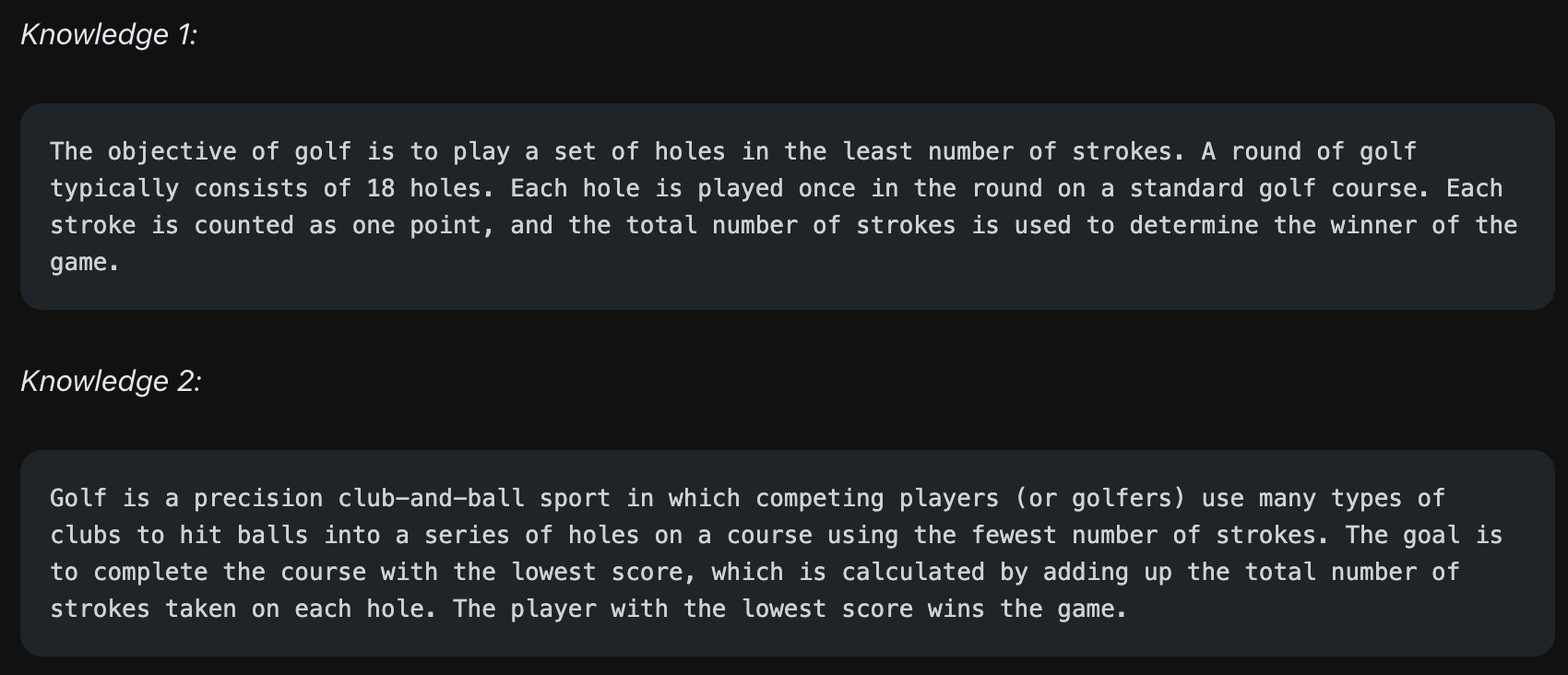
이제 모델이 가져온 정보를 복붙해서 사용합시다. 질문만 주지 않고 이번에는 질문과 함께 모델이 생성한 정보를 함께 줍니다.
