Acceleration of Packet Filtering using GPGPU
SIN '11: Proceedings of the 4th international conference on Security of information and networks
November 2011 Pages 227–230
Paper PDF
Problem
-
Packet filtering is core funcitonality in computer networks.
-
With the introduction of new types of services and applications, there is a growing demand for larger bandwidth and also for improved security.
-
However, "larger bandwith" and "improved security" conflict, since providing security partly relies on screening packet traffic implying an overhead.
-
Thus, to not be susceptible to Dos attacks, high processing power is needed.
Therefore, this paper presents and analyse various parallel implementations of packet filtering running on cost effective GPGPU. It describes an approach to efficiently exploit the massively parallel capabilities of the GPGPU.
Background
-
Packet filtering involves finding a match based on packet's metadata from the header for all ingress and egress packets.
-
The packet filtering decides to either DROP or ACCEPT.
-
Attackers can attack this firewall by:
1. Find the "Last matching ruleset", remotedly.
2. Since the "Last matching ruleset is located at the bottommost rule, it makes the server's firewall consume the most CPU power.
3. This attack can be used in Dos attack, bringing firewall to its knee. -
This kind of an attack can be minimized by increading the computing power.
-
Many optimization techniques are employed to increase throughput or decrease packet latency of firewalls:
1.Algorithmic optimization
2. Implementing packet filtering in FPGA/ASIC
3. Parallel Firewall -
Parallel Firewalls can be implemented by dividing either the traffic or the workload across an array of firewall nodes.
CUDA Programming Model && Linux Netfilter
CUDA
-
GPU, with the parallel structure, has high computational power and memory bandwith, showing more effective than general purpose CPU for many applications.
-
CUDA is a parallel programming model that leverages the computational capacity of the GPUs for non-graphics applications.
-
Programming in CUDA entails the distribution of the code for execution between the host CPU and the device GPU.
Linux NetFilter
- Under Linux, packet filtering is built into the kernel as part its networking stack. Netfilter is a framework for packet mangling, outside the normal socket interface.
-Each protocol defines hooks, well-defined points in a packet's traversal of that protocol stack, and kernel modules can register to listen to the different hooks for each protocol and get to examine the packet in order to decide the fate of the packet - discard, allow or ask netfilter to queue the packet for userspace.
- These rules can be determined using the iptables tool
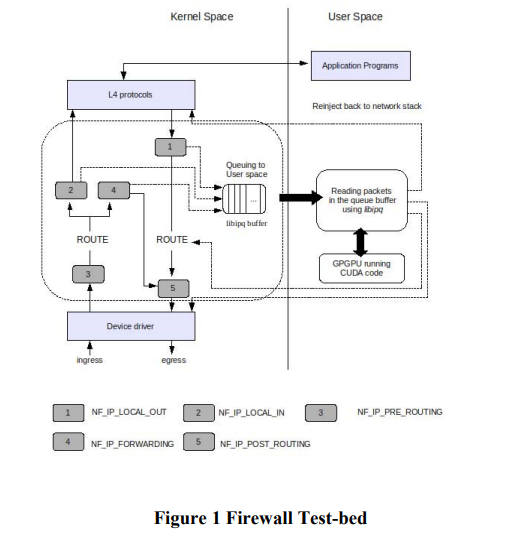
Implementation
This paper uses CUDA to implement packet filtering that will execute in parallel on GPGPU. Yet, nVidia does not provide any drivers which allow the direct control of their cards from within the Linux kernel,which forces all interactions to originate from userspace.
Thus, the model:
1. queues packets to userspace
2. processes them in the GPGPU
3. reinject back to the kernel networking stack with action decided from filtering.
The test-be created uses a set of rules, each containing 5-tuple:
1. source IP address
2. source port number
3. destination IP address
4. destination port number
5. protocol
, and specifies the action (Accept / Deny) for all packets across the network.
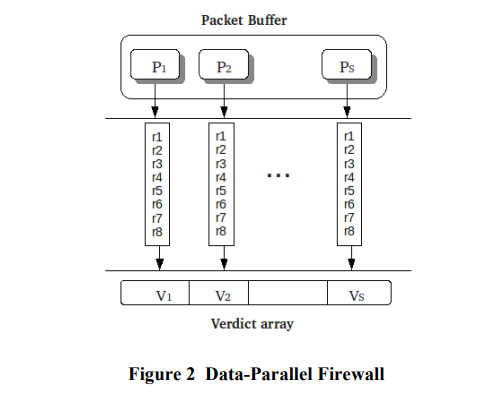
Data-parallel Firewall
-
Data parallel is a design that distributes the data (packets) across the firewall nodes.
-
Data parallel firewall consists of multiple firewall node, where each ith node has the whole rulset, working independantly.
-
Arriving packets are distributes across the nodes such that only 1 firewall processes the given packet.
-
The set of packets are accumulated, copied to device global memory, processed in parallel by different threads on GPGPU, and result is written to verdict array.
