
ch13. Context Free Grammars (Constituency Parsing) and Dependency Parsing
Context-Free Grammars

문장은 단순한 단어의 나열이 아니라, 계층적 구조를 가지고 있다.
이 구조는 구성소(constituent) 단위로 쪼갤 수 있으며,
각 구성소는 다시 더 작은 단위로 나눌 수 있는 트리 구조(tree structure)로 표현할 수 있습니다.
- 예를 들어, 문장은 명사구(NP)와 동사구(VP)로 나눌 수 있고,
- 명사구 안에는 명사, 형용사, 전치사구 등이 포함될 수 있음.
이러한 구조는 구문 분석(Constituency Parsing)을 통해 명확하게 드러남..
트리그릴때 internal node 는 품사나 태그를..
리프 노드에는 단어를..
Tree
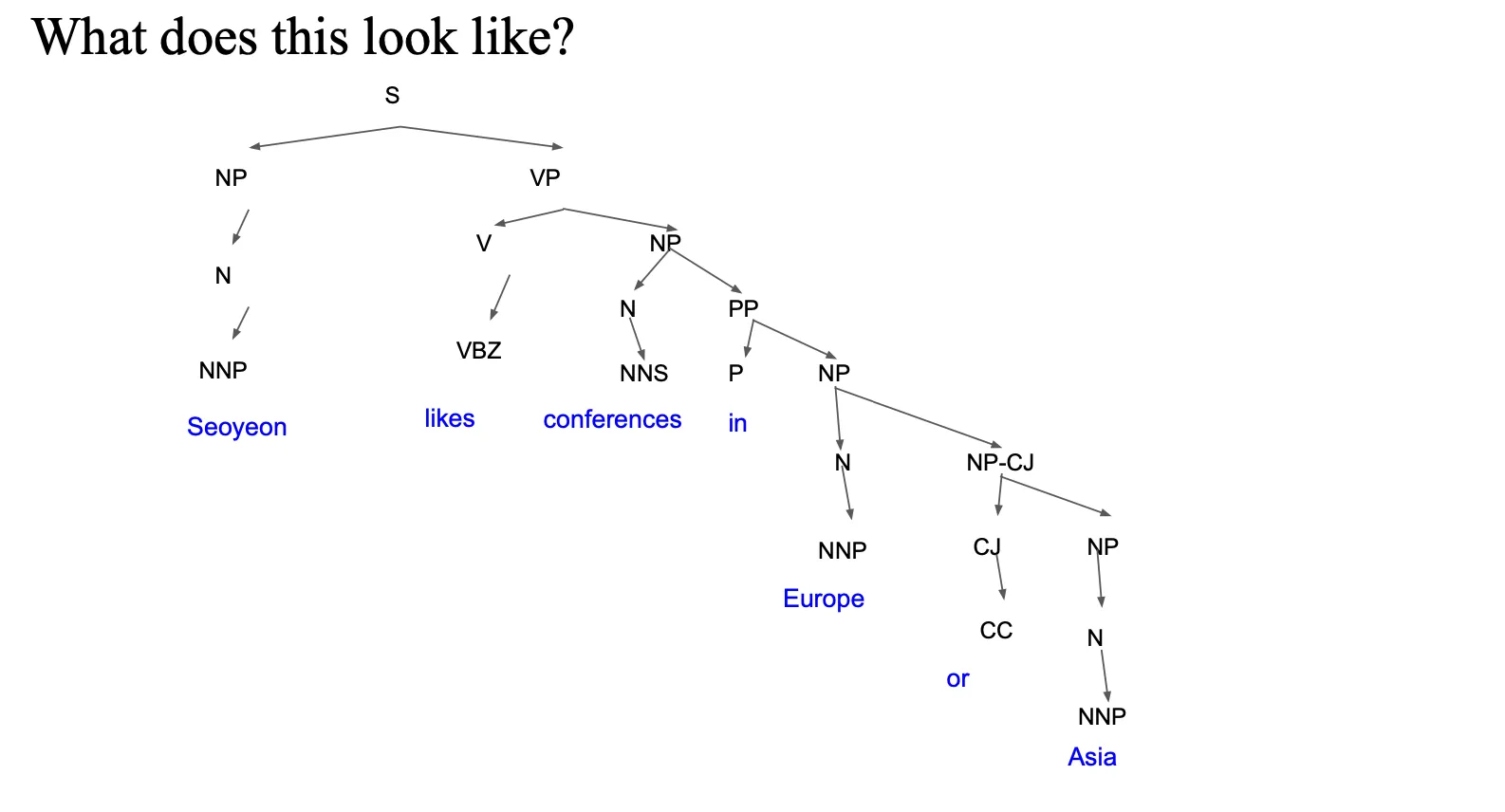
계층적인 것을 확인할수있음
문장이 주어졌을때 구성소들간에 관계. 이해를 하기 위해서 구문분석을 한다…
이 트리를 머신이 자동으로 그리게 하고 싶다.. -> 그러면 룰(rule)이 필요함
어떤 룰을 참고해서 트리를 그리게 하고 싶은 거임..
그 룰들의 집합체 → context - free grammars
The grammars defining these hierarchical trees are context-free grammars.

