
ch11. Transformers (+ Mixture of Expert)
background

apple 의 word2vec 결과가 문맥상관없이 같았음.. (먹는 사과, 회사 apple)
- attention 이 등장
- transformer 등장
- contextual word embedding
Transformer
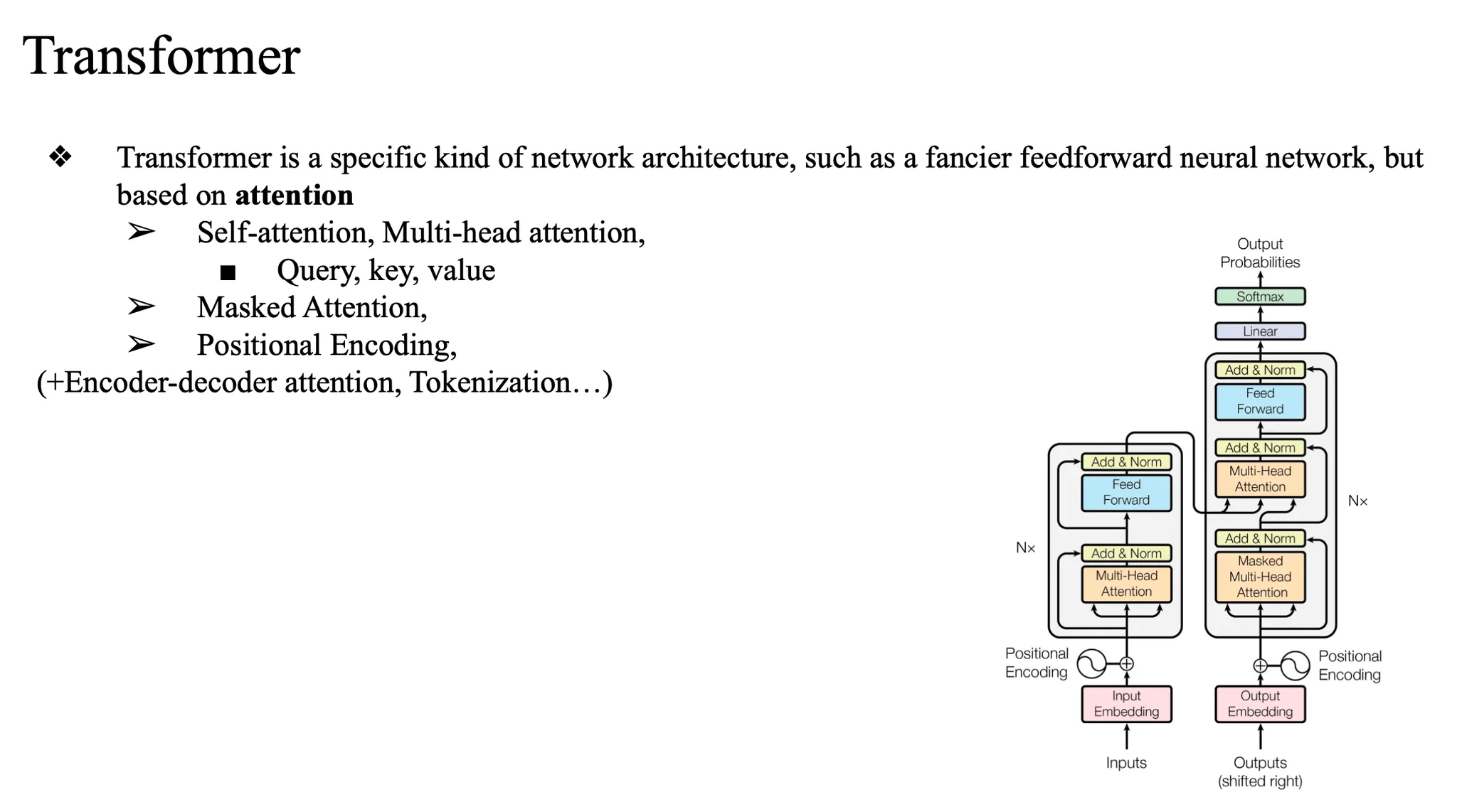
인코더 + 디코더의 구조로 구성되어있음
초기에는 seq2seq 태스크들을 잘 풀어내기 위해 구현된 아키텍처
seq2seq task 특징
- input 과 output 이 명확히 구별되어있고
- input 에 대해서 output을 명확하게 얻고 싶은 것
Transformer 동작 흐름
- Input 시퀀스를 Encoder에 입력
- 입력 토큰들을 임베딩 → 포지셔널 인코딩 추가
- Multi-head attention, feedforward 등 encoder 컴포넌트 통과
- 최종 출력: encoder representation (입력 문장의 압축 정보)
- Decoder에 Target 시퀀스 입력
- 정답 문장의 이전 단어들을 디코더에 넣음 (teacher forcing 시)
- 동시에 Encoder에서 나온 encoder representation도 함께 참조함 (cross-attention)
- Decoder 출력
- 이전 단어들과 encoder representation을 기반으로 다음 단어 예측
- 반복적으로 다음 토큰을 생성하며 전체 출력 시퀀스를 만들어냄
Decoder-only Transformer
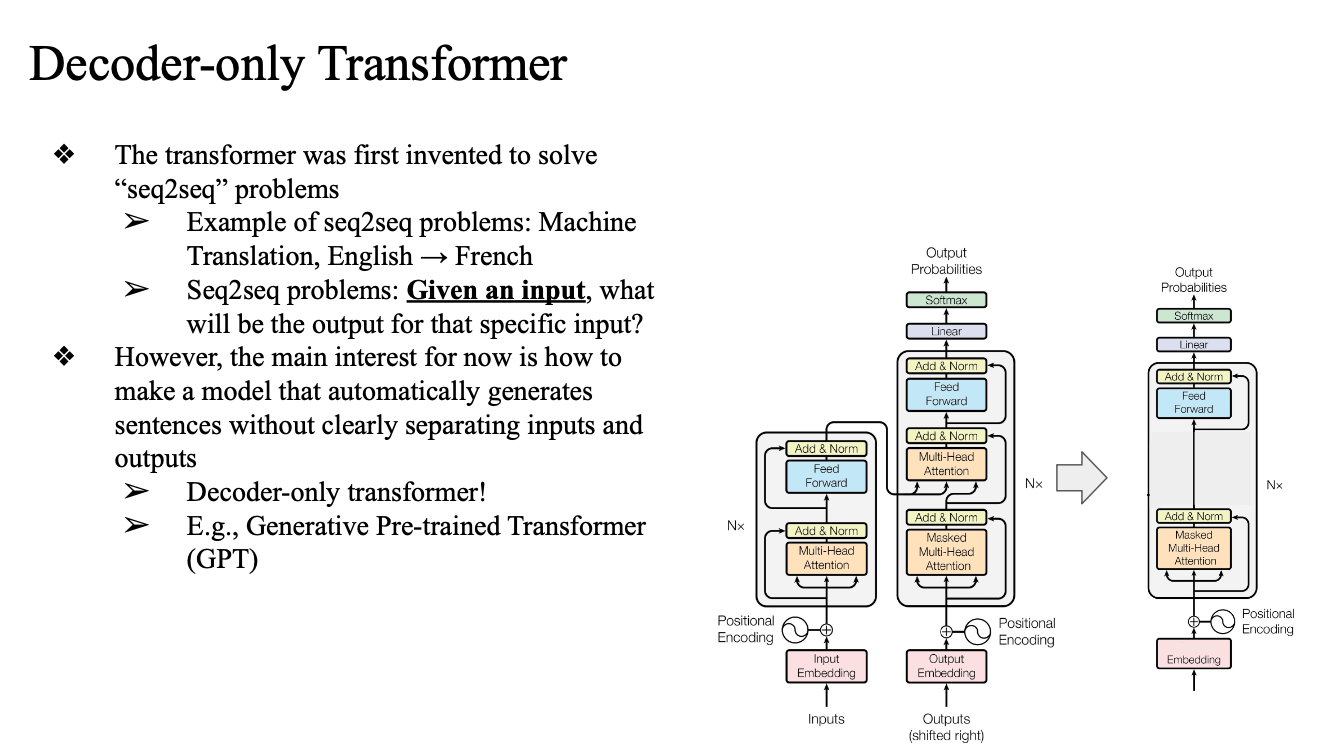
- 머신 translation이 가장 대표적인 seq2seq 예제
- 명확한 input 존재 -> 그에대한 output(번역)
- 디코더만 여러겹 쌓아서 트레이닝 → LLM (GPT)
- 더 나아가서 mixture of expert
- deepseek
Mixture of Experts (MoE)
- GPT 같은 모델을 확장하는 구조 중 하나
- 전체 모델이 아닌, 일부 모듈(feed forward ...)만 선택적으로 활성화
- 예: 100개 중 2~4개의 전문가 네트워크만 사용
- 장점: 계산량 줄이면서도 성능 유지 or 향상
- weight 가 늘어남 -> 선택적으로 고르자 (단순히 디코더 자체의 개수를 늘리는 게 아니라 특정 모듈만 늘리자.)
