
ch14. Retrieval Augmented Generation (RAG)

LLM의 한계
-> hallucination 할루시네이션
세종대왕 맥북프로 던짐사건..
Retrieval Augmented Generation (RAG)
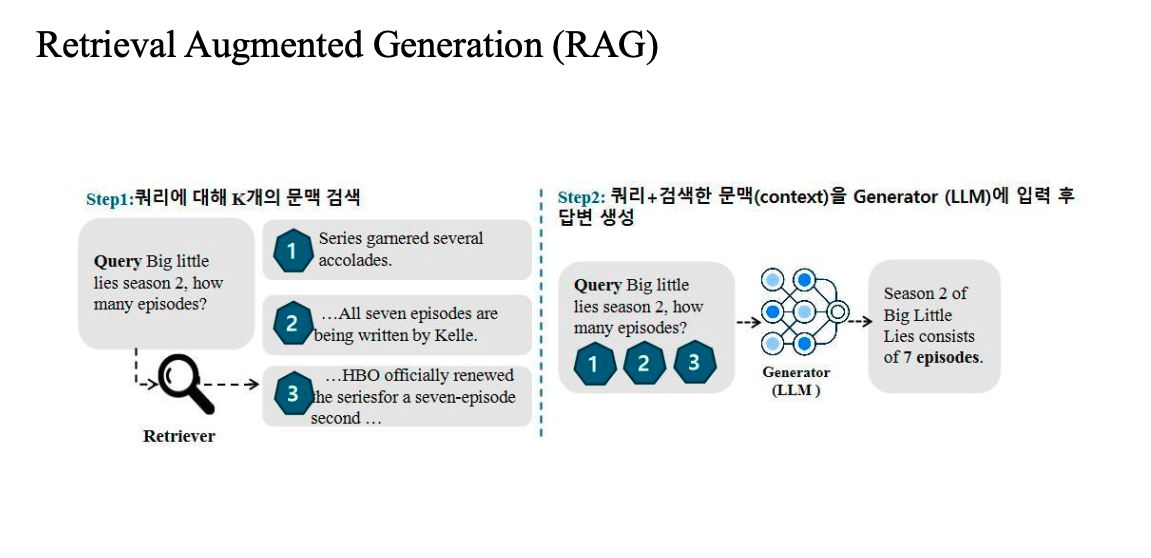
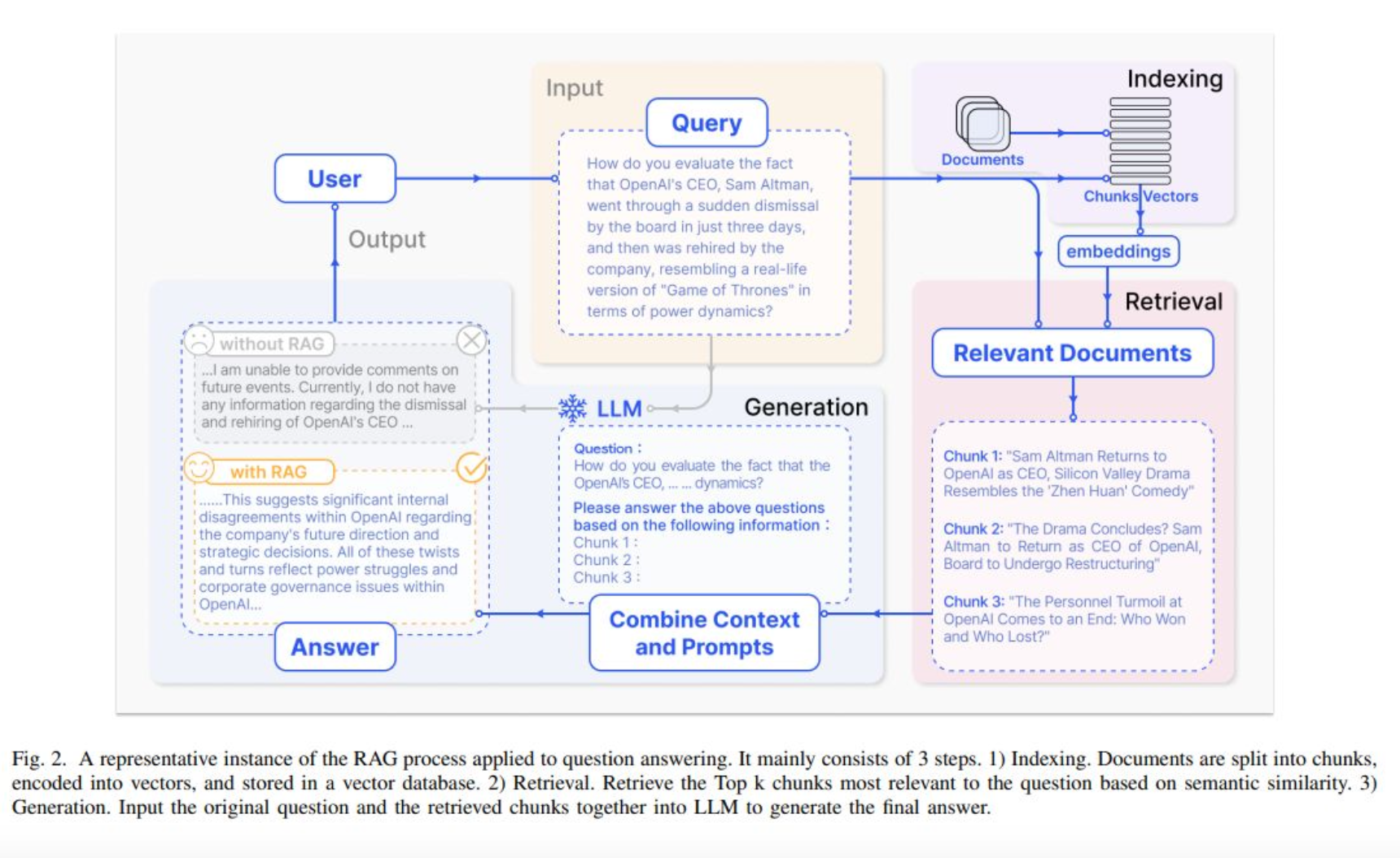
indexing

