하둡 설치가 완료되면 스파크 설치과정을 따라가시면 됩니다.
1. Hadoop 설치하기
(1) JAVA 설치 확인
하둡 설치 전 자바(JAVA)가 설치되어 있는지 확인합니다.
java -versionM1 맥에서 JAVA 설치하는 과정은 기록해두질 않아서... 나중에 기회가 되면 추가하겠습니다.
(2) localhost 암호 해제
먼저 아래 명령어를 입력합니다.
ssh localhost만일 ssh: connect to host localhost port 22: Connection refused 경고가 뜬다면 맥북 설정 -> 일반 -> 공유 -> 원격 로그인을 "켬"으로 설정해 주세요.
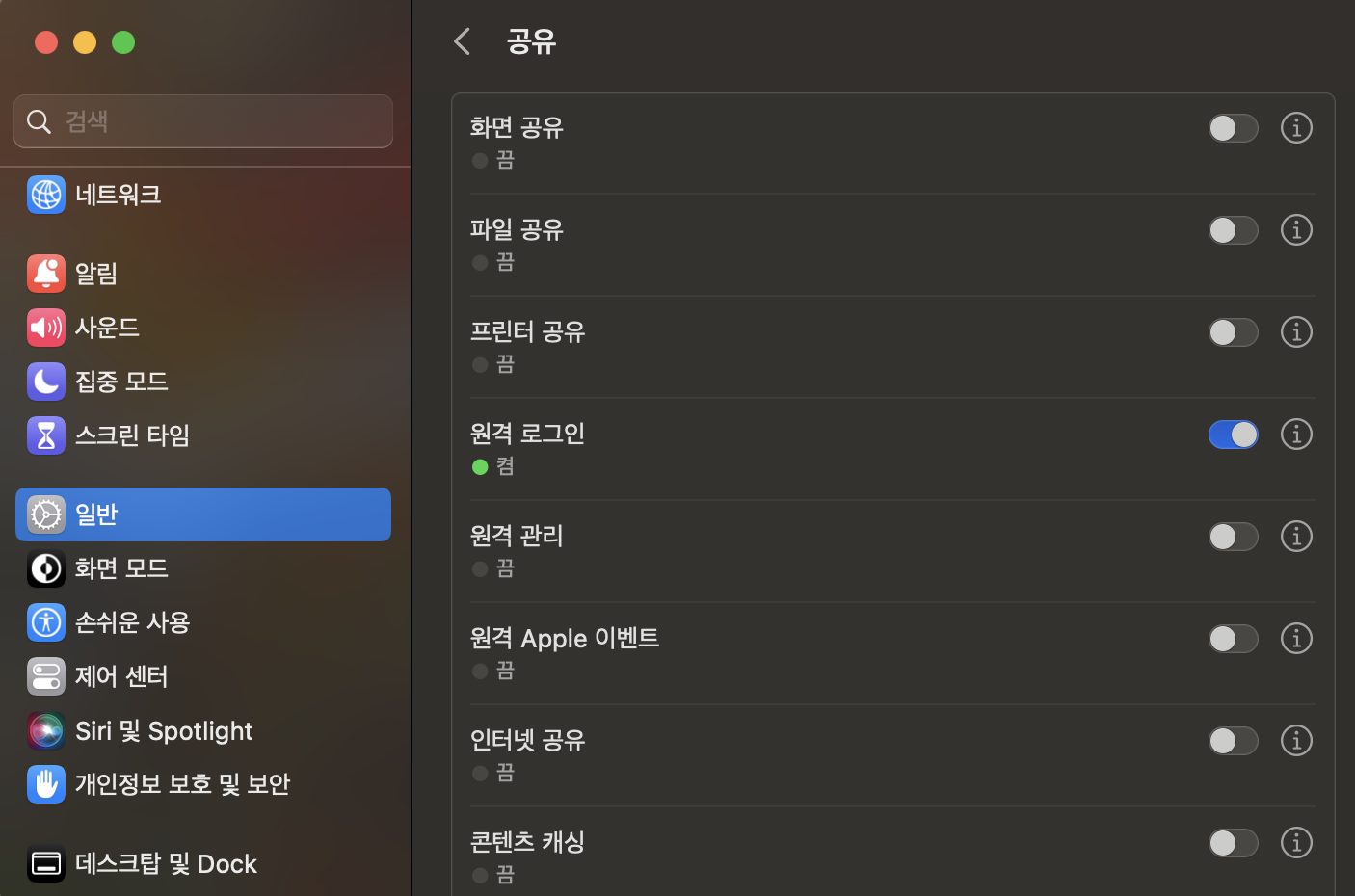
암호를 입력하라는 문구가 나올 텐데, 이를 해제시켜야 합니다. ssh 키를 생성하기 위해 아래 명령어를 입력합니다.