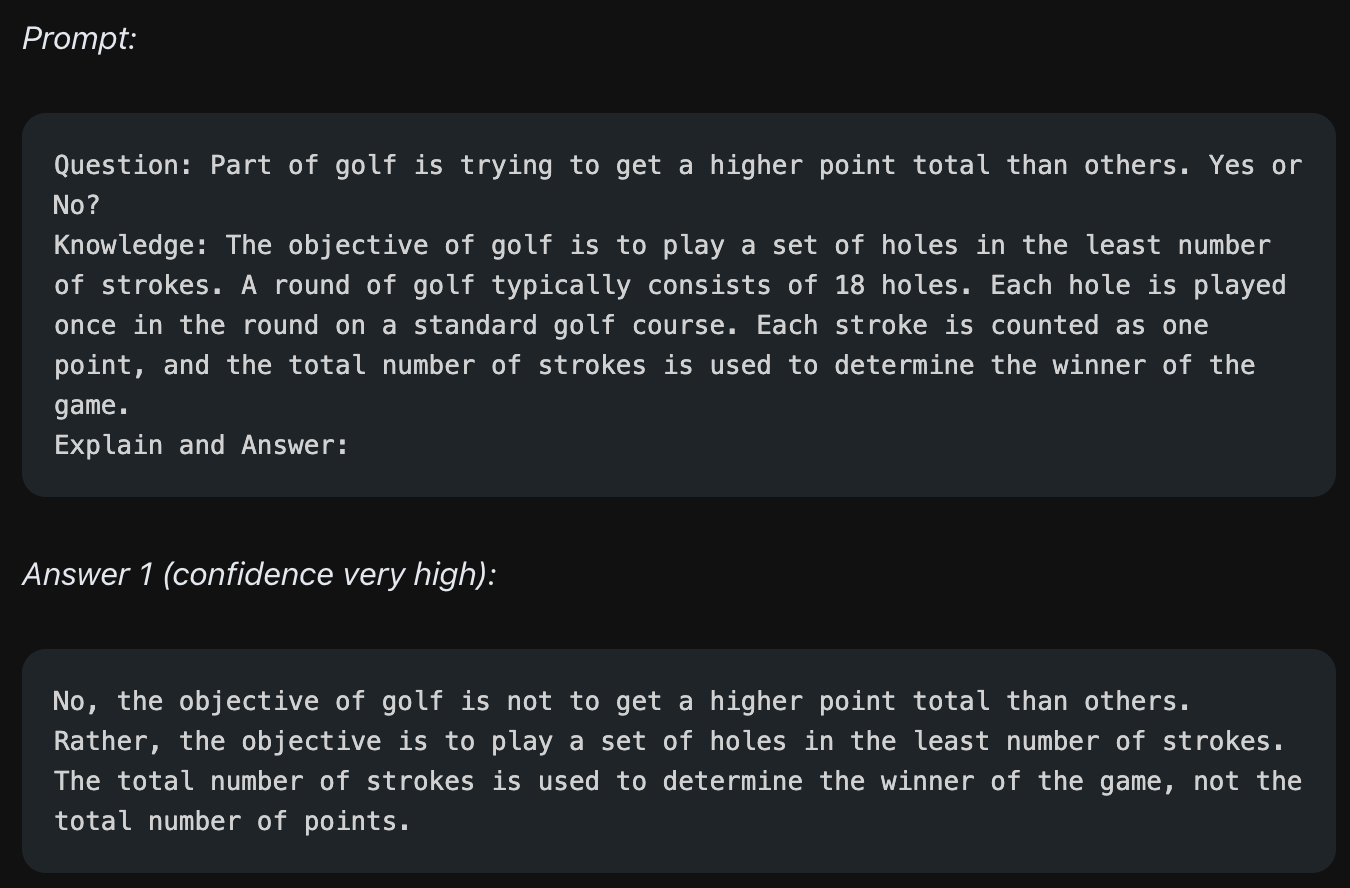
앞서 질문만 주는 경우보다 정보를 함께 줄 경우, 모델은 Knowledge에 나온 내용을 함께 참고해서 정답을 가져올 수 있게 됩니다. 즉 위의 예시에서 모델은 "골프는 점수를 적게 내도록 하는 게임이다"라는 내용을 내포한 정보를 함께 준 결과 정보를 참고해서 "골프는 점수를 많이 낸 사람이 이기는 게임이 아니다!"라는 확실한 답을 가져옵니다.
