
Colorful Image Colorization
Abstract
- 흑백 사진을 입력받아 현실감 있는 색상을 자동으로 컬러입히기
- 기존 방법들은 사용자 상호작용에 의존하거나 색이 탁한 결과물을 산출.
- 제안하는 방법:
- 완전 자동화된 접근 방식.
- 분류 작업으로 문제 정의, 학습 시 클래스 재균형 적용해 색 다양성 향상.
- 테스트 단계에서 CNN을 통해 피드포워드 방식으로 실행.
- 백만 개 이상의 컬러 이미지로 학습.
- "컬러화 튜링 테스트"로 알고리즘 성능 평가:
- 생성된 이미지가 32%의 확률로 실제 컬러 이미지로 혼동됨 (이전 방법들보다 우수).
- 색상 복원뿐 아니라, 자가 지도 학습(self-supervised learning)을 위한 강력한 프리텍스트 태스크로 활용 가능.
- 객체 분류 등에서 최첨단 성능 달성.
Grayscale의 이미지가 입력으로 들어왔을 때, 그럴듯한 착각을 줄 수 있는 Colorization
Keywords
- 색상 복원(Colorization)
- 그래픽을 위한 비전(Vision for Graphics)
- CNNs
- 자가 지도 학습(Self-supervised learning)
Introduction
기존 문제
- 사용자 개입: 사람이 직접 조정하거나 데이터를 제공해야 하는 경우가 많았음.
- 결과 품질: 색상이 흐리거나 (desaturated) 현실감이 떨어지는 경우가 많았음
입력된 흑백 사진에 대해 그럴듯한 색상을 입혀 사람을 속일 수 있는(그럴듯한 ) 이미지를 생성하는 것.
예시

기존의 한계
- 사용자 상호작용에 크게 의존
- 회색빛이 도는(desaturated) 결과를 생성 (CNN을 통한 설계 -> conservative한 예측의 loss 함수)
제안
Lab 색 공간(Lab color space)의 밝기 채널(lightness channel) L 을 입력으로 받아 a, b 색상 채널을 예측.
Lab 색 공간이란?
Lab 색 공간은
색을 밝기(L), a 채널(초록-빨강), b 채널(파랑-노랑) 이렇게 세 부분으로 나눠 표현하는 방식
- L 값: 밝기를 나타내며, 0~100 사이의 값을 가짐. 값이 클수록 밝고, 값이 낮을수록 어두움 -> 흑백이미지
- a 값: 초록(-)과 빨강/보라(+) 사이의 색상 정도
- b 값: 파랑(-)과 노랑(+) 사이의 색상 정도
L 채널을 입력, a와 b 채널을 정답으로 설정
즉, 컬러 이미지를 “입력: 흑백 이미지(L 채널), 출력: 색상 정보(a, b 채널)”로 변환해 학습 데이터를 쉽게 만들 수 있다는 뜻.
이 방식을 통해 모델은 L 채널(흑백 정보)을 입력으로 받아, a와 b 채널(색상 정보)을 예측하도록 학습
- 학습된 모델은 새로운 흑백 이미지를 입력받았을 때도 a와 b 채널을 생성해서 자연스러운 컬러 이미지를 만들어낼 수 있게 됨
Multimodal
사실 colorization은 본질적으로 Multimodal
- 여러 가능한 색상이 각각 답이 될 수 있음...
- 바나나는 초록색과 노란색 두 가지 색을 가질 수 있음.
- 해결 방안:
- 픽셀별 색의 분포를 예측하여 다양한 가능성을 반영.
- 학습 시 Rare한 색에 더 큰 가중치를 부여(re-weight)하여, 드문 색상도 제대로 표현하도록 함.
- 다양한 색상을 표현하기 위해 학습 시 클래스 재균형(class rebalancing)을 적용.
- class 재균형
- 학습 시 데이터에서 색상의 빈도를 기반으로 손실 함수를 조정 -> rare한 색상에 더 높은 가중치
- 이를 통해 다양한 색상을 균형 있게..
- class 재균형
- 분포의 annealed-mean(안정된 평균... 가중 평균...?)을 이용하여 최종 색상화 결과 생성.
- 평가
- 실제 사람이 평가했음
- 32% 참가자가 생성이미지를 실제로 착각함
- 좋은 결과..
2. Approach (방법론)
2.1 Objective Function
-
분류 기반 손실 함수(multinomial cross-entropy loss) 사용.
