Chat-GPT에 이어 GPT-4까지 등장한 지금, 자연어처리에서 LLM(Large Language Model)은 빼놓을 수 없는 주제입니다. 현재 유명한 GPT와 그동안 많이 사용되었고 사용되고 있는 모델인 BERT 모두 시작은 Transformer라는 구조가 등장한 논문 Attention is all you need(2017)였습니다.
이 글을 Attention is all you need 논문 리뷰이긴 한데, 사실상 Transformer 구조를 설명하고자 하는 글입니다. Transformer의 전체적인 구조를 설명하기 전 Attention의 개념부터 정리하고 넘어가려고 합니다.
논문 출처 : https://arxiv.org/abs/1706.03762
Seq2Seq에 대하여
Transformer의 구조는 Seq2Seq(Sequence to Sequence)로부터 시작됩니다. Seq2Seq은 여러 개의 time step으로 이루어진 시퀀스를 입력으로 받아 다른 시퀀스를 반환하는 모델입니다. 자연어 관점에서 시퀀스는 어떤 문장을 의미한다고 보면 됩니다.
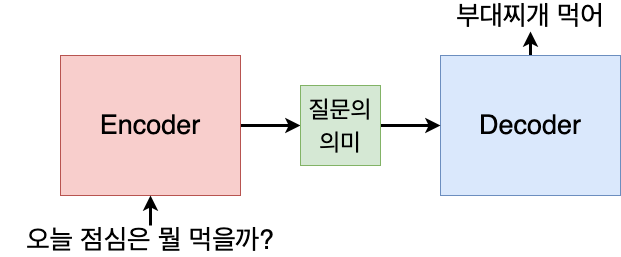
모델은 크게 입력 문장의 의미를 파악하여 반환하는 Encoder와, Encoder가 해석한 문장의 뜻을 입력으로 받아 새로운 문장을 만들어내는 Decoder로 구분됩니다. Attention is all you need 이전에는 양쪽 모두 시퀀스를 처리하기 위해 RNN 또는 LSTM으로 구성되어 있었습니다. 하지만 RNN과 같은 Recurrent structure는 크게 두 가지 단점을 가지고 있습니다.
1) 병렬 처리의 어려움: 각 time step은 이전 time step의 출력값을 바탕으로 출력값을 내보냅니다. 그 말은 이전 time step의 정보가 없는 상태에서는 어떤 것도 할 수 없다는 뜻이기도 하며, 따라서 하나의 시퀀스를 병렬 처리하여 학습하고 추론하는 것이 어려워 computational cost가 많이 발생합니다.
2) Vanishing Gradient: 시퀀스의 길이가 길어질수록 이전 time step의 정보는 많이 손실될 수밖에 없습니다. 비록 LSTM에서 cell state를 도입하는 등 많은 시도를 했지만, 결국 정보 손실을 온전히 막을 수는 없었습니다.
특히 길이가 긴 시퀀스, 즉 긴 문장을 처리하기 어렵다는 단점은 정보 손실 이외에도 다른 문제점도 야기합니다. 실제 문장에서는 위치적으로 거리가 먼 곳에 있는 단어가 더 유사한 의미를 가지거나 중요한 정보를 담고 있는 경우가 꽤 많습니다. 가령 이런 문장이 있고, 이를 영어로 번역하는 테스크가 있다고 가정합시다.
대학원생은 오늘 점심으로 부대찌개를 먹고 싶어 했으나 교수님이 김치찌개를 먹으러 가자고 하였기에 가여운 노예는 김치찌개를 먹으러 갔습니다.
이 글에서 "노예"라는 단어와 가장 유사한 뜻을 가지는 단어는 "대학원생"이라고 볼 수 있습니다. 하지만 둘 사이의 거리는 한 문장 내에서 꽤 멀리 있습니다. 이런 문장을 Encoder가 입력으로 받은 다음 Decoder가 번역된 문장을 만들려고 할 때, "Graduate Student(대학원생)"이라는 단어는 "Slave(노예)"라는 단어와 유사하다는 정보를 가져오는 것이 유리할 것입니다. 이를 가능하게 하는 것이 Attention이라고 볼 수 있습니다.