구문분석을 위한 문법
phrase-structure grammar 도 같은 의미
CFG → 머신이 룰을 찾게 하게끔 문법을 제공함

rule 안에 rule을 만들어서 계층적으로 구성해놓을 수 있다..

구 안에
head 냐 dependent냐… 로 구분해놓을 수 있다
명사구가 있다면?
head → woman, conference : 주체
dependent → 꾸며주는 말, 의존
헤드냐 dependent이냐…로 단어별로 구분할수있다..
more about dependents

dependent 중에서도
- arguments: 반드시 있어야 하는 요소 (필수)
- adjuncts: 없어도 되는 요소 (옵션)
예시:
- “Natalie likes conferences.” → O
- “Natalie likes.” → X (목적어가 빠짐)
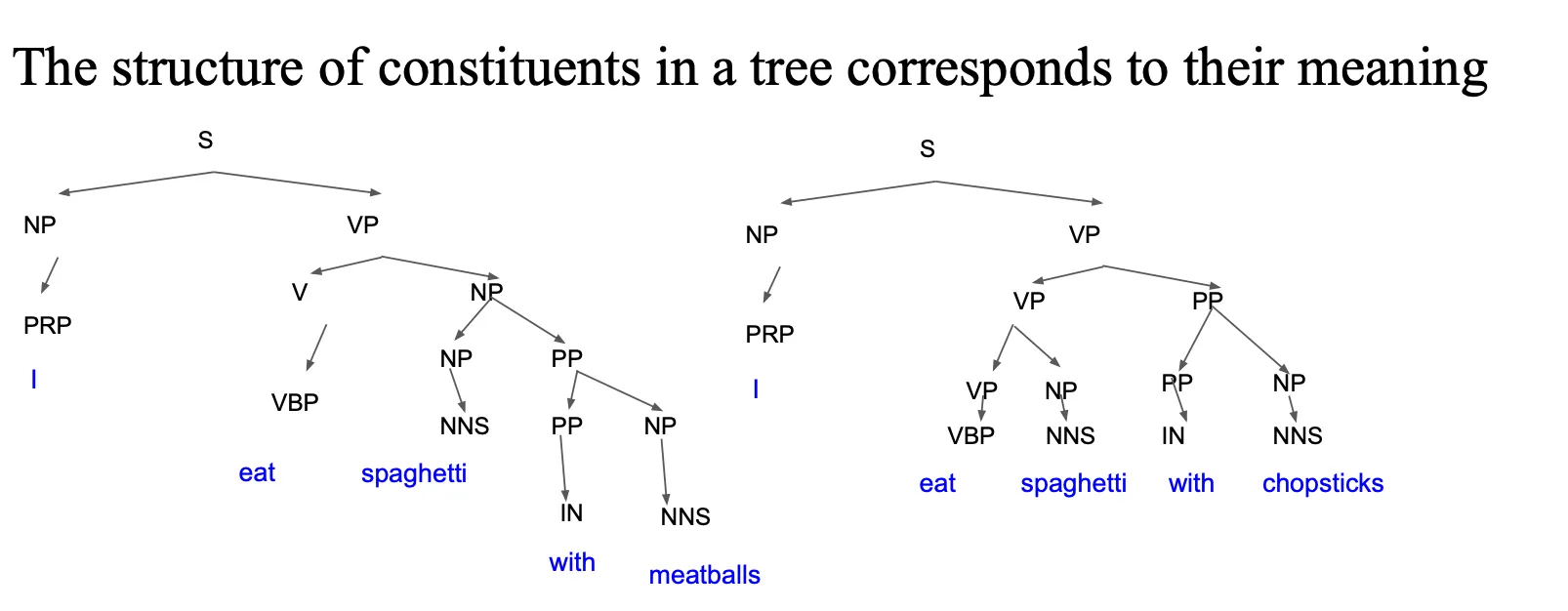
단어 하나 차이로도 전체 구조 달라질 수 있음
→ 문장을 더 정확하게 이해할 수 있는 단서 제공함
Case Example

문장 구조 보기
Time flies like an arrow.
문장은 겉보기엔 단순하지만, 다양한 구조적 해석 가능함
→ CFG로 어떻게 분석되는지 보는 게 포인트임
Production Rules (생성 규칙)
해당 문장을 분석하기 위해 사용된 생성 규칙들:
S → NP VP
NP → N | DET N
VP → V NP | VP PP | V
PP → P NP
P → like
V → flies | like
N → time | fruit | flies | arrow | banana
DET → a | an
다양한 의미 해석 가능성
CFG만 있으면 가능한 구조 여러 개 생성됨 → 문장 해석 다르게 가능
구조 1. “시간은 화살처럼 날아간다”
- Time (NP)
- flies (V)
- like an arrow (PP)
➡️ 정상적인 해석
➡️ flies는 동사, like는 전치사
구조 2. “파리들을 화살처럼 좋아한다”
- Time (N)
- flies (N, 복수명사)
- like (V)
- an arrow (NP)
➡️ 비정상적 해석 같지만 CFG 상으론 가능함
➡️ CFG는 문맥 모름, 단어 의미 구별 못 함

S = np + vp 로 시작
np 가 어떤 것으로 분리될수있을까?
np = n 으로 확장, vp 도 3개 중에.. 하나 고르기.. 이런식으로 쭉쭉..

