
Frame-based Dialogue System
사용자의 요청을 이해하기 위해 slot에 필요한 정보를 채워 넣는 구조화된 대화 시스템
Frame-based Dialogue란?
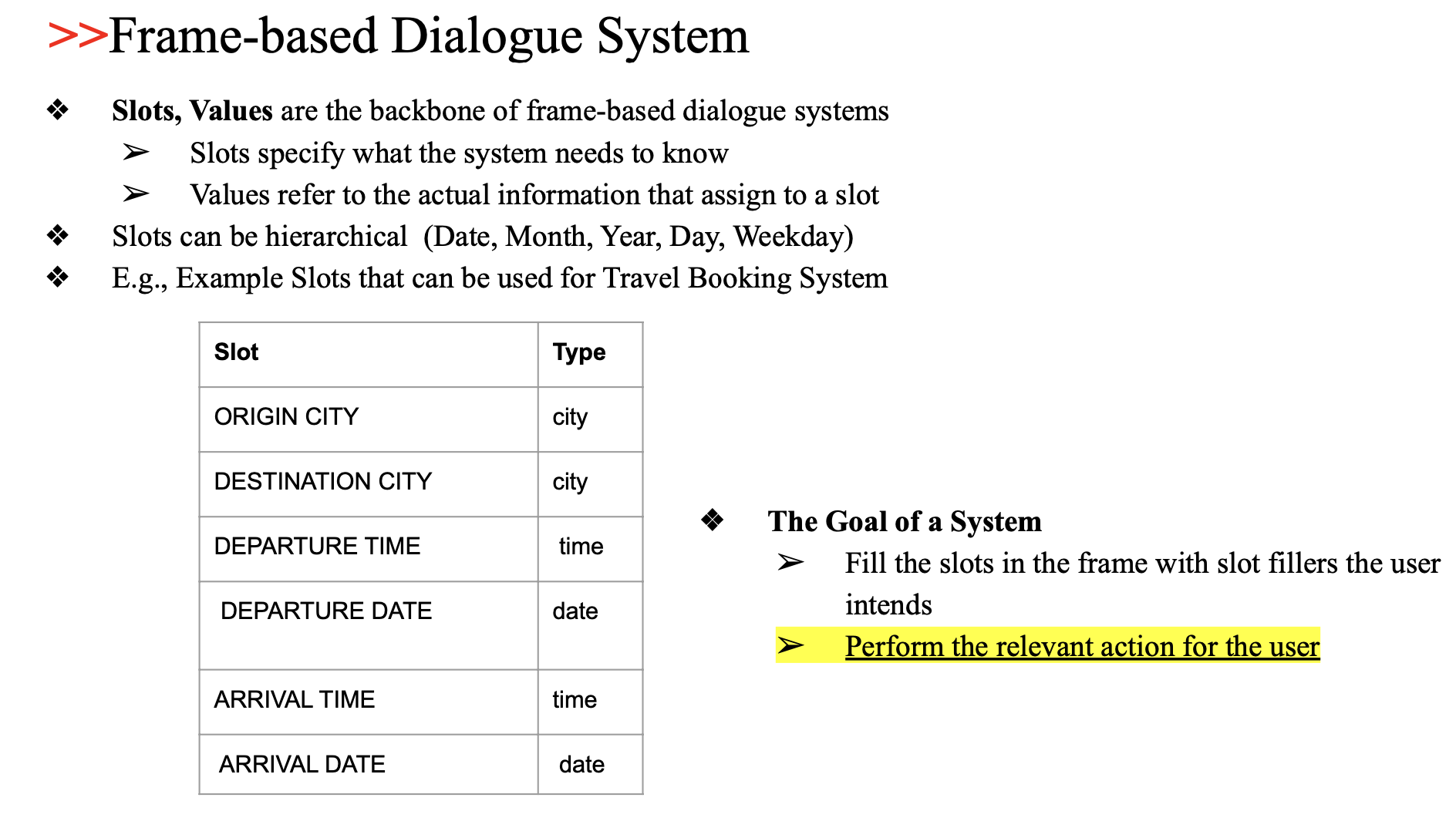
- Slot: 시스템이 알아야 할 정보 항목 (ex. 출발 도시, 도착 날짜)
- Value: 그 slot에 채워지는 실제 값 (ex. "Seoul", "2025-05-10")
The Goal of a System
- 사용자의 입력으로부터 slot을 채움
- 모든 정보가 수집되면, 사용자의 의도에 맞는 행동 수행
(예: 항공권 검색, 호텔 예약)
How it works?