problem with static embedding (word2vec)

두 문장에서 시작
사람은 이 it 이 치킨인지 road 인지 알 수 있는데
word2vec 이나 glove (static word embedding)에서는 구별할수없음
- 그래서 도입한 게 Attention 매커니즘
- 'it'을 표현할 때, 주변 단어들을 고려해서 표현하자..
Attention

주변 단어의 벡터를 weighted sum 계산
→ it을 표현
- 이때 the, chicken, road, ... 등등의 각각의 weighted sum 을 가져온다는것
- 이 의미가 주변 단어를 고려했다..

주변 단어와의 내적으로 score 구함
- 각 워드마다 score assign
- 그 set을 softmax() 취해줌 (다 더해서 1이 되게끔)
- 각각의 word vector에 곱해서 weighted sum 해줌
- it의 값을 구함
contextual embedding 을 만드는 과정이다..
"Self-Attention은 각 단어가 문장 내 다른 단어들과의 관계를 고려해 문맥 정보가 반영된 표현(contextual embedding)을 만드는 과정이다."

- 단어의 의미는 주변 단어(문맥)에 따라 달라짐 → 그러니까 각 단어가 다른 단어들을 얼마나 “중요하게” 여길지(weight)를 고려해야 함
- 이걸 자동으로 학습하게 하려고 나온 게 바로 Self-Attention이고,
- 이 Self-Attention을 바탕으로 설계된 구조가 Transformer
Language Model

문장의 확률을 최대화하는 파라미터를 학습하는 것 ...
next-word prediction... masked word prediction...
GPT는 이런 언어 모델을 Transformer Decoder 구조로 구현한 것...
Self-Attention in Transformer
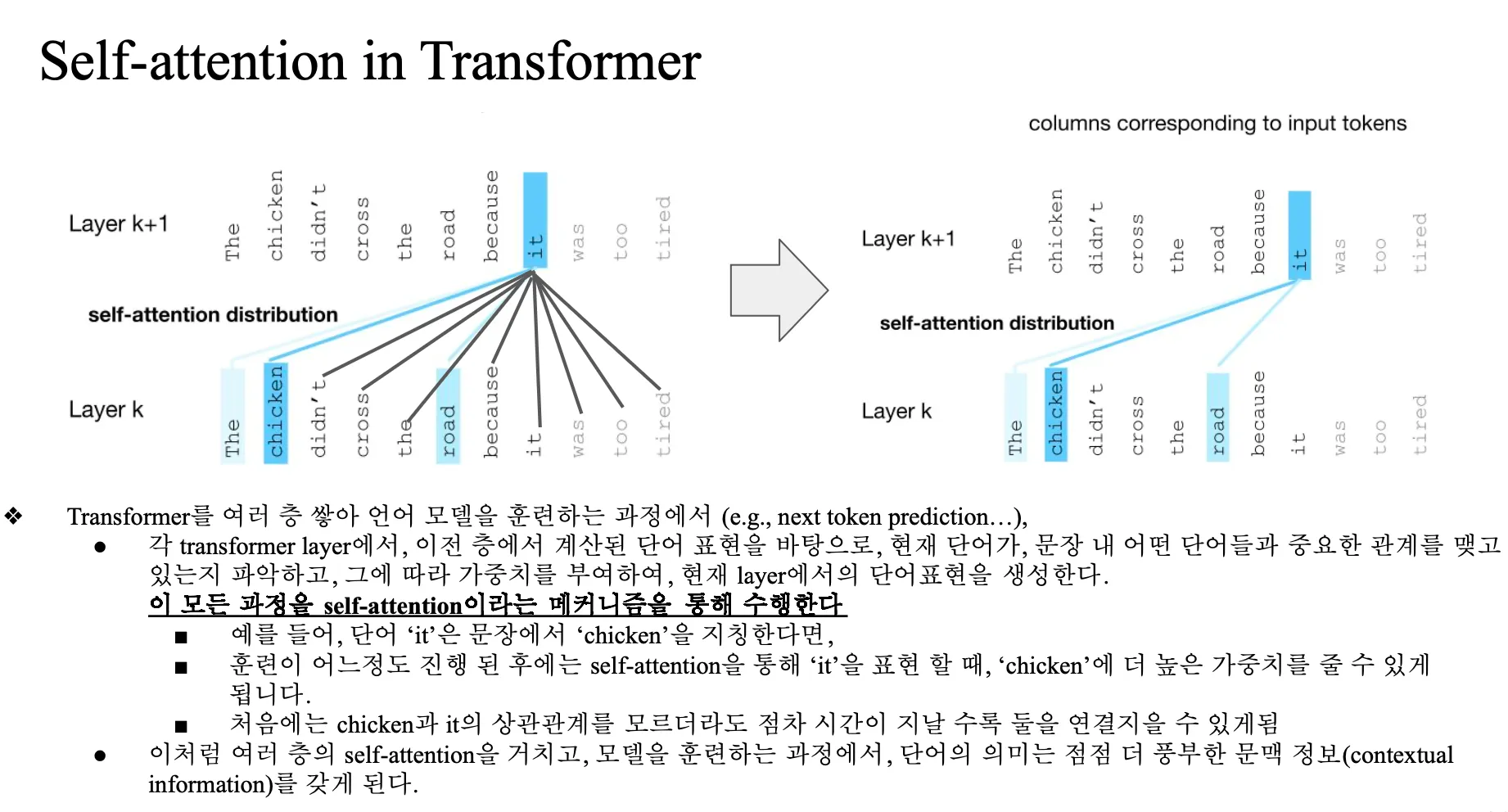
layer k 에서 나온 output 값이 next layer 의 input 으로 쓰인다.. -> 여러 층
맨 마지막 word vector 는 contextual embedding 이다..