Attention
01. Attention 개념 이해하기
Attention은 말 그대로 "어떤 단어에 중점을 두고 이해해야 할까"를 알려주는 정보라고 볼 수 있습니다. 이전의 seq2seq 모델에서는 위에서 설명한 그림처럼 decoder가 encoder를 통해 요약된 하나의 정보(질문의 의미)만을 바탕으로 시퀀스를 만들어냈습니다.
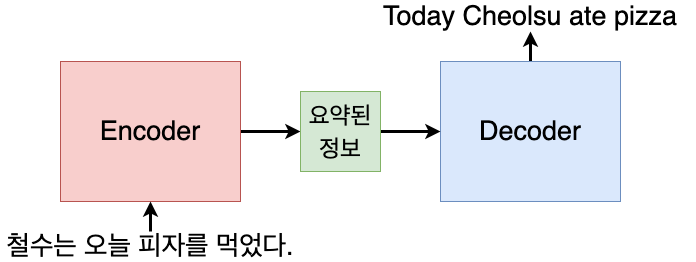
하지만 Attention에서는 여기에 추가로 단어별 가중치(attention) 정보를 가져옵니다. 예를 들어 "철수는 오늘 피자를 먹었다"라는 단어를 Encoder가 받아오고, Decoder가 "Today"라는 단어를 출력하려고 한다고 가정해 봅니다. Today라는 단어는 입력값 중 "오늘"과 가장 유사한 뜻을 가지고 있습니다. 이 때 단순히 입력 문장의 정보를 요약한 값 하나만 decoder에게 주는 것이 아닌, 입력 문장의 각 단어별로 현재 time step에서의 attention 값을 함께 주게 됩니다. "Today"를 출력해야 할 시점의 time step에서는 "철수는 오늘 피자를 먹었다"라는 입력 문장 속 단어들 중 "오늘"이라는 단어에 가장 큰 값을 주면서 attention 값을 넘기게 됩니다. 그러면 decoder는 "오늘"이 가장 큰 attention을 가지고 있기 때문에 "오늘"과 유사한 단어를 출력하려고 할 것입니다. 정확하지는 않지만 그림으로 이해하기 쉽게 표현하자면 아래와 같습니다.
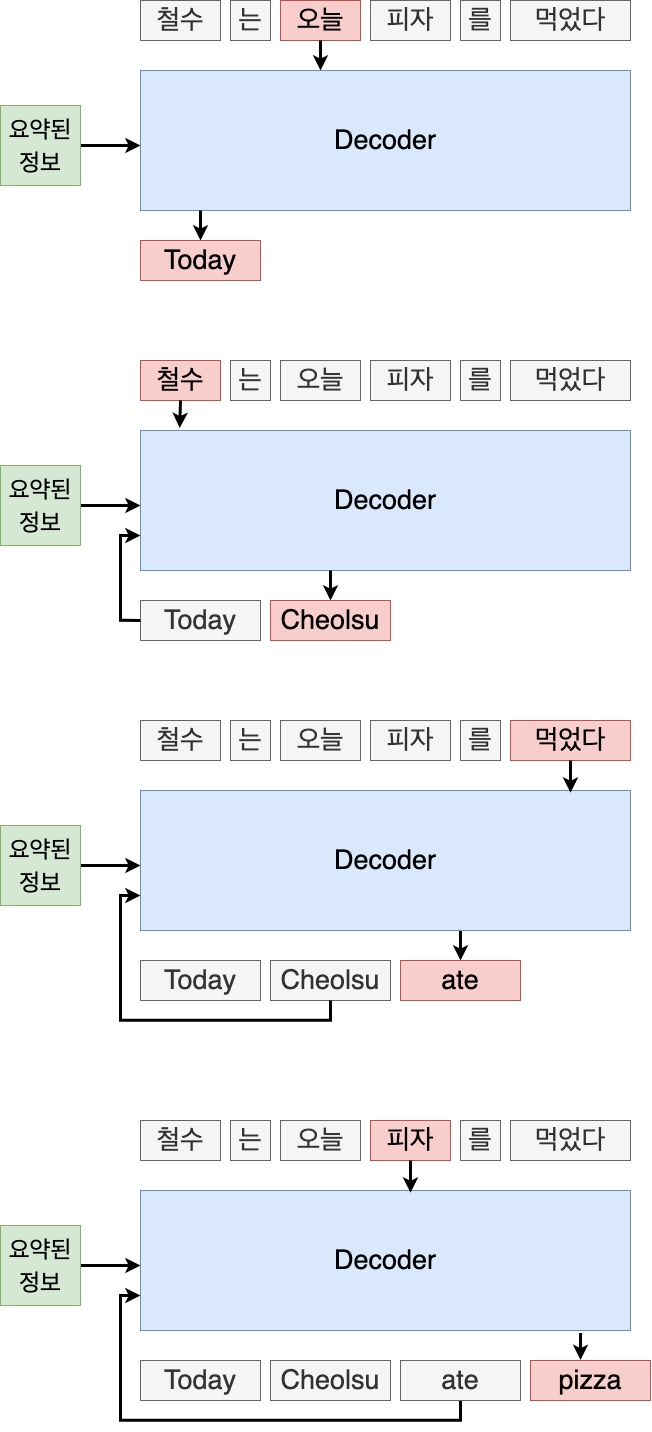
02. Attention 수식 이해
이제 이것을 수식으로 이해해봅시다. Attention 값을 수식으로 쓰면 아래와 같습니다.
