
🧑🏻💻 데이터프레임(DataFrame)
import numpy as np
import pandas as pd
dates= pd.date_range('20130101',periods=6) # 1월 1일부터 6일까지
df=pd.DataFrame(np.random.randn(6,4), index=dates, columns=['A','B','C','D'])
# 랜덤한 숫자로 6x4 행렬, 인덱스는 dates, 각 열은 'A,B,C,D'
df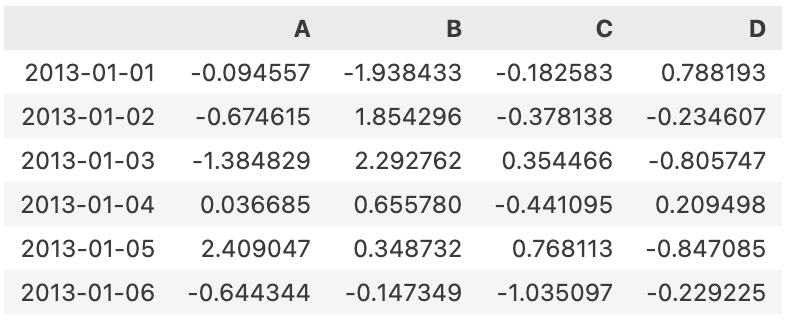
df.info() # 각 열에 대한 정보와 데이터 타입 불러오기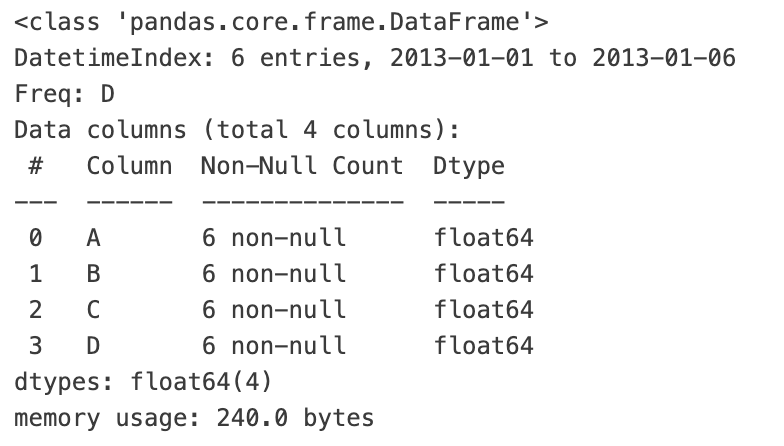
df.decribe() # 각 열의 여러 값들 표현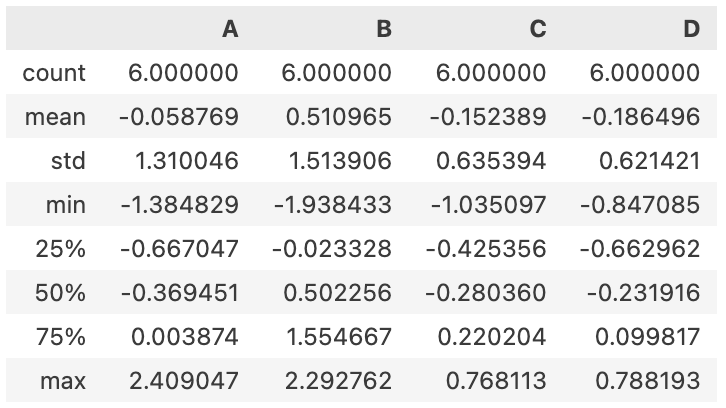
df.sort_values(by='B',ascending = False)
# B 열의 최댓값부터 나열한다.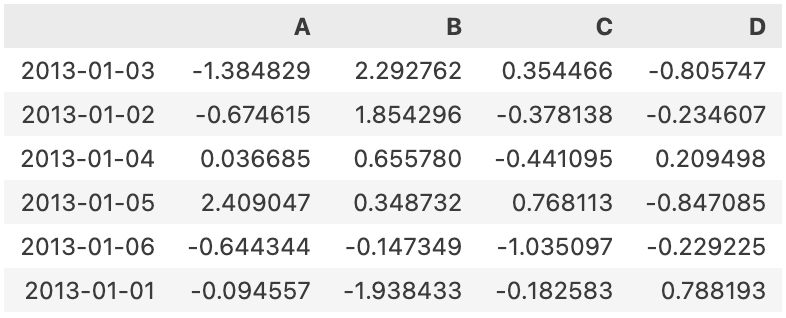
df.loc['20130102':'20130104', ['A','B']]
# loc을 이용해 특정 범위를 지정해서 볼 수 있다.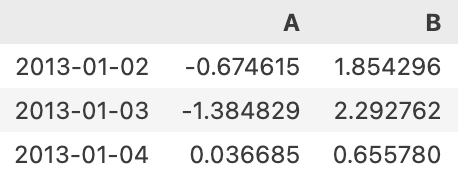
df.iloc[[0,4,2],[1,0]]
# iloc을 이용해 순서까지 바꿔서 원하는 행과 열을 확인할 수 있다.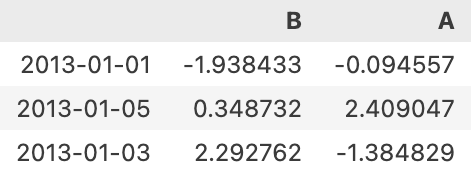
df[df["A"]>0]