Self-Attention module

- 세 가지 구성요소 기반
- Query
- Key
- Value
- Query는 내가 지금 주목하고 있는 단어, 질문
→ 예: "It"이 다른 단어들을 바라보며 얼마나 중요한지 판단- Key는 다른 단어들이 가진 정체성 (주변 word)
→ "나는 이런 정보를 가지고 있어요"- Value는 실제로 그 단어가 가지고 있는 정보 내용
→ attention score가 곱해져서 최종 출력값을 만들기 위한 대상
Self-Attention (Vaswani et al., 2017 from Google)
https://jalammar.github.io/illustrated-transformer/
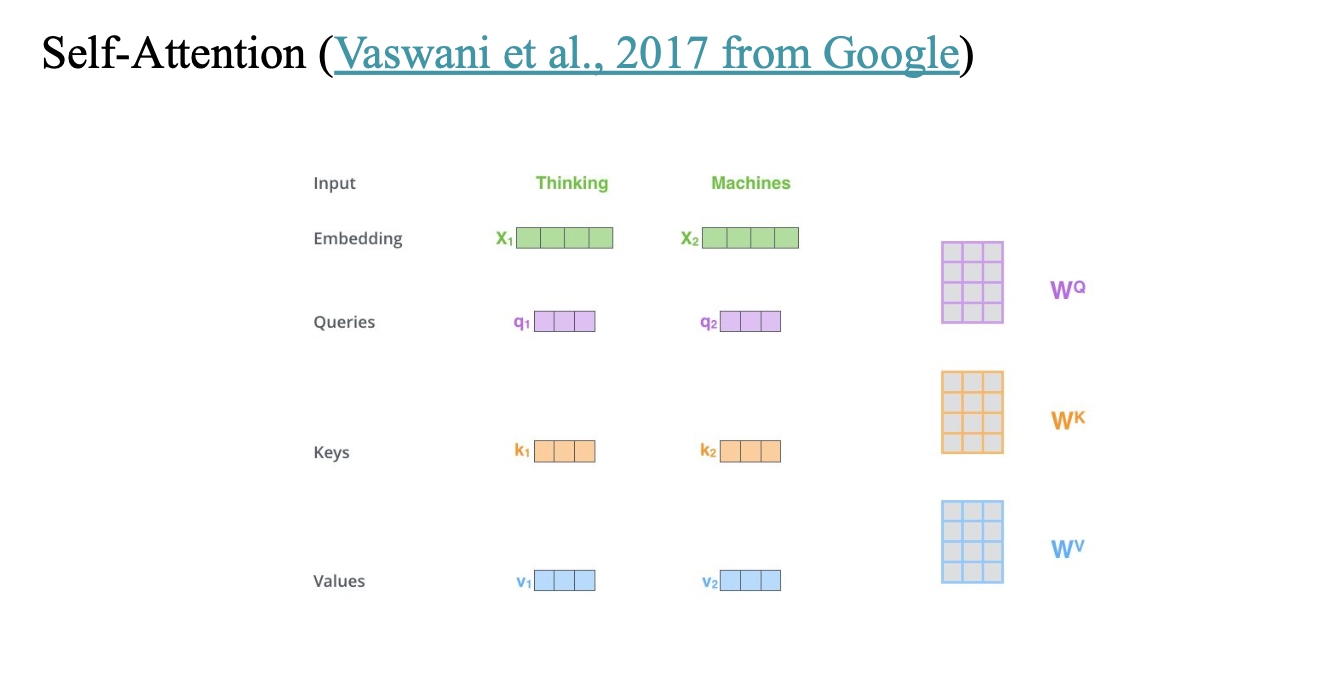
처음에 thinking 과 machine 에 대해서 qeury key value 를 모두 얻음
thinking을 기준으로
