2022년, "그림 그리는 AI"라고 불리는 DALL-E가 이슈가 된 적이 있습니다. 말하는 대로 온갖 그림을 내보내는 DALL-E는 실제로 인공지능이 인간의 영역을 침범할 수도 있다는 가능성을 남겼었습니다. 그리고 한 해가 지나 OpenAI는 또 다시 ChatGPT라는 이슈거리를 만들어냈습니다. 어떻게 보면 단순한 챗봇일 뿐인데, 이번에는 단순히 예술가뿐만 아니라 심지어는 ChatGPT 자체를 만든 개발자들의 영역까지 넘볼 수 있다는 가능성을 남기고 있습니다.
그렇다면 ChatGPT는 어떤 원리로 만들어진 것인지가 궁금하신 분들도 있을 것이고, 인공지능에 대한 기본 지식이 있으신 분들도 있겠지만 전혀 모르는 분들도 계실 것입니다. 그래서 설명하다 보면 틀린 부분이 꽤 많을 수 있겠지만, 원리의 맥락 정도는 이해할 수 있게 ChatGPT의 기본이 되는 자연어처리에 대해 설명해보고 싶었습니다. (사실 관련 논문들을 제대로 읽어보질 않아서 딥하게 설명하질 못하는 것도 있습니다.) 유행이 끝나기 전에 인공지능 베이스가 없는 분들을 위해 자연어처리는 어떻게 발전해 왔고, ChatGPT는 어디서 생긴 친구인지 설명해보고자 합니다.
워낙 가볍게 설명할 예정이라, 추후에 각각에 대해 자세히 설명하는 글을 적게 되면 링크를 추가할 예정입니다.
딥러닝의 기본 원리
혹시 딥러닝을 모르시는 분들을 위해 기본원리를 간단하게 예시를 들어보겠습니다. 딥러닝이 어떻게 동작하는지는 아래 영상 하나로 설명이 가능합니다. (출처: 유튜브 침착맨)

영상을 보면 주호민님은 아이돌에 대한 정보가 없던 상태에서 아이돌 사진을 보고 이름을 맞추는 과정을 반복합니다. 수많은 아이돌 사진 데이터가 쌓이면서 주호민님의 아이돌 이름 맞추기 실력이 향상됩니다. 이를 딥러닝 관점에서 설명하자면 "주호민님"이라는 딥러닝 모델이 있고, 딥러닝 모델은 "아이돌 사진"이라는 입력에 대해 "아이돌 이름"이라는 출력을 내보내도록 학습이 됩니다. "주호민님"은 수많은 "아이돌 사진"들이 "아이돌 이름"으로 라벨링되어 있는 데이터를 바탕으로 학습을 반복하게 되고, 이를 통해 "주호민님"이라는 딥러닝 모델의 성능이 향상됩니다.
즉, 수많은 입력 데이터를 기반으로 학습되는 모델이 딥러닝 모델이라고 볼 수 있습니다. 하지만 여기서 딥러닝 모델을 학습시키는 방법을 크게 세 가지로 구분할 수 있습니다.
1) 지도 학습
라벨링이 되어 있는 데이터로 학습시킵니다. 위의 주호민님 예시가 해당합니다.
2) 비지도 학습
라벨링이 없는 데이터로 학습. 예를 들자면, 아이돌 사진만 주고 아이돌 이름은 알려주지 않은 상태에서 알아서 사진을 분류해 보라고 하는 거죠. 그러면 "걸그룹"과 "보이그룹"으로, 또는 컨셉별로 아이돌 사진을 구분할 수 있을 것입니다.
3) 강화 학습
데이터를 주지 않고 학습시키는 것입니다. 예를 들자면, 주호민님께 아이돌 사진을 주고 맞추라고 합니다. 주호민님이 틀렸을 경우 답을 알려주는 것이 아니라 벌점만 줍니다. 맞췄을 경우 상점을 줍니다. 그러면 주호민님은 점점 상점을 많이 얻을 수 있도록 정답에 가까운 답만 할 수 있도록 학습될 것입니다. (주호민님은 엄연히 사람이신데 자꾸 모델처럼 설명해서 죄송하네요...)
자연어 처리 모델의 변천사
ChatGPT는 자연어 처리 모델, 즉 인간의 언어를 이해하고 이에 대응하는 모델 중 하나이며, 특히 질의응답을 하기 위한 모델입니다.
