
Corpus-based Chatbot (IR based, seq2seq2 based)
여기서는 정보 검색(IR)과 시퀀스 변환(Seq2Seq) 방식 챗봇에 대해서 다룰 예정입니다.
두 방식 모두 기본적인 형태에서는 대화의 맥락(Context)을 깊게 파악하는 데 한계가 있으며, 주로 사용자의 직전 발화에 대한 단일 응답을 생성하는 데 초점을 맞추는 경향이 있다.
Information Retrieval based
정보 검색(IR) 기반 챗봇
- IR 기반 챗봇은 이름 그대로 '정보 검색' 기술을 활용
- 핵심은 새로운 응답을 생성하는 것이 아니라, 기존의 대화 코퍼스에서 가장 적절해 보이는 응답을 '검색(Select)'하여 사용자에게 제공
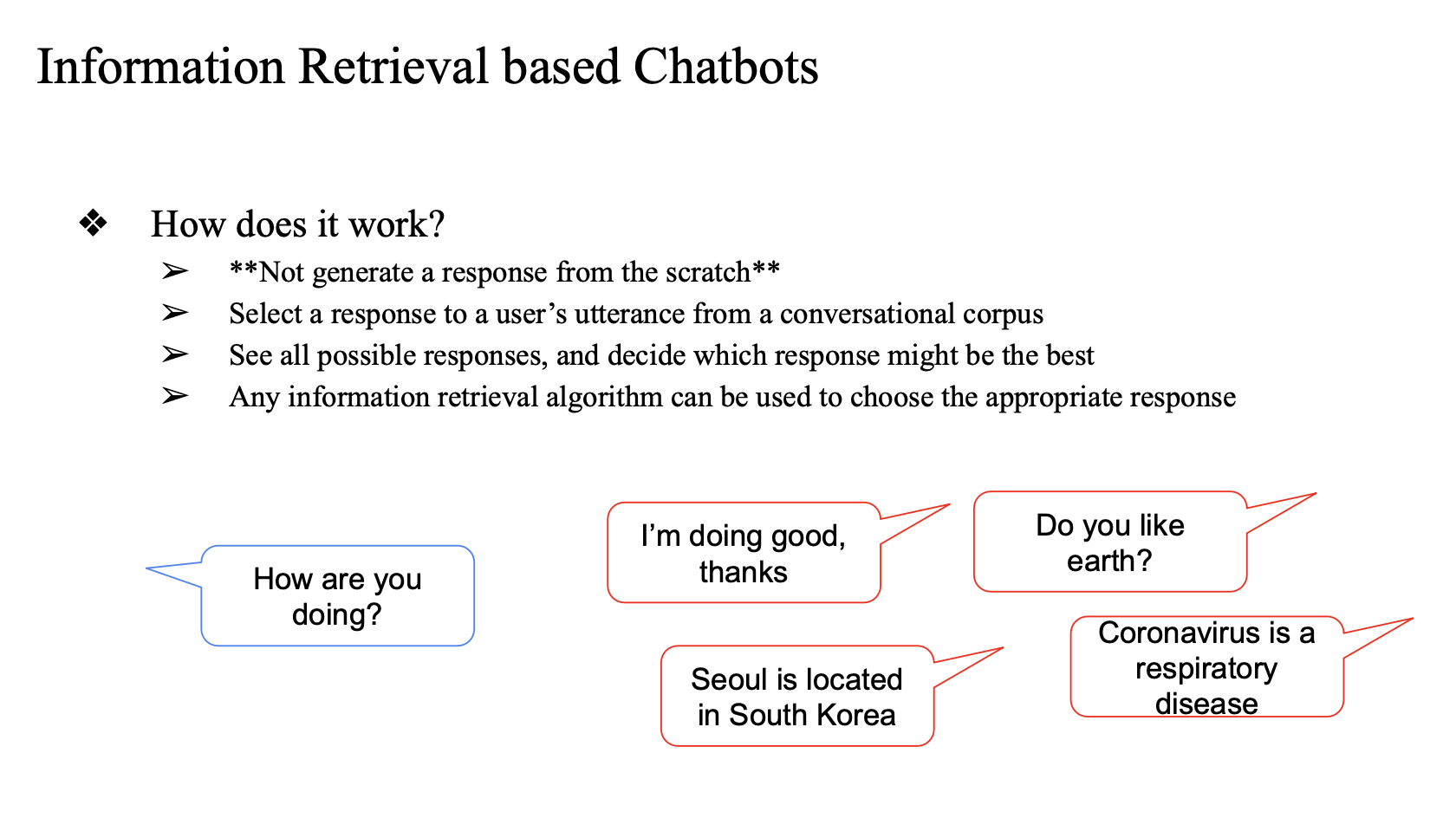
작동 방식
- 응답을 새로 생성하지 않음
- 사용자의 입력(utterance)에 대해 대화 corpus에서 응답 후보를 탐색
- 가능한 모든 응답을 확인하고, 그중 가장 적절한 것을 선택
- IR 알고리즘(예: cosine similarity 등)을 사용해 적합한 응답을 선택
유사한 문장을 찾는 방법
IR 챗봇의 핵심은 “사용자 입력과 가장 유사한 문장을 찾고, 그에 대한 응답을 반환”하는 것.
크게 2가지가 있다.
1. 유사 질문 검색 → 해당 응답 반환