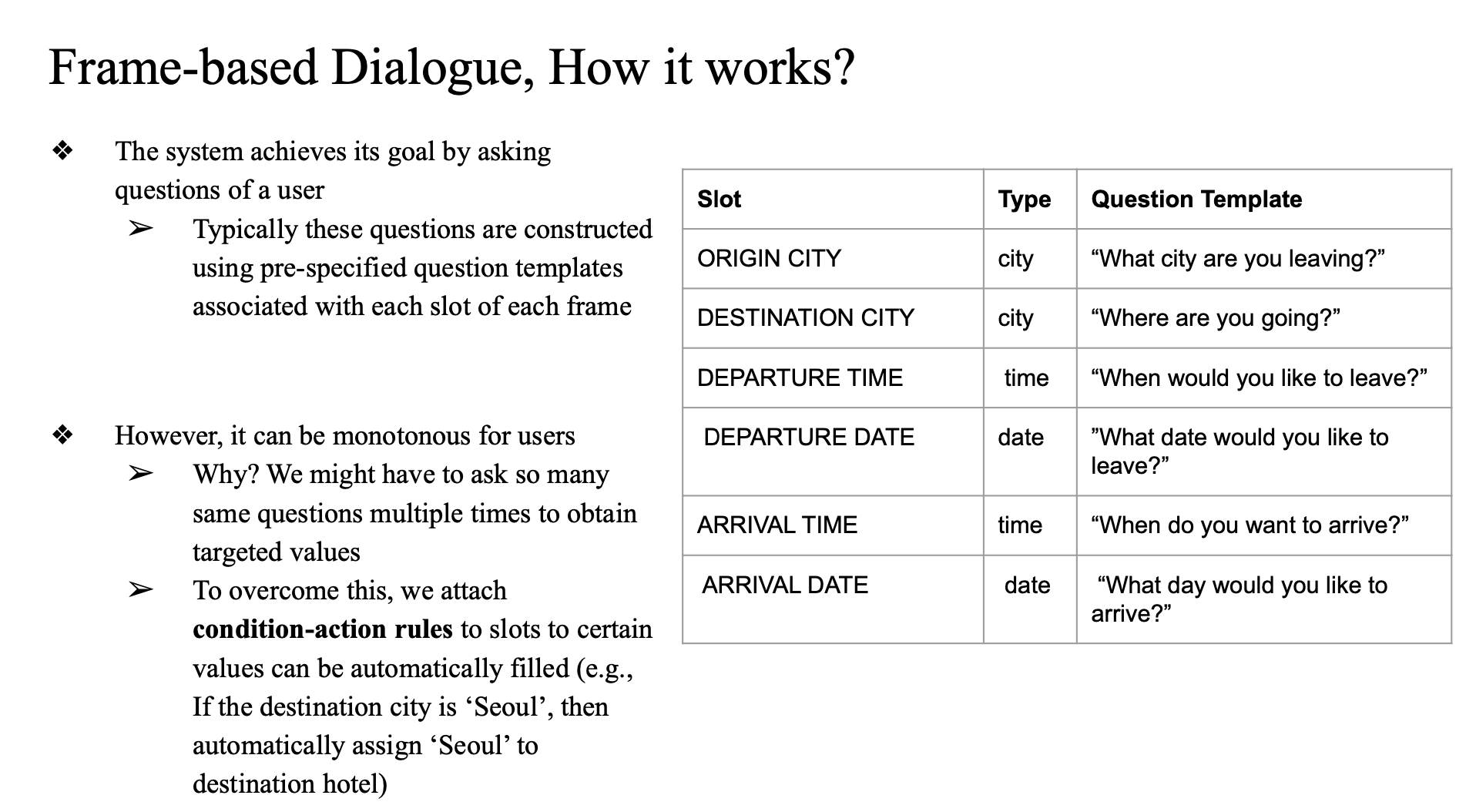
사용자에게 질문을 던져 slot 채우기
- 각 slot마다 사전에 정의된 질문 템플릿을 사용함
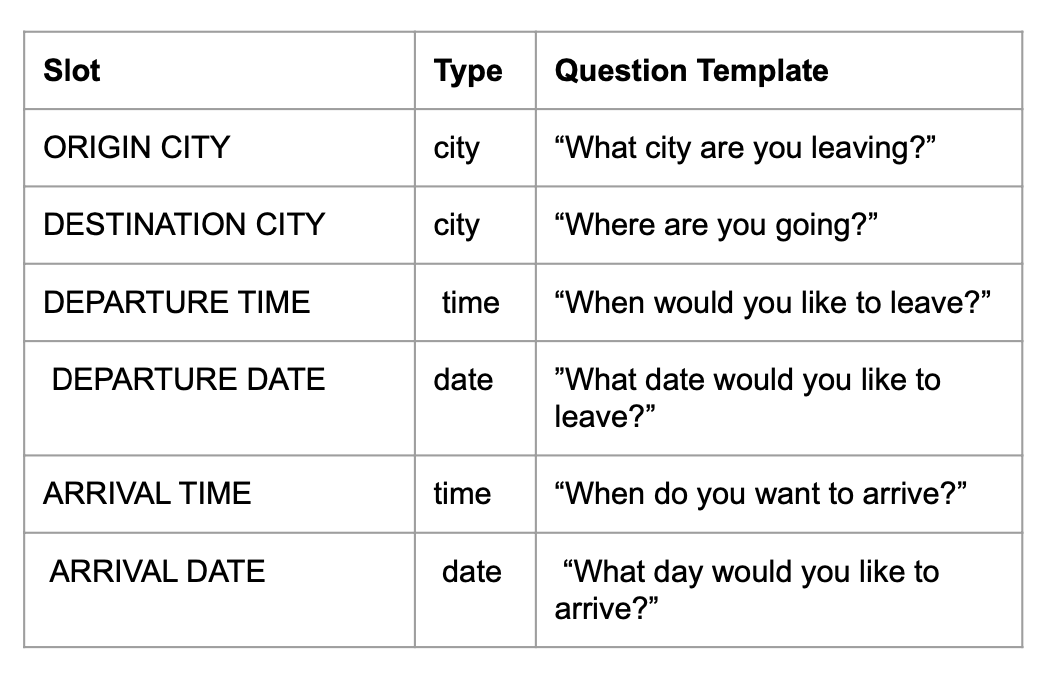
문제점:
질문이 많아 지루할 수 있음
- 반복되는 질문 → 사용자 경험 저하
조건-행동 규칙 (Condition-Action Rules)
- 예: 도착 도시가 'Seoul'이면, 호텔 위치를 자동으로 'Seoul'로 설정
- 이러한 과정으로 질문 줄여나가기..
Multiple Frames

Frame: 특정 목적을 위한 slot 집합
- 여러 도메인에서는 다수의 frame이 필요함
(예: 항공 예약 + 호텔 예약)
disambiguate -> 어떤 frame의 어떤 slot을 채워야 하는지 판별 필요
- 사용자가 "서울로 가고 싶어요"라고 말했을 때, 이것이 '항공권 예약 프레임'의 '도착 도시' 슬롯을 채우는 정보인지, '호텔 예약 프레임'의 '도시' 슬롯을 채우는 정보인지 구분해야 함.
- 이를 해결하기위해 dialogue history와 input type에 기반한
**생산 규칙 (production rules)** 활용 - 대화 기록(Dialogue history)이나 사용자의 입력 유형(Input type) 등을 바탕으로
- 이를 해결하기위해 dialogue history와 input type에 기반한
Frame-based Dialogue에서의 자연어 이해 (NLU)