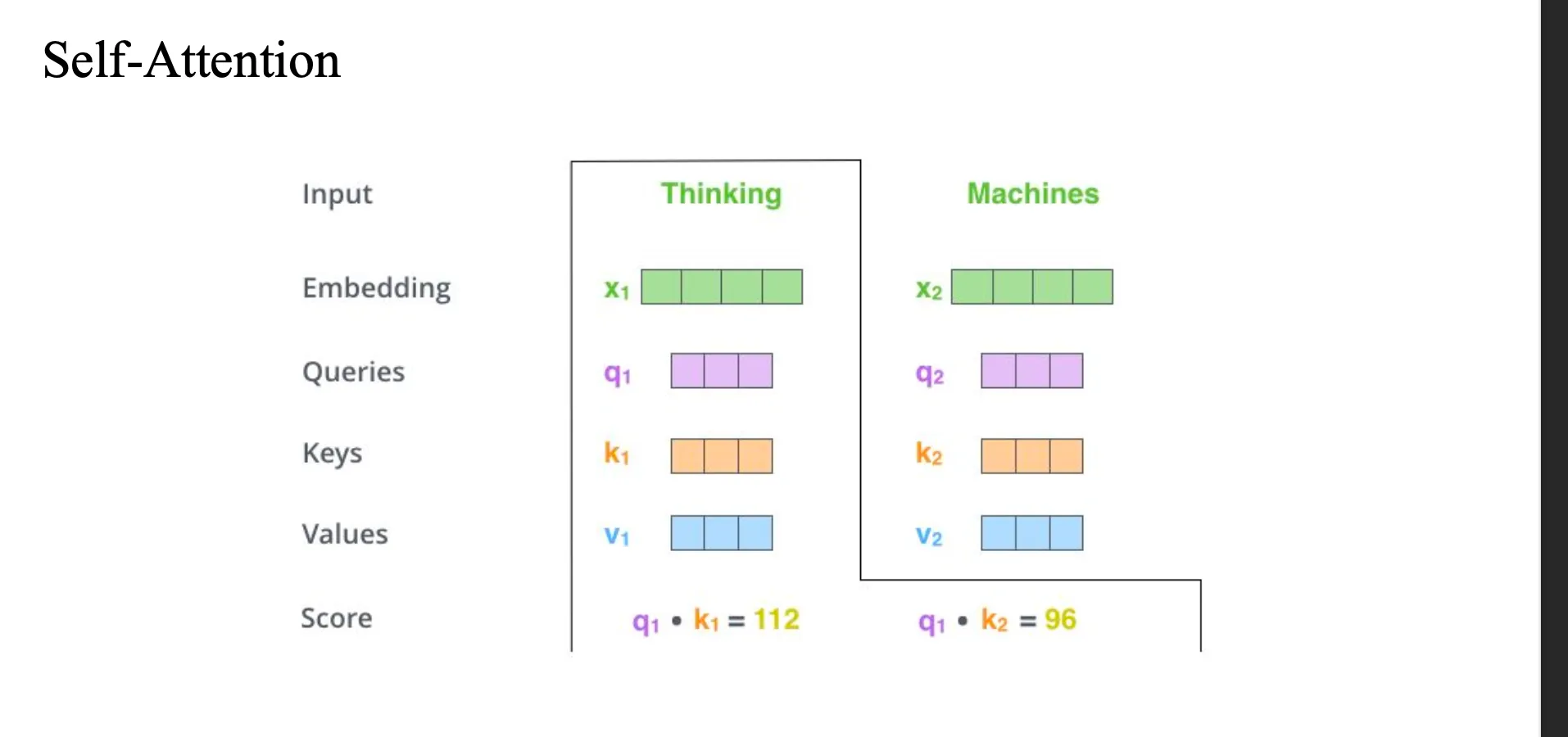
쿼리와 키를 곱해서 스코어를 구해놓음
이 스코어 -> divided by 8 (numerical stability)
-> softmax() -> 합이 1이 되도록 만듦
thinking -> thinking = 0.88
thinking -> machines = 0.12
이 score를 value에 곱해줌
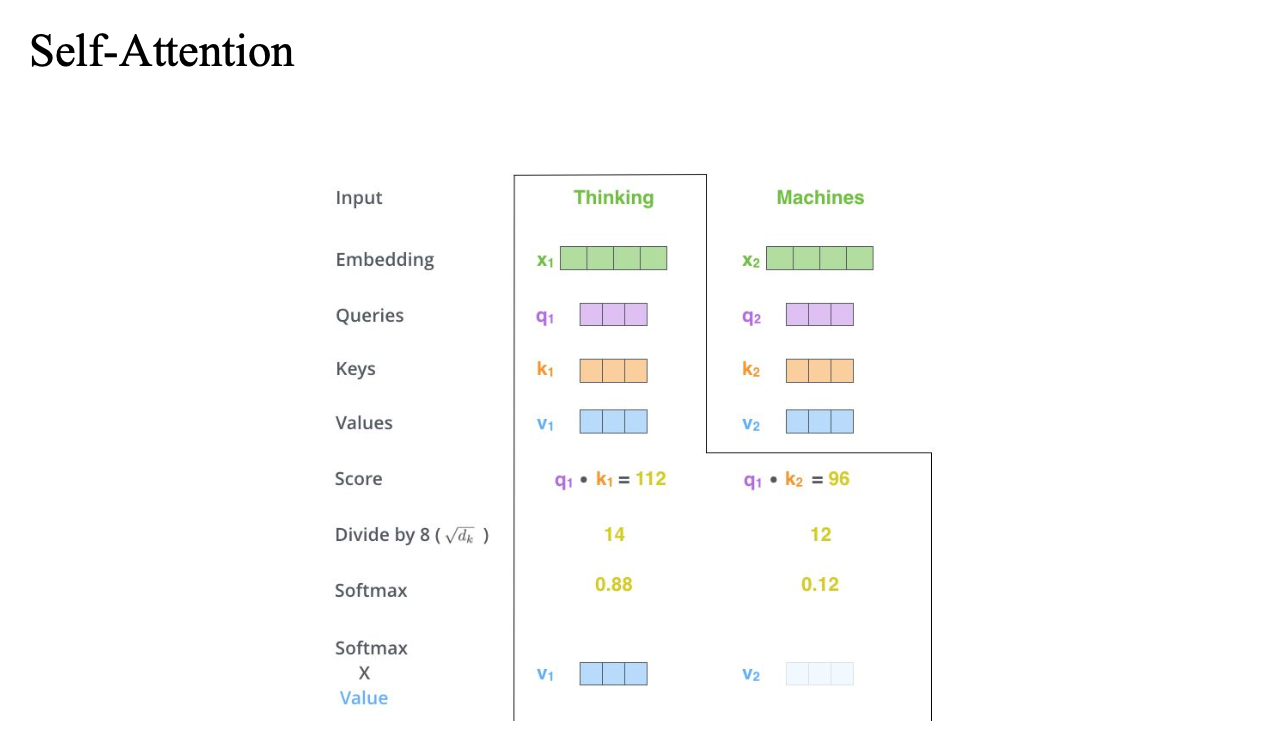
이 v1과 v2를 weighted sum해줌
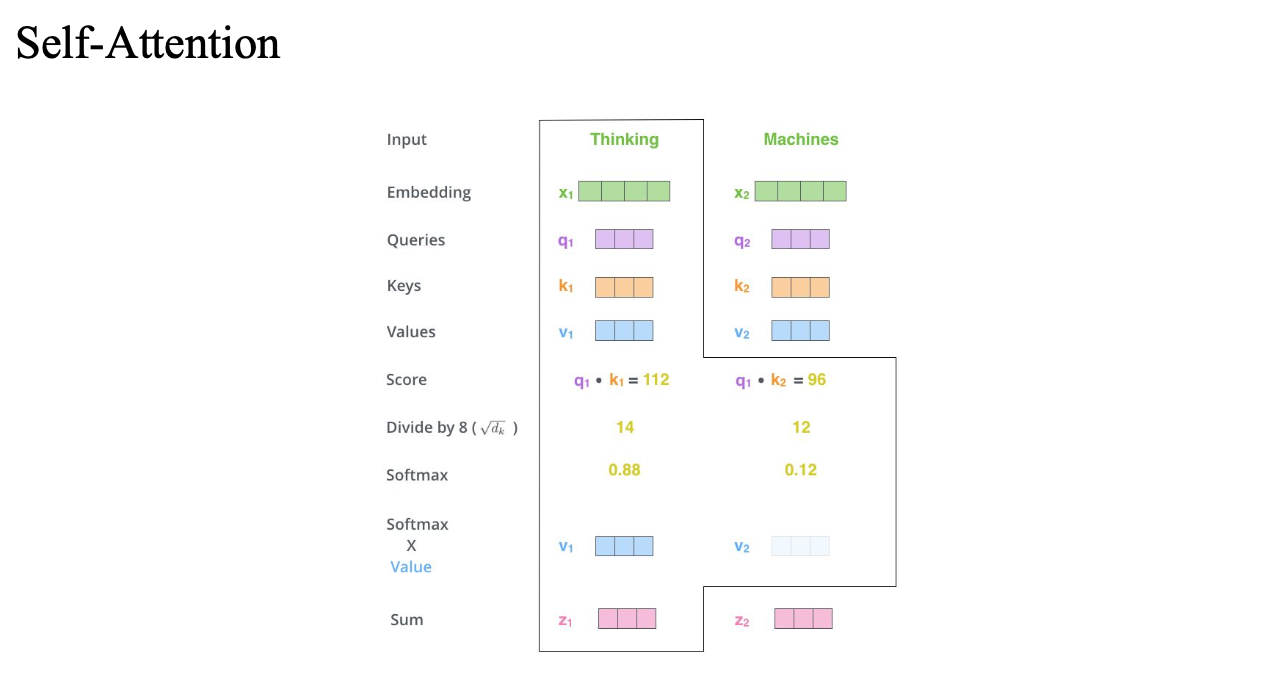
지금은 thinking 입장에서 구한 것이고,
machine 입장에서 구하는 거면 쿼리를 machine의 Queries 를 이용하면 됨..
Parallel Processing
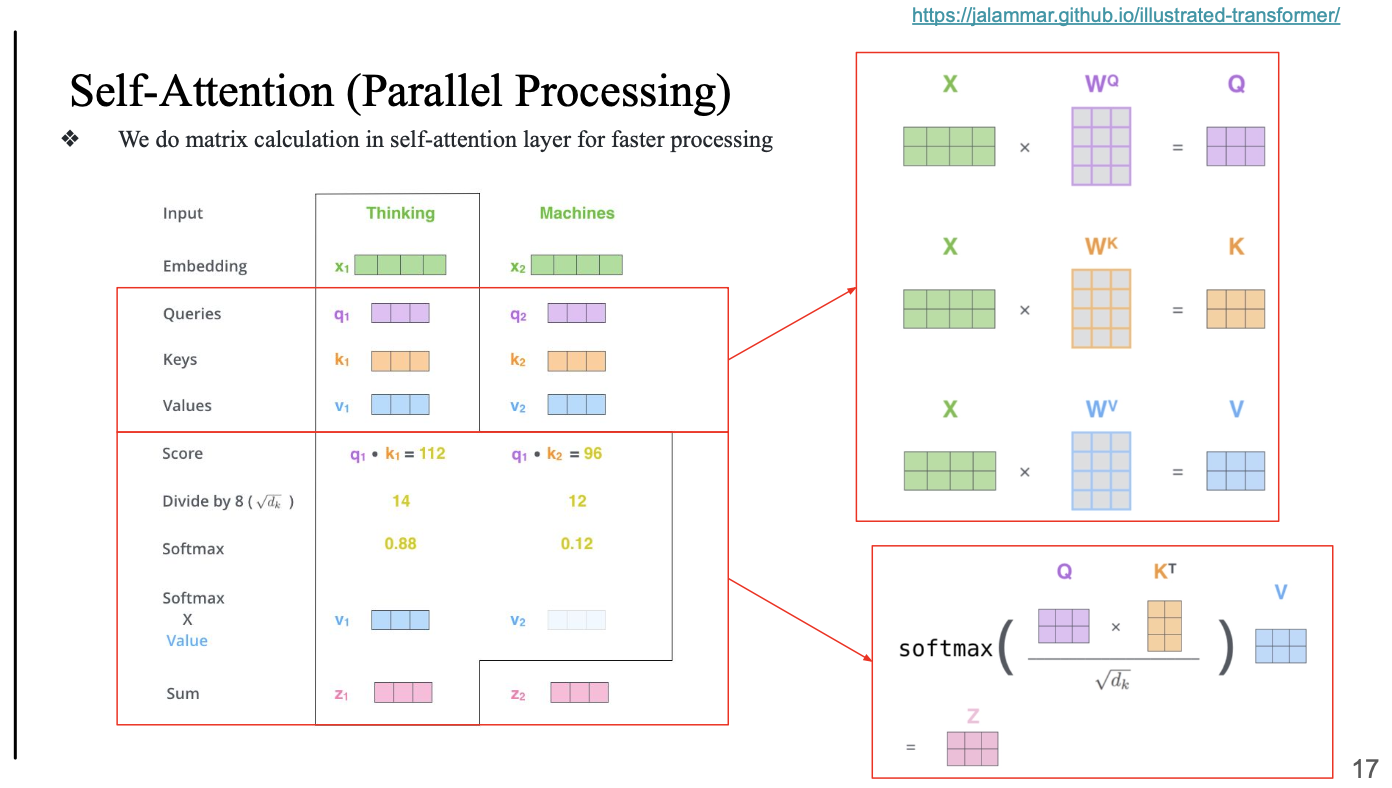
왜 이걸 사용?
