I/O bound process:
- Time taken to complete a computation is primarily determined by period spent waiting for input/output operations to be completed.
CPU bound process:
- the rate at which process progresses is limited by speed of CPU.
Concurrent Execution
- Logical concept meaning that multiple processes progress in execution (at the same time)
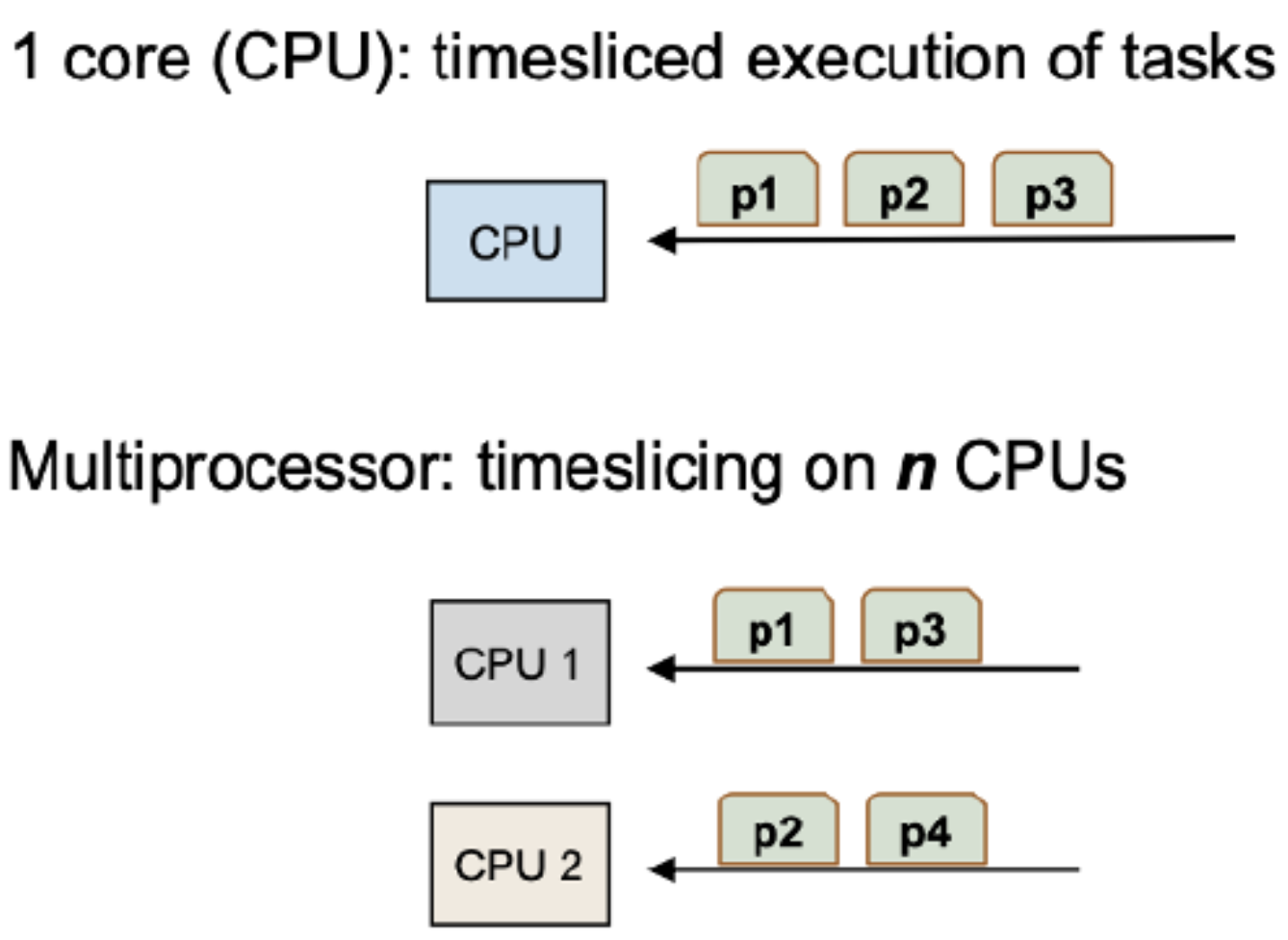
- Applies to both single core and multicore.
- Single core: virtual parallelism
- Multi core: physical parallelism
- Diagram below shows concurrent execution in single core CPU.
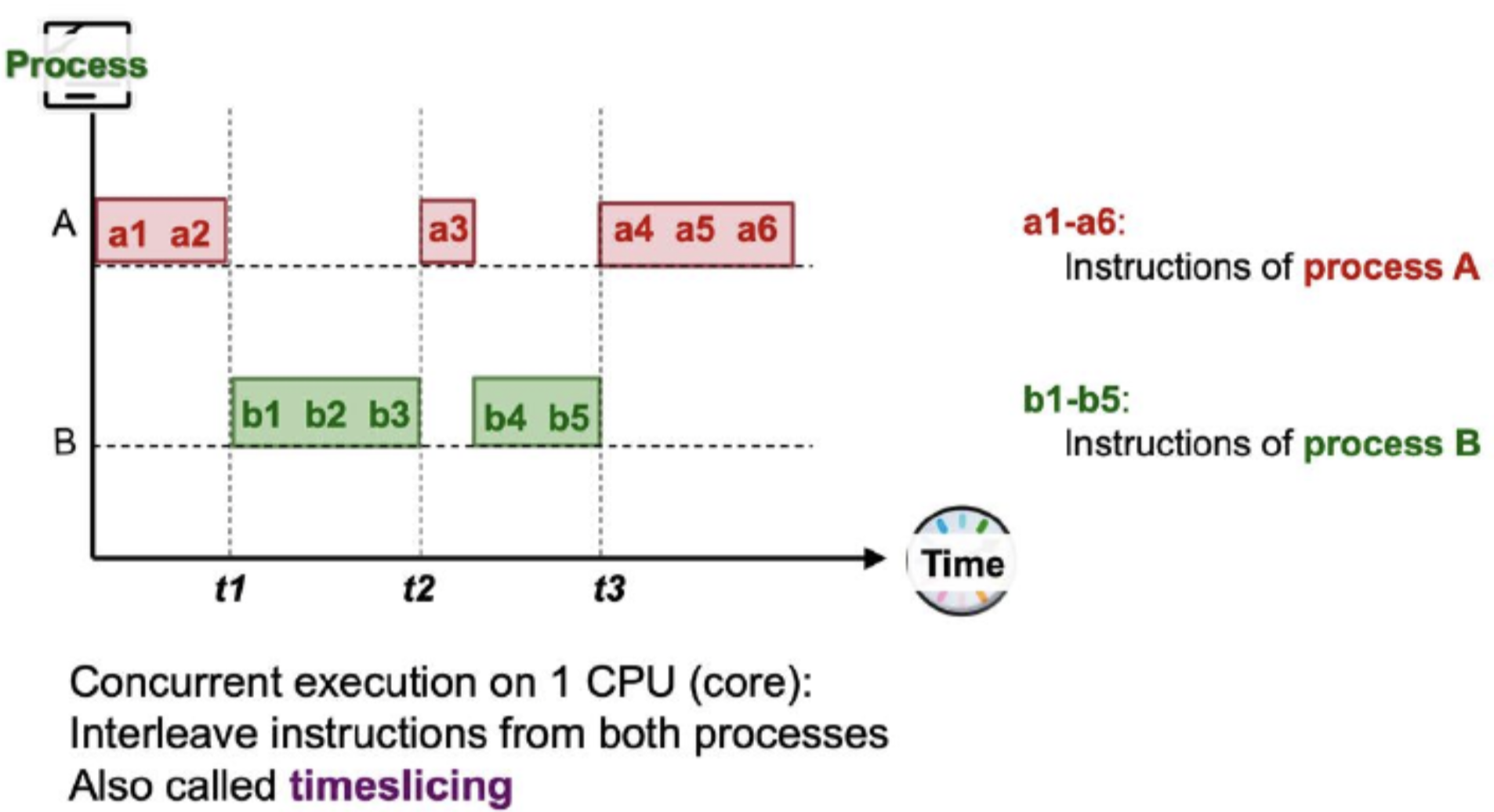
- Timeslicing: Allowing interleave of instructions from both processes
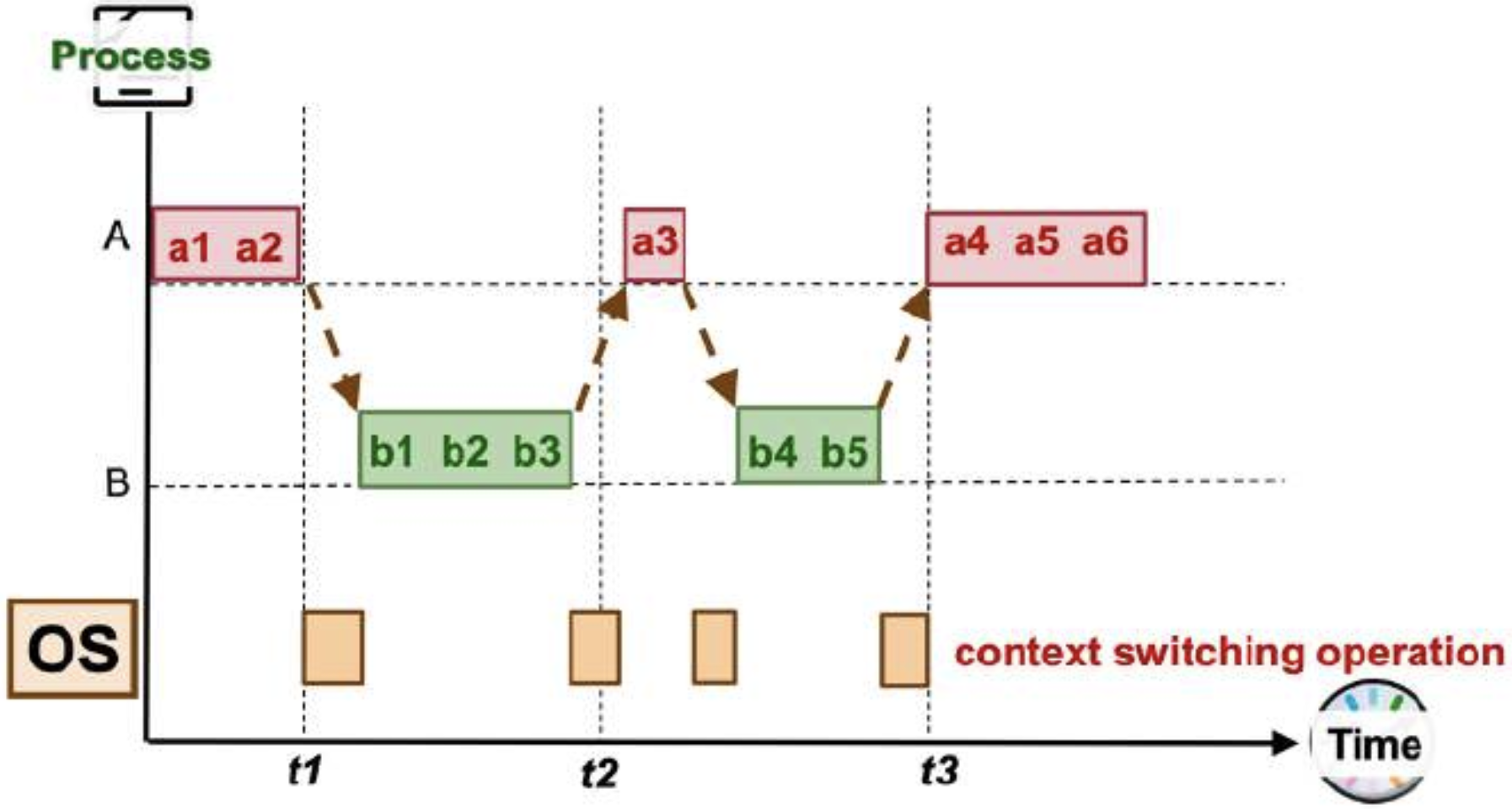
-
OS incurs overhead in switching context process between A and B.
-
Context Switching: Process of saving context of one process and loading context of another process (e.g., Ready → Running for one process and Running → Ready for another process)
-
Scheduling
- Scheduling is important when #ready-to-run processes > #CPUs.
- Each process has process behavior and requires different amounts of CPU time - one factor that influences scheduling.
- A process typically goes through phases of:
- CPU-Activity
- ex) computation, number crunching, compute-bound process
- I/O-Activity
- E.g., print to screen, read from file, etc.
- Another factor of influence is process environment:
- Batch processing:
- No user interaction may be needed.
- No need to be responsive.
- This job is very easy to schedule.
- Interactive:
- Active user interaction may be needed.
- Must be responsive, consistent in response time.
- e.g Microsoft Word. Letters should show up when typing.
- Real time processing:
- for some processes, deadlines should be met.
- Tasks are usually periodic: recurring and repetitive.
- Batch processing:
Criteria for Scheduling