구문분석을 완벽하게 했다고 하더라도 사람이 이해하거나 그럴싸한 문장을 만들수있다라거나 그런 문장이다라는 건 아니다..
CFG는 트리 구조만 만들 수 있음
어떤 해석이 더 자연스러운지는 사람이 판단해야 함
CFG는 모호성(ambiguity)을 처리하지 못함 → 가능한 구조 다 만들어냄
규칙을 추가한다면??

center embedding이 반복적으로 계속 구성되어있다면 (관계절 안에 관계절 안에 …)
→ 사람이 이해하기 되게 어려운 문장임에도 불구하고
→ 머신이 구문분석을 해낼 수 잇음
→ 그렇다고 이게 사람이 이해할만한 문장이라고… 볼 수 없음..

CFGs are unable to capture bounded recursion (e.g., embedding only one relative clause)
제한된 recursion 이 있는 겨우(한번)
구문분석은 하는데, 중첩 임베딩이 있다고 인식(구문분석은 하지만 이게 사람이 이해할수없다라는 것을 알 수 없음, 이런 복잡함을 인지하지 못함)을 하지 않음

Top-Down 방식
- 시작 기호(S)부터 내려오며 파싱
- 규칙 잘못 선택하면 정답에 도달 불가
- 문법적으로는 맞는데 입력이랑 안 맞는 트리 만들 수도 있음
Bottom-Up 방식
- 단어(단말 노드)부터 올라가며 파싱
- 실제 입력에 기반하므로 입력과 일치
- 하지만 중간에 규칙 적용 못 해서 partial tree로 멈출 수 있음
Dependency Relations

구성소가 아니라 단어들의 관계찾기. 그중에서 의존관계 찾기
문장에서 단어들이 어떻게 서로 의미적으로 연결되는지를 나타내는 방법
문장을 구성하는 단어들은 단순히 나열된 것이 아니라
의존 관계(dependency relation)로 연결되어 있음
- 하나의 head 단어가 중심이 되고
- 나머지 단어들은 그에 의존(dependent)함
- 각 관계는 특정 역할을 가짐 (예: 주어, 목적어 등)
head와 dependent를 알아내는게 목적
dependent의 type에 따라서 어떤 의존관계인지..
Subject, Direct object, Indirect object인지 같은 문법적 특성에 따라서 dependency를 찾는다..
head를 기준으로 dependent를 찾기 -> 헤드가 subject 라면 -> 주어를 dependent가 서술해주는구나...
대표적인 Relation Types
- nsubj (nominal subject): 주어
- obj (object): 목적어
- iobj (indirect object): 간접 목적어
- amod: 형용사 수식
- advmod: 부사 수식
- det: 관사
- root: 문장의 중심 동사
"어떤 단어가 어떤 단어를 설명하는지"를 명확히 연결
구성 요소

근데 이 3개말고 더 많음
-> dependency treebank (미리 정의해놓은 tagset) -> stanford,, ... ,, Universal dependencies.
universal dependencies 를 제일 많이 씀
Universal Dependencies