ssh-keygen키가 생성되었다는 문구가 뜰 것입니다. 그 후 cd ~/.ssh 위치로 이동하면 퍼블릭키(id_rsa.pub)가 생성된 것을 확인할 수 있습니다. 이제 생성된 퍼블릭 키를 아래와 같이 authorized_key에 추가시킵니다.
cat id_rsa.pub >> authorized_keys
chmod 0600 authorized_keys이제 ssh localhost를 입력하면 암호 없이 접속이 될 것입니다.
(3) Hadoop 다운로드 및 설치
아파치 하둡 공식 사이트(https://hadoop.apache.org)에 들어갑니다. 그리고 화면에 보이는 Download로 들어갑니다.

최신 버전의 binary 링크로 들어갑니다. 저는 3.3.4 버전으로 진행했습니다.
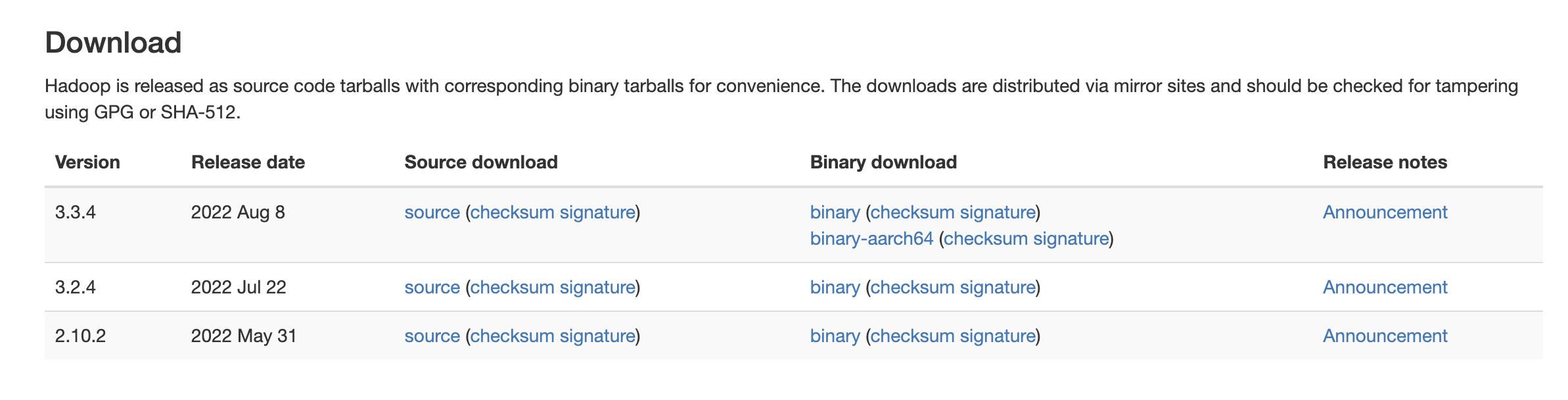
화면 상단에 보이는 링크를 복사해둡니다. 제가 사용한 링크는 다음과 같습니다.