- Fariness:
- Should get a fair use of CPU time (per process basis) OR (per user basis for multi-users)
- No Starvation (When high priority processes keep executing and low priority processes get blocked for indefinite reason)
- Utilization/Balance:
- All parts of computing system should be utilized,
- to effectively allocate resources, balance workloads, minimize bottlenecks, and maximize the overall efficiency and performance of the system.
Scheduling Policies
- Non-preemptive (Cooperative)
- A process stayed scheduled until:
- It blocks OR gives up CPU voluntarily
- Usually for Batch systems.
- Preemptive
- A process is given fixed time quota (CPU time) to run (possible to block or give up early)
- At the end of time quota, another ready process gets picked if available
Scheduling Procedure:
- Scheduler is triggered (OS takes over)
- If context switch is triggered, context of current running process is saved and placed on blocked queue /ready queue
- Pick a suitable process P to run based on scheduling algorithm
- Setup context of P
- Let p run
Scheduling for Batch Processing
- Scheduling algorithms are easier to understand
- Criteria for batch processing scheduling algo:
- Turnaround time: Total time taken (finish time – arrival time)
- this is related to waiting time, because time spent to compute one process means waiting time for other processes back in line.
- Execution time is usually constant, while waiting time can be varied depending on the scheduler.
- Waiting time: Time process waits while on queue
- Throughput: Number of tasks finished per unit of time (rate of task completion)
- CPU utilization: Percentage of time when CPU is working on task (no idle CPU).
- Turnaround time: Total time taken (finish time – arrival time)
1. First-Come First-Served: FCFS
- Tasks are stored in FIFO queue based on arrival time.