Attention(Q, K, V) = attention_score여기서 K, Q, V는 다음과 같습니다.
- K (Key): 입력 시퀀스의 각 time-step에서의 정보 (임베딩값)
- Q (Query): (Decoder의) 현재 time-step에서의 은닉 상태 (임베딩값)
- V (Value): 입력 시퀀스의 각 time-step에서의 정보 2 (임베딩값)
즉 벡터 형태로 되어 있는 Q, K, V 값을 입력으로 받아 어떤 계산식을 거쳐서 attention score를 내게 됩니다. 이 때 Q, K, V 값은 학습을 통해 얻어지는 값인데, 문장을 나타내는 시퀀스에 , , 벡터를 곱해서 얻게 됩니다.
그럼 그 어떤 계산식은 어떻게 계산될까요? Transformer에서는 Scaled Dot-Product Attention을 취하게 됩니다.
Scaled Dot-Product Attention 계산은 다음과 같습니다. 우선 Q와 K 벡터를 내적(dot-product)합니다.
여기서 K는 입력 시퀀스의 정보를, Q는 현재 time-step에서의 정보를 담고 있습니다. 이 말은 현재 time-step에서의 은닉 상태와 입력 시퀀스들 간의 상관관계를 구하겠다는 의미와 같습니다.
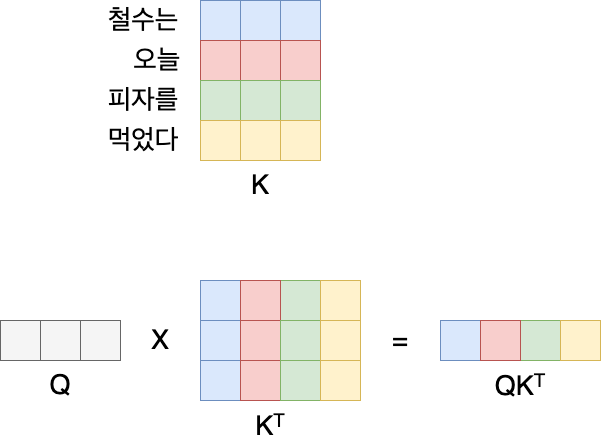
이를 그림으로 다시 설명하자면 위와 같습니다. 입력 시퀀스 "철수는", "오늘", "피자를", "먹었다" 각각에 대한 임베딩 값을 모은 것이 K 벡터이며, 현재 시점에서의 은닉 상태 Q 벡터와 내적을 하게 되면 입력 시퀀스의 단어 갯수만큼의 벡터값들을 얻게 됩니다. 각각은 현재 시점에서 각 입력 시퀀스들과의 상관관계(유사도)를 의미하게 됩니다.