(https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz)
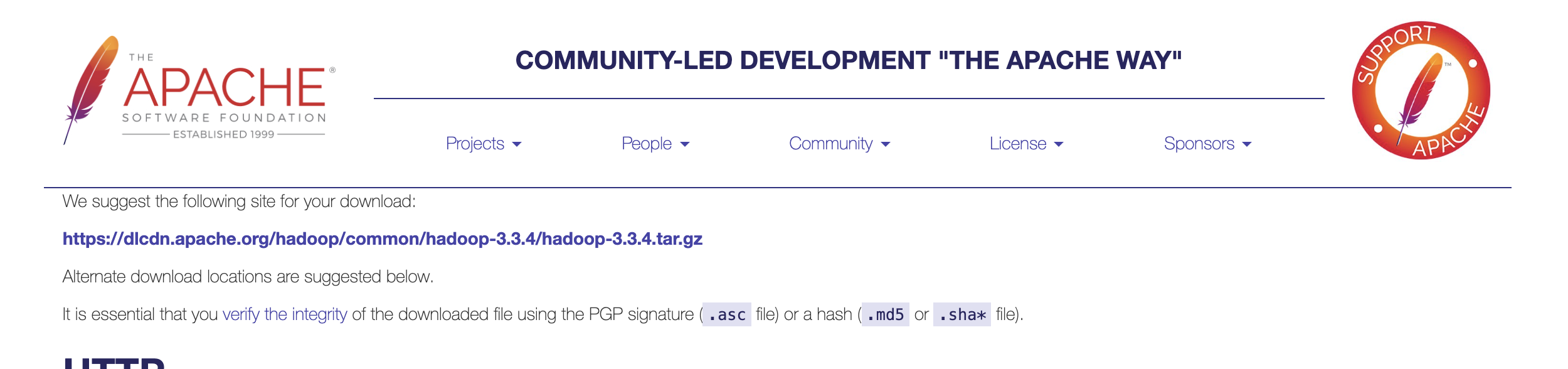
그 후 아래와 같이 다운로드 가능합니다.
- 혹시라도
wget이 설치되어 있지 않다면brew install wget으로 설치해주세요.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz다운로드된 파일을 압축해제합니다.
tar -xzvf hadoop-3.3.4.tar.gzhadoop-3.3.4 폴더가 생성되면 이제 vim ~/.zshrc 명령어를 통해 파일을 열고 아래 코드를 추가하여 경로 설정을 해줍니다. HADOOP_HOME에 현재 압축을 푼 하둡 폴더가 있는 경로를 명시해주고, PATH도 지정해줍니다.
export HADOOP_HOME=/Users/jangboyun/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin~/.zshrc 파일 수정을 마쳤으면 아래 명령어를 입력해주고, 하둡 경로(저의 경우 /Users/jangboyun/hadoop/hadoop-3.3.4)가 제대로 나오는지 확인합니다.
source ~/.zshrc
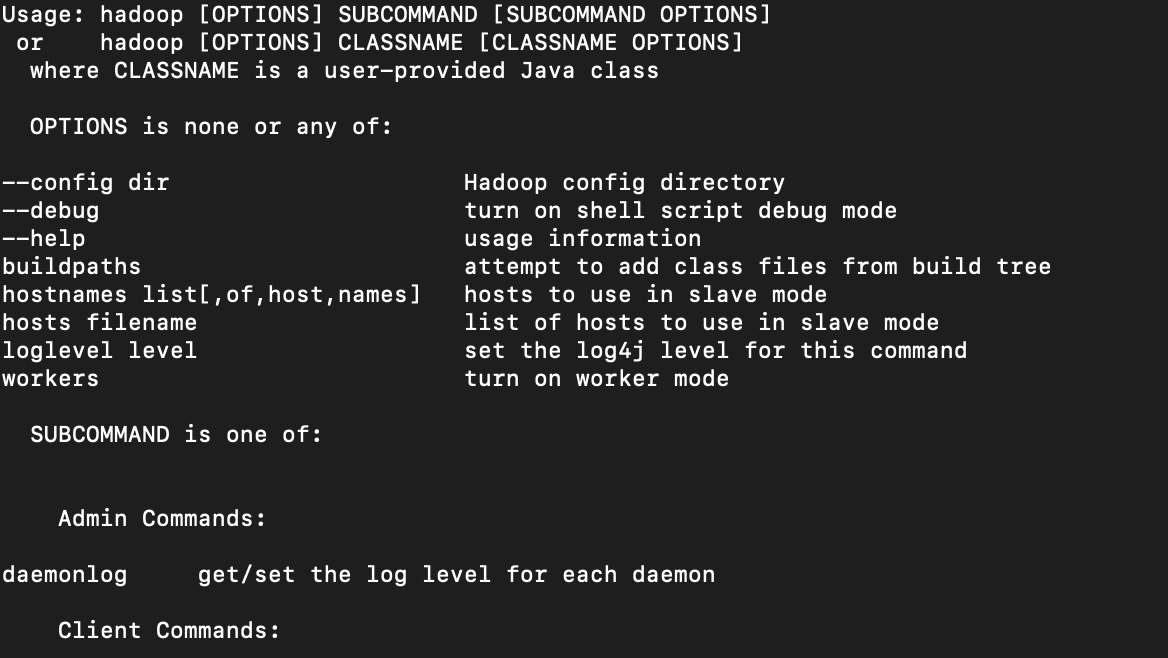
echo $HADOOP_HOME여기까지 하둡이 제대로 설치되었는지 확인하고 싶다면 터미널에 아래 명령어를 입력합니다.
hadoop아래와 같은 안내가 나오면 정상 설치된 것입니다.
hadoop-3.3.4/etc/hadoop으로 이동합니다. 그 후 아래 xml 파일들의 <configuration> 부분을 변경해줍니다.