- 사용자의 현재 질문(
q)을 받습니다. - 대화 코퍼스(
C) 내에서q와 가장 유사한 과거의 질문(Turn)t를 찾습니다. (argmax) - 찾아낸 과거 질문
t에 원래 달려있던 응답(response(t))을 현재 질문q에 대한 최종 응답으로 반환합니다.
사용자가 "뉴욕 날씨 어때?"라고 물으면, 코퍼스에서 과거의 유사 질문("뉴욕 날씨는?")을 찾고, 그에 대한 답변("뉴욕은 오늘 맑아요.")을 찾아 응답
2. 유사 턴(Turn) 검색 → 해당 턴 직접 반환

- 사용자의 현재 질문(
q)을 받습니다. - 대화 코퍼스(
C) 내에서q와 가장 유사한 턴(Turn)r자체를 직접 찾습니다. (argmax) (여기서 턴r은 질문일 수도, 응답일 수도 있습니다.) - 찾아낸 턴
r을 그대로 현재 질문q에 대한 응답으로 반환합니다.
좋은 응답은 종종 이전 턴(질문)과 단어나 의미 패턴을 공유하는 경우가 많기 때문
사용자가 "뉴욕 날씨 어때?"라고 물으면, 코퍼스 내에서 이와 가장 유사한 문장 "뉴욕은 오늘 맑아요." 자체를 찾아 응답할 수 있다.
→ 상황에 따라 대화의 흐름을 자연스럽게 잇는 데 유리할 수 있음
Improve performance

IR 기반 챗봇의 응답 품질을 높이기 위해 다음과 같은 추가 정보를 활용할 수 있다.
- 지금까지의 전체 대화 기록 (특히 "응" 같은 짧은 사용자 입력 처리 시 유용)
- 사용자 정보 (나이, 성별, 선호도 등)
- 감성(Sentiment) 정보
- 외부 지식 정보 (뉴스, 위키백과 등)
Machine learned sequence transduction Chatbot (Encoder-Decoder Chatbots)
IR 기반 챗봇과 다르게 기존 응답을 고르지 않고 새로운 응답을 만들어내는(chat-generative) 방식