외부 db 프로세싱
병원에 대한 모든 컨텐츠들 → 외부 db를 만들어야함 → 청크단위로 벡터 → 벡터 디비
이 과정을 인덱싱이라고 함
자연어로 그대로 정리하면 매우 비효율적
Retriever

Retriever란?
- 검색 시스템에서 핵심은 사용자의 쿼리(query)와 관련된 문서(document)를 찾는 것
- 이를 위해 쿼리를 벡터화(embedding)해서 전체 문서들과 비교함
- 벡터 간 유사도를 계산해 가장 관련 있는 문서를 찾아냄
Query → 임베딩 (벡터화) → 문서들과 비교 → 관련 문서 검색
Sparse Retriever
• 대표 예시: TF-IDF, BM25
→ 둘 다 희소(sparse) 벡터 기반임
• 문서 내 단어 빈도(TF)와 전체 문서에서의 희귀도(IDF)를 고려해 점수 계산함
• 의미보단 단어 매칭 중심
• 임베딩 거의 없음, 단어 카운트 기반
• 학습 불필요, 빠르고 안정적
• 특히 새로운 도메인에서도 잘 작동함 → Generalization(일반화) 강함
Dense Retriever
• 쿼리와 문서를 임베딩 모델로 벡터화해서 연속적 공간(dense space)에 맵핑함
• 이 벡터는 단어 의미(semantic)를 반영함 → 의미 기반 검색 가능
• 학습 가능 → 도메인 적응성 높음 (유연함 있음)
• BERT, DPR, ColBERT 등에서 사용됨
⚠️ 한계점
• Dense Retriever는 학습이 잘 되어 있을 때는 성능 좋지만,
• 새로운 도메인에서는 BM25보다 성능 떨어질 수 있음
→ 이유는 일반화가 어렵기 때문임
→ 학습 데이터에 의존하는 특성 때문
리트리버가 어쨌든 top k 개의 context를 가져오는 기법
어떤 벡터 표현이 sparse 한 벡터를 만들어내는 벡터 retresentation 을 쓴다면... sparse retriever
top k가 아니라
벡터 표현을 어떻게 하느냐가 더 중요하게 생각하는 ..
벡터 표현이 sparse 냐 아니냐.. 아니면 dense냐..를 생각하는 것이 더...
Contrastive learning
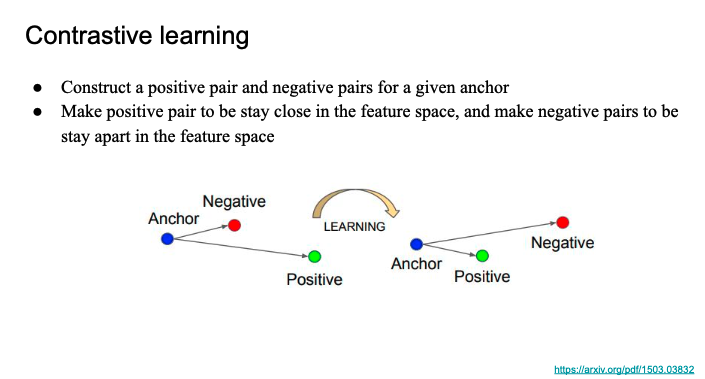
대조학습
- 기준(anchor) 하나를 정하고,
- 유사한 쌍(positive pair)과
- 비유사한 쌍(negative pair)을 만들어서
- 모델이 이들을 구별하도록 학습시킴
- Positive pair는 서로 가깝게
- Negative pair는 멀어지게
- 이걸 feature space (벡터 공간)에서 수행함
즉, 쿼리와 관련 문서는 가까이, 무관한 문서는 멀리 떨어지게 학습시킴
A limitation of using strict supervision, DPR