- Pick first task based on queue to run until:
- Task is done or blocked
- Blocked tasked is removed from FIFO queue
- When it is ready again, placed to back of queue
Advantages:
- Guaranteed to have no starvation: The number of tasks in front of task X in FIFO is always decreasing (will eventually reach task X)
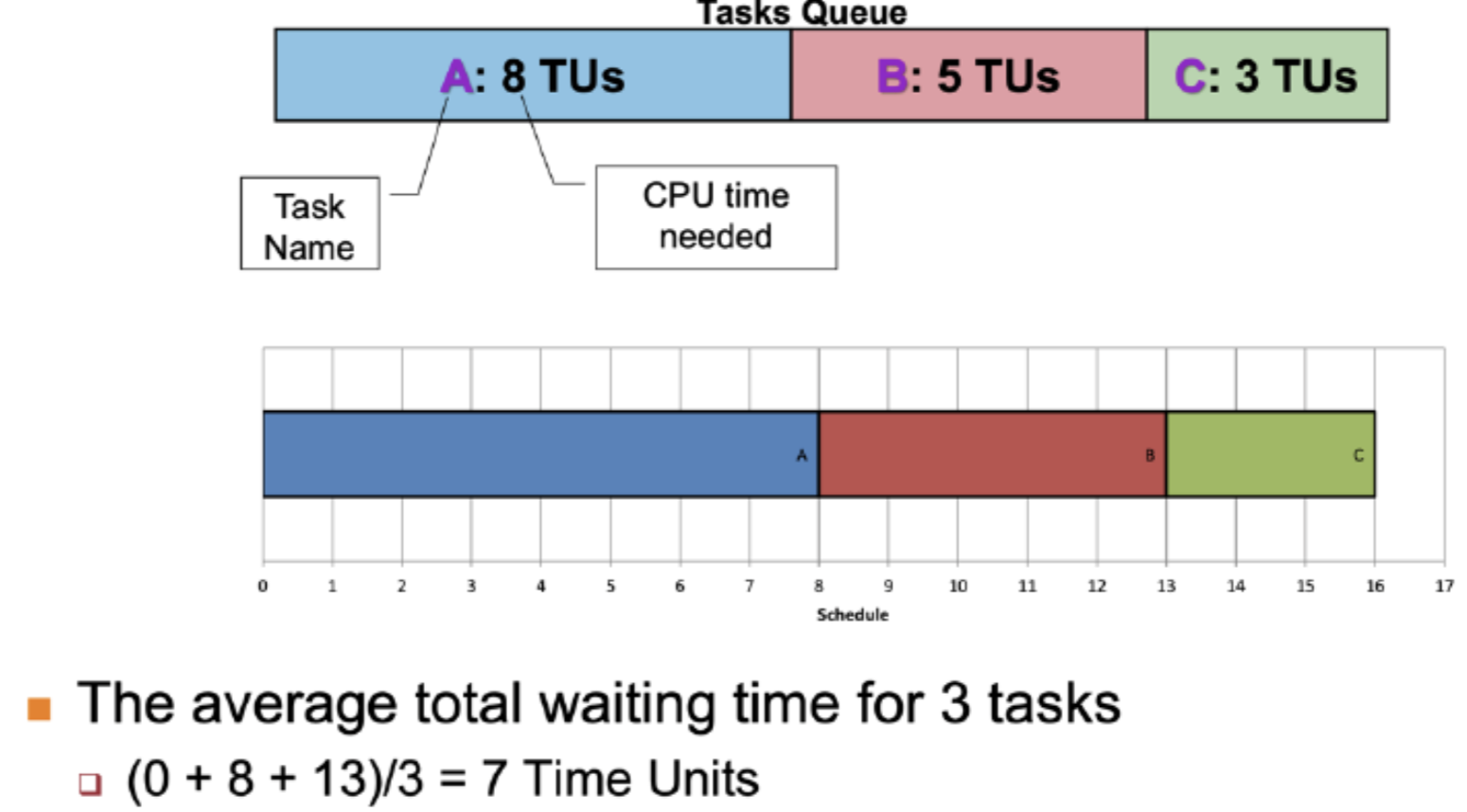
Disadvantages:
- If there is a long task infront, the waiting task behind will have to wait time(A) to finish.
- Average waiting time is higher
- Convoy effect:
- Suppose A is a cpu bound process, and there are Xs which are I/O bound,
- While A is being computed, Xs have to wait, making I/O idle,
- When A is blocked on I/O, then the Xs does the CPU computations which end fast, then they get blocked on I/O, making CPU idle,
- This repeats with the Xs following after the process A, just like a convoy.
2. Shortest Job First: SJF
- Select task with smallest CPU time
- Notes:
- Need to know total CPU time for a task in advance
- Starvation is possible: Biased towards short jobs, long jobs may never get a chance
- CPU time could be predicted using Exponential Moving Average (EMA).

Actual = Most Recent CPU time consumed
Predicted(n) = Past history of CPU time consumer
a = Weight Placed on recent event or past history
Predicted(n+1) = Latest Prediction
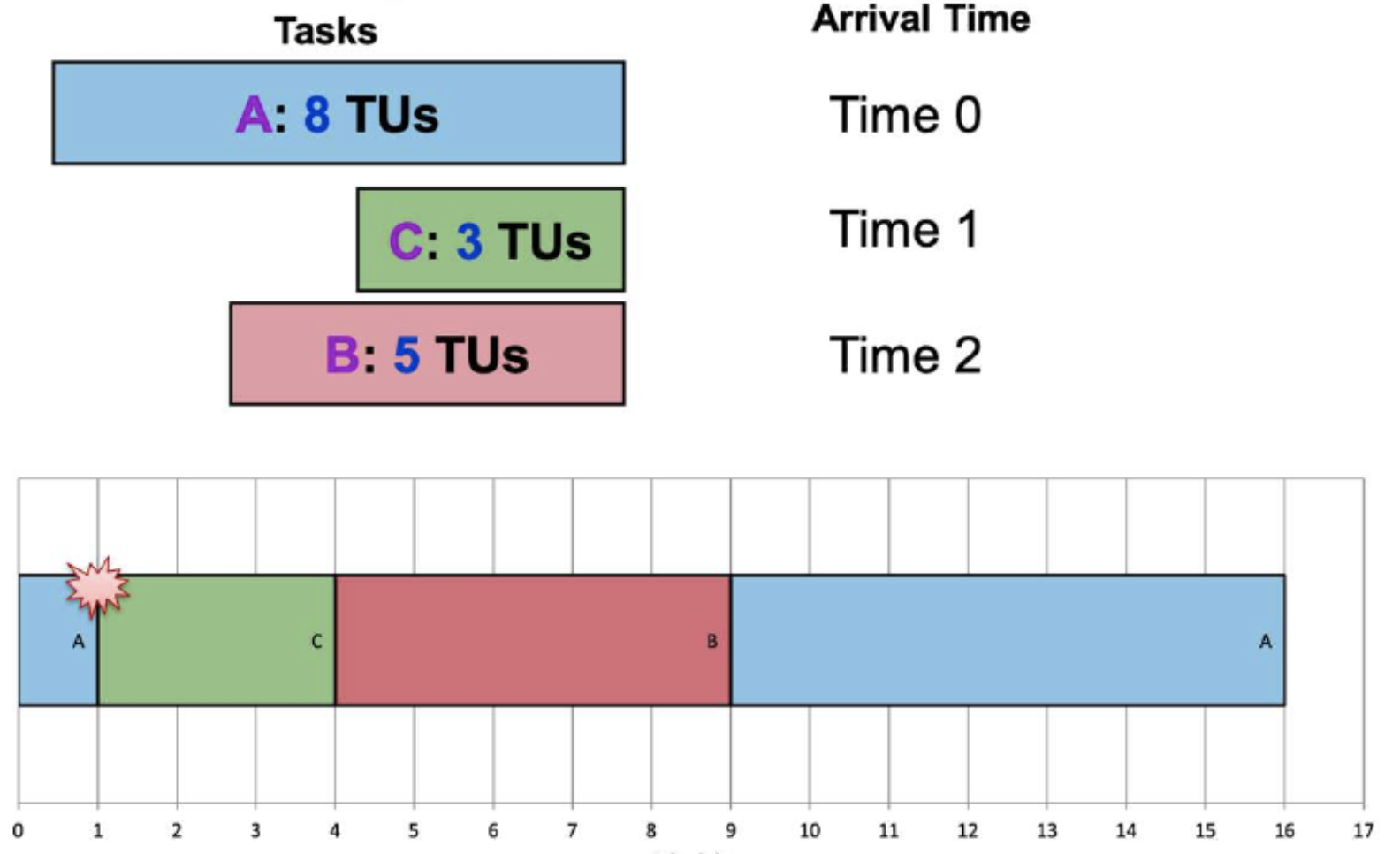
3. Shortest Remaining Time: SRT
-
Variation of SJF:
- Use remaining time
- Preemptive
-
Select job with shortest remaining (or expected) time
-
Notes:
- New job with shorter remaining time can preempt currently running job
- Provide good service for short job even when it arrives late
-
Issue:
- Starve long running process
Scheduling for Interactive System
- Criteria for interactive environment
- Response time:
- Response Time = FirstRun Time - Arrival Time
- Time between request and response by system
- Response time is the time spent between the ready state and getting the CPU for the first time. But the waiting time is the total time taken by the process in the ready state.