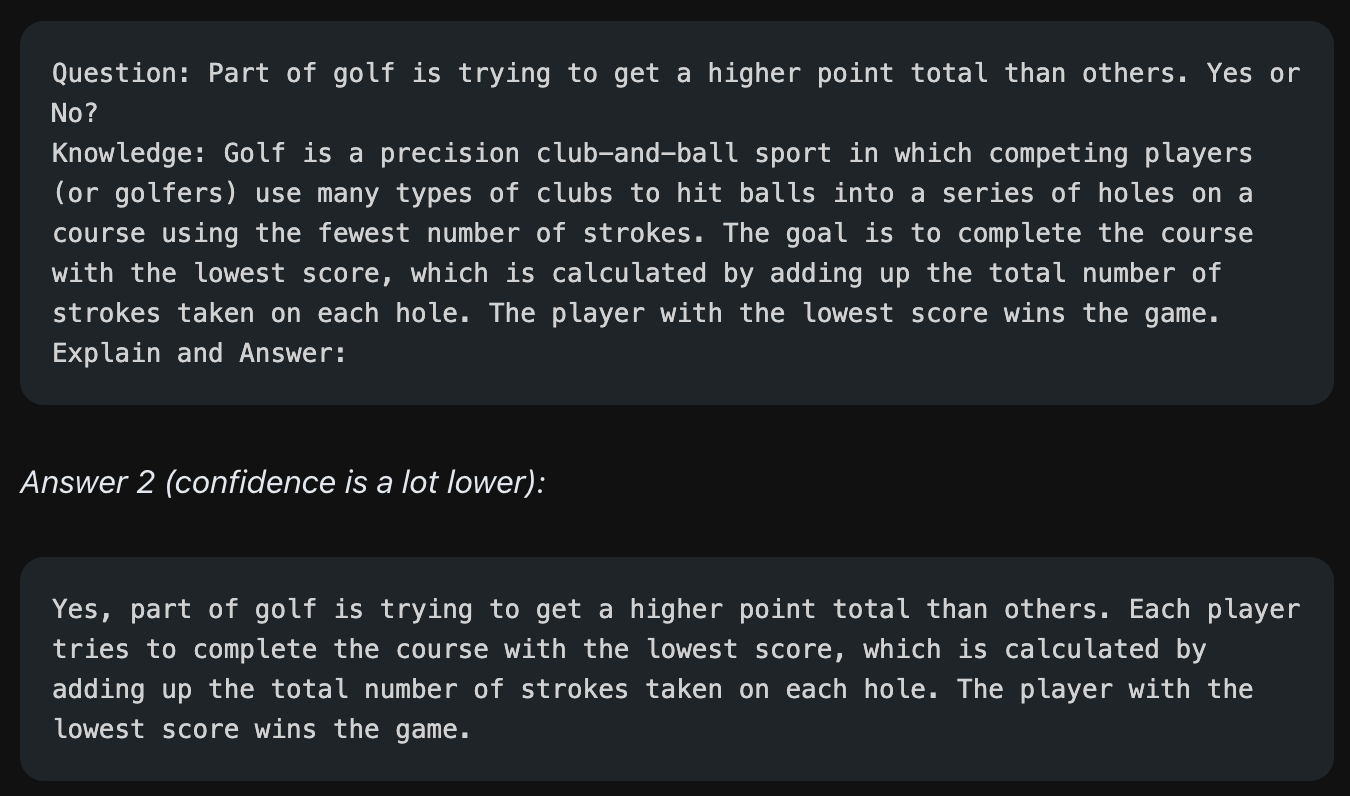
하지만 정보를 함께 주는 상황에서도 모델이 틀린 답을 내놓을 수도 있습니다. 위 예시에서는 약간 다른 정보를 준 경우인데, 재밌는 점은 틀린 답을 내놓으면서도 결국에는 "가장 적은 점수를 낸 플레이어가 이긴다"라는 답을 모델이 함께 제시하는 것입니다. 즉 정보가 없을 때는 "맞다, 아니다"라는 확실한 답을 내던 모델이 정보를 함께 줄 경우 틀린 답을 내놓으면서도 확실하지 않게, 일관성 없는 답을 가져오는 것을 볼 수 있습니다.