영어외의 언어는 라벨 데이터셋이 별로 없음,
다국어 환경은.. 어려움..

ms marco -> 영어로 되어있음 -> 한국어는 벡터화를 못 하는 한계점
-> ms marco 에 너무 특정지어서 사용하지말자... -> DPR 논문에서 제시
dense retriever 만듦 -> 어떤식으로 sim score 계산하는지...

DPR이 어떻게 모델 내부에서 지식 저장 방식에 영향을 미치는지..?
DPR을 training하는 과정이 끝나면 -> 모델이 나옴
그 훈련하는 과정에서 모델은 동일한 정보를 다양한 문맥으로 학습을 하게 되고,
-> 이 정보는 네트워크 전반에 걸쳐서 저장되게 된다.
-> 여러 경로를 통해서 같은 지식에 도달할 수 있다........
????
모델이 단일 지식 저장소에 의존하는 대신 네트워크 전반에 분산 저장하는 역할을 하더라...
이렇기 때문에 다양한 질문이나 context에 대해서도 유연하게 정답을 끌어낼 수 있는 회복력을..주었다...는 결론...

결국 QA데이터셋이 존재해야 학습이 가능함
- 일반적인 위키 (label이 없는, passage data) 로는 불가능할까?
- 이전 방식에서는 dense retriever 를 만들기 위해서 했던 방식은 쿼리를 위한 BERT모델을 하나 뒀었고, 그 다음에 candidate 컨텍스트(top k) 의 벡터화는 또 다른 BERT 인코더로 하는... 각각 다른 범주의 인코더를
사용해왔음- 근데 이렇게 하면 하나의 모델이 쿼리도 벡터화, 컨텍스트도 벡터화 하는 것이 상식적으로 맞지 않나??
두개의 인코더 사용 -> 인터렉션을 잘 캡쳐할 수 없을 것이다..
그러한 dense retriever 를 만들어보자...
-> Contriever
Contriever

어떤방식?
-> one encoder -> 쿼리 벡터화 + 컨텍스트 벡터화 (동일한 BERT 모델로 진행)
위키 데이터(레이블 없는)를 가지고 constrative learning ..
postive negative set 을 어떻게 구성할 것이냐가 핵심
-> 위키 문서 읽고 랜덤하게 두개로 나눔
-> 첫번째를 쿼리로 만들고
-> 두번째를 positive로 만듦
-> 그 문서에 있지 않은 임의의 조각(쿼리나 positive pair로 썼던..) 을 negative로 만들어줌
-> 꽤 작동을 잘 함..
예전에는 MS marco -> open qa(constrative learning) -> wiki data(one encoder, unsupervised learning)
Limitation: Contriever

임의로 나누기(query + positive pair) + next chunk 를 neagative로 설정인데
임의로 나눈 것이 과연 적절할까?
-> 해결하기 위해서 paper 등장
Retriever 염려점..