이러한 트랜스포머 기반의 계산 과정이 되게 빠름
병렬처리가 가능하다..
- thinking 입장에서 계산하고 그 다음, machines 입장에서 계산... 이렇게 sequential 하게 가는게 아니라
Parallel하게 계산됨efficient...
- softmax 할때 Q * K^T 임
- Key를 transpose, shape 을 바꿔줘야 함
Multihead-attention
8개의 self-attention 모델..
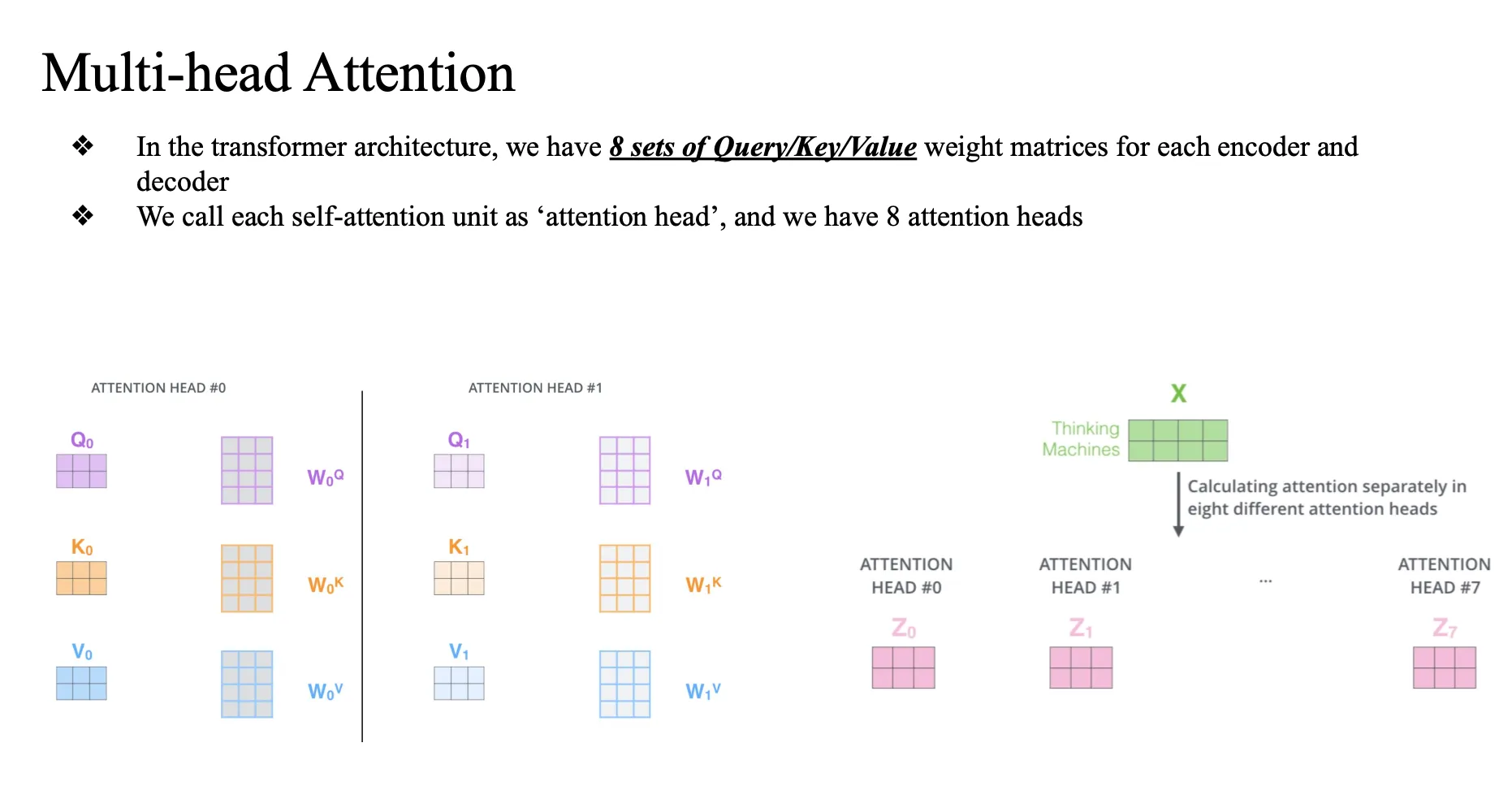
input이 주어지면 Z값이 8가지.. contextual 임베딩 전부 다 구함
Multi-head Attention and then Feed Forward Neural Network
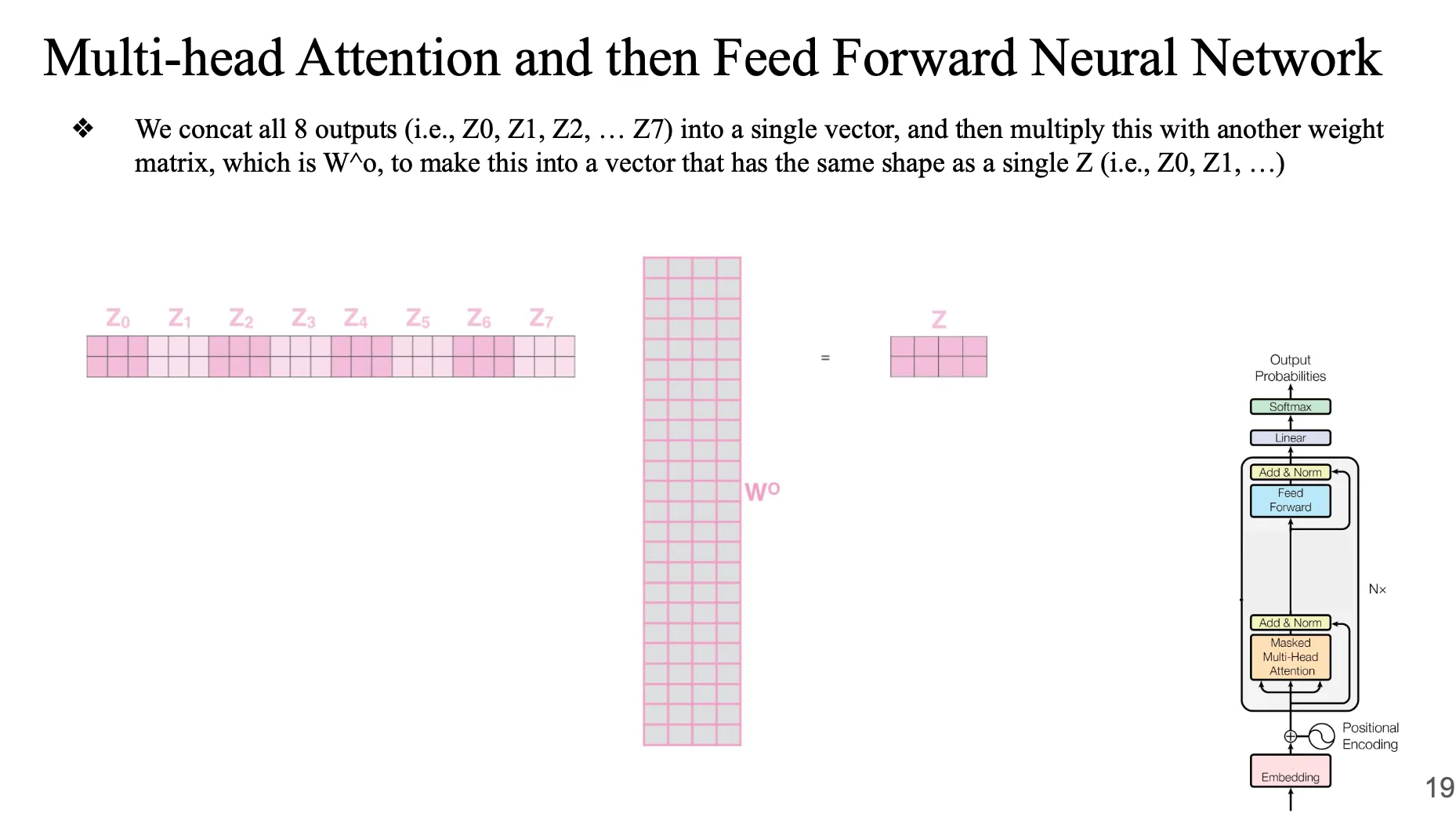
이걸 다 붙여서 feed forward layer 통과시킴
final Z … → 이게 하나의 트랜스포머 layer의 결과 (attention head에서 나온 결과를 concat) → 여러 개의 트랜스포머 통과시킴
weigh matrix 를 곱해줘서 최종 Z를 구함
Masked Self-attention
