
VIRAT: 실외 감시 영상용 대규모 이벤트 인식 데이터셋
A Large-scale Benchmark Dataset for Event Recognition in Surveillance Video
Abstract
대규모 실외 감시 영상에서 지속적 시각 이벤트 인식(CVER) 성능을 평가하기 위한 데이터셋.
기존 데이터셋은 짧은 클립이나 인위적인 장면이 많아 실제 감시 환경과 좀 달랐음.
이 데이터셋은 자연스러운 상황에서 23가지 이벤트 유형을 포함한 29시간 분량의 영상으로 구성.
-> 물론 연출 장면이 있음
주요 특징
- 객체 추적 및 이벤트 주석 제공
- 다양한 평가 모드와 지표 제안
- 초기 실험 결과 포함
1. Introduction
시각 이벤트 인식(Visual Event Recognition)은 걷기(walking), 차량 탑승(getting into vehicle), 시설 진입(entering facility)과 같은 시공간적 패턴(spatio-temporal patterns)을 인식하는 컴퓨터 비전의 핵심 문제임.
기존 데이터셋의 한계
기존 데이터셋은 대부분 짧은 클립으로 구성되어 있으며, 인위적인 장면이 많음. 예를 들어, KTH 및 Weizmann 데이터셋은 단일 인물의 간단한 동작만 포함하고 있어, 실제 감시 환경을 반영하기 어려움. 영화나 스포츠를 대상으로 제작된 데이터셋도 있지만, 감시 영상의 특성과는 거리가 멀어 실용성이 떨어짐.
VIRAT 데이터셋의 특징
이 데이터셋은 실제 감시 환경을 반영한 대규모 실외 영상 데이터셋으로, 지상 고정 카메라와 이동형 항공 카메라로 촬영된 영상을 포함. 총 23가지 이벤트 유형이 29시간 분량의 영상에 걸쳐 나타나며, 16개의 다양한 실외 장면에서 non-actors가 자연스럽게 행동하는 모습을 담고 있음.
세부 주석(annotation) 제공
VIRAT 데이터셋의 강점은 주석(annotation)에 있음. 각 객체의 움직임을 바운딩 박스(bounding box)로 추적하며, 각 이벤트의 시작과 끝을 명확히 구분하여 라벨링함. 예를 들어, “차량에 탑승” 이벤트는 사람이 차량에 접근하고 문을 여는 순간부터, 문을 닫고 차량에 완전히 탑승하는 순간까지 세밀하게 기록됨. 이를 통해 연구자들은 다중 객체 추적 및 이벤트 인식 알고리즘을 정밀하게 평가할 수 있음.
평가 모드와 활용
VIRAT 데이터셋은 독립적 인식 모드와 학습 지원 인식 모드라는 두 가지 주요 평가 모드를 제안.
- 독립적 인식 모드: 훈련 및 테스트 데이터를 엄격히 분리하여, 새로운 장면에서도 성능을 평가할 수 있도록 설계.
- 학습 지원 인식 모드: 특정 장면의 패턴이나 특징을 학습한 후, 이를 활용해 같은 환경에서의 인식 정확도를 높이는 방식.
이 데이터셋은 단순히 이벤트를 분류하는 수준을 넘어, CVER(지속적 시각 이벤트 인식)의 핵심인 시공간 내에서 이벤트를 정확히 식별하고 위치까지 추적할 수 있도록 설계됨. 이는 감시 시스템뿐만 아니라, 비디오 아카이브 분석, 영상 기반 행동 연구, 보조 기술 개발 등 다양한 분야에 적용 가능.
기대 효과
VIRAT 데이터셋은 현실적인 감시 환경을 반영한 최초의 대규모 데이터셋 중 하나로, 기존의 한계를 뛰어넘는 정확한 이벤트 인식 연구를 촉진할 것으로 기대. 이를 통해 감시 시스템의 성능을 높이고, 컴퓨터 비전 연구의 새로운 도전을 제시할 것으로 보임.