구체적인 의존관계 candidate set을 사람들이 많이 쓴다.
큰 카테고리 2개로 나눌 수 있음
Clausal Relations (절 관계)
문장에서 주어(subject)에 대해 설명하는 부분, 즉 **술어(predicate)**와 관련된 관계들을 말함
이건 문장의 핵심 구성요소들 사이의 관계임
문장의 중심 동사와 연결되는 중요한 부분들임(형용사, 부사, 전치사 등)
Modifier Relations (수식 관계)
단어가 다른 단어를 꾸며줄 때 사용하는 관계들
문장의 부가적인 정보를 주는 역할을 함
이런 것들은 필수 요소는 아니지만, 문장을 풍부하게 만드는 보조 정보들
- 문장의 핵심 구조 (누가 무엇을 하는가?)와
- 부가적 수식 정보 (언제, 어떻게, 어디서?)를 명확히 구분해서 처리할 수 있음
이렇게 하면 머신러닝 모델이 문장을 이해하거나 생성할 때
→ 중요한 정보와 옵션 정보를 구별해서 더 똑똑하게 작동 가능함
Clausal Relations
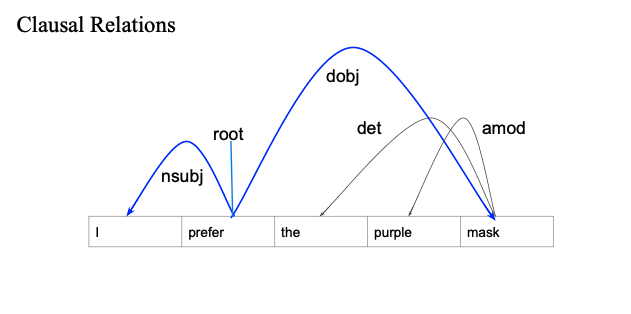
내가 마스크를 선호했다..
- 주어찾기
- prefer 는 I 에 의존
- prefer 는 mask에 의존
Modifier Relations
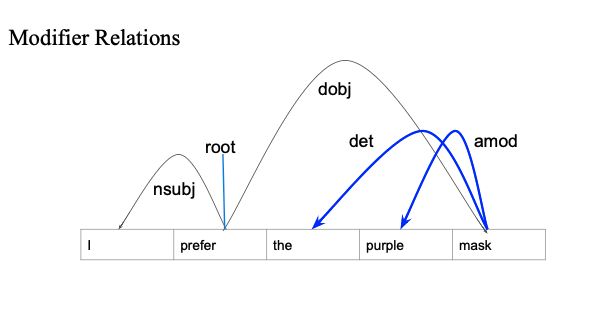
- mask는 purple에 의존
- mask는 the에 의존
Universal Dependencies
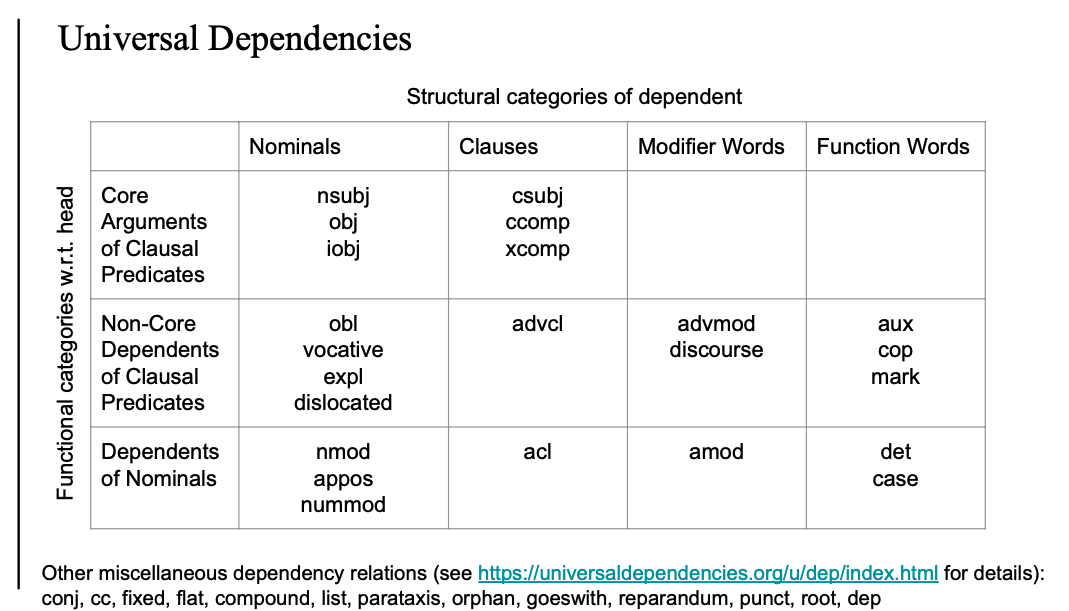
-
Core Arguments of Clausal Predicates
- argument 는 빠지면 안 됨(없으면 의미가 달라짐)
- head와 dependent의 관계가 필수적
- 서술어 찾고 -> 해당하는 주어 찾기 (nsubj)
- Seoyeon wrote a dissertation. nsubj(wrote, Seoyeon)
- 서술어 찾고 -> 목적어가 필요하다? -> (직접)목적어 -> obj
- Seoyeon wrote a dissertation. obj(wrote, dissertation)
- Seoyeon wrote him a dissertation. iobj(wrote, him)
- 서술어를 찾고 -> 절이다? -> 해당 절의 서술어를 가져옴
-
Non-Core Dependents of Clausal Predicates
- 서술어(predicates) 를 찾고 서술어가 의존하는 것들에 대해서 찾기
- 그것에 대해서 labeling해주는 과정..
- non-core: 생략이 되어도 의미에 크게 .. 영향을 안 줌
...
core만 잘 찾기..
| 기능적 범주 (Head 기준) | 명사 관련 요소 (Nominals) | 절 관련 요소 (Clauses) | 수식어 관련 요소 (Modifier Words) | 기능어 (Function Words) |
|---|---|---|---|---|
| 절의 핵심 성분 (Core Arguments of Clausal Predicates) | nsubj (명사 주어)obj (목적어)iobj (간접 목적어) | csubj (절 주어)ccomp (절 목적어)xcomp (보어절) | ||
| 절의 비핵심 성분 (Non-Core Dependents of Clausal Predicates) | obl (부사어/전치사구)vocative (호격)expl (형식 주어)dislocated (이탈어순) | advcl (부사절) | advmod (부사 수식)discourse (담화 요소) | aux (조동사)cop (연결동사)mark (접속사) |
| 명사의 수식 요소 (Dependents of Nominals) | nmod (전치사구 수식)appos (동격)nummod (수사 수식) | acl (관계절 등) | amod (형용사 수식) | det (한정사)case (전치사 등) |
Transition-Based Dependency Parsing