어떤 질문이 있을 때, 우리는 질문에 대한 답을 알고만 있다면 답변을 할 수 있습니다. 질문 자체를 이해하지 못하는 상황은 거의 없습니다. 하지만 딥러닝 모델에게는 질문을 이해하는 것부터가 엄청난 과제입니다. 따라서 답변을 만들기 전에 질문을 이해할 수 있도록 딥러닝 모델을 학습시켜야 합니다. 질문을 이해할 수 있는, 즉 언어를 이해할 수 있는 모델을 언어 모델 (Language Model, LM)이라고 하며, 다양한 자연어 처리 과제(질의응답, 번역 등)를 해결하기 위해 인간의 언어를 이해하는 언어 모델들을 사용합니다.
ChatGPT가 등장하기 전까지 많은 언어 모델들이 등장했었고, 발전에 발전을 이루다가 등장한 것이 ChatGPT입니다. ChatGPT를 이해하기 위해 필요한 이전 모델들을 간단하게 언급하고 넘어가겠습니다.
다시 말씀드리지만, 이 글은 "인공지능을 모르는 사람들"이 읽는이라는 전제 하에 설명하기 때문에 상당히 블랙박스처럼 모델을 묘사할 예정입니다. RNN이라든지 Attention에 대한 개념 같은 것도 과감히 생략합니다.
1. Seq2Seq, Transformer
Seq2Seq (Sequence to Sequence) 모델은 모델명처럼 시퀀스를 시퀀스로 반환하는 모델입니다. (https://arxiv.org/abs/1409.3215)
우리의 언어는 단어들로 이루어진 시퀀스이기 때문에 언어를 입력하면 언어를 반환하는 모델이라고 볼 수 있습니다.
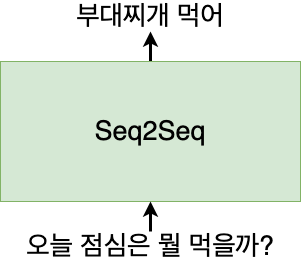
위의 그림은 챗봇 역할을 할 수 있는 Seq2Seq 예시입니다. 입력으로 질문을 입력하면, 출력으로 답변을 할 수 있도록 Seq2Seq 모델을 만들 수 있습니다. 그러면 Seq2Seq 모델 안에서는 어떤 일이 일어나고 있을까요?
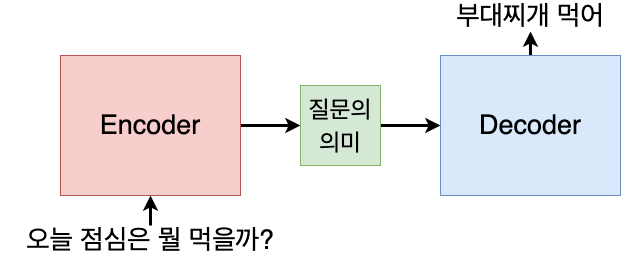
모델은 크게 두 부분으로 나누어지는데, 입력을 이해하는 부분인 Encoder와 이해한 입력값에 따라 출력을 내보내는 Decoder입니다.
먼저 모델은 질문의 뜻을 이해합니다. 이 역할을 하는 부분을 Encoder라고 합니다. Encoder는 입력 문장에 대해 질문의 뜻을 이해한 결과, 즉 입력 언어를 이해한 결과인 Context를 출력으로 내보냅니다. 이 Context를 바탕으로 Decoder는 입력 문장에 맞는 출력 문장을 내보냅니다. 이 출력 문장이 무엇이 될지는 우리가 해결하고자 하는 자연어처리 과제가 무엇인지에 따라 달라질 것입니다. 챗봇 서비스를 만들고자 한다면 출력은 입력 문장에 대한 답변이 될 것이며, 번역 서비스를 만들고자 한다면 출력은 입력 문장을 다른 언어로 번역한 결과가 될 것입니다.
Transformer는 Seq2Seq에서 발전된 모델입니다. (https://arxiv.org/abs/1706.03762)
구조는 아래와 같습니다.
Transformer 설명
1. [논문리뷰] Attention is all you need (Transformer 구조 파헤치기) - 1. Attention이란?