Frame 기반 시스템에서 필요한 3가지 NLU 작업
- Domain Classification
- 사용자가 어떤 주제에 대해 이야기하는가?
- 예: 비행기 예약, 알람 설정, 일정 관리
- Intent Determination
- 사용자가 무엇을 하려고 하는가?
- 예: "모든 비행편 조회", "일정 삭제"
- Slot Filling
- 어떤 슬롯을 채우려 하는가?
- 예: 출발 도시 = 'Los Angeles', 도착 도시 = 'Seoul'
Slot Filling을 위한 Semantic Grammar

전통적 방식: 수동 규칙 기반 (Rule-based)
- Semantic Grammar 사용
- 좌변: 의미 범주 (예: TIME)
- 우변: 가능한 값 (예: at 7 AM)
"Set an alarm at 7 AM"
- Intent: SET-ALARM
- Slots: TIME = 7, AMPM = am
최근 방식: 지도학습 기반 slot-filling 모델로 자동화 가능
- Instead of rule-based, we can leverage supervised learning for slot-filling
Frame-based Dialogue System의 구성 요소

- ASR (Automated Speech Recognition)
- 음성 → 텍스트
- NLG (Natural Language Generation)
- 템플릿 기반 질문 생성
- 예: "What time do you want to leave ORIGIN-CITY?"