- 의존 구문 분석을 하는 전통적인 방식 중 하나임
- 문장을 왼쪽에서 오른쪽으로 보면서 어떤 의존 관계를 만들지 점진적으로 결정해나감
- 일종의 단계별 트리 구축 과정이라 보면 됨
shift reduce parsing -> stack 을 이용
stack을 이용해서 dependency parsing 하는 과정을 아는 것이 중요
shift reduce parsing
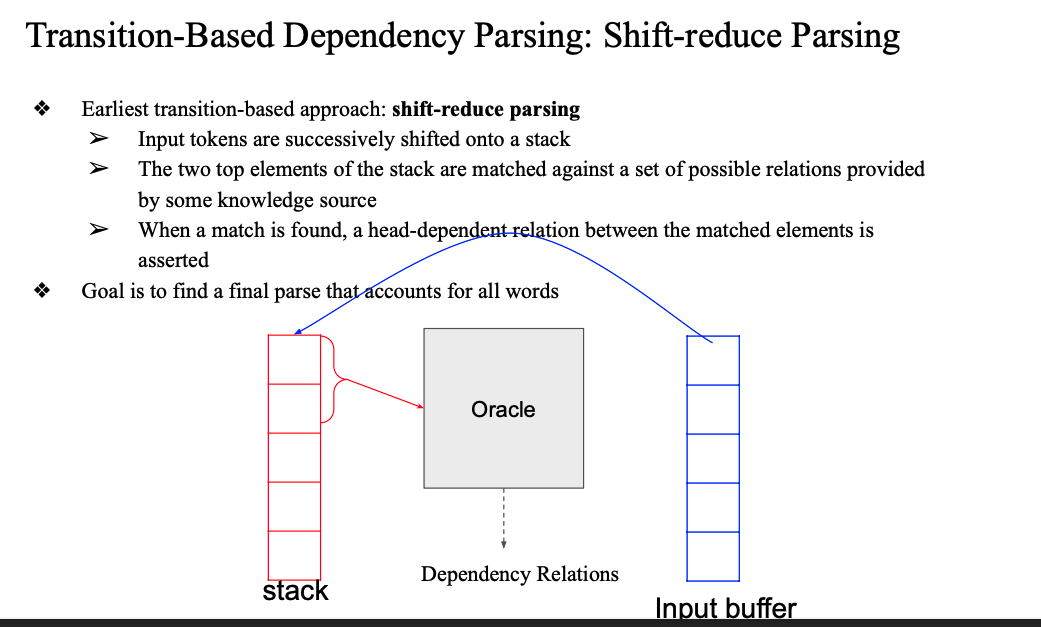
- input buffer(python list)는 input sentence 쭉 단어로 나열한 것
- input buffer에서 단어를 하나씩 스택에 넣기
- 스택 맨 위에 있는 두개의 word를 가지고
- 어떤 dependency relation 가 있는지 확인
- 이 과정에서 하는 연산이 shift or reduce임
- transition이 전체 시스템의 싱태를 어떠한 transition operator 로 정의하는 것
- 어떤 dependency relation 가 있는지 확인
oracle

- 오라클은 그냥 전지전능하게 어떤 Operation 을 해야하는 지 알고 있다고 보면 됨..
- 우리가 예시에서는 아마 임의로 선택하지만 (물론 규칙은 지켜서)
- 실제로는 머신이 이를 하거나,, 뭘 해야 좋은지 아는 오라클이...

결국 transition operator 를 각 단계별로 골라서 shift or reduce 를 하고 그 word간 관계에 따라서 Dependency Relation 을 정의해주는 것..
operator

- Assign current word as head of previous word
- 현재 단어가 이전 단어의
head가 된다 → Right-Arc
- 현재 단어가 이전 단어의
- Assign previous word as head of current word
- 이전 단어가 현재 단어의
head가 된다 → Left-Arc
- 이전 단어가 현재 단어의
- Do nothing yet
- 당장 연결 안 하고 다음 단어로 넘어감 → Shift
- buffer → stack

- left arc
- 조건: stack 두 번째(top-1)에 있는 것이 ROOT가 아니어야 함
- 결과: top 단어 → top-1 단어를 head로 하는 dependency 생성 (즉, top-1이 dependent가 되고 제거됨)
- right arc
- 조건: stack에 최소 두 단어
- 결과: top-1 단어 → top 단어를 head로 하는 dependency 생성(즉, top이 dependent가 되고 제거됨)
configuration

- 초기 설정
- stack 에는 Root 노드만 있음
- 그러면 처음에는 shift 해줘야겠지?
- shift 는 버퍼에 (word list)에 단어가 남아있을 때 가능
- reduce operation 불가능
- 그러면 처음에는 shift 해줘야겠지?
- 그러면 스택에는 방금 shift 한 word, root 가 존재하게됨
- 이때는 left arc 못함
- 스택에서 두번째 있는 게 Root 노드면 left arc 못함..
- 이때는 left arc 못함
- 이런식으로 각 단계별로 어떤 operation 쓸지..? 정해가면서 dependency 를 찾아가는 것.
- stack 에는 Root 노드만 있음
- 최종 단계
- 스택은 비어있어야 함 (root 도 나가야함)
- 버퍼(word list) 도 비어야함
- Dependency Tree: 모든 단어에 대해 head가 하나씩 설정되어 있어야 함
Example

