
ch12. Part-of-Speech Tagging
형태에 관련된 태깅
문법적으로 deep한 정보를 얻을 수 있는 건 아니다.
word에 대해서 무슨 품사를 갖느냐 마킹을 해주는 것
word 인풋을 주고 sequence pos tagging..
sequence tagging 을 어떻게 할 것이냐..
단어에 대해서 먼저 품사를 붙일텐데 널리 쓰이는 tagging이 뭔지.

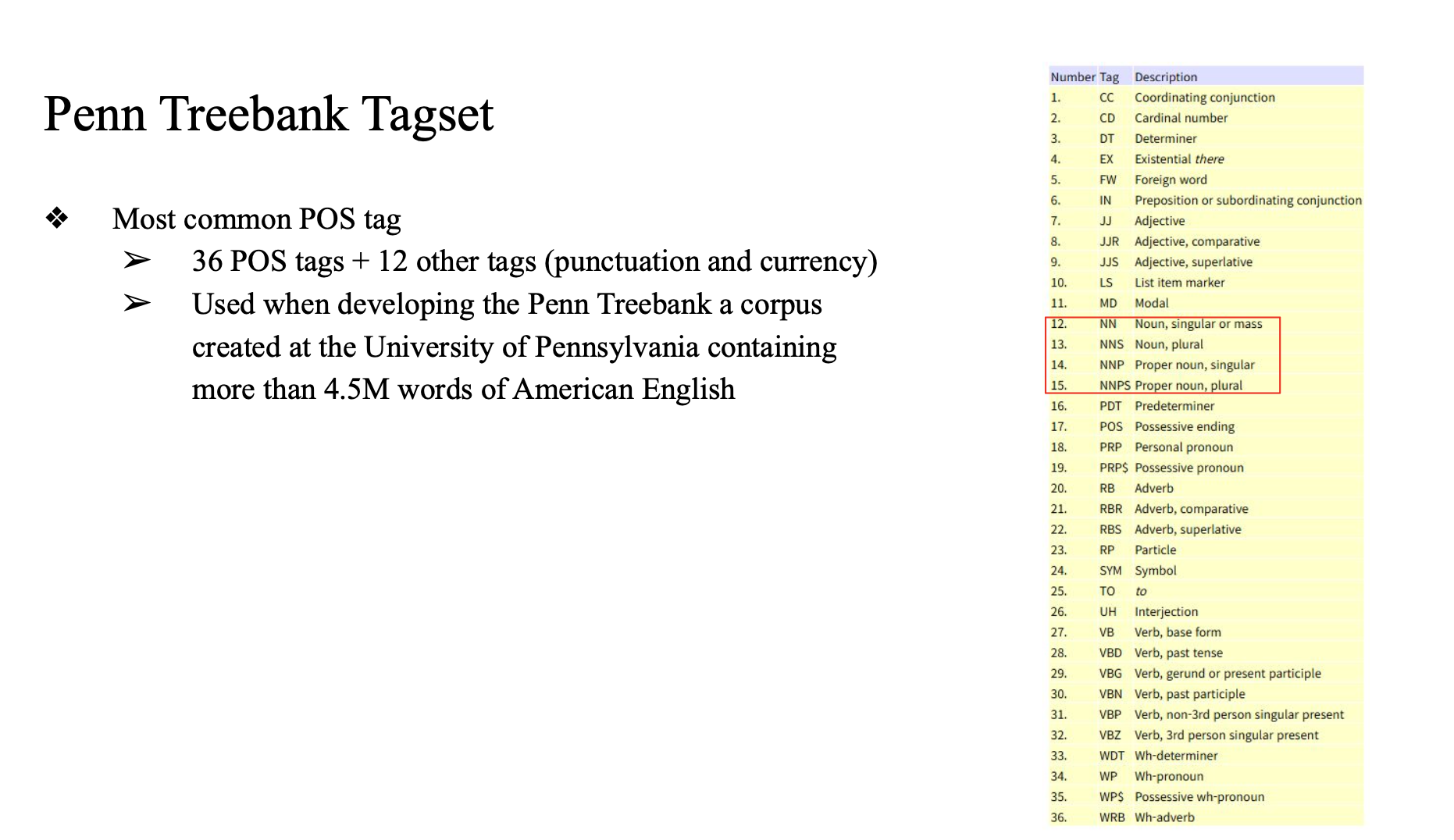
Penn Treeback Tagset
매칭해주는 것
라이브러리

KoNLPy
https://konlpy-ko.readthedocs.io/ko/v0.4.3/morph/
모델이 참고할수있는 정보가 많아지기 때문에 성능이 더 좋다..
품사 태그를 같이 주게되면 performance가 더 올라가지 않을까?
- 그치만 결국은 dataset이 중요한 것..
tagset
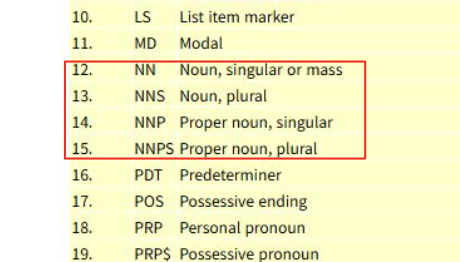
명사

동사

형용사

부사

tagset 분류

새로운 단어들이 자주 계속 추가되느냐..? -> open class
- 코로나.. instagramable..
자주 추가가 되지 않는 것 -> closed class - and, a, the, ...
보통 명사가 많이 추가될것
open class 가 보통 모델이 의미있는 정보를 줄 가능성이 높음
-> 그러면 모델에 open class를 다른 input feature를 주면 좋지 않을까..?

대체로 30개정도면 괜찮은 성능...
어려운 task..
-> pos tagging 하면 성능이 올라갈까...?
61개를 주면, 146개를 주면 성능이 올라갈까..?
example
문장이 주어졌을 때, pos tagging을 어떻게 하려나...

time 이 명사일까... 동사일까...
time flies 에서는 명사 -> NN tagging

files 는 '파리' 가 될 수도...
'날다' 가 될 수도...
여기서는 날다..
-> VBZ

like 는 종속접속사..
subordinating conjunction(IN)

fruit flie like 에서는 이제 NNS, VBP...

rule based로 pos 태깅 직접...
candidate corpus -> 확률적으로 접근
Predicts POS tags based on the probabilities of those tags occurring
counting base로 100번 중에 95번 NN이라면 -> NN tagging.
확률적으로 어소시에이트 된건아니지만
naive하게 접근해도 놀랍게도 잘 작동함 (90% accuracy)
POS Tagger using BERT

accuracy 를 100%로 올려보자..
