Because the mlnx_qos did not work at host,
I found:
https://enterprise-support.nvidia.com/s/article/HowTo-Configure-Rate-Limit-per-VF-for-ConnectX-4-ConnectX-5-ConnectX-6
From this I was able to see that Rate limit on VFs were available using:
ip link set <PF_IF_NAME> vf <VF_IDX> max_tx_rate <MAX_RATE_IN_MBIT/S> min_tx_rate <MIN_RATE_IN_MBIT/S>Thus, I decided to:
1. Test if rate limit well works
2. Test if rate limit gives better results for latency ( latency vs message rate sensitive)
1. Test max_tx_rate
1.1 Baseline Test

As tested multiple times before, with 13 cores given for tx, 100G was fulfilled with 64byte packets.
1.2 max_tx_rate limit test 1 iperf
Rate limit 90Gbps:
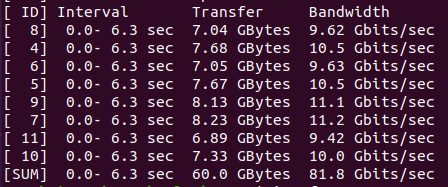
Rate limit 40Gbps:

With Iperf test, I could see that performance was right below the rate limit.
This I believe is normal as iperf is unavailable to show max performance
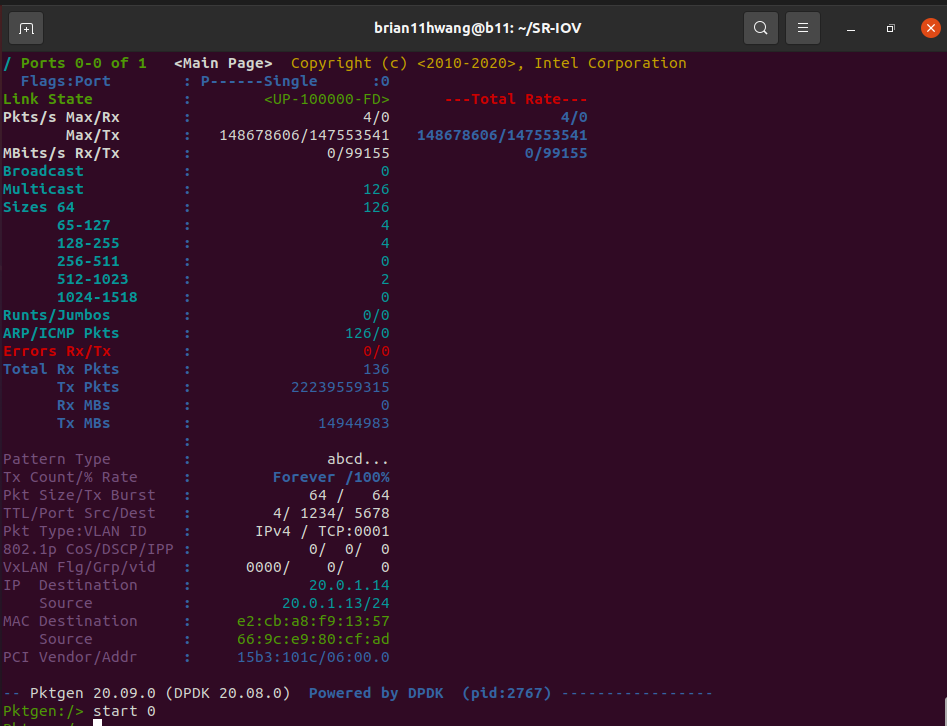
1.3 max_tx_rate limit rest 2 DPDK-Pktgen
Rate limit 90Gbps:
Rate limit 40Gbps:
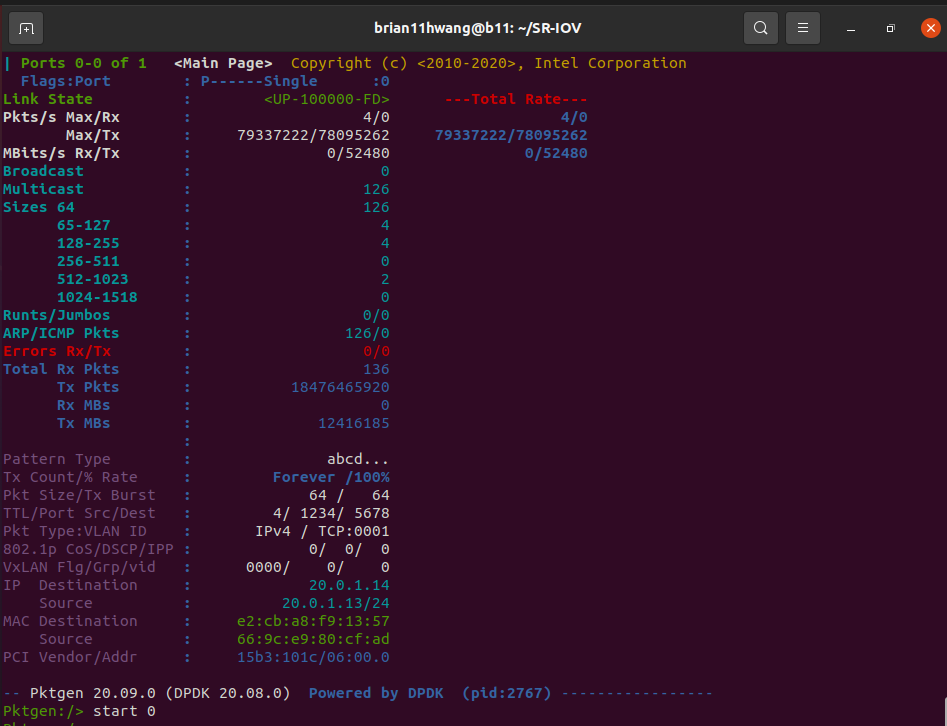
Now this is weird as it shows higher performance than the rate limit.
I first thought that the Pktgen shows generated packets, and thus was not limited by the rate limit, but with 40Gbps, it still shows deprecation in rate.
Still, it shows a limit in rate.
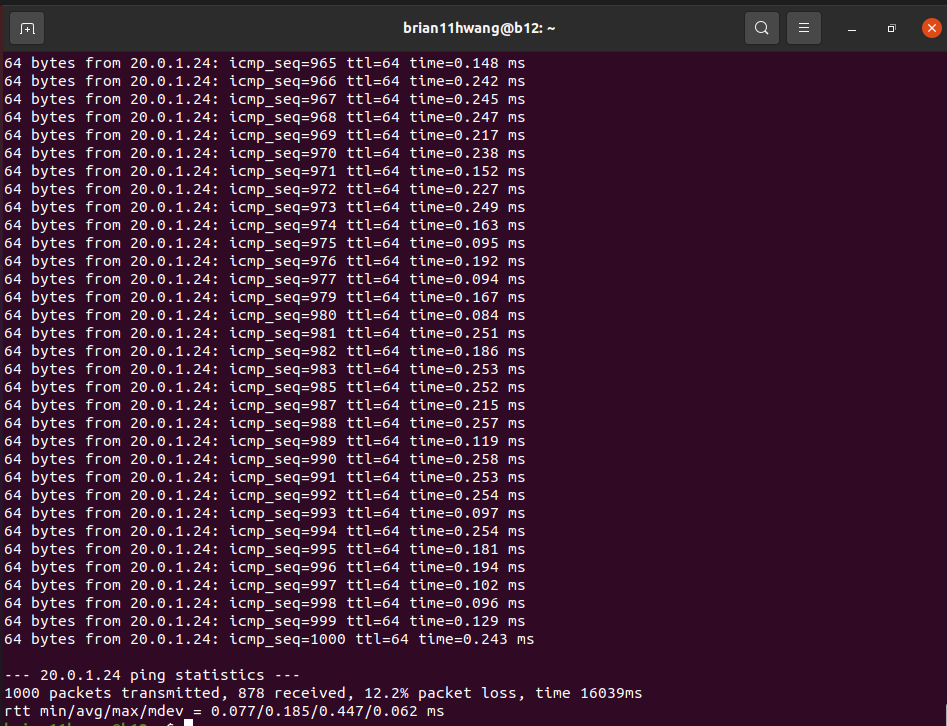
2. Test ping loss rate I (Recv side promiscuous mode, 64byte)
2.1 Baseline
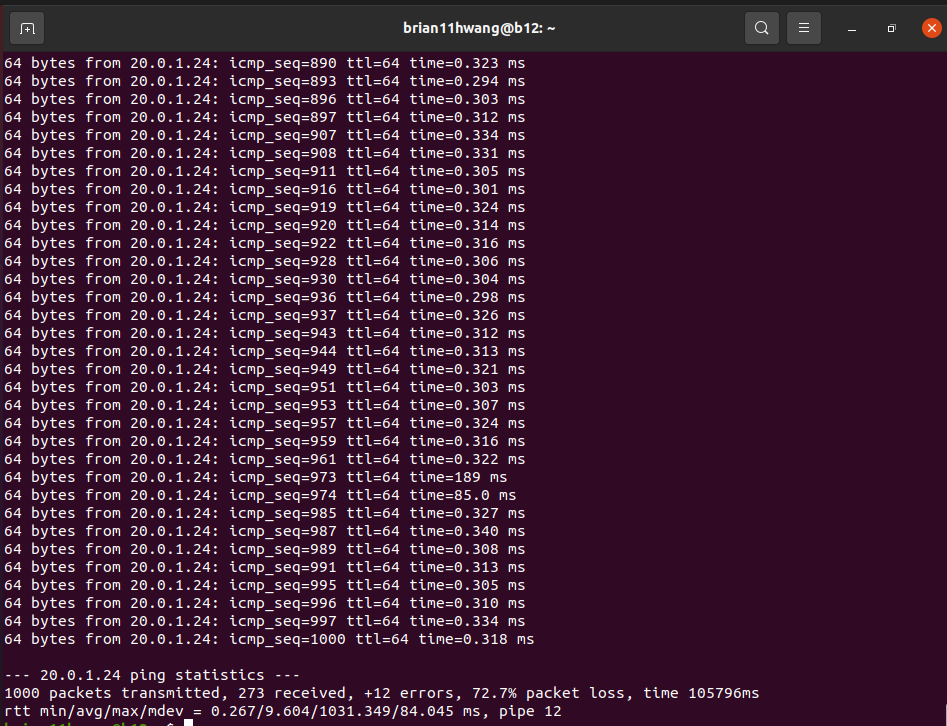
72 percent packet loss
2.1 Rate limit = 90G

74 percent packet loss..