- 초기상태임
- 버퍼에 워드리스트
- 스택에 Root 만
일단그러면 shift 먼저.
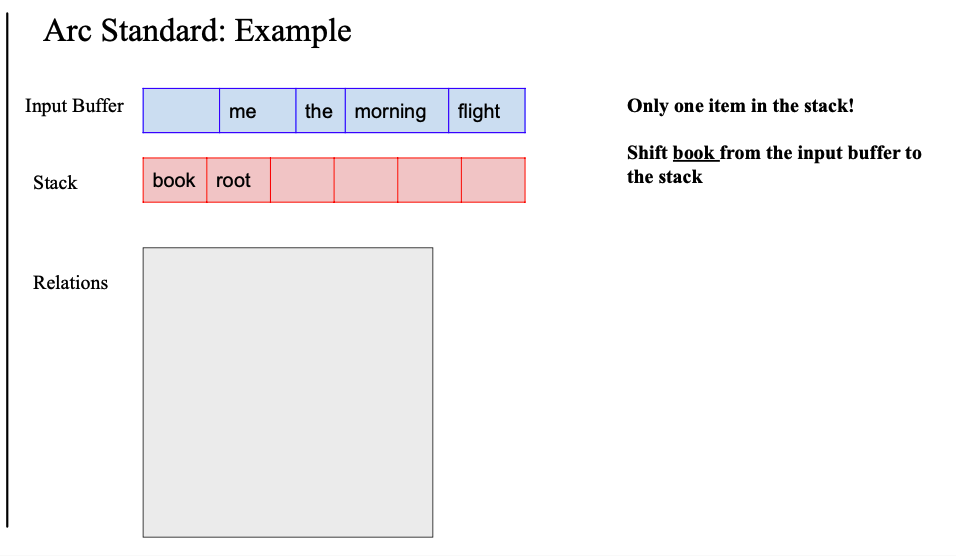
- 그러면 스택에 book 이 들어감
- 이제 여기서 Operation 해야하는데
- 스택 두번째가 root -> left arc 불가능
- 그래서 right arc or shift 인데 여기서 오라클은 shift 함
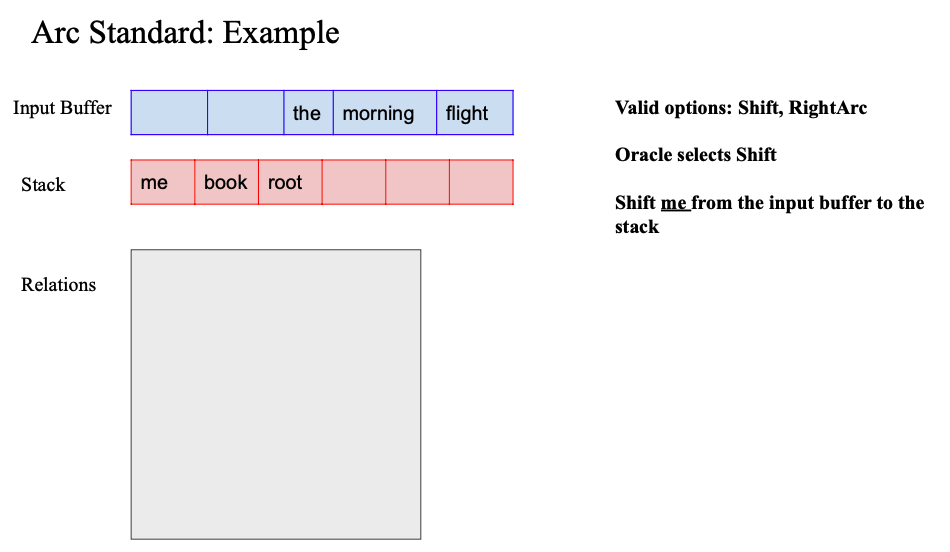
그러고 나면 세가지 opertaion 다 가능
- 오라클이 RightArc 함
- me 는 스택에서 나가고
- (book -> me) relation 추가해주기
- book 이 head
- me 가 dependent
- book이 me를 지배