- TTS (Text-to-Speech Synthesis)
- 텍스트 → 음성 출력
Dialogue State Architecture
사용자의 발화를 이해(NLU)하고, 상태 추적, 정책 결정, 응답 생성까지 일련의 구조로 이루어진 전형적인 task-oriented dialogue system의 핵심 구조
기본 구성 요소
- Natural Language Understanding (NLU)
- Dialogue State Tracker (DST)
- Dialogue Policy
- Natural Language Generation (NLG)
Text-based Dialogue State Architecture
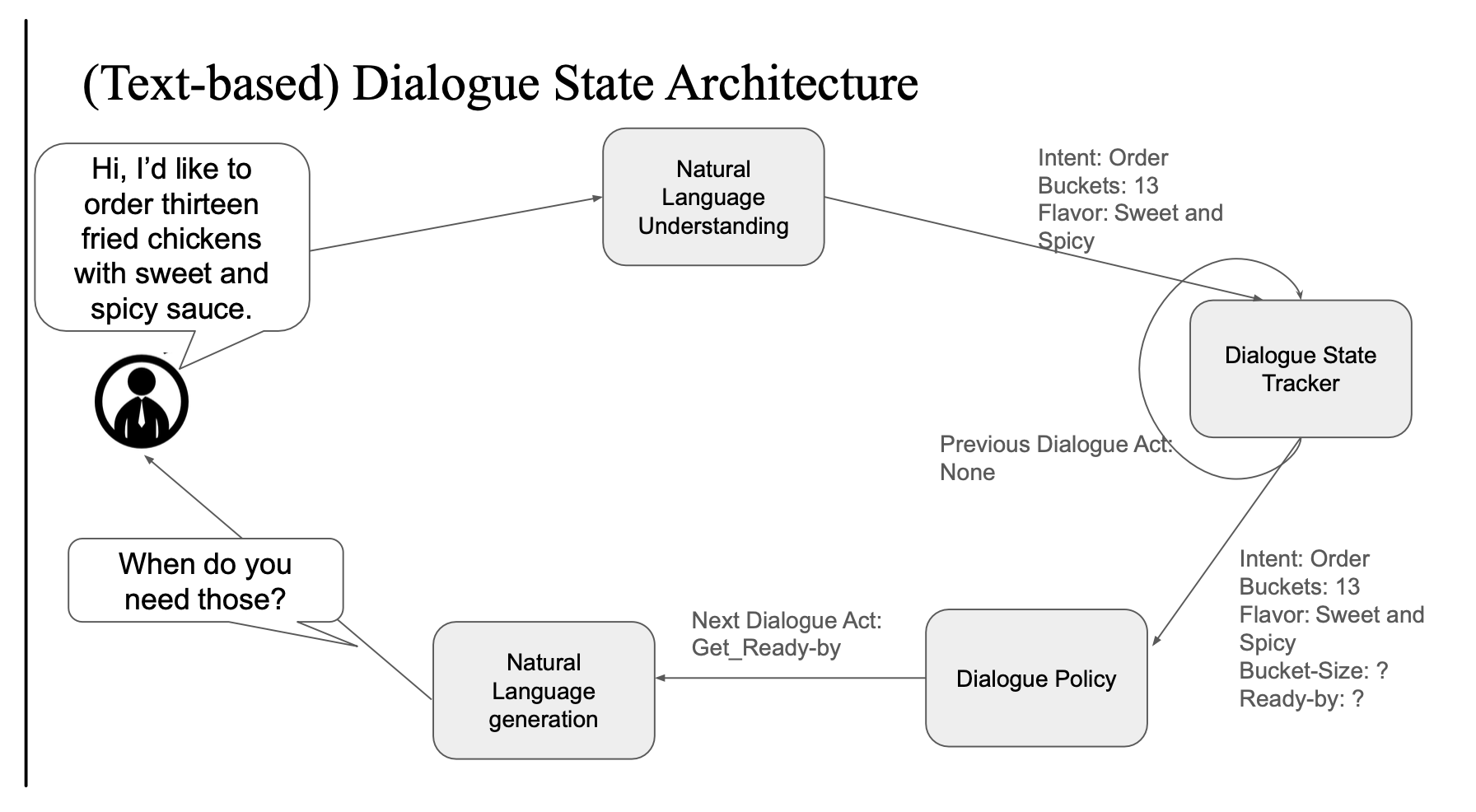
플로우
- NLU (자연어 이해)
- Intent: Order
- Slot: Buckets = 13, Flavor = Sweet and Spicy
- Dialogue State Tracker
- 현재까지 모은 정보:
- Intent: Order
- Buckets: 13
- Flavor: Sweet and Spicy
- Bucket-Size: ?, Ready-by: ?