2.2 Rate limit = 40G

37 percent packet loss
3. Test ping loss rate II (to diff recv side)
2.1 Baseline
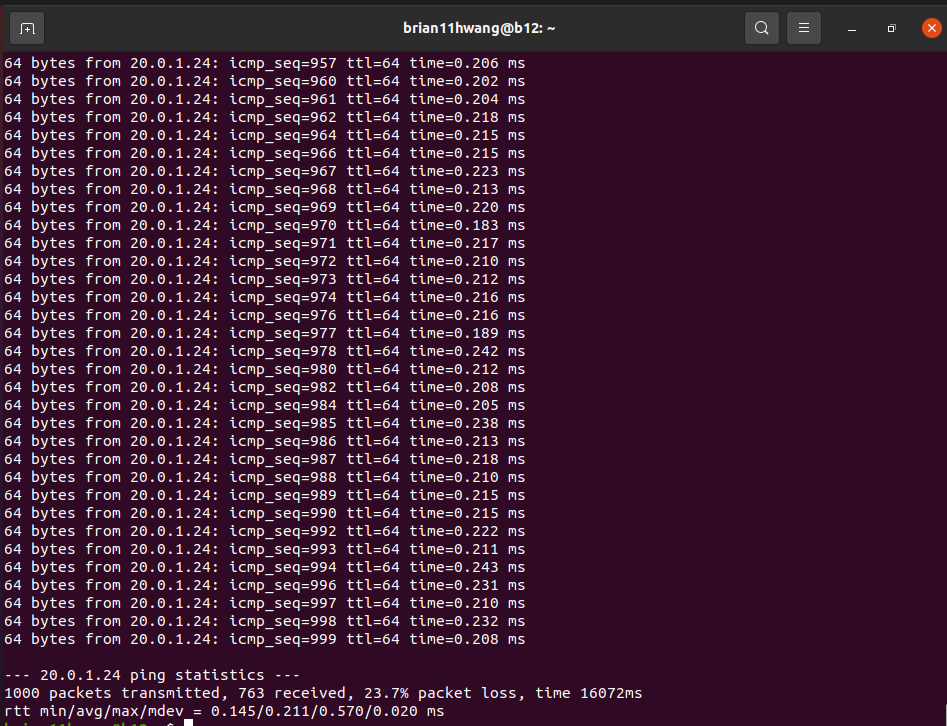
23.7 percent packet loss
2.1 Rate limit = 90G
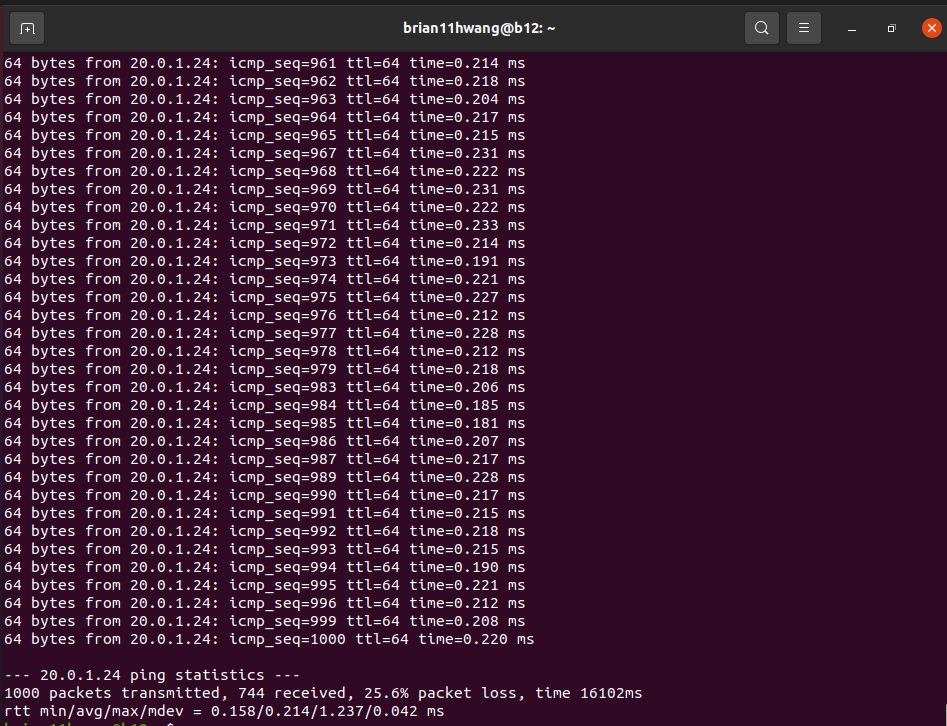
25.6 percent packet loss..
