
ch09.Vector Semantics and Embedding
Vector Semantic

어떤 단어를 vector 로 표현하고 싶음.
(숫자의 나열로 표현)
- 강아지를 숫자로 나열
- [0.1 0.2 0.3] -> mapping 과정.. 어떻게 의미를 담을까?
벡터로 표현 가능하면?
- clustering
- performing
Semantics
단어의 의미

- 주변 context에 의해 정해질 수 있다.
- 단어는 주변 문맥을 봐야 한다.
- Distributional Hypothesis
- 같은 문맥에서 나온 단어 -> 비슷한 의미

ongchoi 를 몰라도,, 비슷한 시금치... 등과 비슷하게 등장함..
그러면 Ongchoi가 시금치와 비슷할 거다.. 라고 유추할수 있음
-> 이 과정을 컴퓨터도 할 수 있게 하자..
Context information

context word의 정보를 vector 에 담자.
-
BoW를 이용해 vector semantic 을 담아보자.
- Bow: 어떤 document 나 문장이 주어지면 그 안에 등장하는 word들의 frequency를 table로 만드는 것.

- vocabulary(unique word) 만들기
- document가 주어졌을때 voca를 추출
- vocab 개수만큼 initialize.
- 해당하는 vocab이 등자하면 1로 바꿔줌
- 혹은 등장횟수
단점

- 순서 고려가 안 됨
- rare 한 단어가 더 중요한 의미를 담고 있을 수 있음
- 기존 구현 방식엔 적용이 되어있지 않음
- 치명적인 단점
- TF-IDF 를 사용하여 극복
- ...
TF-IDF
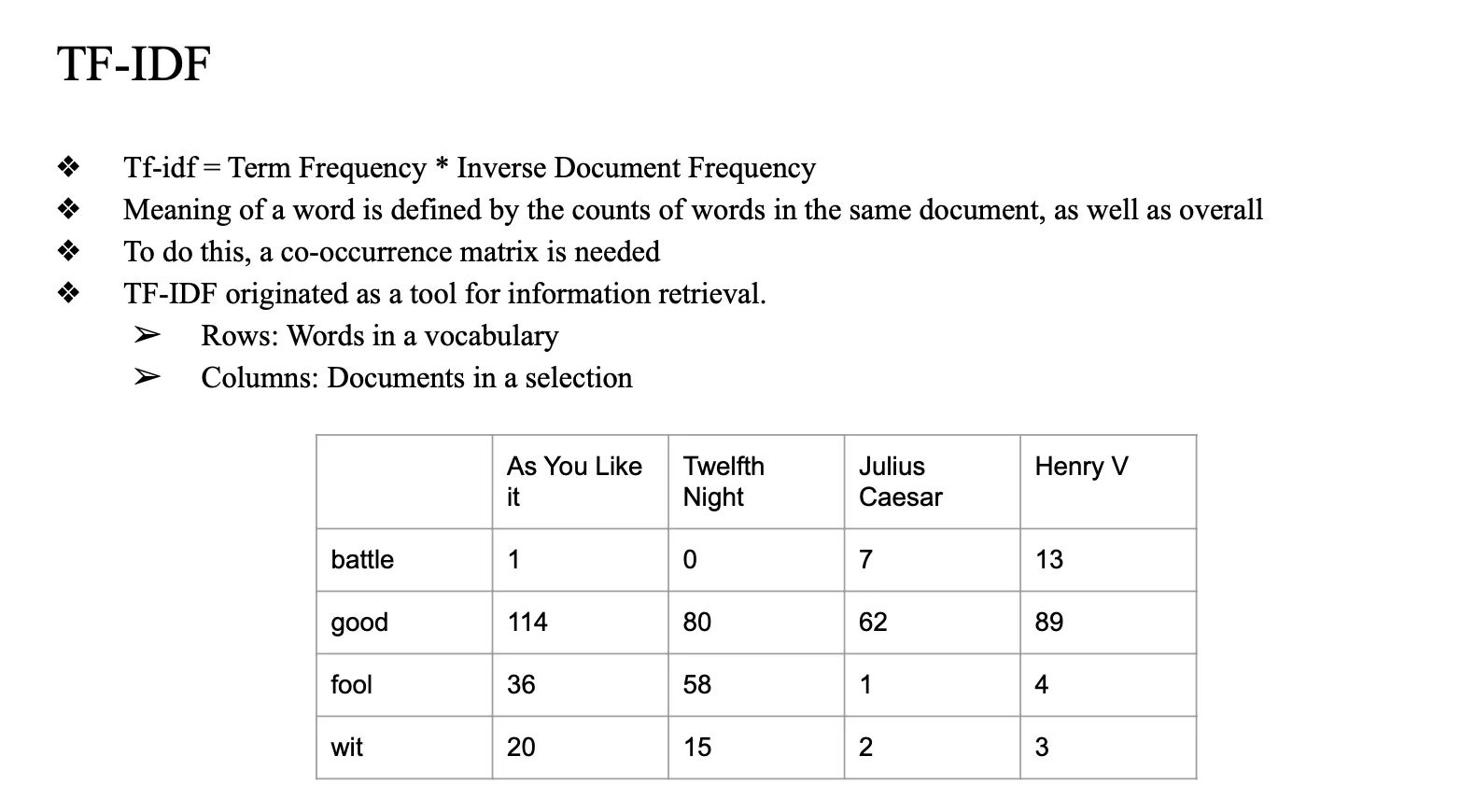
- Term Frequency * Inverce Document Frequency
- 얼마나 자주 나왔는지 * 얼마나 희귀한지
- 단어 등장 횟수 * (전체 문서 대비 해당 단어가 등장한 문서개수)
- co-occurrence matrix 만들기
- 각 document를 가지고 vocab를 만들고, 각 vocab이 각각의 document에 몇 번 등장했는지 세는 matrix
- 이 count를 바로 vector에 쓸 수 있는데
- 이러면 마찬가지로 rare word inportance 고려 안 하는 것임