2. VIRAT Video Dataset
Overview
VIRAT 데이터셋의 목적:
- 실제 감시 환경에서 현재 지속적 시각 이벤트 인식(CVER)의 한계를 식별
데이터셋 구성
- Stationary Ground Dataset: 고정된 지상 카메라로 촬영
- Aerial Dataset: 이동형 항공 카메라로 촬영
- 총 23가지 이벤트 유형
- 단일 인물 이벤트 (8개): 걷기, 뛰기, 서 있기, 제스처, 물건 나르기 등
- 인물과 차량 상호작용 (7개): 차량 탑승, 하차, 트렁크 여닫기, 짐 싣기/내리기 등
- 인물과 시설 상호작용 (2개): 시설 입장, 퇴장
특징 및 장점
1. 다중 객체 상호작용 지원 (Multi-Object Interactions)
기존 데이터셋(KTH, Weizmann 등)은 주로 단순한 단일 인물 이벤트에 초점.
- VIRAT는 다양한 객체 간 상호작용(예: 인물-차량)을 포함.
- 인위적이지 않은 자연스러운 행동을 캡처.
2. 부수적 객체와 활동 (Incidental Objects and Activities)
장면 내에서 여러 객체와 활동이 동시에 발생.
- 예: 여러 사람이 움직이고, 배경에서 차량이 지나가는 장면 등.
3. End-to-End 활동 기록 (End-to-End Activity Recording)
이벤트가 시작부터 끝까지 시공간적 맥락을 모두 포함.
- 예: 사람이 등장 → 가방을 들고 차량 접근 → 짐을 싣고 차량 탑승 → 차량 운전 후 퇴장까지 연속적으로 캡처.
<Figure 1>

Figure 1은 VIRAT 데이터셋이 제공하는 지속적 시각 이벤트 인식(CVER)의 예시를 시각적으로 보여줌.
해당 시퀀스는 다음과 같은 일련의 행동으로 구성:
1. 사람이 장면에 등장.
2. 가방을 차량에 싣고,
3. 차량에 탑승 후 떠남.
ㄴ 이렇게 주석으로 작성되어 있음
- 빨간색 박스: 사람의 위치 추적.
- 초록색 박스: 차량의 위치 추적.
데이터셋 비교
| Dataset | Event Types | Samples per Class | Resolution | Human Height (Pixels) | End-to-End Activities | Multiple Annotations |
|---|---|---|---|---|---|---|
| KTH | 6 | ~100 | 160 x 120 | 80~100 | No | No |
| Weizmann | 10 | ~9 | 180 x 144 | 60~70 | No | No |
| HOHA 1 | 8 | ~85 | ~540 x 240 | 100~1200 | Varying | No |
| TRECVID | 10 | ~1670 | 720 x 576 | 20~200 | Varying | No |
| VIRAT | 23 | 10~1500 | 1920 x 1080 | 20~180 | Yes | Yes |

(a) KTH: 단일 인물의 간단한 동작(예: 걷기, 뛰기)을 보여줌. (b) Weizmann: 제한된 공간에서 수행된 단일 동작. (c) HOHA: 영화 장면에서 추출된 데이터로, 동작 및 상호작용이 복잡하나 배경 다양성이 부족. (d) CAVIAR: 실내 감시 환경에서 발생하는 이벤트에 초점. (e) TRECVID: 대형 공항과 같은 복잡한 환경에서 여러 객체가 활동.
용어설명
-
CVER (Continuous Visual Event Recognition):
- 비디오의 시공간적 맥락을 유지하며 이벤트를 인식하고 위치를 추적하는 기술.
- 단순한 클립 분류를 넘어선 감시 분석에 필수.
-
End-to-End Activities:
- 이벤트의 시작과 끝을 포함한 전체 맥락을 캡처.
- 기존 데이터셋은 짧은 이벤트 클립만 제공했지만, VIRAT는 이를 극복.
-
Incidental Objects/Activities:
- 장면 내 부수적인 객체 및 활동.