-
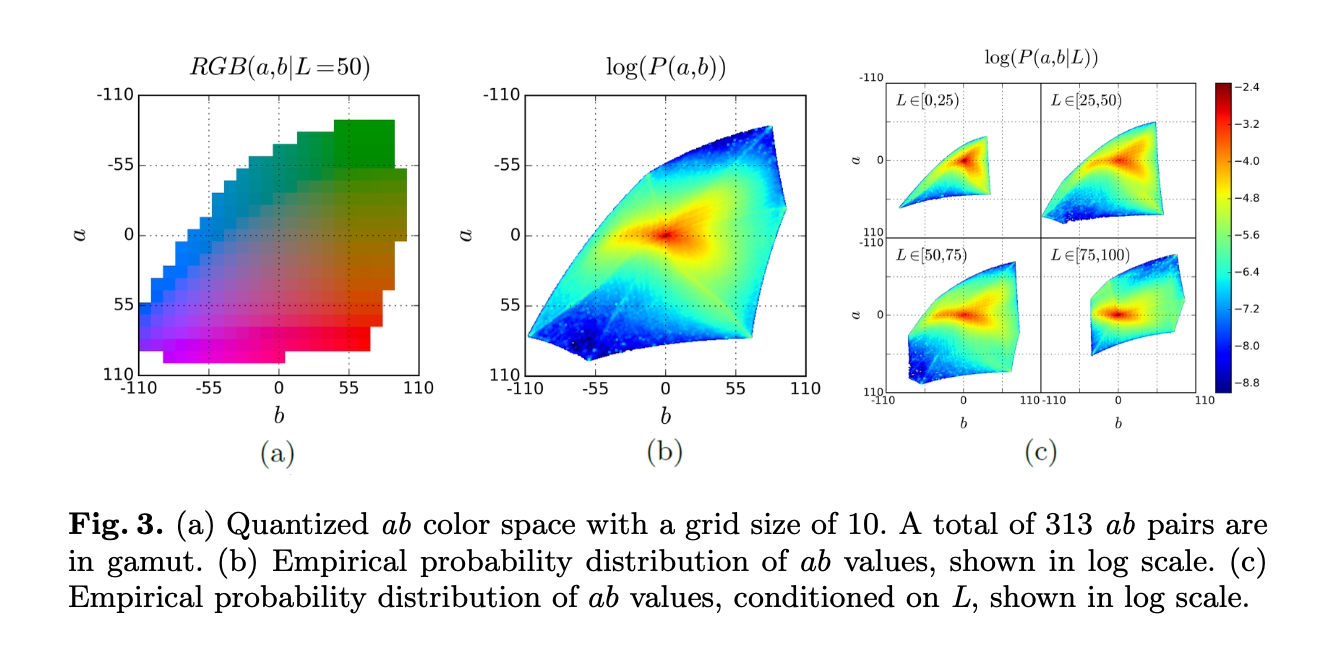
CIE Lab 색 공간에서 a, b 채널을 313개의 가능한 색상 클래스로 양자화(quantization).
-
픽셀별로 색상 분포를 예측하여 다중 모드 특성을 반영.
-
예측된 분포를 기반으로 최종 색상화를 수행.
(H,W,1)의 lightness channel에서, (H,W,2)인 2개의 컬러채널과 관련된 Yhat을 mapping하는 함수를 학습하는 것
- 입력: (H, W, 1) 크기의 밝기 채널(L).
- 출력: 픽셀별로 a, b 색상 클래스를 예측하는 확률 분포 Z(h, w, q) (q = 313개의 클래스).
- 손실 함수는 예측된 분포(Ẑ)와 실제 정답(Z) 간의 차이를 다중 클래스 교차 엔트로피(multinomial cross-entropy)로 계산.
가능한 색 찾기
2.2 Class Rebalancing (클래스 재균형)
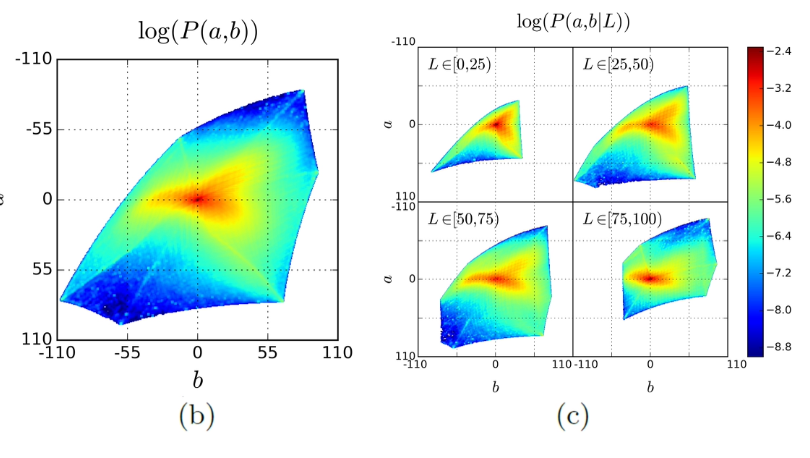
- 문제점:
- 자연 이미지에서 색상 분포는 불균형하며, rare한 색상이 적절히 학습되지 않음.