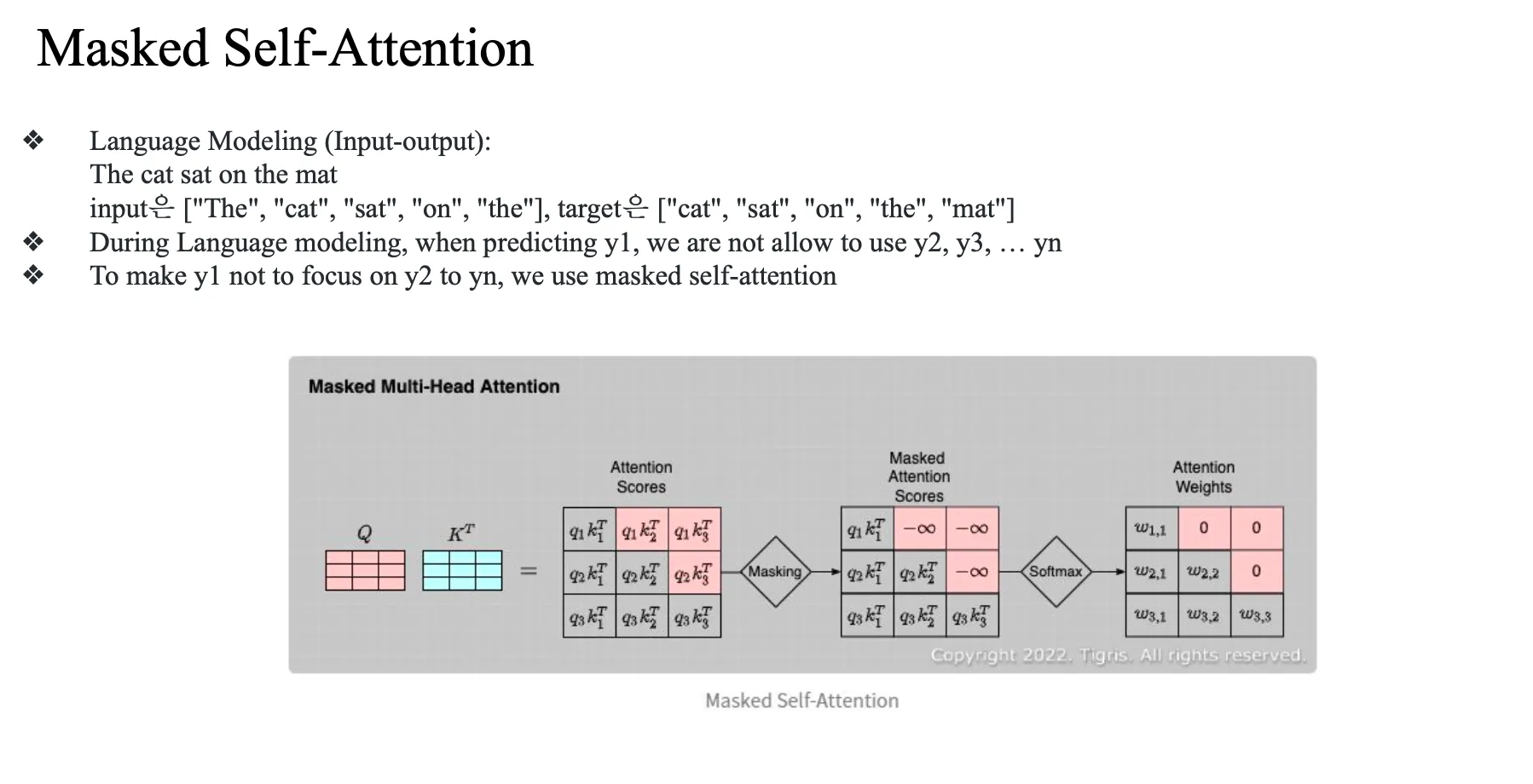
제일 중요했던게 the cat 을 주었을 때 그다음 word로 sat 을 prediction 할 수 있느냐...
근데 사실 input이 the cat sat on the mat 이므로...
뒤에를 참고하면 안됨.. 이건 cheating
그래서 masked self-attention 이 필요함
(초기에 문장이 전부 다 주어지게 되기 때문에...)
Masked Self-Attention에서는
현재 시점 이후의 단어에 attention score를 못 주게 막음
즉:
"the" → 볼 수 있는 단어: [the]
"cat" → [the, cat]
"sat" → [the, cat, sat]
...- 이런 식으로 look-ahead masking을 적용함
Future 컨텍스트를 치팅하지 말자…
뒷 부분은 마스킹을 하자..
Residual Connection
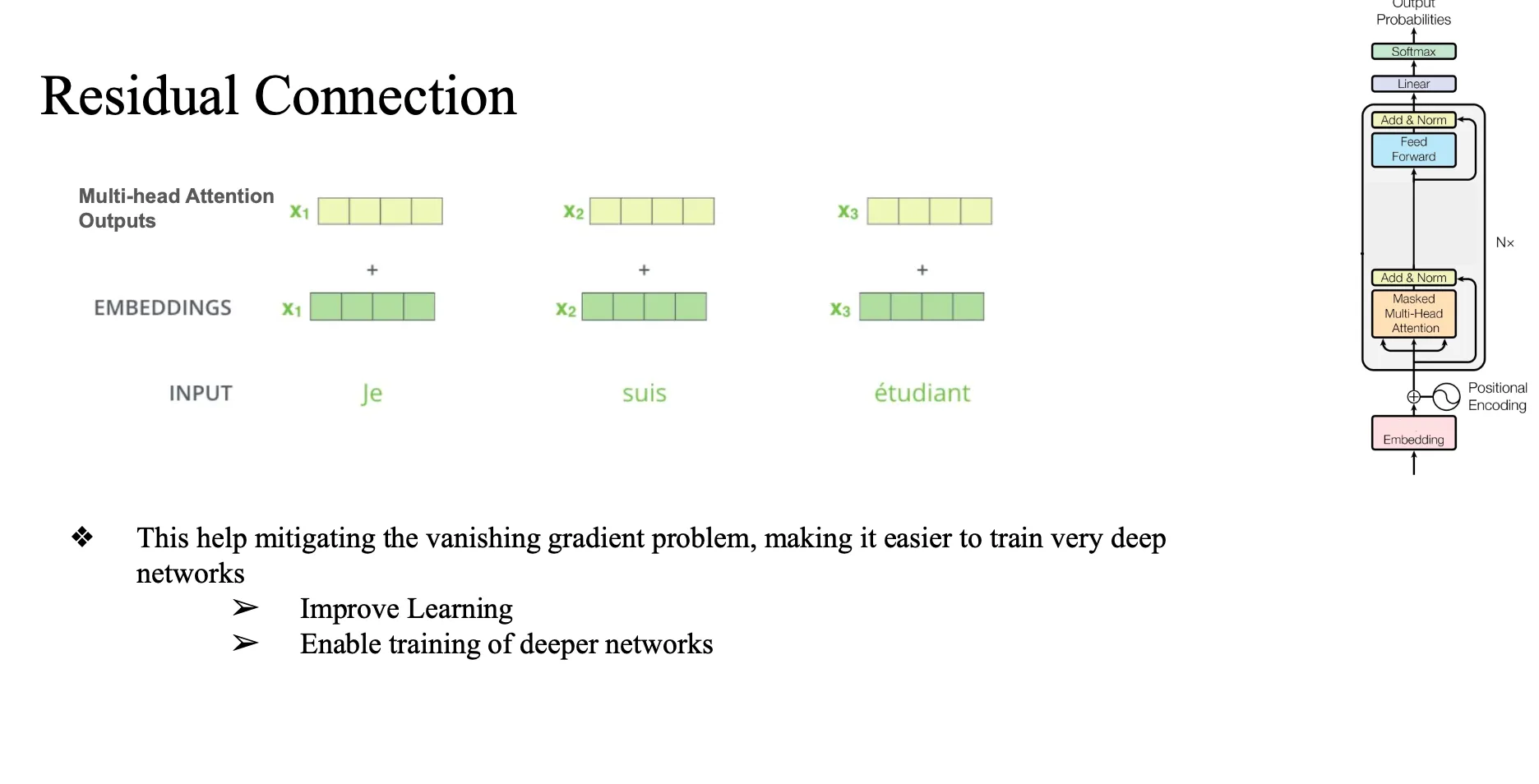
원래 값 한번 더해주자 왜? → 원래 vector format을 잊어버리는 vanishing 문제 방지, original format 유지.. … 그리고 ? 이득?