- 현실적인 배경에서 다양한 객체와 이벤트를 동시에 포함.
annotation
- 정밀한 바운딩 박스 제공:
각 객체의 움직임과 이벤트를 정확히 라벨링. - 다중 주석:
하나의 장면에 여러 객체 및 이벤트를 주석 처리.- 예: 인물, 차량, 물건 등의 복합적 움직임.
2.1. First Part: VIRAT Ground Video Dataset
Overview of Ground Dataset
VIRAT Ground Video Dataset는 고정된 지상 카메라로 촬영된 약 25시간 분량의 영상으로 구성됨.
총 16개의 장면에서 촬영되었으며, 각 장면당 평균 1.6시간의 데이터가 포함.
- 촬영 장면: 주차장, 건설 현장, 야외 공터, 도로..
- 카메라 사양:
- 해상도: 1080p 또는 720p
- 프레임 레이트: 25~30 Hz
- 카메라 각도: 지상 면과 20~50도 사이
- 설치 위치: 건물 위
장면 및 이벤트 특징
-
자연스러운 이벤트 기록
- 21시간의 영상은 실제 환경에서 자연스럽게 발생하는 이벤트를 기록.
- 4시간만 배우가 참여한 다중 객체 상호작용 이벤트 포함.
-
시간대별 데이터
- 출퇴근 시간 및 점심시간 등 활동이 많은 시간대
- 100시간 이상의 영상에서 25시간의 고품질 데이터를 선별.
-
장면 다양성
- 16개의 장면 중 4개는 시야(Field of View) 중첩, 나머지는 독립적인 장면.
- 다양한 조명 조건에서 촬영: 시간대 및 날씨 변화 포함.
-
데이터 상세정보
- 사람의 키: 25~200 픽셀 (영상 높이의 2.3~20%)
- 평균 사람 키: 약 7%
-
호모그래피(Homography) 정보 제공
- 각 장면에 대해 이미지-지면 변환 정보를 제공.
- 객체 추적 및 지면 좌표 기반 연구에 유용.
데이터셋의 차별점
VIRAT Ground Video Dataset은 기존 데이터셋(CAVIAR, TRECVID 등) 대비 다음과 같은 특징을 가짐:
- 고해상도 및 광범위한 시야를 제공.
- 장면의 배경 복잡성과 다양한 수집 장소 및 시점 반영.
- 기존 데이터셋보다 더 많은 야외 이벤트와 카테고리를 포함.
다운샘플링 데이터 제공
원본 HD 데이터에서 공간 및 시간적 해상도를 낮춘 버전도 제공하여 연구자들이 다양한 조건에서 CVER 알고리즘을 테스트 가능.
-
Temporal Downsampling
- 프레임 레이트: 10 Hz, 5 Hz, 2 Hz
- 많은 감시 카메라가 낮은 프레임 레이트(2 Hz 이하)로 동작하므로,
저해상도 데이터에서 알고리즘 성능 분석 가능.
-
Spatial Downsampling
- 고정 비율 대신, 사람의 평균 픽셀 높이에 맞춘 방식으로 다운샘플링.
- 제공 픽셀 높이: 50, 20, 10 픽셀
- 예시: Fig. 4에서는 동일 인물이 140픽셀, 50픽셀, 20픽셀, 10픽셀로 다운샘플링된 모습을 보여줌.

- 결과적으로 9가지 버전의 다운샘플링 데이터
- 시간적(3가지) + 공간적(3가지) 다운샘플링의 조합.
2.2. Second Part: VIRAT Aerial Video Dataset
Overview of Aerial Dataset
VIRAT Aerial Video Dataset는 항공 촬영 데이터
- 데이터 수집 목표:
- 항공 영상에서 다양한 이벤트 인스턴스를 수집.
- 항공 데이터 특유의 시점 변화, 조명 변화, 가시성 문제를 포함하여 CVER 문제를 더욱 복잡하게 만듦.
데이터 특징 및 구성
-
촬영 환경
- 지정된 장소에서 이벤트를 연출.