# A열에서 0보다 큰 행만 출력하는 조건을 걸 수 있다.
-
열 추가하기
df["E"] = ["one","one","two","three","four","three"] -
특정 값을 찾고 싶을 때
df['column'].isin(['value1','value2']) -
특정 컬럼을 삭제하고 싶을 때
del df['column'] -
함수를 적용하고 싶을 때 (예시 : 누적합
np.cumsum)
df.apply(np.cumsum)
merge를 이용해 병합하기
left = pd.DataFrame(
{
'key':['K0','K4','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
}
)
right = pd.DataFrame(
{
'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],
}
)left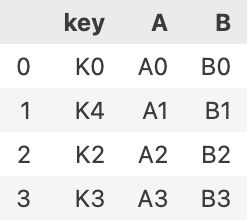
right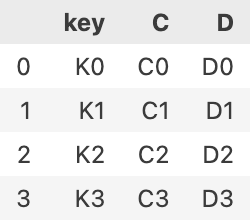
# key에 동일한 값이 있을 행만 합침
pd.merge(left,right, on='key')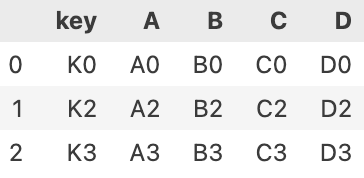
# key에 동일한 값이 없어도 왼쪽 key 기준으로 합침
pd.merge(left, right, how='left',on='key')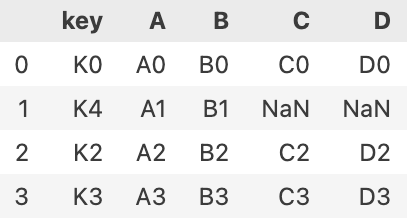
기준은 왼쪽의 key이다. 이때 없는 값은 NaN으로 표기된다.
# 양쪽 key를 다 보존하고 합침
pd.merge(left, right, how='outer',on='key')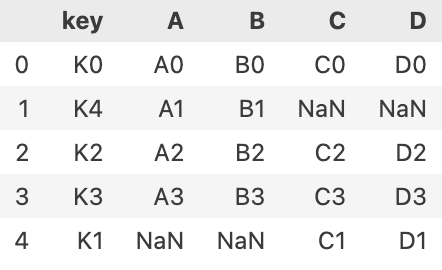
how = 'inner'은 교집합만 합친다.
피봇 테이블
피봇 테이블은 데이터를 요약하거나 재구성하는 데 사용되는 효과적인 방법입니다. 피봇 테이블은 기본적으로 주어진 데이터셋을 재구성하여 특정 기준에 따라 요약된 데이터를 보여줍니다. 예를 들어, 특정 열을 기준으로 그룹화하고 그에 따른 평균값, 합계, 빈도 등을 보여주는 것이 일반적입니다. 이를 통해 데이터셋의 특정 측면이나 관점을 빠르게 파악할 수 있습니다.
df = pd.read_excel('data/02. sales-funnel.xlsx')
df.head()
이 데이터를 활용해 피봇 테이블을 작성해보겠다.