단순하게 더하기만했더니 생기는 문제?
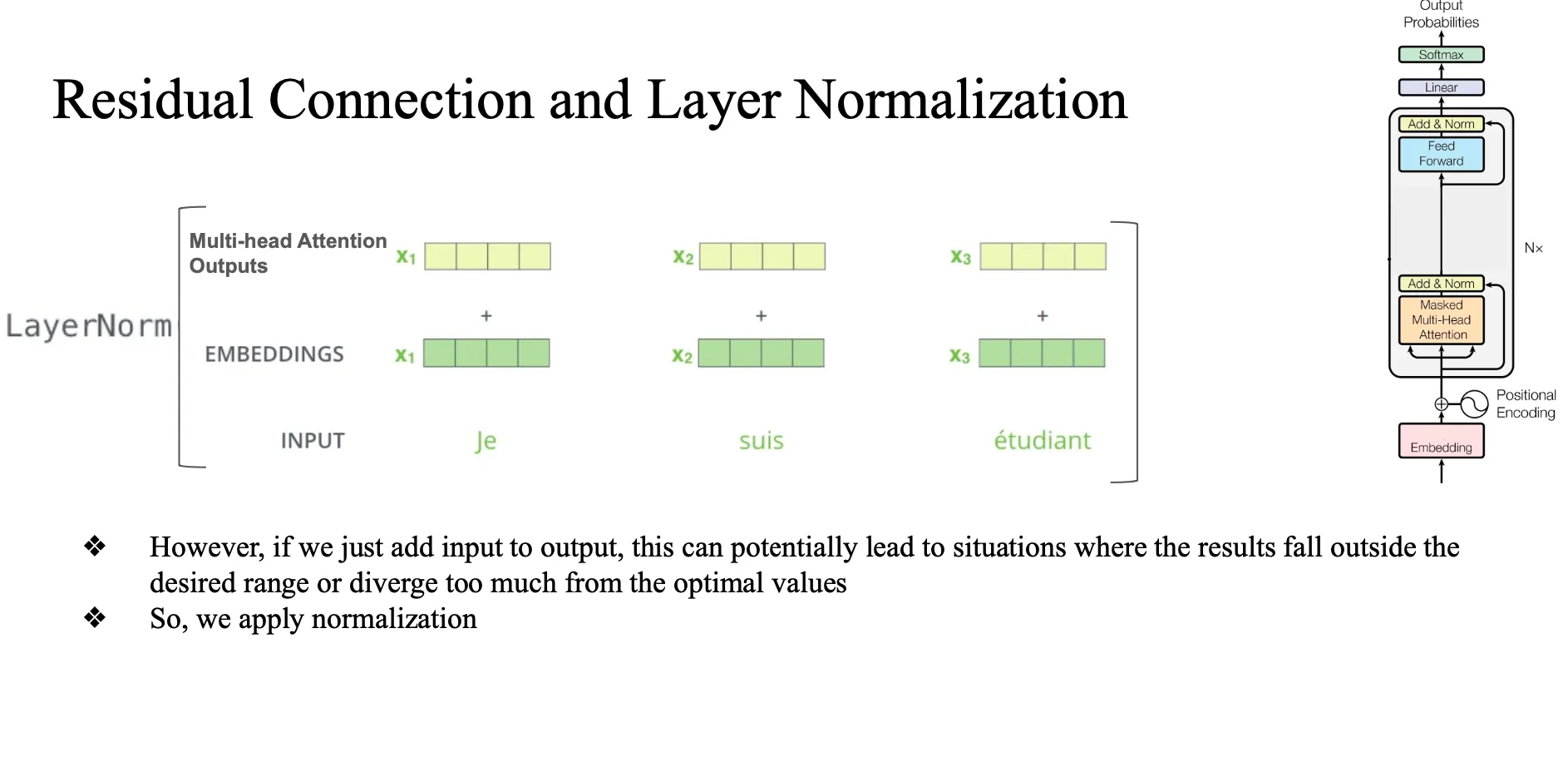
너무 영향력이 클 수도 있음...
그래서 apply normalization(정규화)
- 너무 큰 값 이 더해지는 것을 방지하자...
Positional Encoding

왜 존재?
- contextual embedding 과정은 병렬적
- 머신 입장에서 누가 먼저인지 순서를 알 수 없음
- 순서 information 을 알려주는 모듈을 만듦
- not 이 어디에 들어가는지에 따라 의미가 너무 달라짐
문장 순서를 고려해줌
- not 이 어디에 들어가냐에 따라 문장의 의미가 완전히 달라질 수 있음
- word order가 중요한 요소이다.
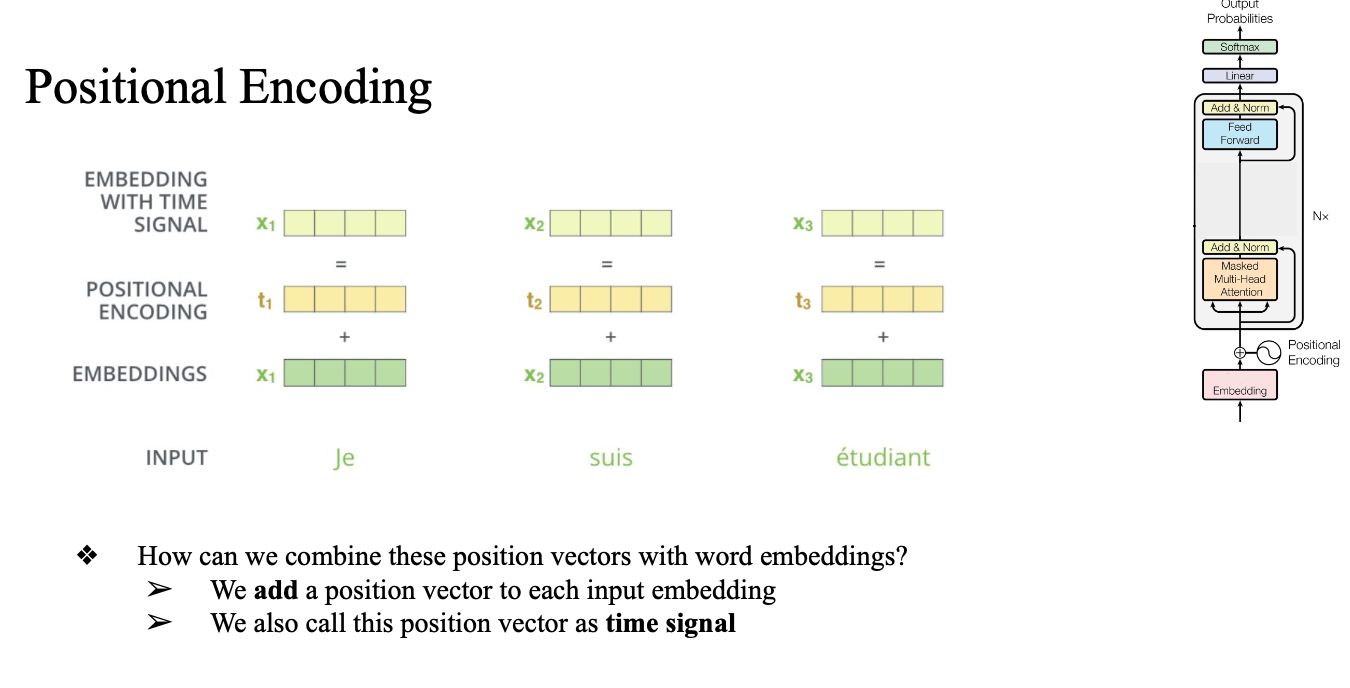
주기함수를 통해서 Init(짝수인지 홀수인지에 따라서, index i 에 따라서 다른 값을 할당)
이 값은 원래 word embedding에 더하거나 곱함
→ 이렇게 하면 순서 정보가 자연스럽게 임베딩에 포함됨
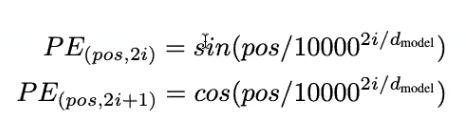
Large Language Models meets Mixture of Expert (MoE)
Llama 4, DeepSeek, Qwen
-> MoE architectures...