- 장소: 건물, 주차장, 창고 등 다양한 시설이 포함된 복합 장소(Fig. 5 (a)).
- 시퀀스 예시: 약 10초 간격으로 촬영된 장면(Fig. 5 (b))은 시점 변화와 스케일 변화를 보여줌.
-
항공 데이터의 도전 과제
- 시점 변화: 항공기의 움직임에 따라 view point가 끊임없이 변동.
- 스케일 변화: 객체 size가 장면 내에서 지속적으로 달라짐.
- 영상 안정화: 비디오 흔들림이나 픽셀 정렬 불완전성을 보정해야 함.
-
기술 사양
- 640x480
-> 해상도가 이미 낮음 - 프레임 레이트: 30 Hz
- 카메라 장비: 짐벌(gimbal)이 장착된 유인 항공기.
- 평균 인물 크기: 약 20 픽셀 높이
- 총 영상 데이터: 25시간 녹화 → 4시간의 매끄러운 카메라 움직임 및 좋은 날씨 데이터만 선별
- 640x480
예시

- Fig. 5 (a): 다양한 규모와 시점을 포함한 장면.
- 건물, 주차장, 저장 시설 등의 복합적 배경.
- 인물, 차량, 시설 간의 이벤트 상호작용 포함.
- Fig. 5 (b):
- 항공기의 이동으로 인해 시간이 지남에 따라 변하는 시점과 스케일 변화.
- 약 10초 간격으로 캡처된 일련의 이미지로 데이터의 동적 특성을 보여줌.
2.3. Annotations
quality와 cost간의 균형 유지가 중요함..
VIRAT 데이터셋의 주석은 두 가지 주요 형태의 정답 데이터(ground-truth)로 구성됨:
1. 움직이는 객체를 위한 바운딩 박스(bounding box).
2. 객체 상호작용을 포함한 event.
1. bounding box
- 절차:
- 비디오를 10초 단위로 분할하여 MT(Mechanical Turks) 플랫폼에 업로드.
- 작업자들은 주기적으로 움직이는 객체를 바운딩 박스로 표시.
-> 수동으로 했다니.. - 자동 보간(interpolation) 알고리즘을 사용해 주요 프레임 사이의 주석을 생성.
- 바운딩 박스 기준:
- 타이트(Tight): 객체 주변에 최소한의 불필요한 픽셀 포함.
- 전체(Whole): 사람의 팔, 다리와 같은 모든 보이는 부분 포함.

Fig. 6에서는 여러 객체(사람, 차량 등)가 시간에 따라 추적되는 바운딩 박스 예시를 보여줌.
2. Event 주석
- 절차:
- 전문가가 바운딩 박스 트랙을 검토하여 특정 이벤트가 발생하는 time intervals을 식별.
- 예: 사람이 가방을 들거나 건물에 들어가는 등의 상호작용 이벤트 라벨링.
- 주요 고려사항:
- 보이는 부분만 주석 처리하며, 가림 현상(occlusion)을 넘어 추측하지 않음.
- 예: 사람의 상체만 보이는 경우, 상체 부분만 ‘사람’으로 라벨링.
2.3.1 다중 객체 추적을 위한 정답 데이터
-
주석 가이드라인:
- 움직이는 객체는 바운딩 박스로 추적하며, 보이는 부분만 라벨링.
- 중요한 속성:
- 타이트(Tight): 불필요한 픽셀 최소화.
- 전체(Whole): 객체의 보이는 모든 부분 포함.
- 예: 걷는 사람은 몸통뿐만 아니라 팔과 다리까지 포함해야 함.
-
정적 장면 주석:
- 건물 입구, 가방 등 정적 객체도 움직이는 객체와의 상호작용이 있는 경우 주석 처리.
3. Evaluation Approaches
VIRAT 데이터셋은 다양한 컴퓨터 비전 알고리즘(CVER, 다중 객체 추적, 장면 인식 등)의 평가에 활용될 수 있음.
제공된 ground-truth annotations을 활용.