pd.pivot_table(df, index = ['Name','Rep','Manager'], values = ['Account','Price','Quantity'])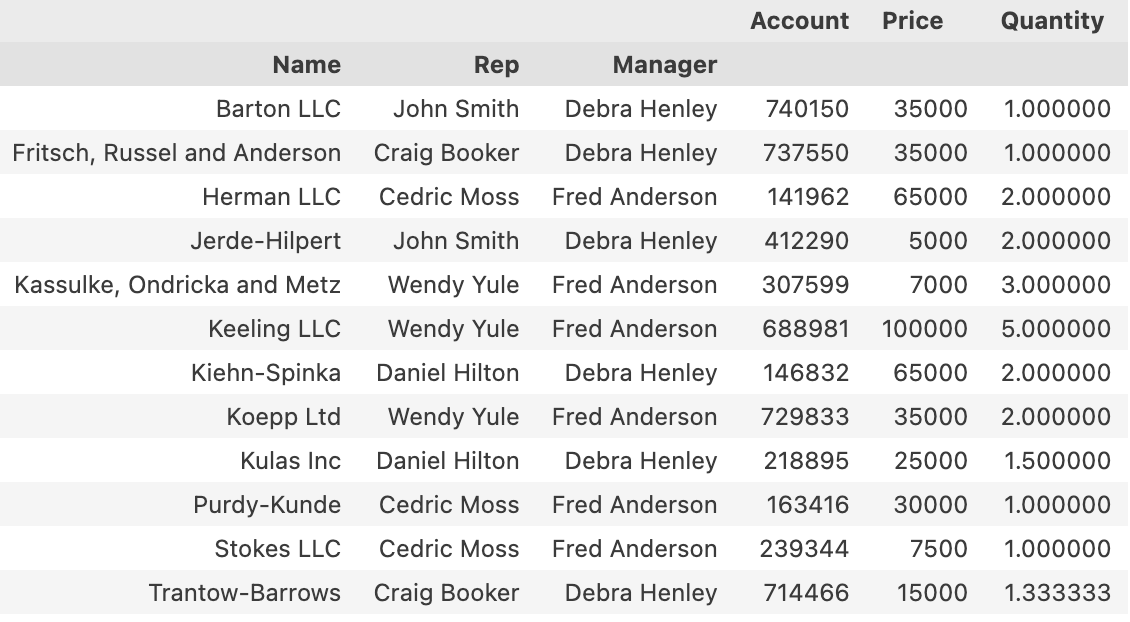
이렇게 인덱스를 설정해 개요를 확인할 수 있다.
# Price 의 합게를 원할 때
pd.pivot_table(df, index = ['Manager','Rep'], values = ['Price'], aggfunc = np.sum)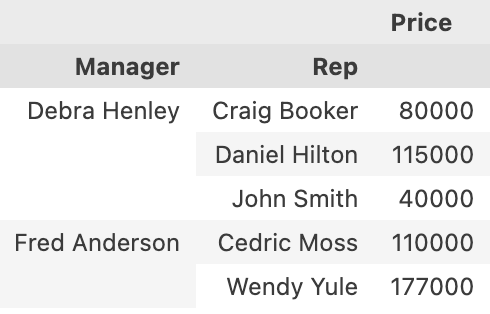
합을 찾고 싶으면 aggfunc = np.sum을 이용하면 된다.
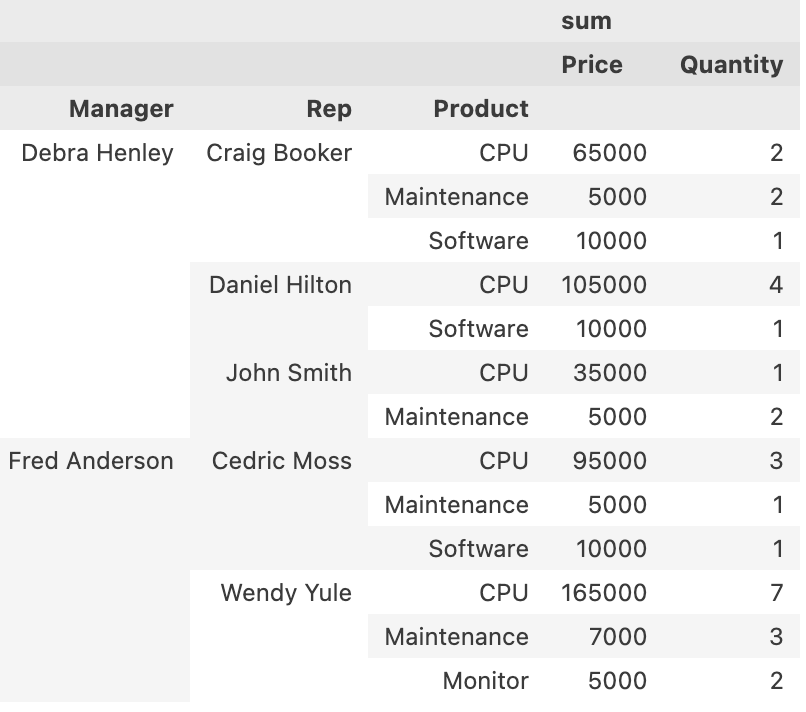
pd.pivot_table(
df,
index=['Manager','Rep','Product'], # 인덱스 설정
values=['Price','Quantity'], #가격, 갯수를 표시
aggfunc=[np.sum], # 방식은 합
fill_value=0, # 값이 없으면 0을 넣어라
)
전체적으로 확인하고 싶으면 margins=True를 넣으면 된다.

낭만젊음사랑