Automatic Prompt Engineer
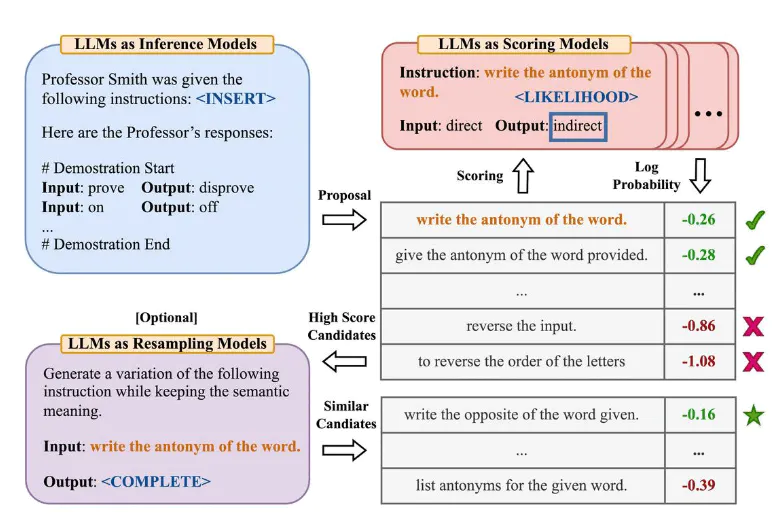
지금까지는 인간이 그래도 직접 prompt를 구성했다면, Automatic Prompt Engineer(APE)는 이름에서부터 알 수 있듯이 모델 스스로 prompt를 만들도록 한 다음, 모델이 만든 prompt를 사용하는 방법입니다. 방법은 다음과 같습니다.
- prompt 내부에 <INSERT>라는 빈 칸을 만들고, Answer를 함께 주면서 모델에게 <INSERT> 부분을 채우라는 테스크를 줍니다.
- 모델은 <INSERT> 부분을 채울 만한 답변을 여러 개 가져옵니다.
- <INSERT> 부분을 채우고 Answer를 비운 상태에서 LLM에게 답을 달라는 prompt를 줍니다. 즉 모델이 만든 prompt를 활용합니다.
- 모델이 만든 답변에 따라 모델이 만든 prompt를 채점합니다. 그 결과 점수가 가장 높은 prompt를 사용하게 됩니다.
즉 모델이 prompt를 만들고, prompt를 사용해서 직접 질문을 던져보고 가장 좋은 답변을 가져온 prompt를 사용하는 방식입니다.
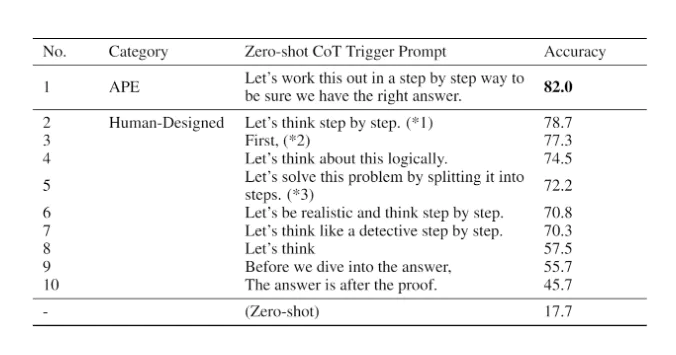
APE를 사용한 예시로 논문에서는 Zero-Shot CoT를 들고 있습니다. 앞서 Zero-Shot CoT에서 "Let's think step by step"라는 문구를 추가했을 때 모델은 추론 과정을 거쳐 좋은 답변을 준다고 했습니다. 이 문구를 APE에서 만들도록 했을 때, 모델이 만든 질문인 "Let's work this out in a step by step way to be sure we have the right answer"가 가장 정확도 높은 답변을 가져온다는 것을 볼 수 있습니다.
Prompting Engineering에는 더 많은 방법론들이 있으며 다음 글에 이어서 작성하도록 하겠습니다.