3.1. Continuous Visual Event Recognition (CVER)
CVER은 시공간적인 event localize하는 문제.
3.1.1 Metrics (평가지표)
CVER 알고리즘을 평가하기 위해 명확히 정의된 metric이 필요함.
-
Hits 정의:
- spatial 및 temporal 겹치는 비율이 임계값 이상일 경우 해당 이벤트를 ‘hit’로 간주.
- ground-truth 중심 평가 방식을 채택:
- 각 ground-truth 예제는 하나의 올바른 검출만 기여함.
- 동일한 영역에서 다수의 중복 결과를 생성하더라도 false alarm으로 간주하지 않음.
- 이는 높은 가능성 영역에서 중복된 결과를 생성하여 부당한 점수를 얻는 알고리즘의 이점을 방지.
-
표준 메트릭:
- Precision (정밀도): 검출된 이벤트 중 올바른 검출 비율.
- Recall (재현율): 실제 존재하는 이벤트 중 올바르게 검출된 비율.
- False Alarm Rate (오탐율): 잘못 검출된 이벤트 비율.
3.1.2 Sample Evaluation
Table 2는 샘플 데이터셋에 대한 평가 통계를 보여줌:
- 특정 이벤트 카테고리에서 총 ground-truth 예제 개수와 추적 후 가능한 최대 hit 상한을 포함.
| Event Categories | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| # Ground Truth | 11 | 16 | 18 | 19 | 61 | 63 |
| # Hit Upper-bound | 6 | 8 | 8 | 9 | 18 | 14 |
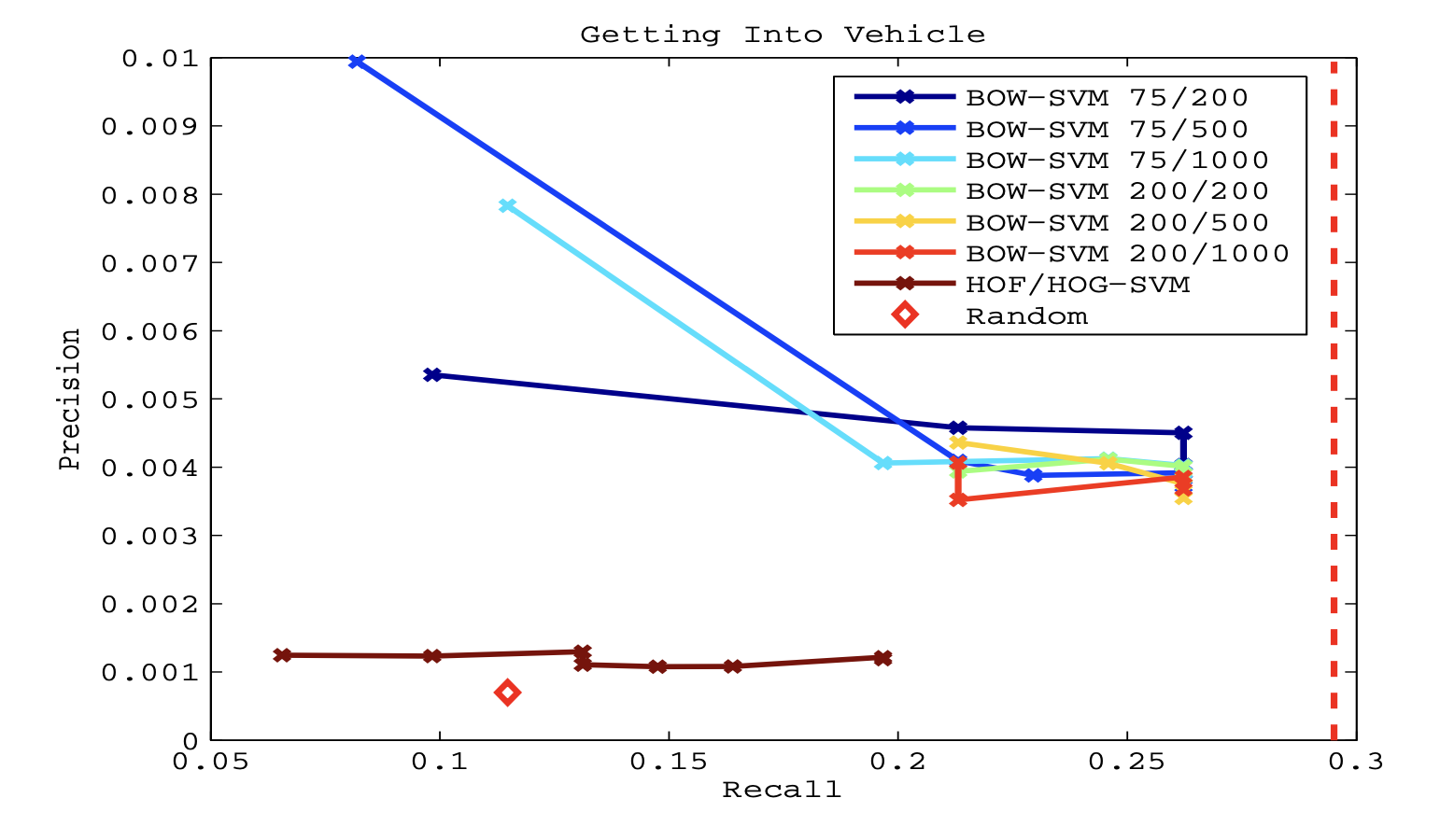
- PR(Precision-Recall) 곡선 분석:
- Fig. 8은 "차량에 탑승(getting_into_vehicle)" 이벤트에 대한 PR 곡선을 보여줌.
- 빨간 다이아몬드: 무작위 성능(random performance)를 나타냄.
- 빨간 점선: 추적 후 잠재적인 최고 재현율(최적 recall)을 나타냄.