2.2 Rate limit = 70G
DPDK Pktgen TX: still >= 92G
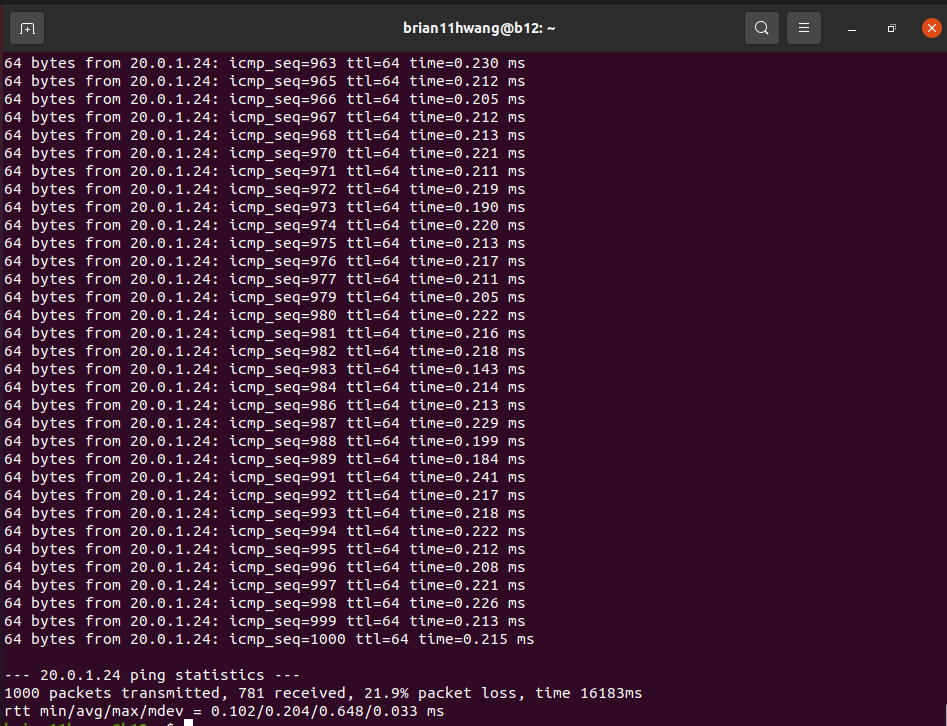
2.2 Rate limit = 60G
DPDK Pktgen TX: about 78G
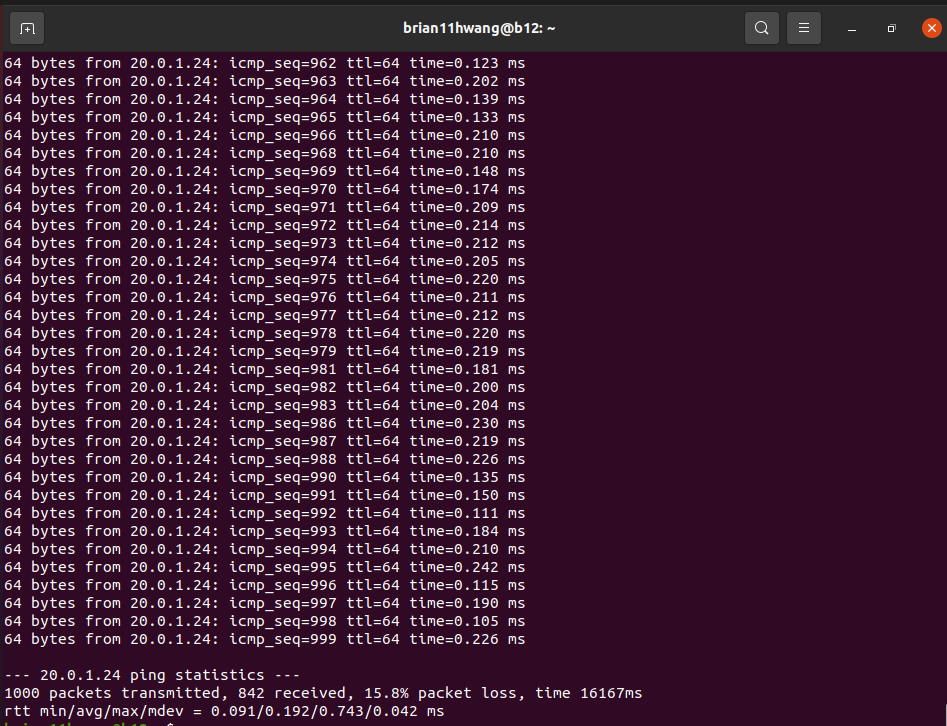
25.6 percent packet loss..