classification 에서만 사용 가능 generation은 안됨..
decoder라는 컴포넌트가 없음
pre training(언어 지식 주입) objective
-
MLM
- 마스킹된 다음 input 예측
- my name is hyunsu -> my [MASK] is hyunsu
- [MASK] 가 name의 probability 가 1이 되도록 하는...
- 이건 모든 문장을 보고 빈 자리는 예측하게 됨
- 일반적으로 사람이 왼쪽 -> 오른쪽 으로 작성하는 식으로 하는 게 아님
- 인간이 text 작성하는 성격과 좀 다름 -> text generation 에 쓰일 수 없음
-
NSP
- 어떤 문장을 임의로 뽑아서 연속되어있으면 1, 아니면 0
- 다음 문장 classification 학습
- 더 자연스러운 다음 문장 예측 가능
-
특별한 labeling 이 필요 없음(annotation step 이 없음)
- 그냥 wiki 긁어와서 처리하면 됨
- 편리함
어느정도 지식을 가지고 있는 BERT
-> BERT를 불러와서 추가적인 training -> 간편, 더 잘 작동.
=> fine tune
WordPiece Tokenizer for BERT (POS Tagging)

Elsewhere -> EL + ##se + ##where
드물게 나오는 단어 -> 세 개로 나눠서 학습하면 더 성능이 좋다..
happiness -> happ + iness
-> 한 단어를 학습하는 건 좋은 게 아니다...
-> 나눠서 happy에 대한 context를 최대한 많이 배우는 것..
-> sub word tokenizer
=> wordpiece tokenizer -> vocab 구성 -> MSM, NSP 같은 과정을 수행함.
downstream task 에 대해서 tokenization 을 새로 정의하지 말고
그냥 원래 쓰던 것을 가져와서 다시 쓰자..
embbeding layer에 token information 이 다 있음
-> 새로 정의하면 BERT embbeding layer도 다시 구성해야함
-> 그냥 잘 유지해서 사용하자.. -> 실제로도 성능이 좋음
POS tagging can be either text generation or token classification

pos tagging은 두가지 task 로 볼 수 있음
- token classificaiton
- 토큰 분류
- BERT
- text generation
- i eat apples 를 넣어서 디코더가 PRON VERB NOUN 을 생성하도록
- BART,T5 model
보통은 분류(token level classificaiton)로 보는게.. 일반적
근데 BERT를 이용해서 wordpiece tokenizer를 사용하게 되면
Elsewhere 가 세 단어로 나눠지게 됨