이후에 shift 수행 -> the 스택에 추가
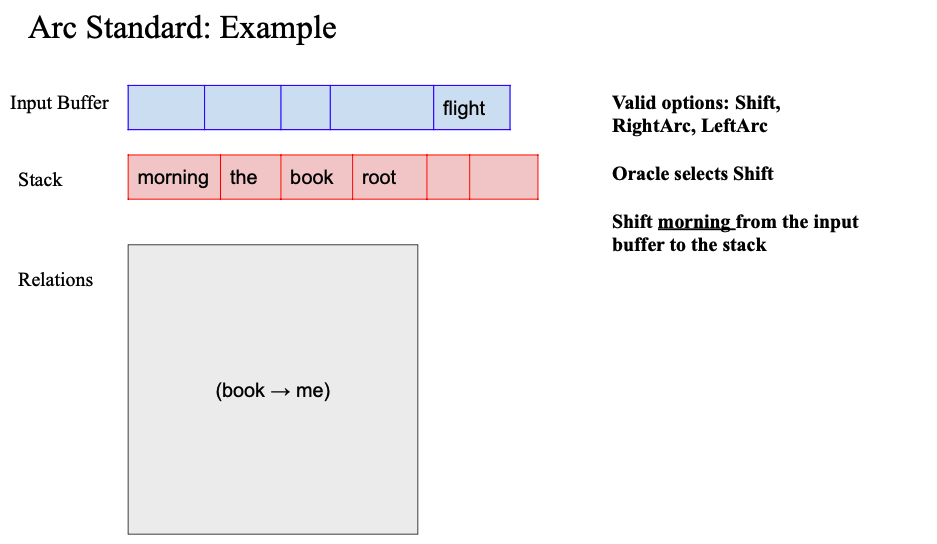
또 shift
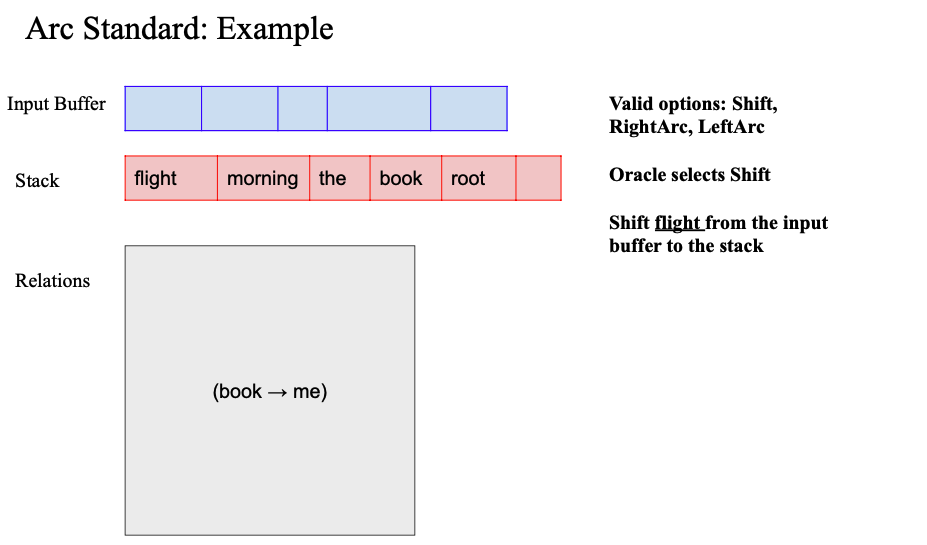
마지막 shift 해주면 버퍼가 비었음
이제는 shift 못함 (버퍼가 비어있어서) -> Left right arc 만 가능
- left arc 해줌
- (flight -> morning) relation 추가
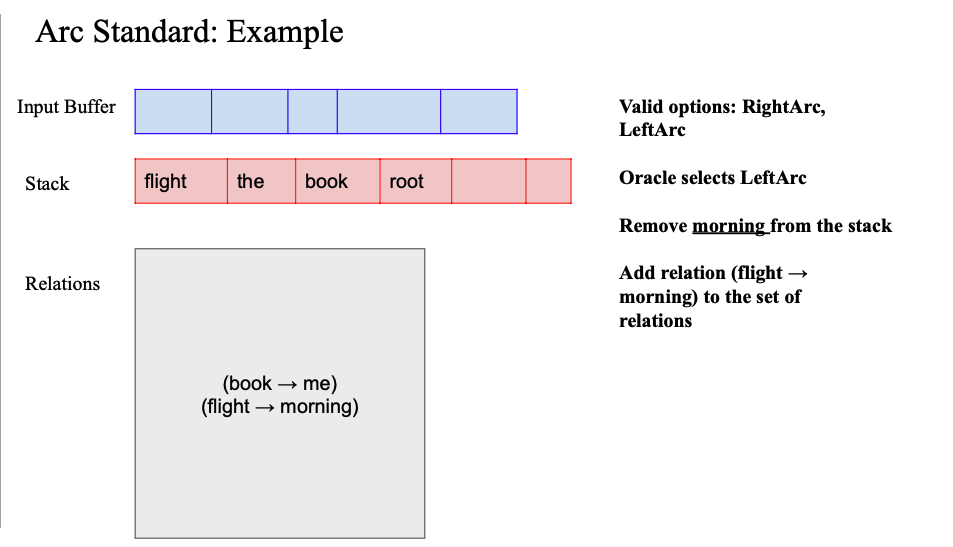
- 마찬가지로 shift 불가능
- left arc 수행
- (flight -> the) relation 추가
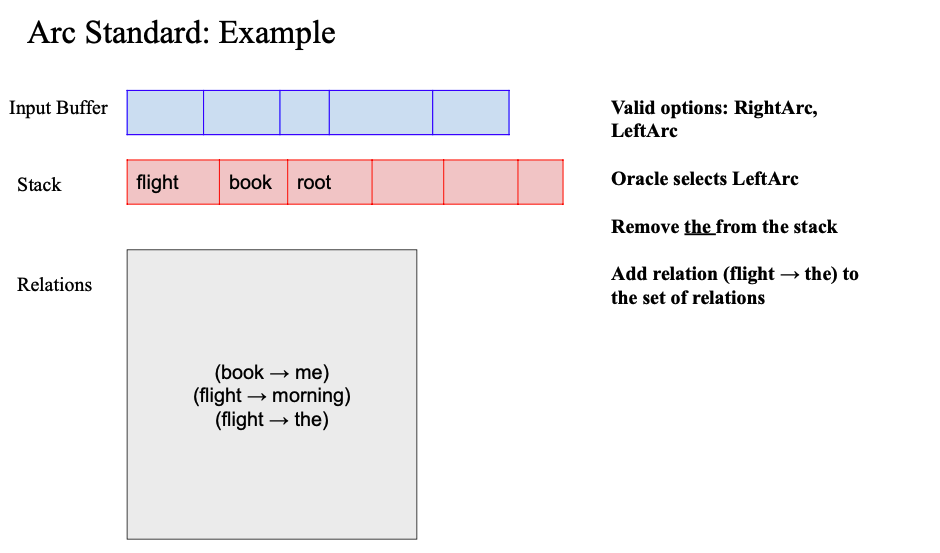
- right arc 수행