리트리버는 덴스 리트리버를 쓰는데
인덱싱 과정에서 sparse 한 벡터 표현을 사용해서 어떤 데이터 소스를 sparse vector representation 으로 저장을 해놓았다면
그러면 retriever가 검색을 해올 때, 벡터DB에 있는 벡터 값(sparse)이랑 쿼리 벡터 값(dense)이랑 통일성이 없음
-> 이 두 값을 곱해서 sim 값을 구할 수 있는가?
-> 괜찮은가???
-> 괜찮지 않을 수 있음 -> representation space(vector space)가 완전히 다름 (내적, 코사인유사도 무의미해질 수 있음)
그럼 어떻게 극복?
- dual indexing
- 하나는 sparse한 인덱스, 하나는 dense 인덱스를 따로따로 가져가는 경우(실제로 많이 씀)
- dense <-> sparse 변환 모델링 가능
논문에서도 sparse, dense 를 같이 가져가는 구조를 많이 사용하게 됨.
Paradigms of RAG
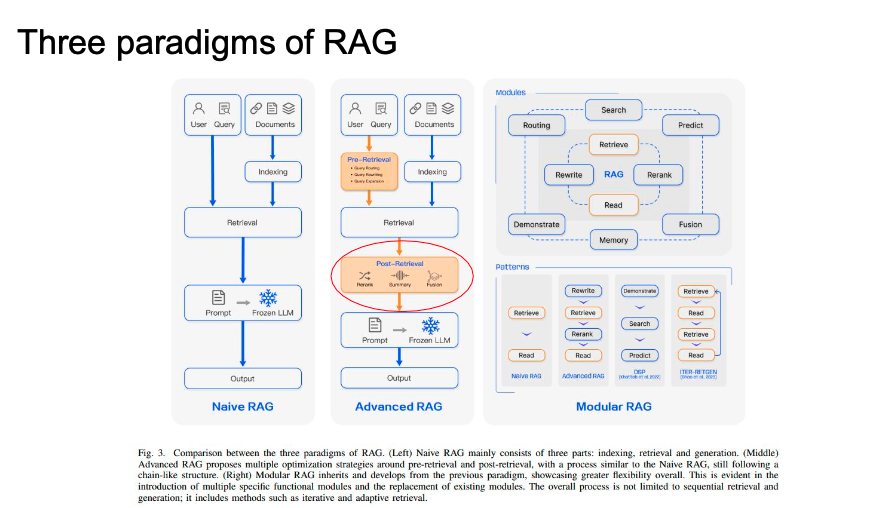
rag system의 진화
- query processing
- post retrieval
RE-RAG
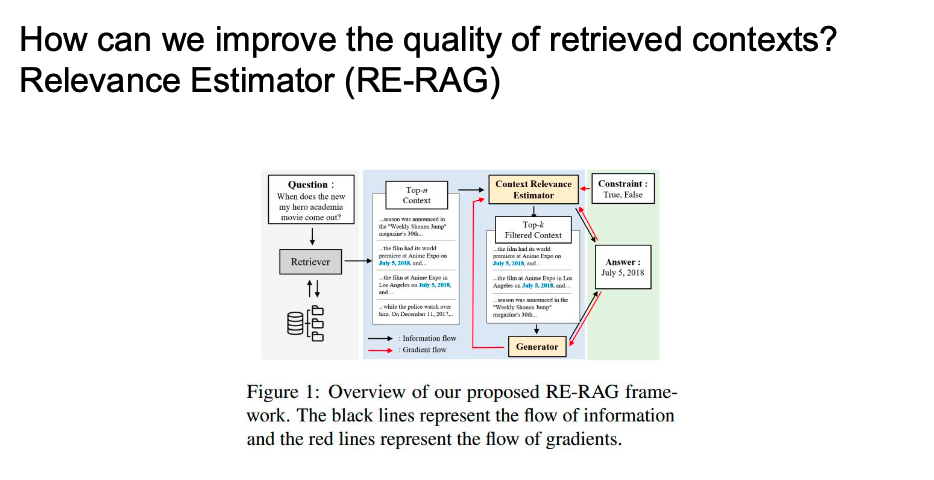
relevance estimator 모듈을 추가해서 retrieve 된 context 중에서 prompting 에 관여할 수 있게끔...
Q가 들어왔을 때 top k 개 뽑기
-> llm의 Input 으로 넣기가 naive한 flow인데
Relevance Estimator(RE) 가 top k 에서 relevant한 n개를 또 뽑겠다는 것
- 여기서는 relevance estimator 가 generator 와 상호작용 하면서 훈련하게 된다...
- gradient flow라는게 training 이 어떻게 일어나는지 알 수 있는데
- 정답에 대해서도 영향을 받아서 weight 를 업데이트하고..
- 서로 scoring 을 가지고 영향을 준다는 것 -> Joint training
- 이런 상호작용 매커니즘을 꼭 넣는다...
- gradient flow라는게 training 이 어떻게 일어나는지 알 수 있는데
Generator