그냥 elsewhere에서 분리된 단어는 모두 RB라는 태깅을 유지시켜줌
구현을 쉽게 할 수 있는 파라미터
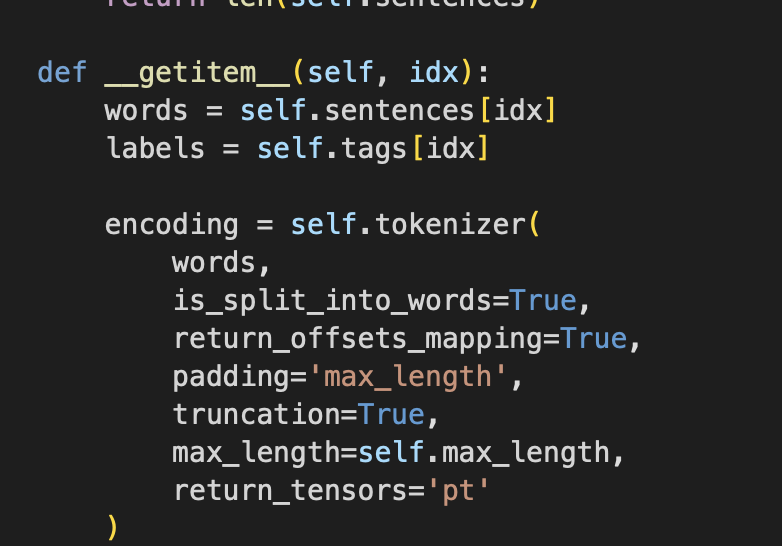
Dataset -> getitem -> 단어 input 이 들어왔을 때, 토크나이저에대한 인코딩 output이 뭐냐를 정의하는 경우가 많음
- mask를 랜덤하게 넣겠다면? 랜덤하게 making해줌
- 세개로 나눠진 word에 대해서 똑같은 pos tag 를 갖게 해
- self tokenizer 로 input 확인해서 ... xx
- is_split_into_word = True
-> 문제가 바로 해결됨
def __getitem__(self, idx):
words = self.sentences[idx]
labels = self.tags[idx]
encoding = self.tokenizer(
words,
is_split_into_words=True,
return_offsets_mapping=True,
padding='max_length',
truncation=True,
max_length=self.max_length,
return_tensors='pt'
)
# print(tokenizer.convert_ids_to_tokens(encoding['input_ids'][0]))
# print(tokenizer.decode(encoding['input_ids'][0]))
word_ids = encoding.word_ids()
label_ids = []
ori_label = []
for word_idx in word_ids:
if len(label_ids) > self.max_length:
break
if word_idx is None:
label_ids.append(-100) # ignore
# ori_label.append(-100) # debugging purpose
else:
label_ids.append(self.tag2id[labels[word_idx]])
# ori_label.append(labels[word_idx]) # debugging purpose
# print(ori_label)
# print(label_ids)
return {
'input_ids': encoding['input_ids'].squeeze(),
'attention_mask': encoding['attention_mask'].squeeze(),
'labels': torch.tensor(label_ids)
}CLS token
모든 sentence 에 첫 토큰으로 [CLS] 토큰 부여 (문장에 대한 모든 정보(의미)가 담겨있음)
[SEP] 토큰 으로 문장 seperate
BERT를 불러오고 -> 분류하고자 하는 class 수 만큼을 prediction 을 prob distribution을 만들 수 있는 fully connected classifier 를 올려놓는 과정이 꼭 필요함