- Predictability:
- Variation in response time, less variation -> More predictable
- Response time:
- Preemptive scheduling algorithms are used to ensure good response time
- the CPU scheduler has the ability to interrupt and suspend the execution of a running process to allocate the CPU to a higher-priority process.
- Scheduler needs to run periodically:
- Timer interrupt = Interrupt that goes off periodically (based on hardware clock)
- OS ensure timer interrupt cannot be intercepted by other program
- Timer interrupt handler invokes schedule
Terminology: Timer and time quantum
- Interval of timer interrupt (ITI):
- OS scheduler is triggered every timer interrupt
- duration between successive timer interrupts used by the scheduler to make scheduling decisions
- Typical values (1ms to 10ms)
- Time Quantum
- Execution duration given to a process
- Could be constant or variable among the processes
- Must be multiple of interval of timer interrupt (WHY??)
- Large range of values (Commonly 5ms to 100ms)
- IF Time lapsed >= Time Quantum -> Change process (Context Switch)
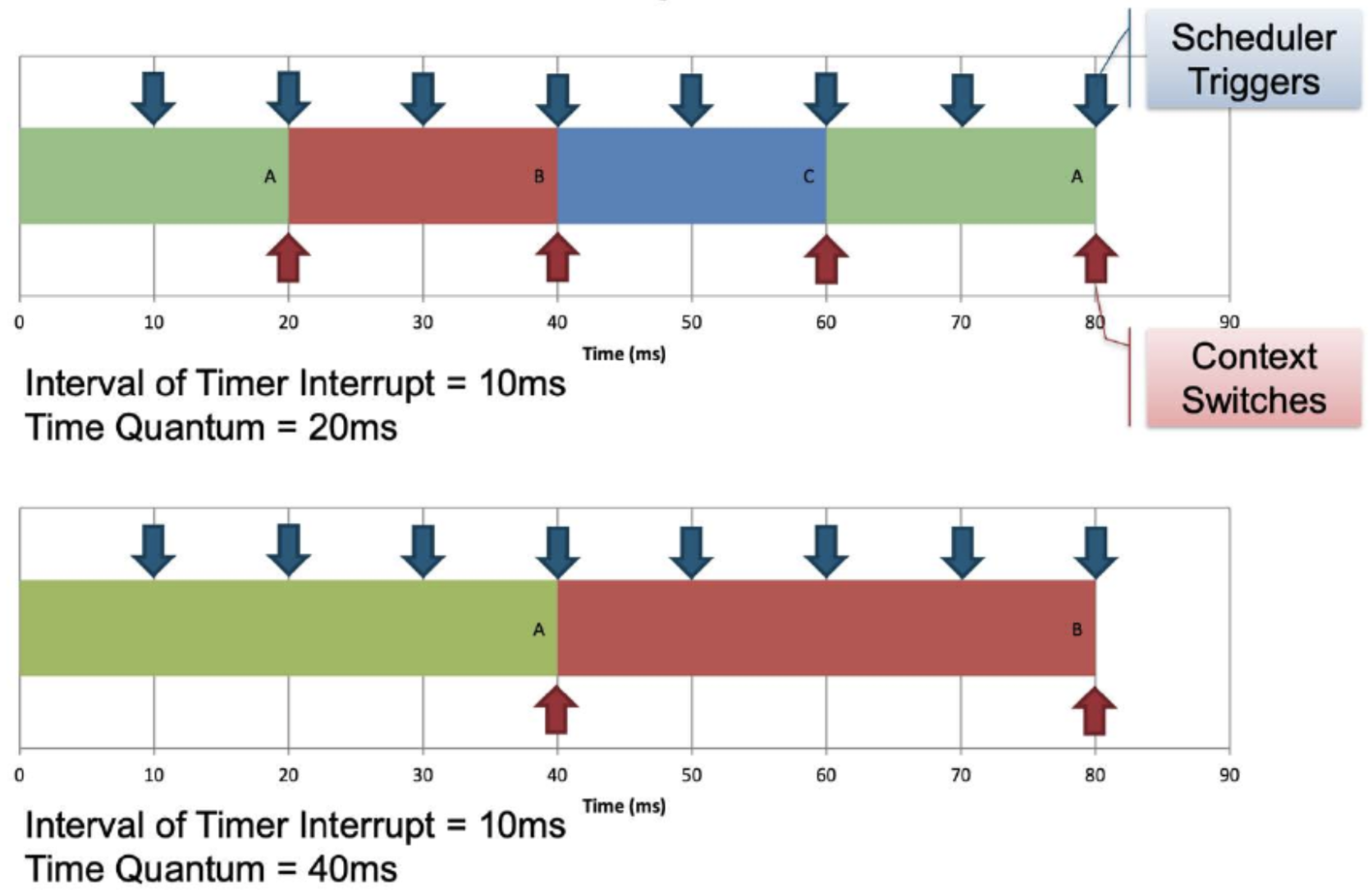
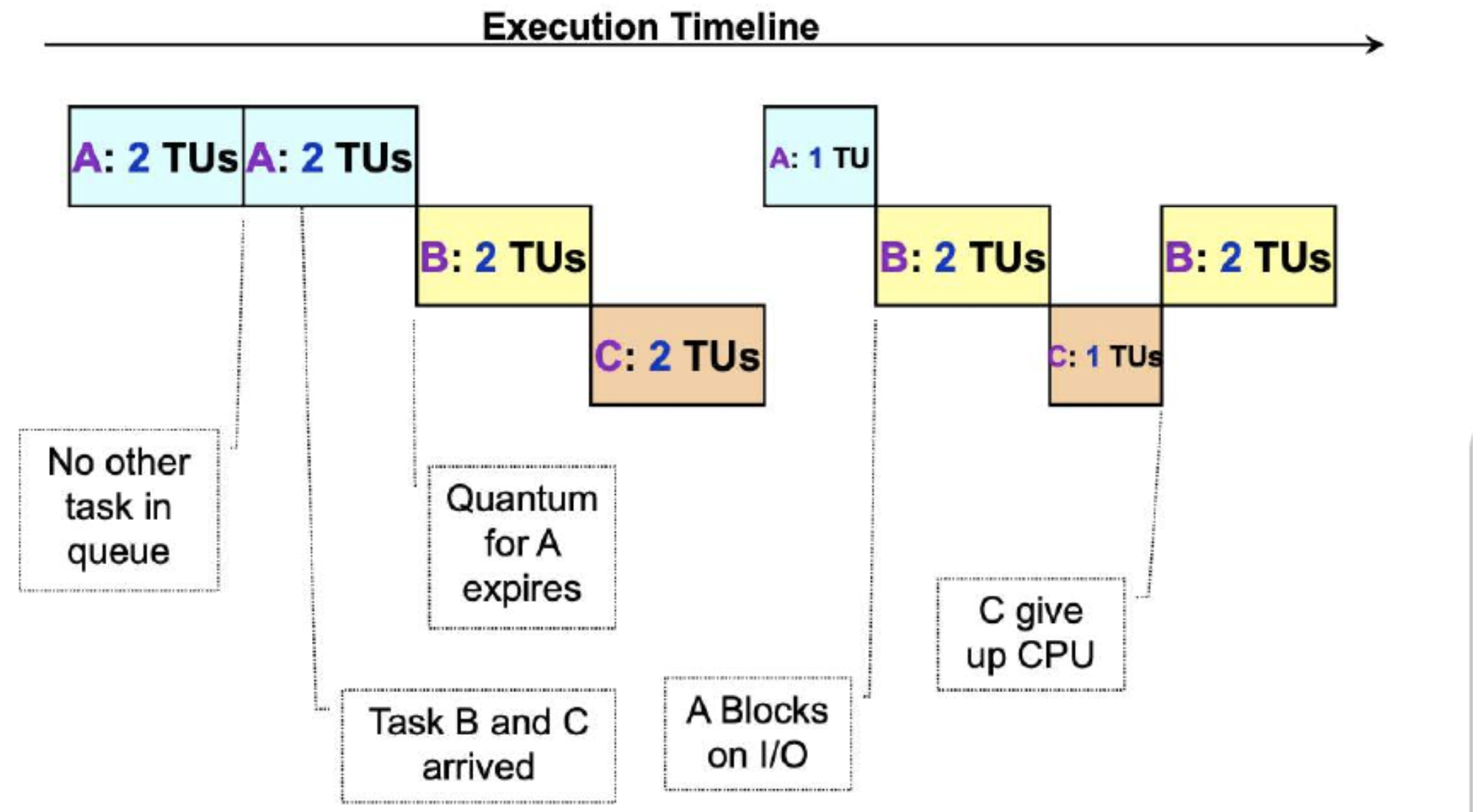
1. Round Robin
- Tasks are stored in FIFO queue (First-in first-out)
- Pick the first ask from queue front to run until:
- A fixed time slice elapsed (quantum elapsed) or,
- Task gives up the CPU voluntarily or,
- Task blocks
- If task is undone, the task is placed at the end of queue to wait for another turn.