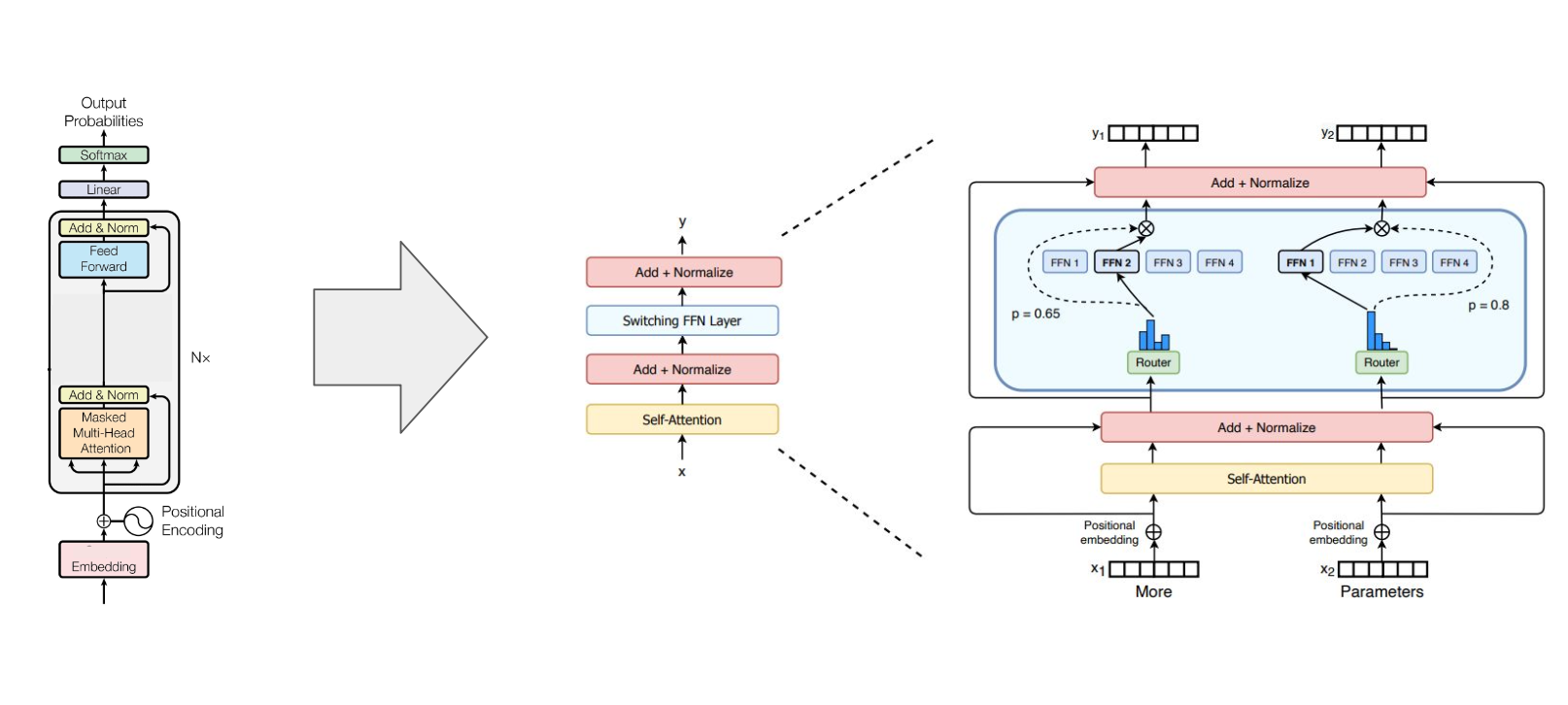
원래는 feed foward 가 단일이었는데 여러개를 두어서 계산함
이때 라우터가 특정 FFN을 통과하도록 지정해줌
원래는 dense → sparse한 모델 (선택적으로 activation이 되니까)
모델파라미터 증가? → 모델이 가질 수 있는 정보가 많아짐 → 성능이 좋긴 함
그래서 컴퓨테이셔널 비용이 증가하는데 (어차피 파라미터를 선택적으로 골라서 사용함)
MoE는 sparse한 학습을 진행 → 비용도 그렇게 크게 나오진 않음
단점?
- feedforward 를 gpu에 다르게 할당
- balancing 이 중요
- 고도의 소프트웨어적인 지식이 필요함
- 작동을 하기까지의 과정이 어려움
- 구현이 어려움
- 토큰이 expert 를 고르기..
- 몇개의 expert를 고르지? → top 2 가 보통…
MoE는 모델의 파라미터 수는 늘리고 계산량은 줄이는 LLM의 스케일 한계 문제를 해결했다...
Example of Self-Attention
x1 = [1, 2, 3, 4, 5], x2 = [6, 7, 8, 9, 0] 이라고 할 때,
self attention 을 위한 query, key, value weight matrix 가 아래와 같다면..
query
[[0, 1, 0, 0, 0],
[1, 0, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 0, 1]]
key
[[1, 0, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 0, 1]]
value
[[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 1, 0, 0, 0],
[0, 0, 0, 0, 1],
[1, 0, 0, 0, 0]]
x1과 x2에 대한 쿼리, 키, 밸류 벡터를 각각 구해보면
x1 쿼리 -> [2, 1, 5, 3, 5]
x1 키 -> [1, 3, 4, 2, 5]
x1 벨류 -> [5, 3, 1, 2, 4]
x2 쿼리 -> [7, 6, 9, 8, 0]
x2 키 -> [6, 8, 9, 7, 0]
x2 벨류 -> [0, 8, 6, 7, 9]
self attention score 구해보면 (sqrt(dk) = 2, softmax대신 simple normalization을 사용)
먼저 score = [(Q1 * K1) / 2 , (Q1 * K2) / 2]
score x1 = (2*1 + 1*3 + 5*4 + 3*2 + 5*5) / 2 = 56/2 = 28
score x2 = 86/2 = 43
[28, 43]
simple norm하면
[28/71, 43/71] -> attention weight
최종 x1 output (x2는 x2의 self attention weight 로 구하면 됨)
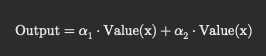
그러면 28/71 * [5, 3, 1, 2, 4] + 43/71 * [0, 8, 6, 7, 9] ...