2.3 Rate limit = 40G
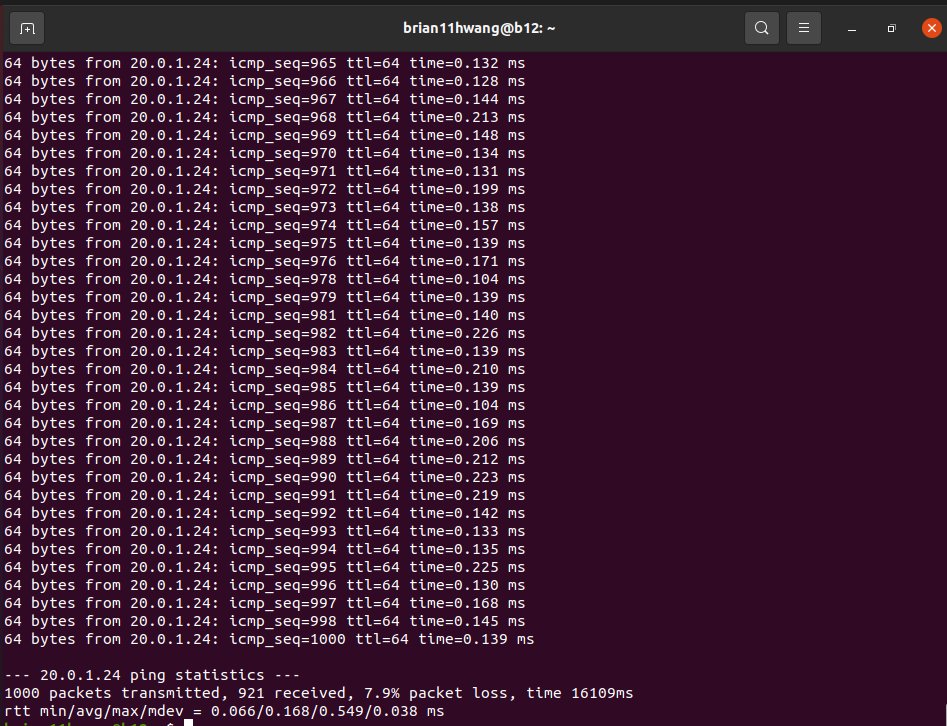
7.9 percent packet loss
3. Test ping loss rate III (Recv side promiscuous mode, 128byte)
Note : recv side different with 128byte packet showed no loss at baseline