- Blocked task will be moved to other queue to wait for its requested resource
- When blocked task is ready again, it is placed at the end of queue
- Notes:
- Preemptive version of FCFS
- Response time guarantee:
- Given n tasks and quantum q, Time before a task get CPU is bounded by (n-1)q
- Time interrupt needed: for scheduler to check on time quantum (ChatGPT says not??)
- The choice of time quantum is important:
- Too big quantum: Better CPU utilization but longer waiting time
- Too small quantum: Bigger overhead (worse CPU utilization) but shorter waiting time, reducing the time quantum increases the amount of CPU time spent by the OS performing context-switching, reducing throughput and increasing the average turnaround time
2. Priority Scheduling
- General Idea:
- Some processes are more important than others.
- Assign a priority value to all tasks.
- Select task with highest priority value.
- Variants:
- Preemptive version:
- Higher priority process can preempt running process with lower priority
- Non-preemptive version:
- Late coming high priority process has to wait for next round of scheduling
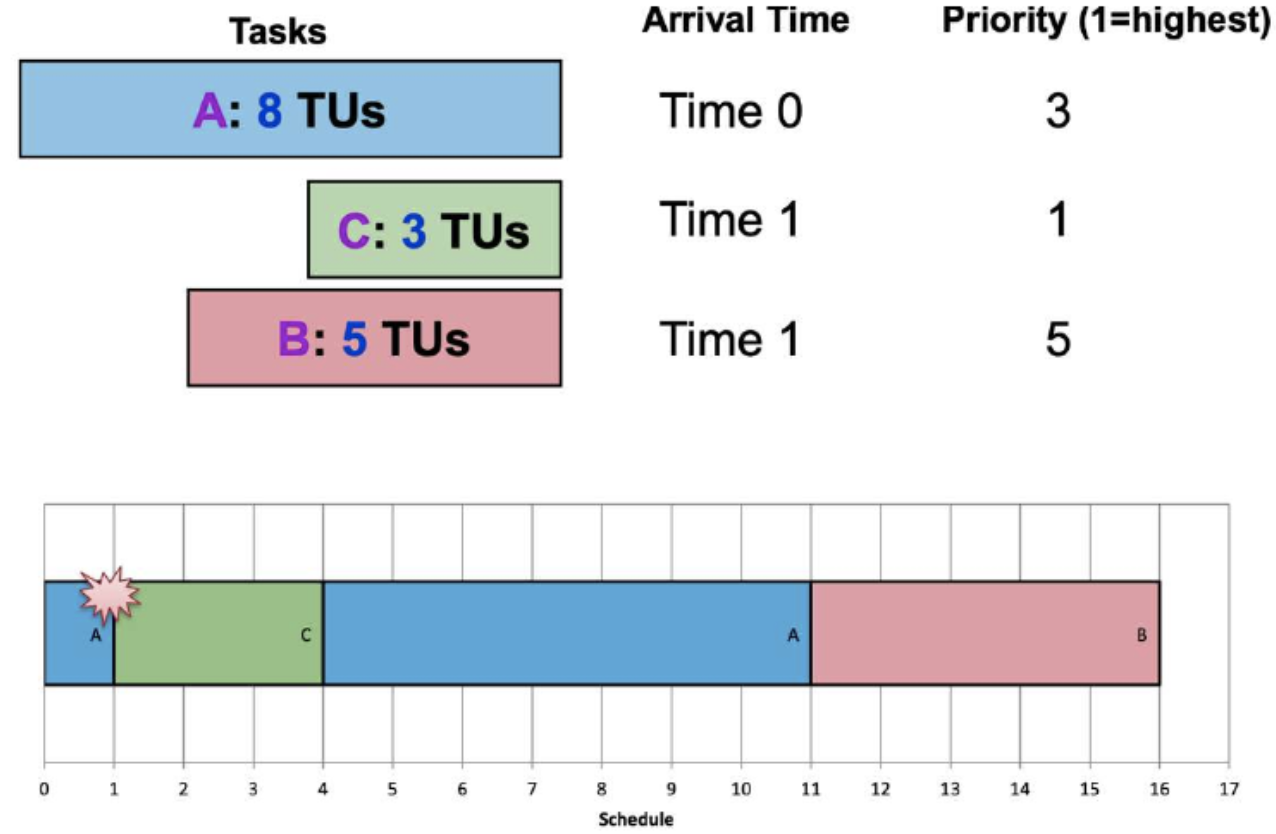
- Preemptive version:
- Problems:
- Low priority jobs can starve:
- High priority process keeps using CPU
- Worse in preemptive variant (because high priority process can keep coming in)
- Priority Inversion:
- Mutex Lock: Synchronisation mechanism for mutual exclusion by locking the resource when one process is using it.
- Let's say there are LP, MP, HP (low priority, medium, and high)
- When a LP process is using the resource, HP process may try to preempt,
- but the resource is not unlocked, leaving the HP on wait till lower priority process releases the resource.
- meanwhile, MP can continue being executed - so MP finishes faster than HP!
- This makes lower priority tasks get done before higher priority tasks.
- Hard to guarantee or control the exact amount of CPU given to a process using priority (I don't get it?)
- Possible solutions:
- Decrease priority of each time a process gets a chance to run.
- Give currently running process a time quantum.
- Low priority jobs can starve:
3. Multilevel feedback queue (MLFQ)
- Adaptive: Learn the process behavior automatically to assign the process priorities.
- A new process is run, and its behavior is observed,
- if the process is CPU bound, then its priority is lowered;
- if it is I/O bound, the priority is increased.