- 현재까지 모은 정보:
- Dialogue Policy
- 다음 행동 결정:
Get_Ready-by(언제 필요한지 물어보기)
- 다음 행동 결정:
- NLG (자연어 생성)
- 응답: "When do you need those?"
Spoken Dialogue State Architecture
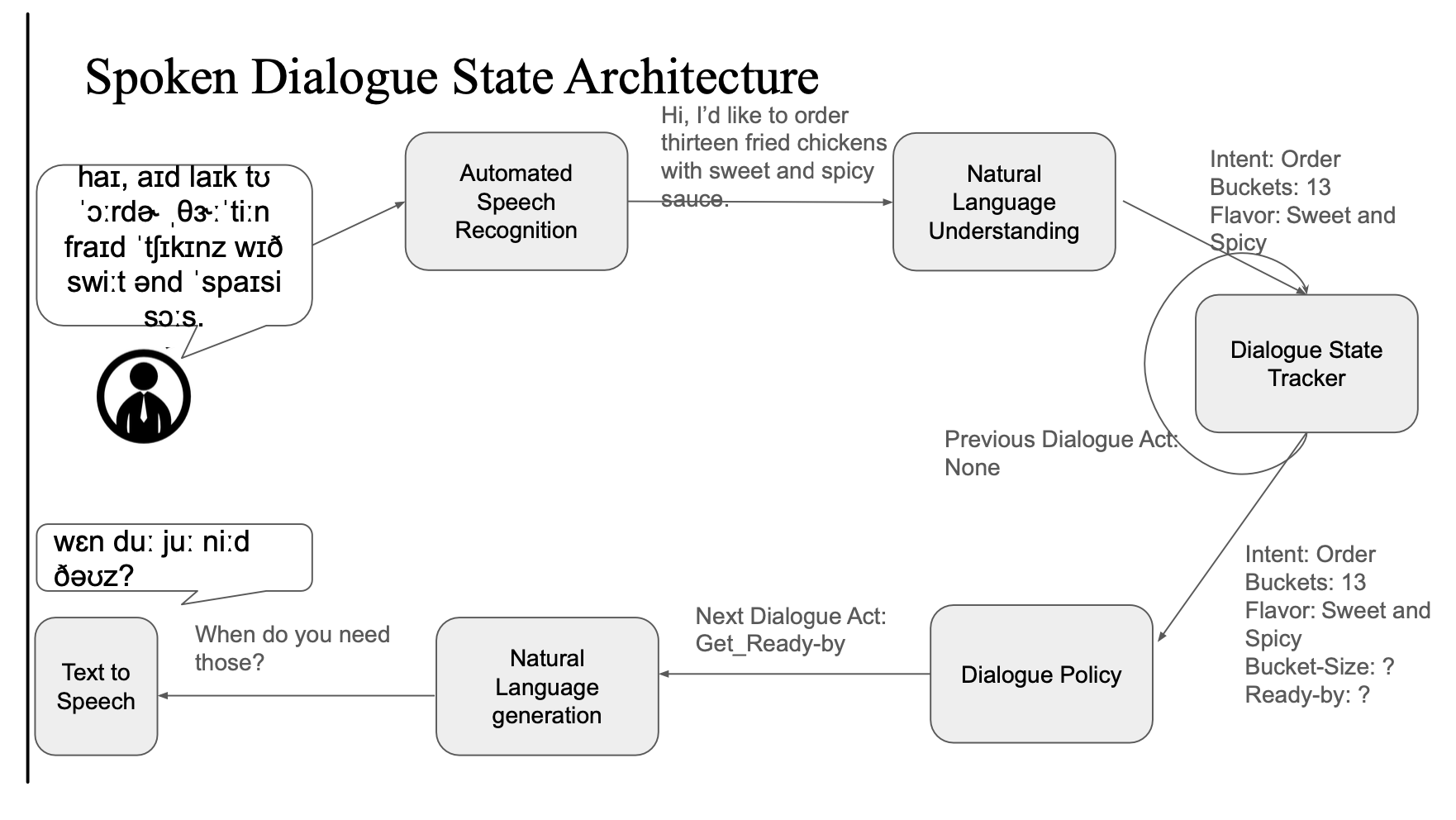
음성 기반 대화 시스템은 여기에 ASR과 TTS 모듈이 추가됨
추가 구성 요소
- ASR (Automated Speech Recognition)
- 음성 → 텍스트 변환
- TTS (Text to Speech)
- 텍스트 → 음성 응답 생성
음성 흐름 요약
- ASR: 음성을 텍스트로 변환
- 이후는 텍스트 기반 아키텍처와 동일
- TTS로 최종 응답을 음성으로 출력
NLU의 역할과 구현 방법

주요 작업
- Domain Classification: 주제 분류
- Intent Determination: 사용자의 목적 파악
- Slot Filling: 필요한 정보 추출
구현 방식
- 전통적: Rule-based, Semantic Grammar
- 현대적: Machine Learning, 특히 딥러닝 기반 모델 (예: RNN, BERT)
학습 예시
Input: "I want to fly to San Francisco on Monday please"
Output: {
Destination: SF,
Depart-time: Monday
}딥러닝 기반 모델은 이러한 input-output 쌍을 학습하여 NLU를 수행할 수 있습니다.
- Dialogue State Architecture는 주로 Frame-based 시스템의 내부 구현 구조로 활용됨
- Corpus 기반 학습이 가능한 구조 (특히 NLU, Policy, NLG 부분)
- 사용자의 발화를 통해 점진적으로 슬롯을 채우고, 목적을 달성
BIO tagging

-