2.1 Baseline
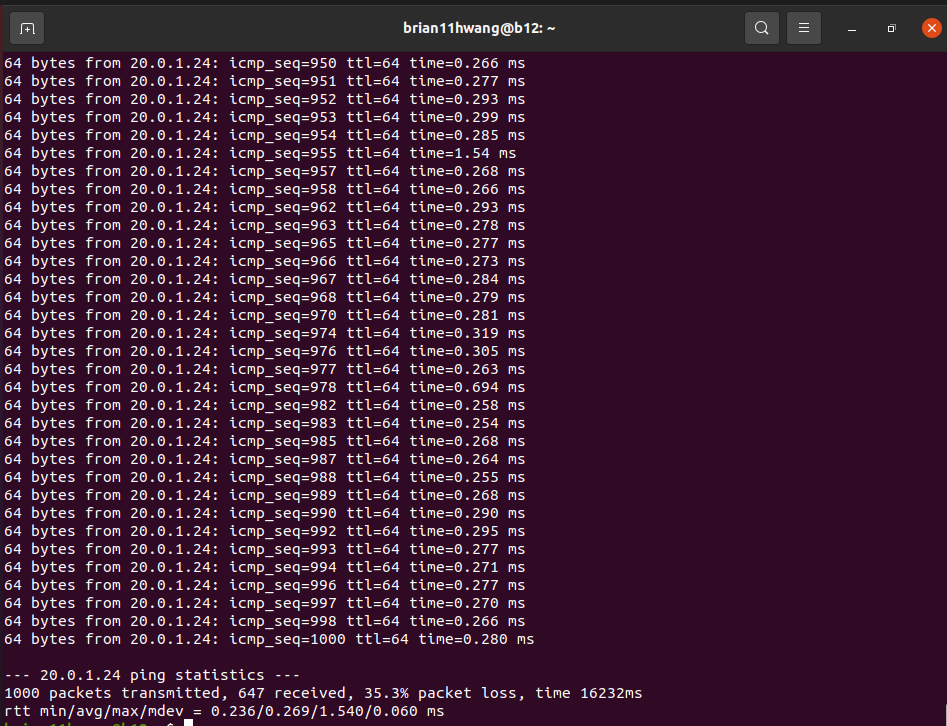
35.3 percent packet loss
2.1 Rate limit = 70G
DPDK Pktgen TX: about 80G
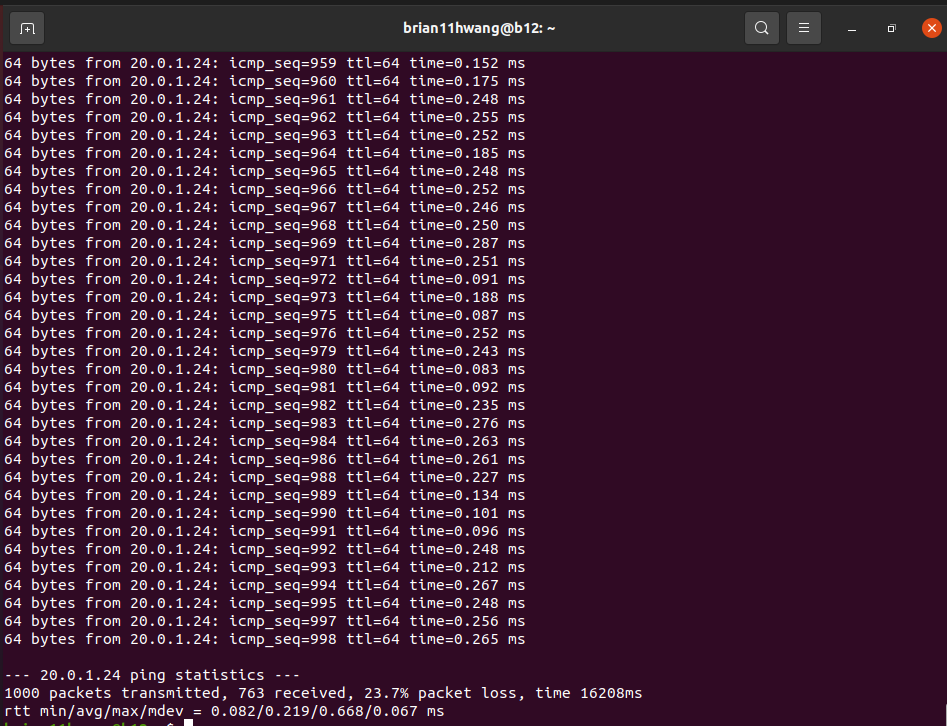
2.2 Rate limit = 60G
DPDK Pktgen TX: about 70G