- Minimizes both:
- Response time for IO bound processes
- Turnaround time for CPU bound processes
- Basic Rules:
- If Priority(A) > Priority(B) -> A Runs
- If Priority(A) == Priority(B) -> A and B runs in Round Robin
- Priority Setting/Changing rules:
- New job -> Highest Priority
- If a job fully utilized its time quantum -> priority reduced
- If a job gives up/blocks before finishes its time quantum -> priority retained
4. Lottery Scheduling
- Give out “lottery tickets” to processes for various system resources
- When a scheduling decision is needed: A lottery ticket is chosen randomly among eligible tickets
- The winner is granted the resource
- In the long run, a process holding X% of tickets
- Can win X% of CPU time
- Benefits:
- Responsive: A newly created process can participate in next lottery (Response time is low)
- Provides good level of control:
- A process can be given Y lottery tickets (then can distribute to child process)
- An important process can be given more lottery tickets (can control proportion of usage)
- Each resource has its own set of resource (different proportion of usage per resource per task) (I DON'T GET THIS)
- Simple implementation
Inter-process Communication
- Memory spaces for processes are independent to each other.
- This makes it hard for cooperation process to share information (e.g. sockets, pipes, or message queues)
- IPC is needed.
- IPC provides mechanisms for processes to communicate and transfer data across process boundaries, overcoming the memory isolation enforced by the operating system.
- IPC mechanisms:
- Shared Memory
- Message Passing
- Unix Mechanisms:
- pipe
- signal
Shared Memory
- Process P1 creates a shared memory region M
- Process P1 and P2 attach memory region M to its own memory space
- P1 and P2 can now communicate using memory region,
- M behaves very similar to normal memory region
- Any writes to region are visible to other process
- Same model is applicable to multiple processes sharing the same memory region
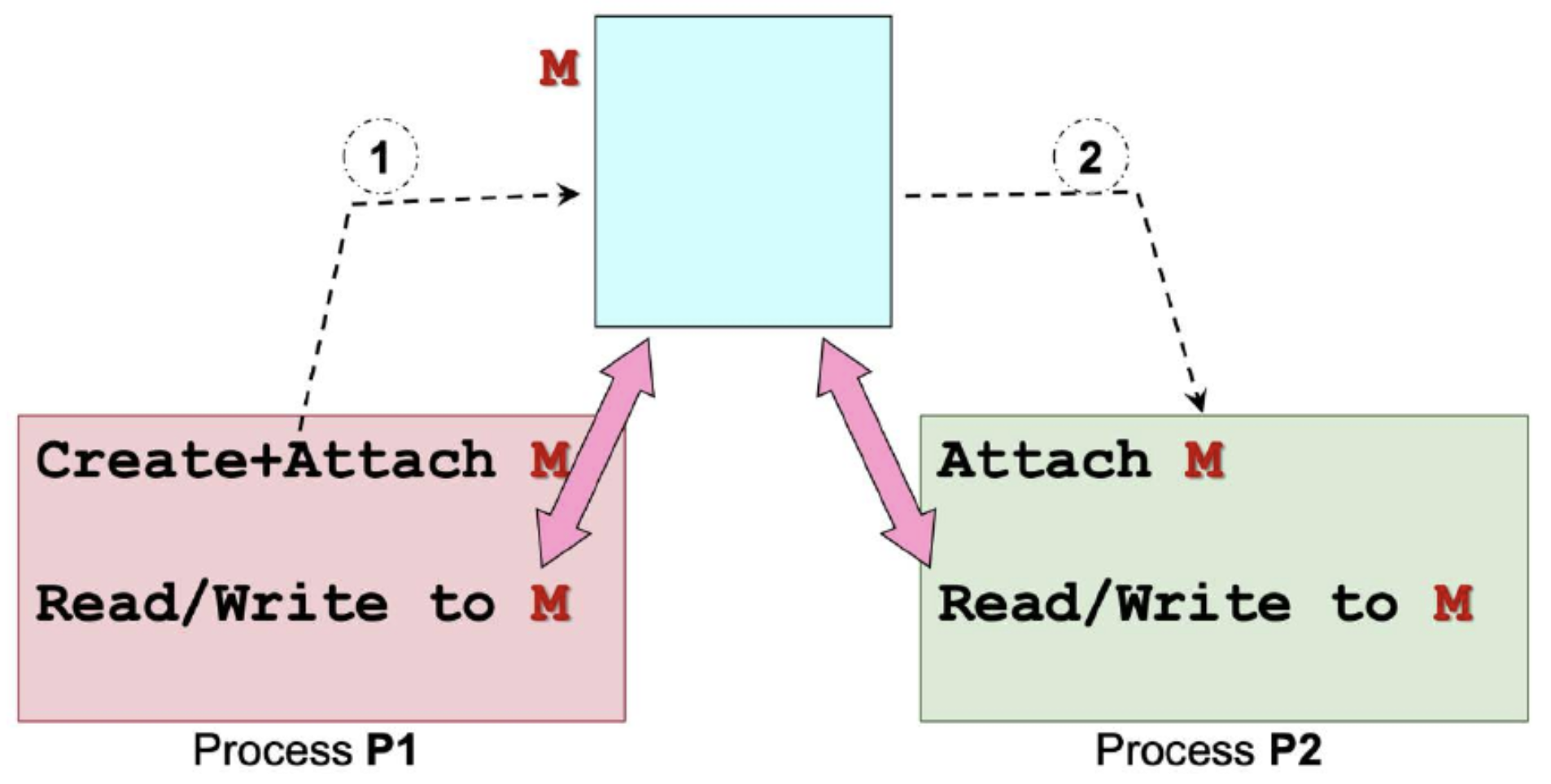
POSIX Shared Memory in Unix/Linux
-
Create/locate a shared memory region M
-
Attach M to process memory space
-
Read from/write to M
a. Values written visible to all process that share M -
Detach M from memory space after use
-
Destroy M
a. Only one process need to do this
b. Can only destroy if M is not attached to any process

-
Master program keeps on checking if the shared memory space is filled; else the while loop makes the program keep checking it.

-
Advantages of shared memory:
- Efficient: Only creating and attaching shared memory region involves OS. Reading and writing is done without OS.
- Ease of Use: Shared memory region behaves the same as normal memory space i.e., information of any type or size can be written easily
-
Disadvantages:
- limited to single machine
- Requires synchronization:
- order matters here, because if a process reads or writes a value, another process must not at the same time.
- This is called race condition: processes race to get the data - ending up messing up the data.
- Synchronization is hard to implement.
Message Passing
- Process P1 prepares a message M and sends it to Process P2
- Process P2 receives the message M
- Message sending and receiving are usually provided as system calls
- Properties:
- Naming: Required to identify sender and receiver processes
- Synchronization: Receiver process may block until it receives the message.