# core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration># hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/Users/jangboyun/hadoop/hadoop-3.3.4/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/Users/jangboyun/hadoop/hadoop-3.3.4/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
# 여기서 dfs.datanode.data.dir의 value 값은 본인 하둡 디렉토리 경로로 설정해 주세요.# yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration># mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>그 후 다시 hadoop-3.3.4로 이동해서 아래 명령어를 실행시킵니다.
hdfs namenode -format
sbin/start-dfs.sh아래 화면이 나오면 정상적으로 네임노드와 데이터노드가 실행된 것입니다.

그 다음 아래 명령어를 이용해 디렉토리를 생성합니다.
hadoop fs -mkdir -p /user/test
# 디렉토리 생성 확인
hadoop fs -ls / 이제 하둡을 구동시킵니다.
cd sbin
start-dfs.sh # DataNode, NameNode 생성
start-yarn.sh # ResourceManager, NodeManager 실행
jps # 생성된 노드들과 ResourceManager, NodeManager 확인정상적으로 하둡이 실행되었다면 http://localhost:9870에서 확인 가능합니다.
2. Spark 설치하기
(1) Spark 다운로드 및 설치
스파크 다운로드 페이지에 접속합니다. (https://spark.apache.org/downloads.html)
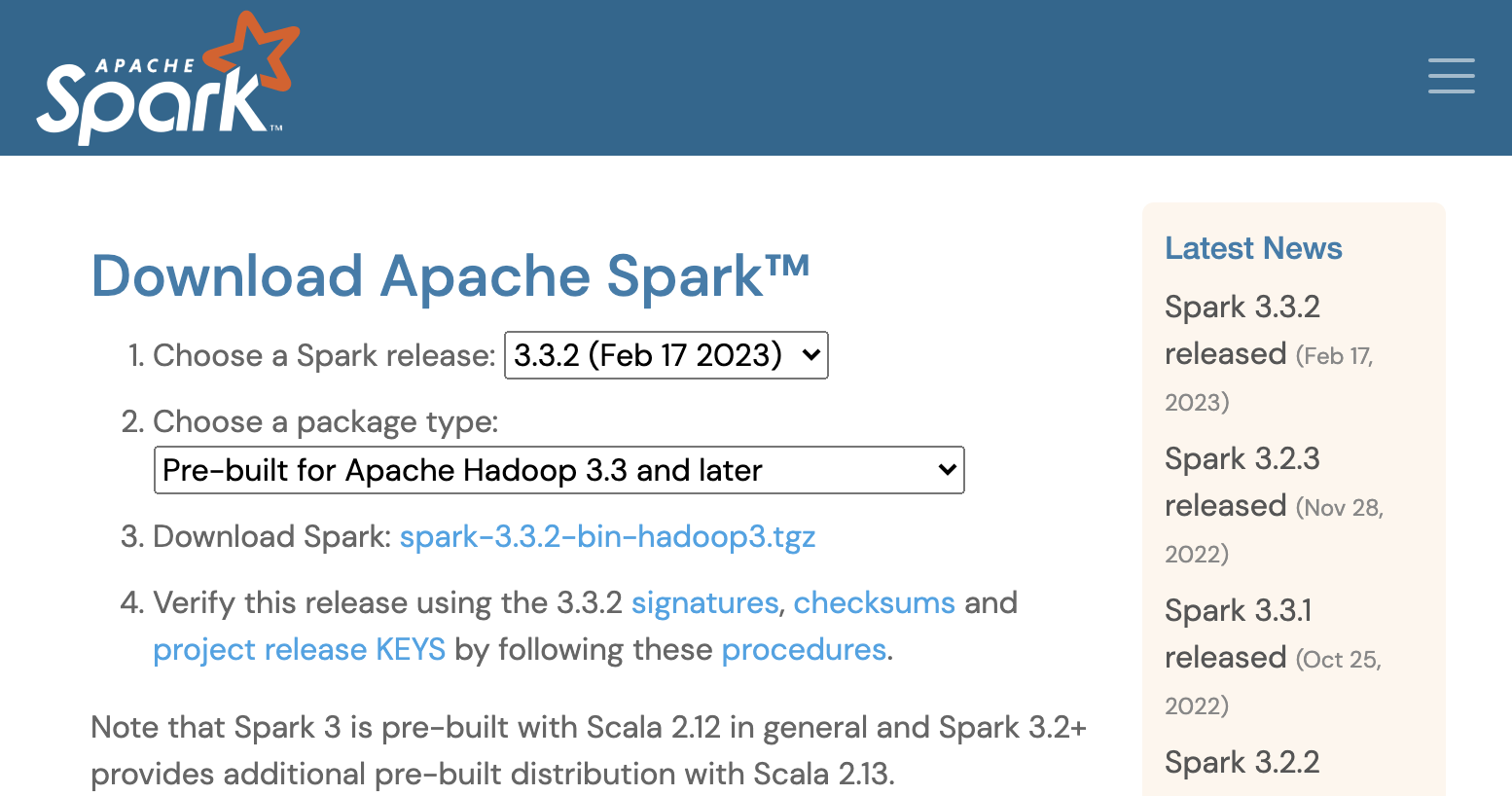
위와 같은 화면이 보이면 가장 최신 버전의 Spark를 설치하면 됩니다. (작성 시점에는 Pre-built for Apache Hadoop 3.3 and later를 선택했습니다.) 선택을 마쳤으면 3.Download Spark에 보이는 링크로 들어갑니다. (spark-3.3.2-bin-hadoop3.tgz)