- rarity
- 예: 하늘(파랑/회색)이 배경일 경우, 구분하기 힘듦..
- 자연 이미지에서 색상 분포는 불균형하며, rare한 색상이 적절히 학습되지 않음.
- 해결책:
-
클래스 가중치(weighting):
- rare colors에 높은 가중치를 부여하여 균형을 맞춤.
- 색상의 빈도를 기반으로 손실 함수의 가중치를 동적으로 조정.
-> 다양한 색상이 학습되고, 결과물이 더 생생하며 현실적.
-
2.3 Class Probabilities to Point Estimates (클래스 확률에서 최종 색상 생성)

- 문제:
- 색상 분포 예측 후 이를 단일한 색상 값으로 변환하는 방식.
- 단순히 평균(mean)을 취하면 흐릿한 색상(desaturated)을, 최빈값(mode)을 사용하면 색이 불안정.
- 해결책:
- Annealed-Mean:
- 분포의 "온도(temperature)"를 조정해 평균과 최빈값의 중간 결과를 생성.
- 낮은 온도: 분포가 날카로워져 최빈값에 가까움.
- 높은 온도: 분포가 넓어져 평균에 가까움.
- 최적 설정:
- T = 0.38로 설정..
- 효과:
- 공간적 일관성과 선명도를 모두 유지하는 색상화 결과.
- Annealed-Mean:
Experiments
데이터셋: ImageNet에서 1.3M개의 이미지로 학습, 10k개의 이미지를 검증.

학습된 특징이 PASCAL VOC 데이터셋에서 분류(Classification), 탐지(Detection), 세분화(Segmentation) 작업에 얼마나 효과적인지 검증.
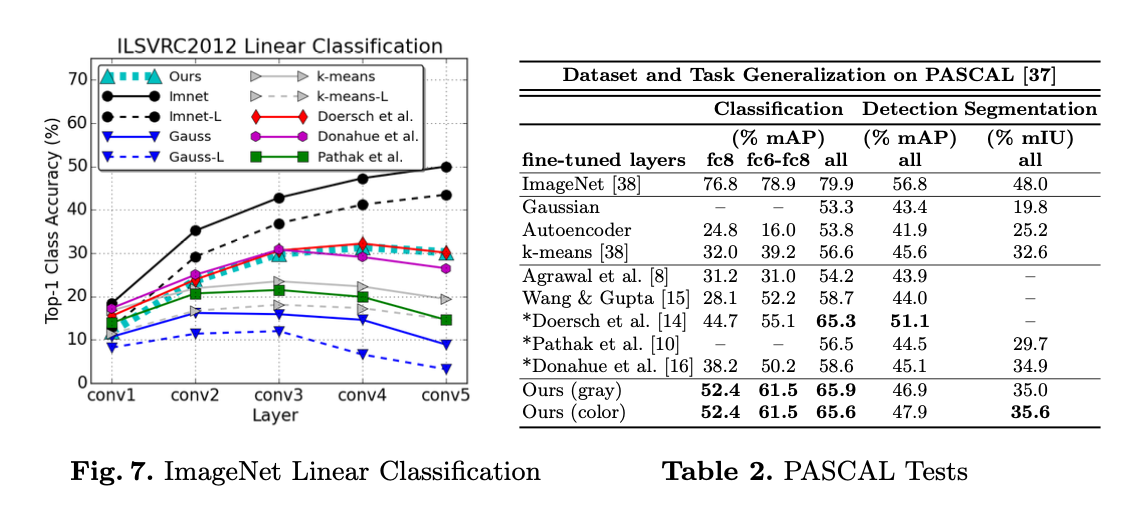
Fig7
- 제안된 모델은 흑백 입력으로도 높은 정확도를 기록.
- 컬러 입력에서는 정확도가 약간 더 높아짐.