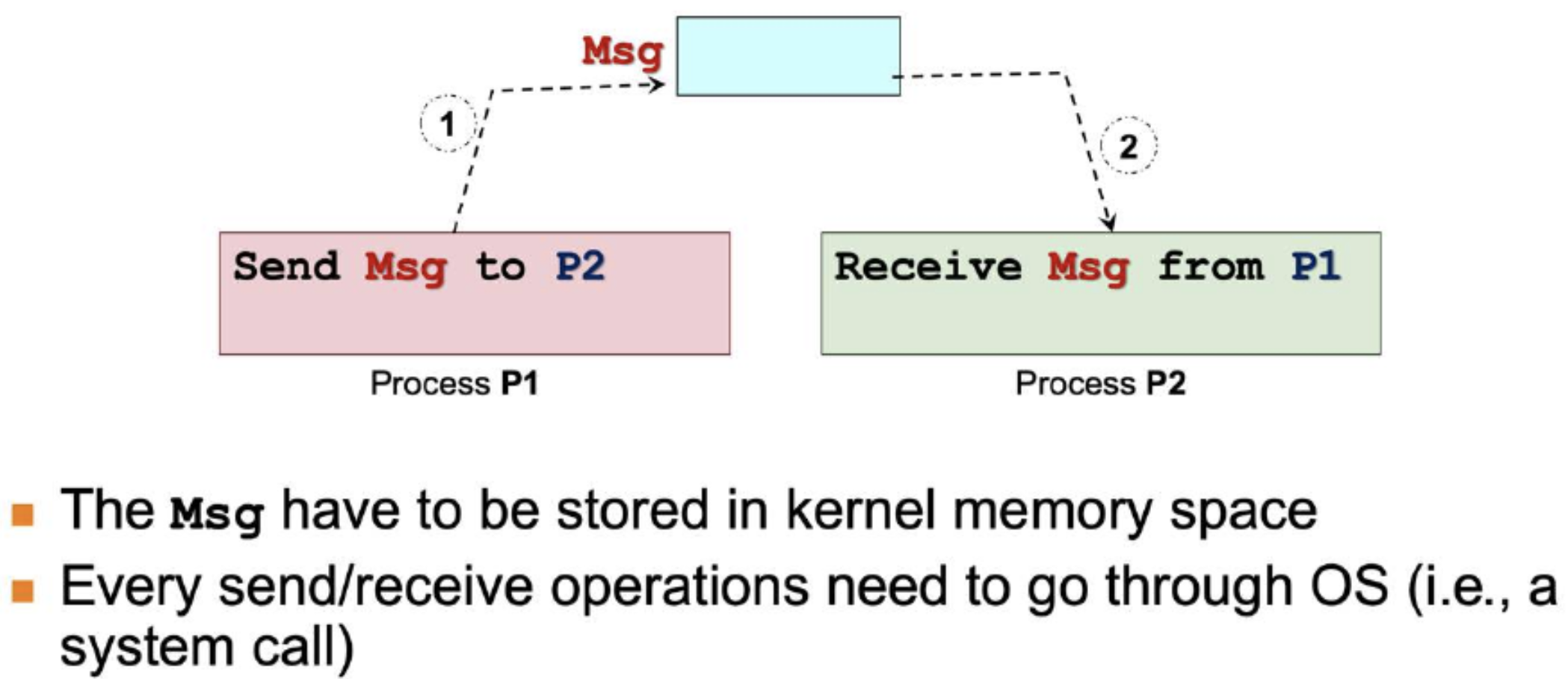
Naming Scheme: Direct Communication
- Sender/Receiver of message explicitly name the other party
- Unix: Unix domain socket
- Example:
- Send (P2, Msg): Send to Process P2
- Receive (P1, Msg): Receive from Process P1
- Characteristics:
- One link per pair of communicating processes
- Need to know the identity of other party
Naming Scheme: Indirect Communication
- Message are sent to / received from message storage:
- Usually known as mailbox or port
- Unix: message queue
- Example:
- Send (MB, Msg): Send message to Mailbox MB
- Receive (MB, Msg): Receive message from Mailbox MB
- Characteristics:
- One mailbox can be shared among a number of processes
- (asynchronous)
Synchronization behaviors for Message Passing
- Blocking Primitives (Synchronous):
- Send(): Sender is blocked until message is received.
- Receive(): Receiver is blocked until a message has arrived
- Non-Blocking Primitives (Asynchronous)
- Send(): Sender sends messages in buffers and continues execution.
- Receive(): Receiver is blocked until a message is sent, later takes messages from buffers. Doesn't take if not available.
- Finite buffer size makes it not truly asynchronous.
- Message buffers: Intermediate buffers between sender and receiver in asynchronous (indirect) communication. Under OS control so no synchronization necessary. User declares in advance the capacity of the mailbox.
Message Passing Pros and Cons
- Advantages:
- Portable: can easily be implemented on different processing environment, e.g, distributed system, wide-arm network
- Easier synchronization (when synchronous primitive is used), sender and receiver are implicitly synchronized
- Disadvantages:
- Inefficient
- Extra copying (unlike shared memory space, message needs to be copied to the receiver.)
- Usually requires OS intervention
- Inefficient
Unix: Pipes
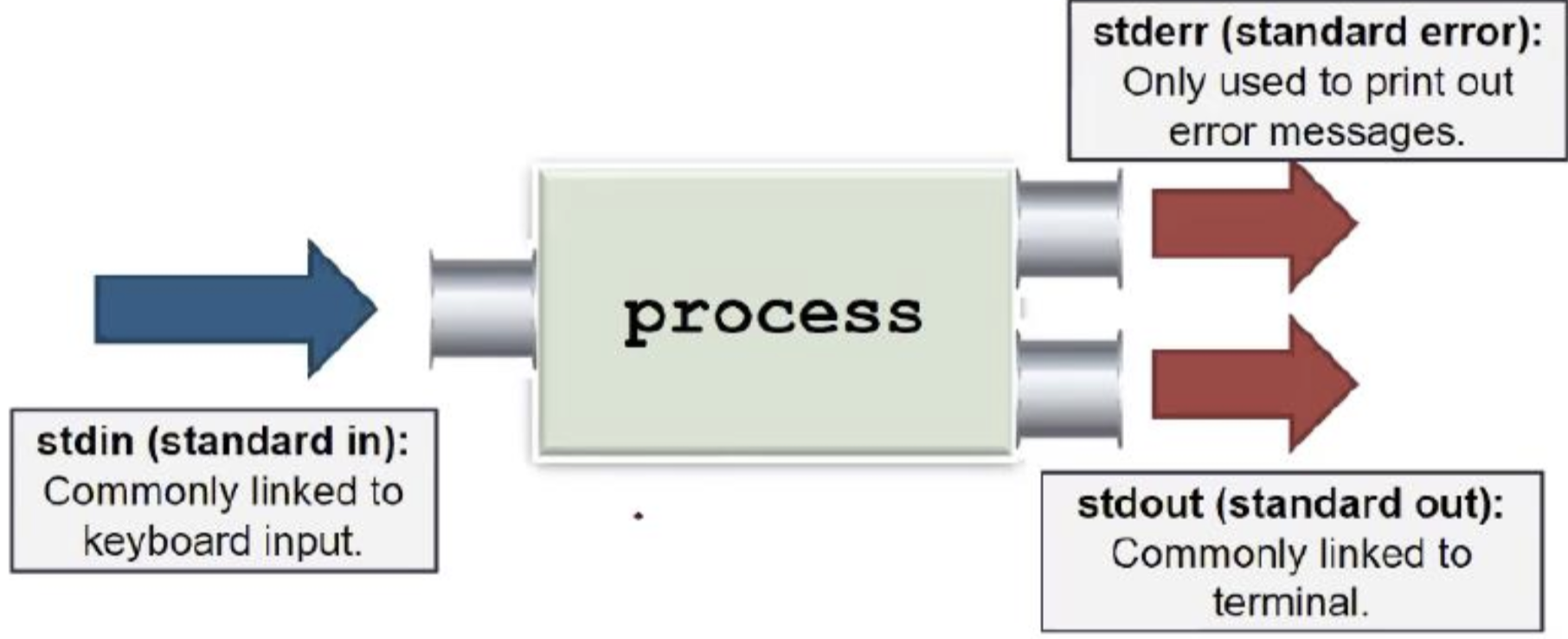
In C: printf() uses stdout, scanf() uses stdin
Piping in Shell:
- “|” is used to link the input/output channels of one process to another
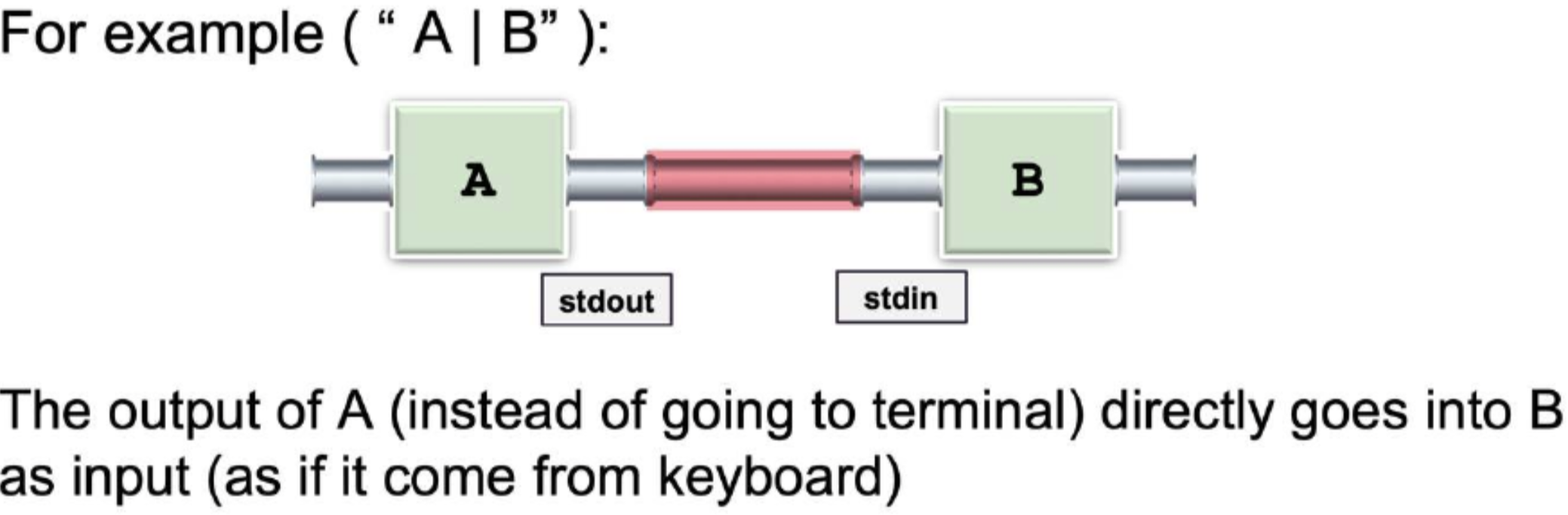
Notes:
-
A communication channel is created with 2 ends
-
“|” is used to achieve this mechanism internally

-
A pipe can be shared between two processes
-
A form of Producer-Consumer relationship

-
(Will follow FIFO)
-
Pipe functions as circular bounded byte buffer with implicit synchronization:
- circular bounded byte buffer means that when a buffer is full, a new data overwrites the oldest data in the buffer.