슬롯 필링(Slot Filling)을 시퀀스 레이블링(Sequence Labeling) 문제로 보고, BIO 태깅(BIO Tagging)을 사용하는 방법
-
사용자 발화에서 "출발 도시", "날짜", "시간" 등 필요한 정보(슬롯 값)를 정확히 추출해내는 것이 중요..
-
BIO 태깅은 슬롯 필링 문제를 시퀀스 레이블링(Sequence Labeling) 문제, 즉 문장을 이루는 단어 시퀀스 각각에 레이블(태그)을 붙이는 문제로 접근
핵심 아이디어:
문장의 각 단어마다 BIO 태그 중 하나를 붙여서, 그 단어가 어떤 슬롯 정보의 시작인지, 이어지는 부분인지, 아니면 슬롯과 관련 없는지를 표시
BIO 태그:
B(Beginning): 특정 슬롯 값이 시작되는 단어를 나타냄. (B-[슬롯타입]형식, 예:B-DES)I(Inside): 특정 슬롯 값이 이어지는 단어임을 나타냄.
(슬롯 값의 두 번째 단어부터 해당) (I-[슬롯타입]형식, 예:I-DES)O(Outside): 어떤 슬롯에도 속하지 않는 단어임을 나타냄.
시스템이 인식해야 하는 모든 슬롯 타입(slot-type)에 대해
B태그와I태그를 만듦 예를 들어 목적지(Destination) 슬롯이 있다면B-DES와I-DES태그를 만드는 식
Bootstrapping

머신러닝(ML)으로 슬롯 필링(Slot Filling) 모델을 만들려면 보통 잘 레이블링된 학습 데이터가 많이 필요한데, 현실적으로 처음부터 이런 데이터를 구하기는 쉽지 않음
부트스트래핑 과정:
부트스트래핑은 마치 '신발 끈을 스스로 당겨 올린다'는 의미처럼, 작은 시작점을 활용해 점차적으로 더 나은 결과물을 만들어가는 과정을 의미합니다.
- 부트스트래핑은 수동으로 레이블링된 데이터가 부족할 때 유용한 기법입니다.
- 간단한 시스템으로 시작해서 자동 레이블링과 모델 재학습을 반복
-> 점진적으로 머신러닝 기반 슬롯 필링 모델의 성능을 끌어올리는 현실적이고 효율적인 방법