https://velog.io/@boyunj0226/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Attention-is-all-you-need-Transformer-%EA%B5%AC%EC%A1%B0-%ED%8C%8C%ED%97%A4%EC%B9%98%EA%B8%B0
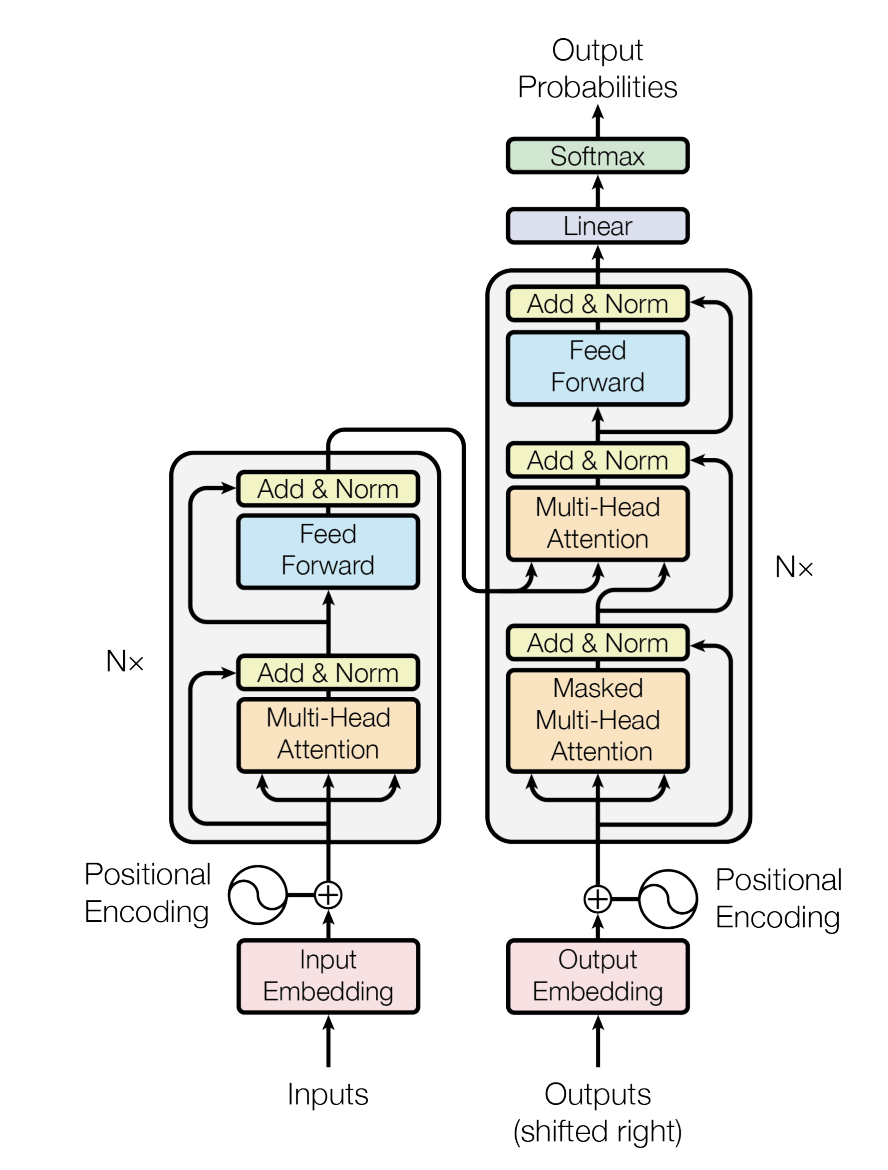
자세한 설명은 이 글에서는 생략하도록 하겠습니다. 하지만 Transformer 역시 문장을 이해하는 부분인 Encoder, 이해된 내용을 바탕으로 문장을 출력하는 부분인 Decoder로 구성되어 있다는 것만 이해하고 넘어가도록 하겠습니다.
2. BERT
BERT는 Bidirectional Encoder Representations from Transformers의 약자로, 앞서 언급한 Transformer에서 Encoder 부분만 떼어서 사용하는 모델입니다. (https://arxiv.org/abs/1810.04805)
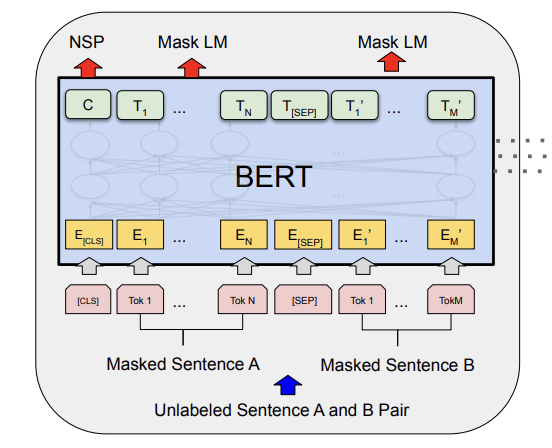
앞서 Encoder의 역할은 입력 언어를 이해하는 것이라고 설명했습니다. 그렇다면 Encoder만 있는 BERT는 언어를 이해하는 능력이 있는 모델이라고 볼 수 있습니다. 하지만 사람이 처음 언어를 학습하기에 상당한 시간이 필요하듯, BERT를 처음부터 학습시키는 데에는 상당히 많은 데이터와 시간이 필요합니다. 따라서 우리는 일반적으로 이미 어느 정도 학습이 되어 있는 BERT를 사용하여, 이미 언어를 이해하는 능력이 있는 BERT를 목적에 맞게 사용합니다.