4dimention 으 이해하기 위해 일단 2차원으로 floating 해놓음
fool 이랑 wit는 어쨌든 비슷한 위치에 존재하게 됨
Document 기준으로 단어의 등장 횟수를 세는 방식은, 자주 등장하지 않더라도 의미 있는 단어를 충분히 반영하지 못하는 한계가 있다. 반면, window 기반의 context word들과의 동시 등장 빈도(co-occurrence) 를 바탕으로 벡터를 구성하면, 적게 등장한 단어라도 문맥상 중요한 의미를 가질 수 있어 더 풍부한 표현이 가능하다.
context size(window size)을 몇으로 정해야하는가가 중요.
TF-IDF 계산

example

- battle 이 d_1 에서 한 번 등장
- battle 은 전체 37개 document 중에서 21번 등장
- 37/21 = 1.76
1 * 1.76
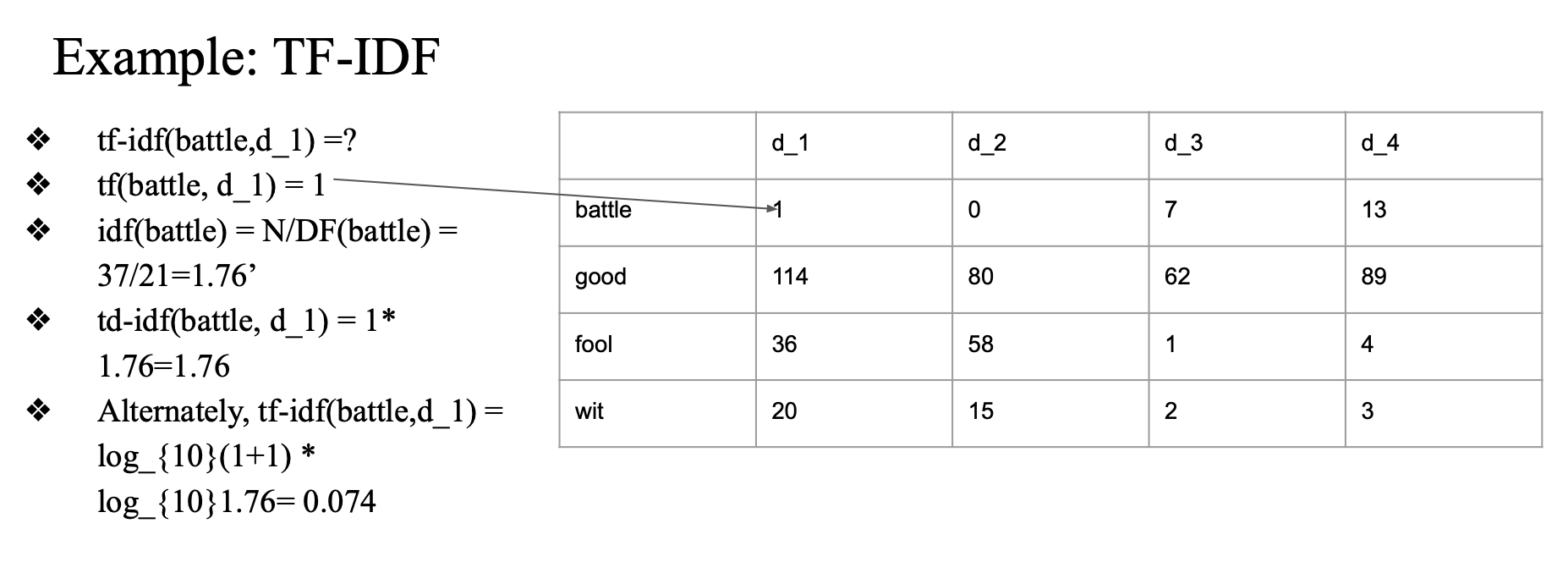
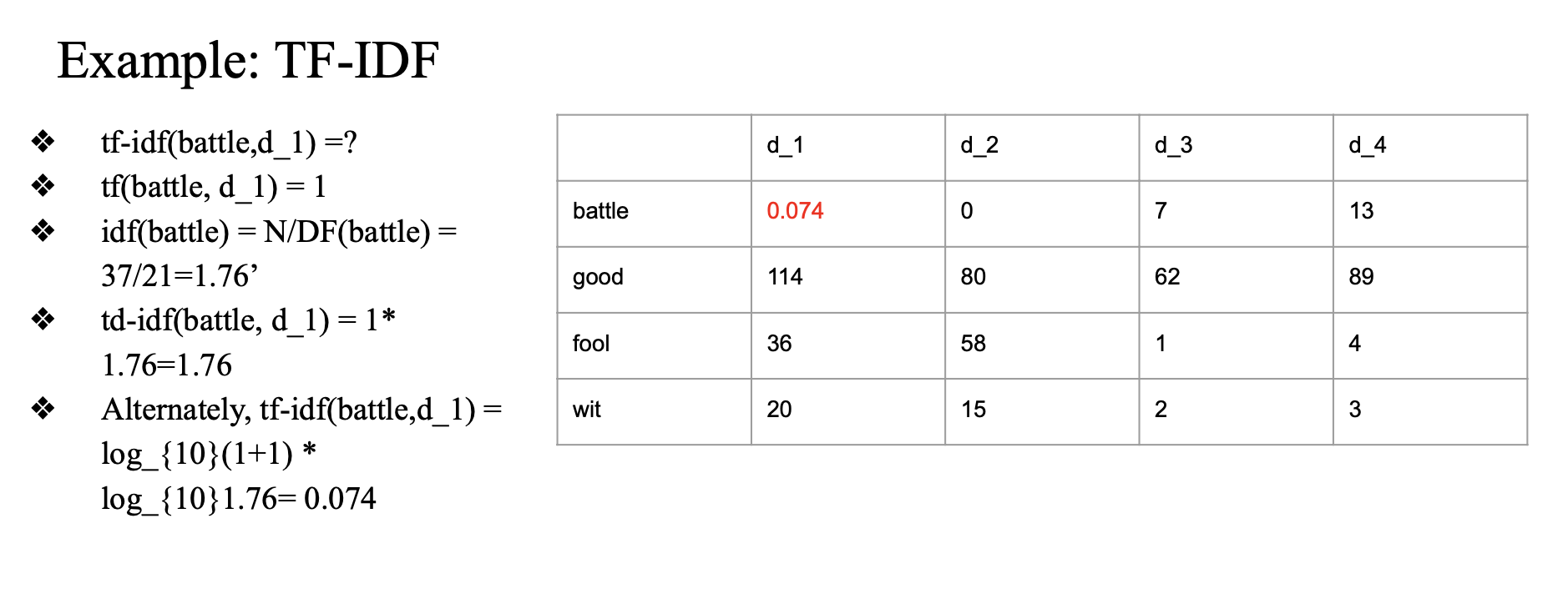
idf 로그 취해서 계산
- normalize,
- scale 줄이기
그리고 smoothing도 해줌
- log(tf+1)
- log(idf)