3.1.3 Learning-Enabled Recognition Mode
Learning-Enabled Recognition은 기존의 독립적 인식 모드(independent recognition mode)와는 다른 새로운 CVER 평가 방식으로,
장면 내 중요한 패턴(trajectory나 이벤트 우선순위 등)을 학습한 뒤 미래의 인식 작업에 활용하는 것을 목표로 함.
기본 개념
- 학습 가능한 패턴(trajectory priors 또는 event priors)을 현재 장면에서 학습하고 이를 미래의 이벤트 인식에 활용.
- 예:
- 특정 장면에서 객체의 경로(trajectory)를 학습하여 이후 같은 장면에서의 이벤트 인식을 개선.
데이터 분할 및 학습 설정
-
시간 기반 데이터 분할:
- 각 장면(scene)과 이벤트 유형에 따라 ground-truth 데이터를 시간 순서대로 여러 세트로 나눔.
- 테스트 세트에 대한 평가 시, 동일 장면 내의 다른 세트와 다른 장면(out-of-scene) 데이터는 학습에 사용 가능.
-
장면 의존적 학습 지원:
- 동일한 장면 내의 데이터를 학습에 포함하여 장면별 특화 패턴(scene-dependent priors)을 학습할 수 있도록 지원.
-
과적합 방지:
- 공정한 평가를 위해 모든 장면의 일부 데이터를 테스트 전용 데이터로 분리(sequestered).
- 이는 학습과 테스트 데이터가 독립적으로 유지되도록 보장.
결론
- containing diverse examples of multiple types of complex visual events.
- 시계열 기반 데이터
블랙박스의 저해상도 문제 해결시 super resolution의 모델 학습에 적합해보임.
다운샘플링 버전을 사용하는 것도 ...
블랙박스 영상 객체 추적에 도움?
주차장, 도로, 건설 현장, 공터 등 다양한 장면의 영상을 포함하고 있어, 흑백 영상의 컬러화를 학습할 때 현실적인 데이터로 활용이 가능해보임.
시간적으로 연속된 비디오로 구성되어 있어 video interpolation에도 적합한 듯.
평가 및 검증에도.