하둡 설치 과정과 마찬가지로 상단에 보이는 링크를 복사해둡니다. (https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz) 그 후 wget 명령어를 이용해 다운로드한 후 압축을 풉니다.
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
tar -xvzf spark-3.3.2-bin-hadoop3.tgz그 후 vim ~/.zshrc 명령어를 통해 파일을 열고 아래 코드를 추가하여 경로 설정을 해줍니다. SPARK_HOME 경로는 압축해제한 스파크 폴더가 있는 경로를 넣어줍니다.
export SPARK_HOME=/Users/jangboyun/spark/spark-3.3.2-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin변경 후 변경사항이 제대로 반영되었는지 확인합니다.
source ~/.zshrc
echo $SPARK_HOME그 후 아래 명령어를 통해 스파크가 정상 작동되는지 확인합니다.
spark-shell아래와 같은 화면이 나오면 정상적으로 설치된 것입니다.
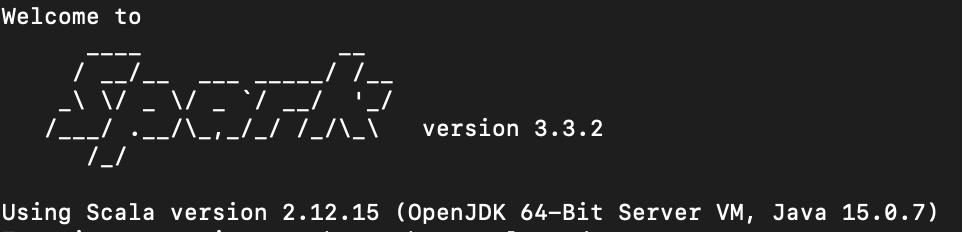
(2) localhost 설정
만일 spark-shell 명령어를 입력했을 때 Service 'sparkDriver' could not bind on a random free port.와 같은 에러메세지가 뜨면 먼저 아래 명령어를 입력했을 때 나오는 호스트명을 복사해둡니다.
hostname그 후 sudo vim /etc/hosts 명령어를 통해 /etc/hosts 파일에 관리자 권한으로 접근합니다. 여기서 기존의 127.0.0.1 localhost 위에 아래와 같이 한 줄을 추가합니다.
...
127.0.0.1 {아까 복사해둔 호스트명}
127.0.0.1 localhost
...수정 후 다시 spark-shell을 입력하면 정상 작동되는 것을 확인할 수 있을 것입니다.

좋은 포스트 감사합니다 ㅎㅎ 덕분에 도움 많이 됐어요! 좋은 하루 보내셨으면 합니다 ㅎㅎㅎ