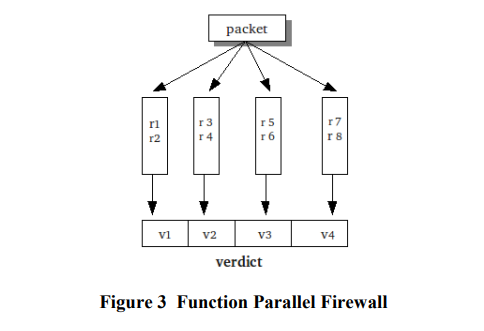
Function-Parallel Firewall
-
A function parallel Firewall design consistsof an array of firewall nodes.
-
In this design, arriving traffic is duplicated to all firewall nodes. Each firewall node 'i' employs a part of the security policy. After a packet is processed by each firewall node 'i', the result of each Ri is sent to the calling program running on the CPU.
-
To ensure no more than one firewall node determines action on a packet only the sequential code can execute an action on a packet.
-
Verdict array is copied from device to host after all the threads complete execution.
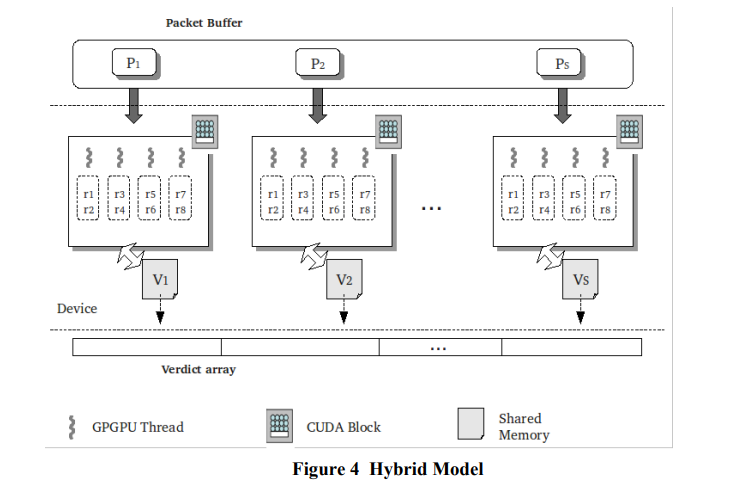
Hybrid Model
-
In Hybrid Model, a set of packets are accumulated and each packet is processed in parallel by a different block on GPGPU.
-
Within a block, a packet is processed by multiple threads simultaneously with each thread checking a part of the ruleset. Rule database is kept in device global memory.
-
Verdict array is copied from device to host after all the threads complete execution.
-
Using massively parallel computing capabilities of GPGPU we
have achieved a better model with increased throughput and
reduced packet processing delay compared to data/function-parallel firewall.
Results
- Test was ran on models on a node that has 3 GHz Dual Core processor with 1 GB RAM with nVidia Tesla C870 GPGPU with 4 GB global memory and 128 cores.
- The applications were first executed on CPU. These were compared with the timings from the parallel models executed on CPU + GPGPU.
- Traffic used for performance analysis contains packets whose source or destination addresses are from different class of IP address. The modeled traffic also contains traffic from different services like FTP, SCP and TELNET.
Data-parallel Firewall
- LIMITATION: Accesses to memory are cached. But caching does not improve performance since the cached data is not used later. Overhead of copying the whole ruleset to shared memory eclipses the improvement achieved by reduction in global memory contention.
Function-Parallel Firewall
- LIMITATION: Because of the CUDA overhead in copying verdict array to/from the device memory and kernel launch for every packet makes function-parallel model inefficient.
Hybrid Model
-In hybrid model, a packet is assigned to a CUDA block processed by the threads within that block. Number of threads launched per block has significant effect on the processing time.
Simulation
Simulations are performed to test the latency of various models of Parallel Firewalls. Each is compared with the conventional sequential approach.
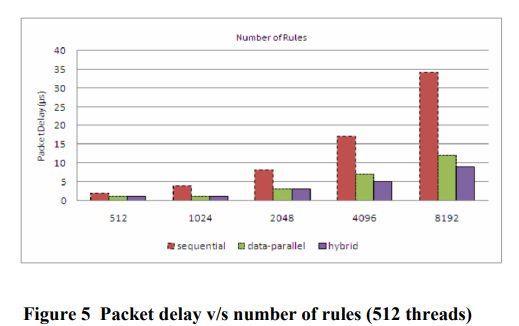
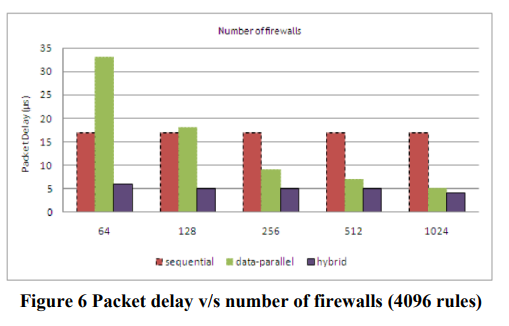
Conclusion
Data-Parallel design gives 3.4x and Hybrid model gives
4.25x speedup compared to sequential approach. Because of
increased throughput and low latency, parallel firewalls running on multi-cores will be more resilient to attack based on remote discovery of last matching rules.
Yet, current parallel models are stateless. A stateful parallel firewall will pose new challenges to implement.
Terminologies
- GPGPU
- WAN / LAN
- FPGA / ASIC
- CUDA
- Packet Mangling
- SM