예전에는 LLM보다는 비교적 작은 모델을 Generator로 사용했었음
동시에 retriever, generator 를 학습시키는 것이 가능했음(물론 따로도 가능)
근데 요즘에는 리트리버는 따로 training하고, generator 는 LLM을 사용

joint training
- workflow
- 리트리버는 문맥을 가져오고 쿼리에 대해서 얼마만큼의 유사도(scoring)을 generator 도 같이 전달
- next token prediction 할 때 이 값을 반영을 함...
- retirever가 가지고 온 정보를 가지고 상호작용를 하게 된다...(bridging)
-> joint training 이 가능하다...
- retriever 와 generator 를 동시에 training한다..
- retriever 가장 연관되어 있는 문맥을 가져오기.
- generator 는 정답을 잘 도출하는 것
- next token prediction 과 관련된 training objective를 가지고..
- 각각 트레이닝을 함(둘 다)
- 근데 핵심은 이 두개가 서로 상호작용 할 수 있게끔 하는 매커니즘이 들어가게 됨
Training Free
RE-RAG, Training

https://arxiv.org/abs/2406.05794
context를 가지고 오면서 쿼리와의 연관성 점수를 매김
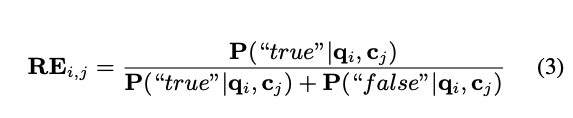
context와 query 를 가지고 연관성 점수를 측정
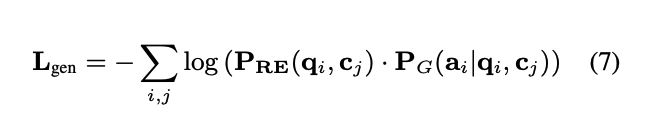
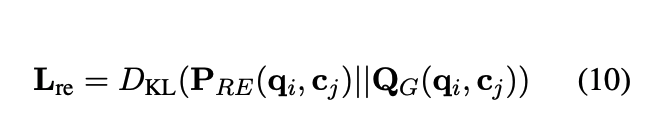
generator, relevance 의 목적 함수를 구하고 이 둘을 더해서 전체적인 RAG시스템을 위한 Training 을 하게됨
(서로 영향을 주게끔 설계를 한다...)
...
여기까지는 이해됐는데..
결과적으로는 RE는 context에 대해서 True, False를 생성...
Query Processing

쿼리를 다시 쓰는 방법을 채택하는 경우가 꽤 많음 (혹은 확장)
- Query rewriting
- input -> retrever -> doc -> llm -> output
- 이걸 개선
- llm이 쿼리를 재정비 (rewriting)
- 쿼리 여러개 만들기 (하나만 쓰는 게 아니고 비슷하게 여러개 많이...)
- 쉽게 놓칠 수 있는 여러 개를 다시 재생성
- retrieval 하고 docs 모아서 llm output 진행
- llm이 쿼리를 재정비 (rewriting)
- 최근에는 query rewriting 을 llm을 쓰지 않고 작은 모델을 쓰자(T5)
- 강화학습을 여기서 적용해보자...
- 사용자가 쿼리를 주면
- 비슷하게 여러개 만들기 -> expansion (많이 늘리기, 수를 늘리는 작업)
- 더 정교화 시키기 -> rewriting(구채화, 상세화)