그렇다면 BERT가 언어를 이해할 수 있게 학습시키려면 어떻게 해야 할까요? 크게 2가지 학습방법이 있습니다.
1) Masked LM : 쉽게 말해, 글 중간중간 단어들을 마스킹해두고, 마스킹된 단어를 예측하도록 학습시키는 것입니다. "나는 오늘 퇴근을 하고 치킨을 먹으러 갈 거야"라는 문장이 있을 때, 랜덤하게 한두 개의 단어를 뚫어놓습니다. "나는 오늘 퇴근을 하고 치킨을 [MASKED] 갈 거야"라는 문장을 준 상태에서, [MASKED] 부분이 무엇일지 맞추게 합니다. 뚫린 부분을 맞추기 위해 BERT는 "먹으러"라는 단어의 뜻과 함께 앞뒤 문장의 문맥까지 이해해야 합니다. 따라서 이 과정을 통해 언어를 이해하는 능력을 가지게 되는 것이죠.
2) Next Sentence Prediction (NSP) : 두 개의 문장을 주고, 두 문장의 순서가 맞는지 맞추도록 학습하는 것입니다. "나는 학교에 갔다.", "그리고 급식을 먹었다"라는 두 개의 문장은 앞뒤관계가 맞다고 맞춰야 하고, "나는 학교에 갔다.", "펭귄은 무리를 지어 이동한다." 두 문장은 앞뒤관계가 아니기 때문에 틀리다고 해야 하는 것입니다. 초기에 제안된 학습방식이며 이후에는 잘 사용되지 않는다고 합니다.
위의 두 가지 학습을 거쳐 BERT는 언어를 이해할 수 있는 모델이 됩니다. 미리 학습된(pretrained) BERT 모델을 약간만 더 학습시켜서 (fine-tuning) 질의응답이나 태깅 등 원하는 목적에 따라 사용할 수 있습니다.
3. GPT
Transformer의 Encoder 부분을 사용하는 BERT와 다르게 GPT(Generative Pre-Training)는 Decoder 부분만 사용합니다. 앞서 언급한 Decoder는 입력에 맞는 출력 문장을 만드는 역할을 합니다. 즉 GPT도 입력에 맞는 적절한 출력 문장을 생성하며, BERT보다 먼저 OpenAI에서 시작한 모델입니다. (https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf)
GPT는 총 3가지 버전이 있었습니다.
- GPT-1 : 초창기 GPT. 미리 학습된 모델을 약간만 더 학습해서 (fine-tuning) 사용할 수 있게 만듬
- GPT-2 : GPT-1에서 모델 사이즈를 키우고 데이터를 더 많이 사용. 미리 학습된 모델을 어느 정도까지 그대로 사용 가능 (zero-shot) (https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
- GPT-3 : GPT-2보다 모델 사이즈를 키우고 데이터를 더 많이 사용 (https://arxiv.org/abs/2005.14165)
물론 단순히 모델 크기만 키운 것은 아니지만, 버전을 거듭할수록 모델 규모가 커지고 많은 데이터를 통해 학습하면서 성능이 좋아졌습니다. GPT-3까지만 하더라도 모델이 만들어낸 글이 인간과 구분하기 힘들 정도로 좋다는 평가를 받았습니다. 그 후 GPT-3를 능가하는 ChatGPT가 등장해버립니다.
ChatGPT와 함께 글을 마무리하며
그러면 ChatGPT는 어디서 온 것일까요? 바로 앞서 언급한 GPT 모델 중 하나입니다. ChatGPT는 일반적으로 GPT-3.5 정도로 여겨지고 있으며, GPT-3에서 강화학습을 적용했습니다. 즉 실제 사람들의 피드백을 기반으로 학습하는 과정이 추가되었기 때문에 더욱 감쪽같이 사람처럼 대화할 수 있는 모델이 만들어진 것입니다.
자연어처리의 전체적인 흐름을 설명하는 글이기 때문에 각각의 개념이나 모델에 대해 설명을 많이 생략했습니다. 하지만 대략적으로 딥러닝을 이용한 자연어 처리가 어떤 과정을 거쳐서 발전해 왔는지 이해할 수 있게 해주는 글이 되기를 바랍니다.