- 특히, conv5에서 차이가 큼
Fig8
- 분류(Classification):
- Ours이 흑백(gray)과 컬러(color) 입력 모두에서 65.9% 이상의 mAP를 기록.
- 탐지(Detection):
- 흑백 입력(46.9%)
- 컬러 입력(47.9%)
- 세분화(Segmentation):
• 컬러 입력(35.6%)
• 흑백 입력(35.0%)
평가
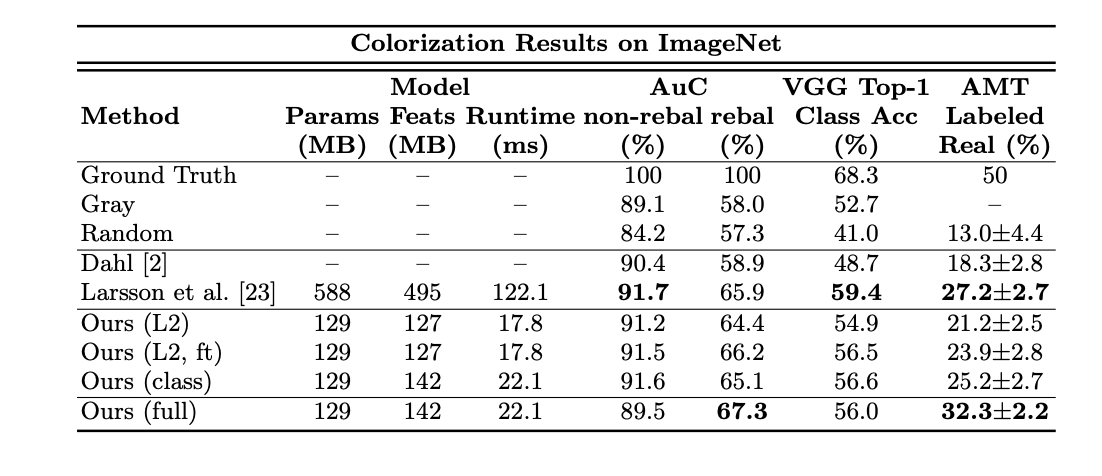
• Larsson et al.: ImageNet 기반 CNN을 활용한 색상화 모델.
• Ours (L2): 단순 L2 손실 기반으로 학습한 모델.
• Ours (L2, ft): L2 손실로 fine-tuning한 모델.
• Ours (class): 분류 기반 손실(classification loss)을 사용한 모델.
• Ours (full): 분류 기반 손실 + 클래스 재균형(class rebalancing)을 적용한 완전한 모델.1. AuC (non-rebal, rebal)
- 예측된 색상이 실제 색상과 얼마나 일치하는지를 나타내는 누적 오차 곡선(Area under Curve).
- non-rebal: 클래스 재균형을 적용하지 않은 경우.
- rebal: 클래스 재균형을 적용한 경우.
- 결과: 제안된 모델(Ours full)이 rebal에서 가장 높은 67.3% 기록.
2. VGG Top-1 Class Accuracy (%)
- 색상화된 이미지를 VGG 네트워크로 분류했을 때의 정확도.
- 결과:
- Ours full: 56.0%로 Dahl보다 높음.
- Larsson et al. 모델(59.4%)에는 약간 뒤짐.
3. AMT Labeled Real (%)
- 컬러화 튜링 테스트(Amazon Mechanical Turk)에서 사람이 생성된 이미지를 실제 이미지로 혼동한 비율. -> 1초만 보여줬다고 함
- 결과:
- Ours full: 32.3%로, 기존 모델(Dahl 18.3%, Larsson 27.2%)보다 월등히 높음.
4. Runtime(ms)
- 다른 모델에 비해 빠름
- 22.1ms
빠른건가?
real-time 적용 가능할까?
AMT 평가 사례

가장 성공적인 사례:
- 왼쪽의 상단 이미지는 AMT 참가자들의 82%가 알고리즘의 결과를 Ground Truth보다 더 진짜로 간주.
- 이 경우, 알고리즘이 더 표준적이고 예상 가능한 색상(예: 자연스러운 갈색의 물과 반사된 색상)을 예측했기 때문.
실패 사례:
- 오른쪽 하단 이미지는 참가자들이 0%의 확률로 알고리즘 결과를 진짜로 인식.
- 색상이 부정확하거나 비자연적인 결과(예: 노란색 트럭, 파란색 톤의 물고기)가 문제.
그래도 잘 속긴 했으니 성능이 좋다고 생각됨
22.1 ms 정도면 어느 정도일까..