- 이 방식은 기계 학습 모델, 특히 인코더-디코더(Encoder-Decoder) 구조를 사용하여 입력 시퀀스(문장)를 출력 시퀀스(응답 문장)로 변환(Transduce)하는 방법을 학습하는 방식
- "ELIZA의 머신러닝 버전"이라고 볼 수 있고, 대화 코퍼스로부터 응답 생성 규칙을 시스템이 스스로 학습
- 대표적으로 Seq2Seq 모델이 있음
- 이 과정에는 주로 RNN(Recurrent Neural Network)이나 트랜스포머(Transformer) 같은 딥러닝 모델이 사용됨
Encoder-Decoder Models
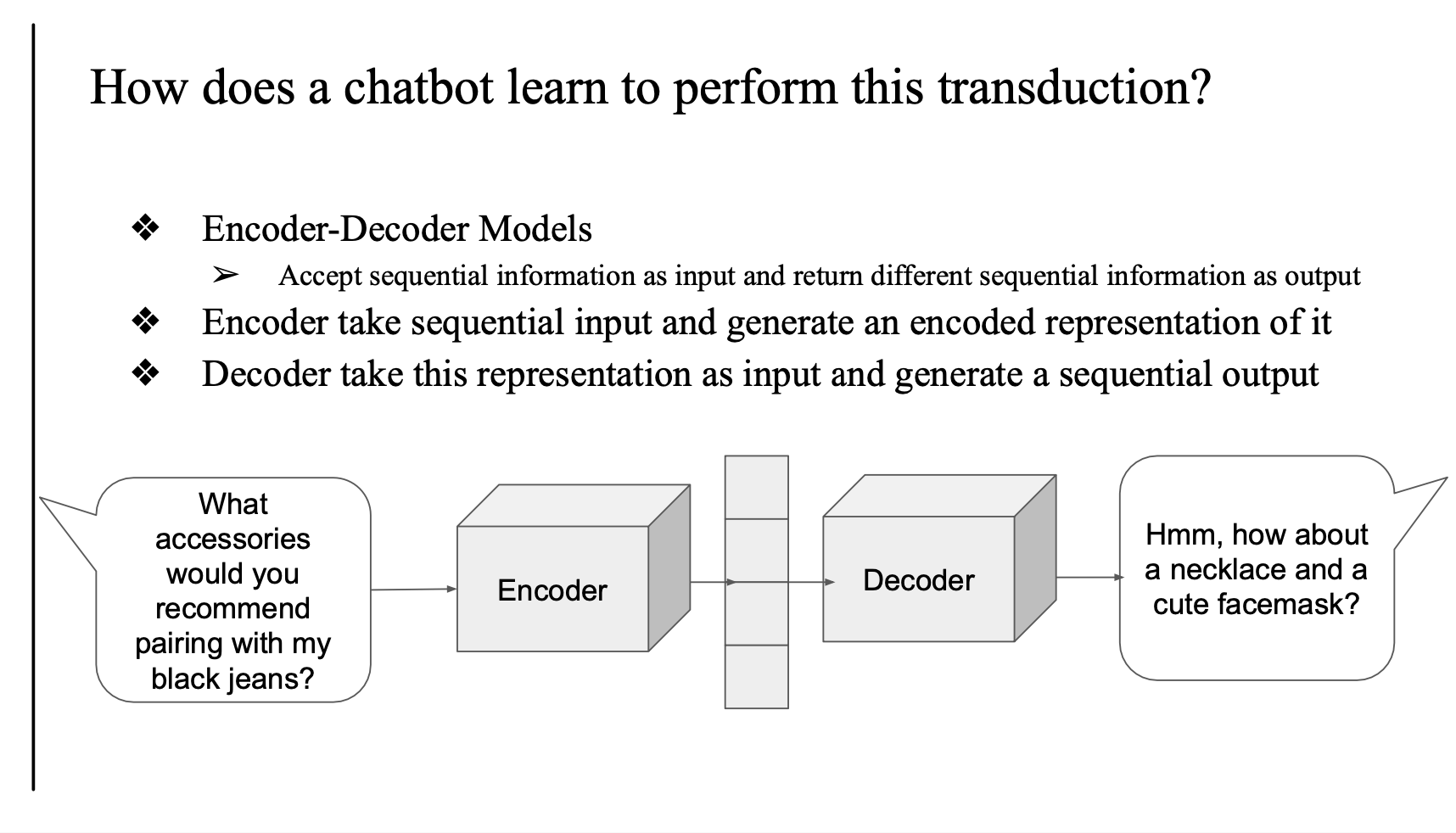
Encoder-Decoder 모델은 시퀀스 데이터를 입력받아 새로운 시퀀스를 출력하는 구조
- 인코더(Encoder): 사용자의 입력 문장을 받아 문맥 정보를 압축한 벡터 표현(Representation)을 만든다.
문장의 의미를 요약하는 단계 - 디코더(Decoder): 인코더가 만든 벡터 표현을 입력으로 받아 응답 문장을 순서대로(Sequentially) 생성
사용자 입력 → Encoder → Context Vector → Decoder → 챗봇 응답
Encoder-Decoder 챗봇의 한계와 해결 방법

Seq2Seq 기반 챗봇은 새로운 문장을 생성할 수 있지만, 다음과 같은 문제점들이 있을 수 있다.
- 반복적이고 지루한 응답 생성
- 응답의 다양성을 높이는 기법 적용 (빔 서치, 상호 정보량 목적 함수 등)
- 이전 대화 맥락 반영 미흡
- 여러 턴의 대화 정보를 요약하여 반영하는 계층적 모델(Hierarchical model) 사용
- 다중 턴 대화 시 일관성 부족 (이야기가 산으로..)
- 강화학습이나 Adversarial Networks(GAN) 을 활용하여 더 자연스러운 대화 흐름 학습
코퍼스 기반 챗봇을 만드는 두 가지 주요 방법, 정보 검색(IR) 기반 방식과 기계 학습 시퀀스 변환(Seq2Seq) 방식에 대해 강의 자료를 바탕으로 알아보았다. 하나는 기존 데이터에서 찾아오는 방식이고, 다른 하나는 데이터를 학습해 만들어내는 방식이라고 생각하면 되겠다..