sparse 한 결과를 낳는다
벡터를 가지고 왔는데 0이 너무 많은 문제 → 0값은 무의미 하지 않나?

Sparse vector = 대부분의 원소가 0인 벡터
- TF-IDF로 문서 벡터를 만들면 보통:
- 단어 수 (vocabulary size): 수천~수만 개
- 각 문서에 실제 등장하는 단어 수: 매우 적음
- 메모리 비효율: 수천 차원의 벡터 대부분이 0 → 저장 공간 낭비
- 연산 속도 저하: 계산상 비효율 (특히 고차원 연산에서)
- 거리 계산 왜곡 가능성: 0이 많으면 유사도 계산이 부정확해질 수 있음
- 계산 간단하고 직관적
- 의미 정보(rare word 중요도)를 반영함
-> 많은 ML 모델에서 입력 벡터로 무난하게 사용 가능
특히 데이터가 작거나 딥러닝을 쓰기 어려운 상황에서 아주 강력한 베이스라인
TF-IDF는 보통 어떤 모델과 결합?
- Logistic Regression (선형 분류 모델)
- 벡터로 표현된 문서를 입력받아 클래스를 예측함
- TF-IDF가 고차원 sparse feature로 잘 맞음
- Naive Bayes
- 확률 기반의 전통적인 텍스트 분류 알고리즘
- 단어 등장 여부나 빈도를 확률로 해석함
- TF-IDF를 그대로 쓰기도 하고, TF만 쓰기도 함
TF-IDF는 대부분의 벡터 값이 0인 희소(sparse) 벡터를 생성하므로 메모리와 계산 비용 측면에서 문제가 생길 수 있다.
그럼에도 불구하고, 단어 중요도를 반영하는 간단하고 효과적인 벡터화 방법으로, Logistic Regression이나 Naive Bayes 같은 전통적 머신러닝 알고리즘과 자주 결합되어 사용된다.
그러나..
TF-IDF는 단어가 어떤 문맥에서 사용되었는지 고려하지 않고,
문서 전체 통계만 가지고 벡터를 만듦
apple 이 회사이름인지 사과인지 고려 x
단순하게 특정 단어가 한 문서 안에서 몇 번 나왔는지 (TF) 그 단어가 전체 문서에서 얼마나 희귀한지 (IDF) 만 계산에 이용함..
결국 TF-IDF는 단어의 의미를 주변 단어(문맥)와 무관하게 고정된 벡터로 표현하기 때문에, 문맥에 따라 의미가 달라지는 단어들을 구분하지 못한다라고 할 수 있음..
"TF-IDF represents words as fixed vectors regardless of the surrounding context, so it cannot distinguish between words that have different meanings depending on the context."