- (book -> flight) relation 추가
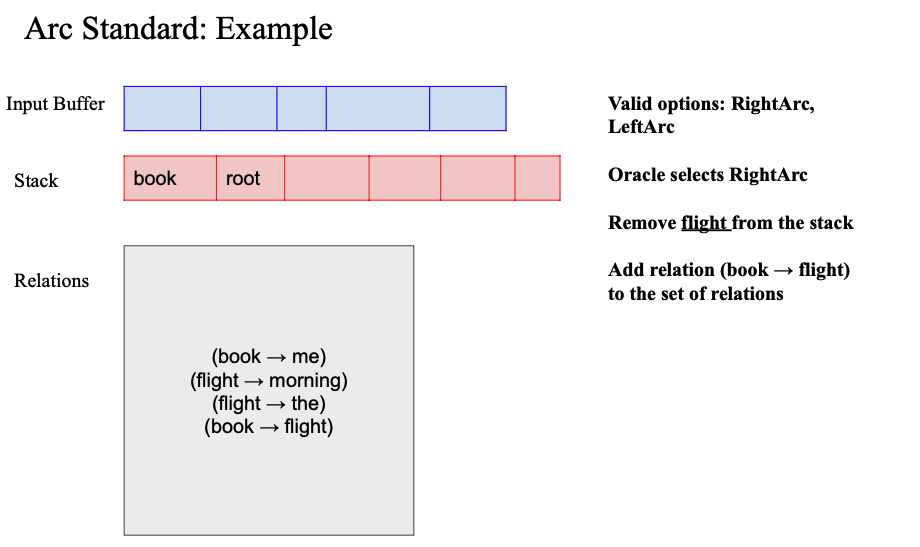
- 마지막 shift 불가능, left arc 불가능 (두번째가 Root)
- right arc 수행
- (root -> book) Relation 추가
- book 제거
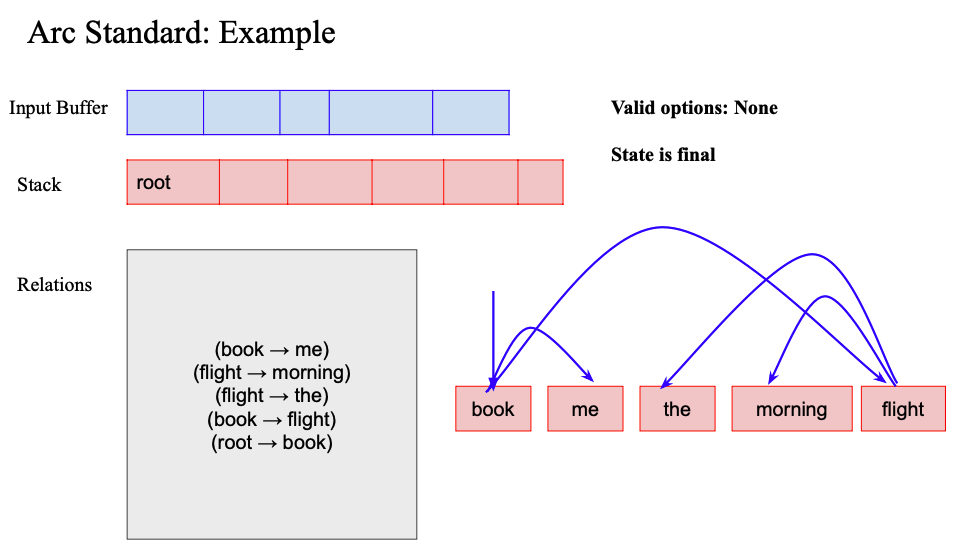
그럼 최종적으로 stack 에는 Root 만남음
final state
그러면 releation 기반으로 화살표 그려줄 수 있음
root -> book -> me, book
book -> flight -> morning, the

이 결과에다가 dependency labeling 까지하면 더 ... 정확한 의미 해석이 가능한 구조..