- Writers wait when buffer is full, and readers wait when buffer is empty.
From ChatGPT:
- When a pipe is full, the behavior depends on the type of pipe being used:
- Ordinary Pipe (Anonymous pipe):
- pipe's buffer is full, the write operation blocks (waits) until space becomes available.
- "Anonymous" because it is not associated with specific file system entry or name.
- Can be used for two related processes.
- Synchronized: Writers wait when buffer is full, and readers wait when buffer is empty.
- Named Pipe (FIFO):
- If a named pipe's buffer is full, the write operation overwrites the oldest data.
- continuous data flow

- Ordinary Pipe (Anonymous pipe):
- Returns:
- 0 to indicate success; !0 for errors
- An array of file descriptors is returned:
- file descriptor is a notation that denotes a certain file or socket.
- Fd[0] == reading end
- Fd[1] == writing end
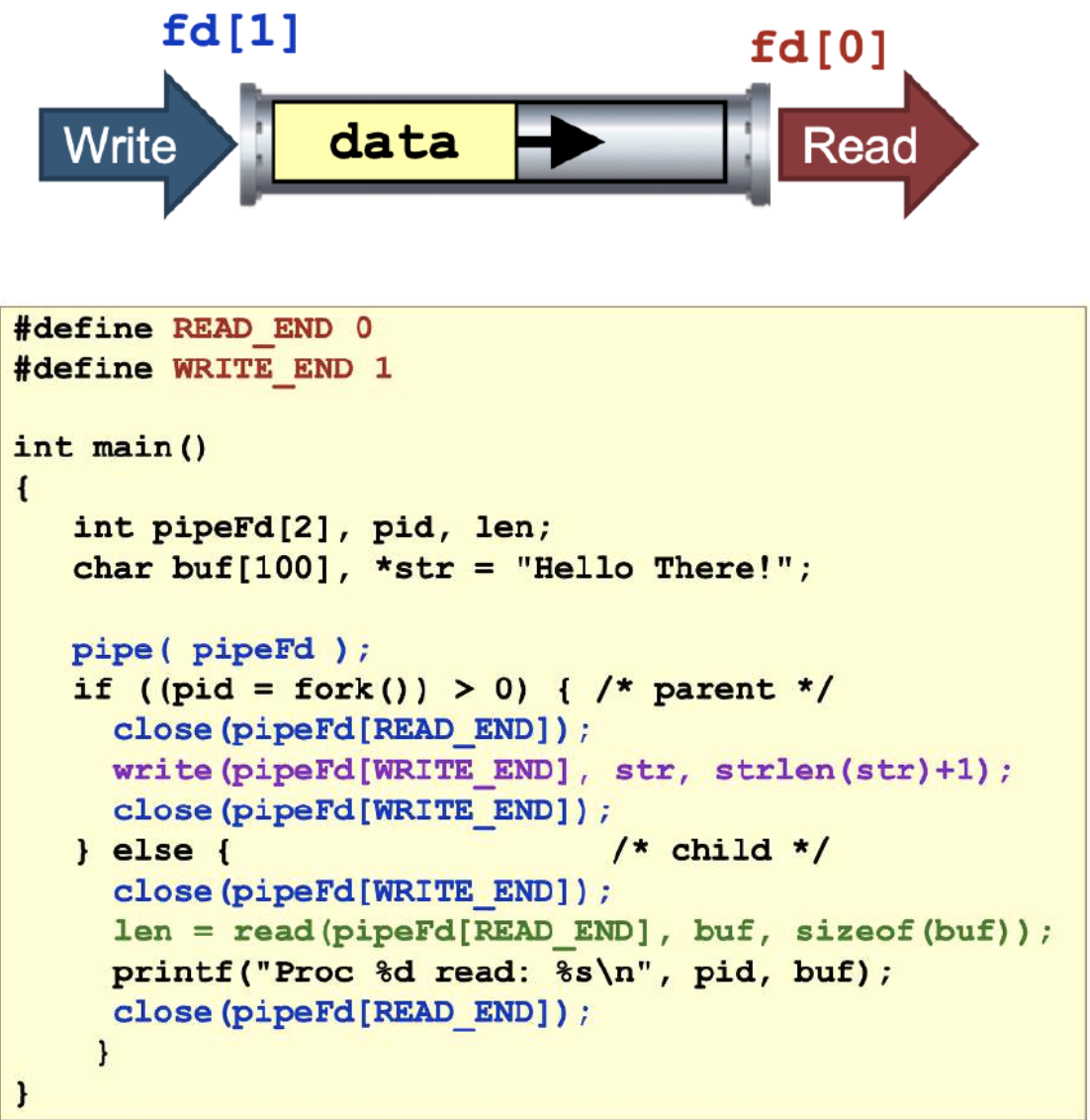
Note:
- close() is used to signal the blocked process that a file is sent: in other words, end-of-file (EoF) is signalled.
- or else the program will be on a deadlock and wait indefinitely.
- pipeFd array must have size 2 to include READ_END and WRITE_END
Variants
- Can have multiple readers/writers. Normal shell pipe has 1 writer, 1 reader
- Depends on UNIX version, pipes may be half-duplex
- Unidirectional: with one write end and one read end
- Or full-duplex, meaning communication can occur in both directions at the same time.
Unix: Signal
- A form of inter-process communication
- An asynchronous (other process not expecting signal) notification regarding an event
- Sent to a process/thread
- The recipient of signal must handle the signal by
- Default set of handlers, OR
- User supplied handler
- Common signals example in Unix:
- Kill, Interrupt, Stop, Continue, Memory error, Arithmetic error, etc…

- Kill, Interrupt, Stop, Continue, Memory error, Arithmetic error, etc…