token classification 도 마찬가지
-> 토큰별로 pos tagset 을 penn treebank 라고 한다면
-> 원래는 word 수 만큼 * 768의 아웃풋
-> CLS에 대한 하나의 임베딩 output -> fully connected clssifier 전달 -> back propagation을 하는 식의 traning
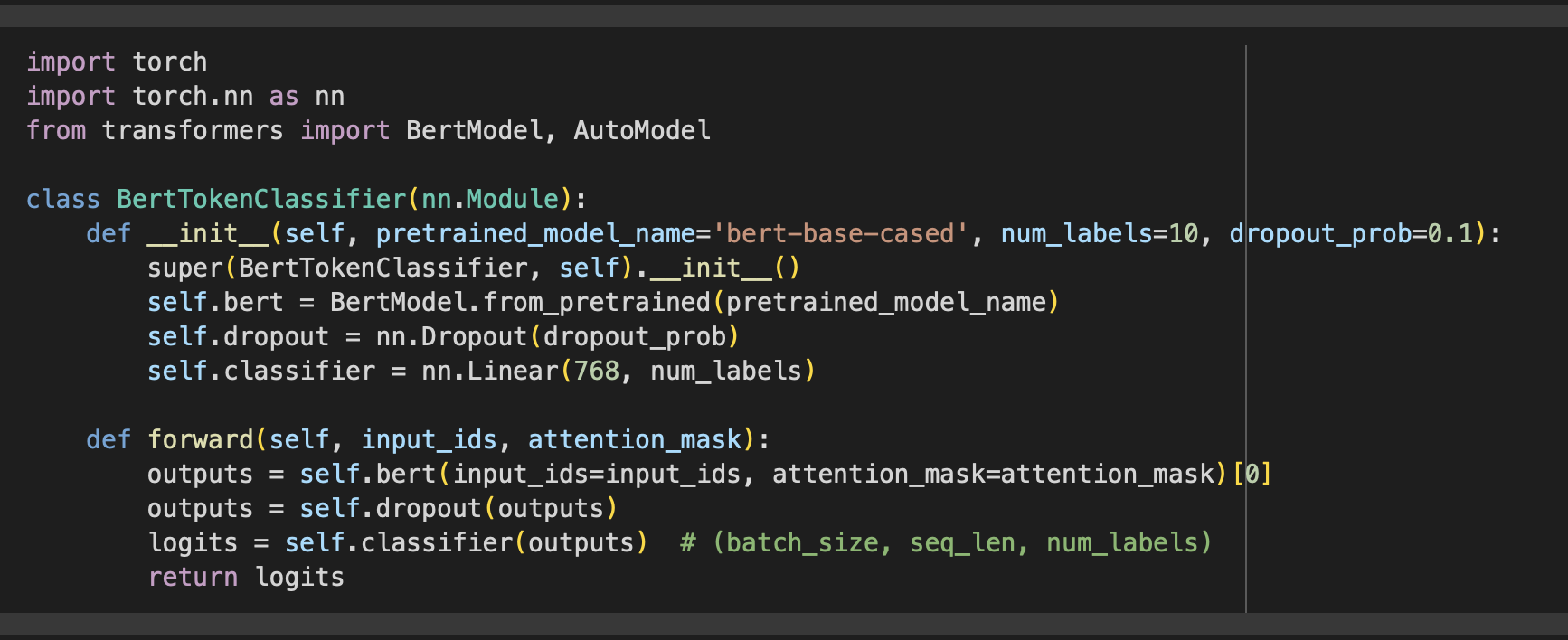
import torch
import torch.nn as nn
from transformers import BertModel, AutoModel
class BertTokenClassifier(nn.Module):
def __init__(self, pretrained_model_name='bert-base-cased', num_labels=10, dropout_prob=0.1):
super(BertTokenClassifier, self).__init__()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.dropout = nn.Dropout(dropout_prob)
self.classifier = nn.Linear(768, num_labels)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)[0]
outputs = self.dropout(outputs)
logits = self.classifier(outputs) # (batch_size, seq_len, num_labels)
return logits근데 token classification 에서는 [CLS] 토큰만으로 모든 워드에 대한 predict 를 진행한다?
- 그냥 모든 word 별로 probability distribution 과 정답값을 비교해서 정하는 것이 더 상식적인 생각...
POS tagger using BERT
sequence classification
허깅페이스에서 모델 가져오기..
bert-base-cased
토크나이저도 같이 가져와야함.
-
우리가 살고 있는 이 세계의 언어지식을 주입할 때, 토큰을 어떻게(split) 설정했는가.. ( 단어 단위인지... 어떤 단위인지... 모델별로 다 다르게 됨 -> 모델에 특화된 토크나이저를 가져올 필요가 있음)
-
같은 토크나이저를 사용하는 게 좋음
POS Tagging Corpus

데이터셋이 있어야,, 학습해보고 -> 성능확인
treebank.tagged_sents()
korean

한국어 관련 BERT... KoBERT
어떤 setence -> 토큰별로 시퀀스 prediction 가능
두문장 관계도 0,1,2 분류 가능
다양한 format 의 classification 이 다 가능함