그 다음 이렇게 구한 값을 로 나눕니다. 여기서 는 임베딩 벡터의 차원 수를 의미합니다. 위에서 값은 Q와 K에서의 임베딩 벡터의 차원 수가 커질수록 커지게 됩니다. 따라서 차원 수가 커질수록 가중치 값이 커지는 것을 방지하기 위해 로 나누는 과정을 거치게 됩니다. 이 과정이 추가되기 때문에 Transformer에서의 Attention을 Scaled Dot-Product Attention이라고 합니다.
이렇게 구한 값을 softmax를 취해서 각 단어별로 유사도 값을 얻습니다.
이렇게 입력 시퀀스의 각 단어별로 현재 time-step에서의 유사도 값을 얻었습니다. 이제 현재 time-step에서 단어를 출력하기 위해 어떤 단어에 가중치를 가져야 할지에 대한 정보, 즉 attention score를 얻어야 합니다. 이를 위해 입력 시퀀스를 표현하는 또 다른 벡터 V를 내적하게 됩니다.
이 값이 최종적으로 attention score가 됩니다. 실제로 attention score를 계산할 때는 time step별로 각각 계산하지 않고 한 번에 벡터 내적 연산을 취하게 됩니다.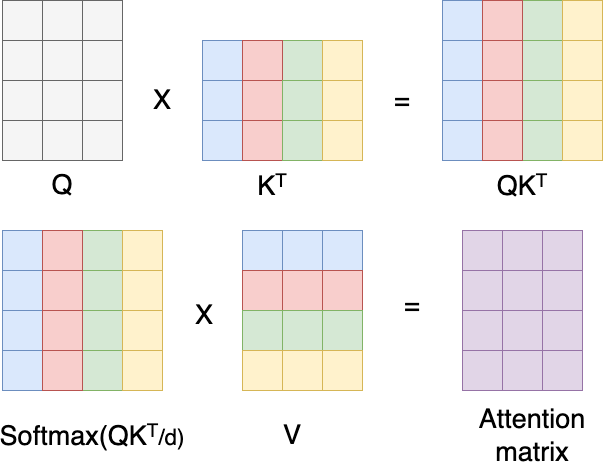
최종적으로 얻게 되는 attention matrix는 (time-step의 길이) x (v 벡터에서 각 단어의 임베딩 차원수) 만큼의 크기를 가지게 됩니다.
03. Multi-head Attention
Transformer 논문에서는 여기서 다시 multi-head attention을 사용한다고 언급하고 있습니다. 그럼 여기서 multi-head란 무엇일까요? 여러 개의 attention 값을 합친다는 의미입니다. Transformer에서는 각각 하나씩의 Q, K, V 벡터를 이용해서 얻은 하나의 attention matrix를 이용하지 않고, 서로 다른 Q, K, V 벡터들을 사용하여 8개의 attention matrix를 얻은 다음 합쳐서 사용합니다. 논문에 나온 수식은 아래와 같습니다.
앞서 Q, K, V 벡터는 학습을 통해 얻은 , , 를 곱해서 구한다고 했었습니다. 이 학습을 통해 얻은 가중치 벡터를 한 번에 큰 차원의 것을 사용하는 것이 아니라, 8개의 서로 다른 작은 벡터를 사용해서 Attention을 계산하고, 그 값들을 서로 합쳐서 얻은 attention 값을 사용하는 방식이 multihead attention입니다.
왜 한번에 계산하지 않고 이렇게 나누어 계산하게 되었을까요? 쉽게 설명하자면 8개의 서로 다른 관점에서 문장을 바라보고 attention 값을 계산하기 위해서라고 합니다. 즉 보다 더 다양한 정보를 얻어서 합치고자 하는 의도라고 이해하면 될 것 같습니다.
여기까지 Transformer에서 Attention을 계산하는 방법에 대해 설명했습니다. 다음 글에서는 실제 Transformer의 Encoder와 Decoder 각각에서 어떻게 Attention을 계산하는지 설명하겠습니다. (다음 편이 나오면 아래에 덧붙이겠습니다.)
마지막으로 내용과 무관하지만 한마디 하자면...이 글은 뉴진스 attention을 들으면서 작성했습니다
