
ch08. Conditional Random Fields(CRF)
discriminative model 의 한 종류
Text classifacation model 분류

다양한 text classification 기법이 있다.
- hmm
- naive bayes
- logistic regression...
두가지 관점으로 분류해보면
1. Label Type (라벨 유형)
-
우리가 예측하려는 라벨의 구조에 따라 모델이 달라짐
-
개별라벨
- 문장, 문서등 단일 입력에 대해 단일 라벨 예측
- naive bayes, logistic regression
-
시퀀스라벨
- 입력이 여러 토큰
- 각 토큰에 대해서 라벨링 하는 것
- hmm, crfs
2. model type
-
모델이 데이터를 어떻게 다루는지, 어떤 확률을 학습하는지에 따라 구분
-
생성 모델
- 데이터 생성 전체 구조 학습
- joint probability
- p(x,y) or p(x|y) 에 집중
- naive bayes, hmm
-
Discriminative(판별 모델)
- 데이터를 생성하려고 하지 않음 → 오직 분류 목적
- 확률만 보기(prediction label, y)
- logistic regression, crf
Conditional Random Fileds

- Generalized multi-class regression
- multiclass(activation function 으로 softmax를 사용)
- 전체 클래스에 대한 스코어를 다 합해서 특정 클래스 확률에서 나눠줌
- normalization 한다는 것을 담음
- generalized 됐다...
- logistic 은 원래 한가지... -> 이걸 여러가지에 적용될수있게 했다..
- crf가 좀더 확장됐다..
- multiclass(activation function 으로 softmax를 사용)
- HMM
- joint probability 모델링 -> 어려움
- CRF보다 고려해야할 상황이 많음
- 특정한 가정을 하지 않으면 연산이 복잡 (strict 한 가정이 많음)
- CRF
- 유연화된 HMM (가정이 strict 하지 않음)
- 어떤 sentence 에 대해서 품사 태깅 task (pos tagging)
- HMM
- 주어진 sentense에 대해서 그 센텐스에 대한 pos tag와 sentense 같이 나올 확률
- CRF
- sentense가 주어졌을 때 어떤 pos tag 가 나올지 계산
- HMM
CRF에서는 Potential Function / Feature Function으로 입력과 라벨 간, 혹은 라벨 간 관계까지 표현 가능
단어-태그 관계뿐 아니라,
이전 태그가 무엇이었는지도 고려 가능
CRF는 내가 어떤 단어를 보고 어떤 태그를 붙일까?를 문장 전체 맥락으로 판단
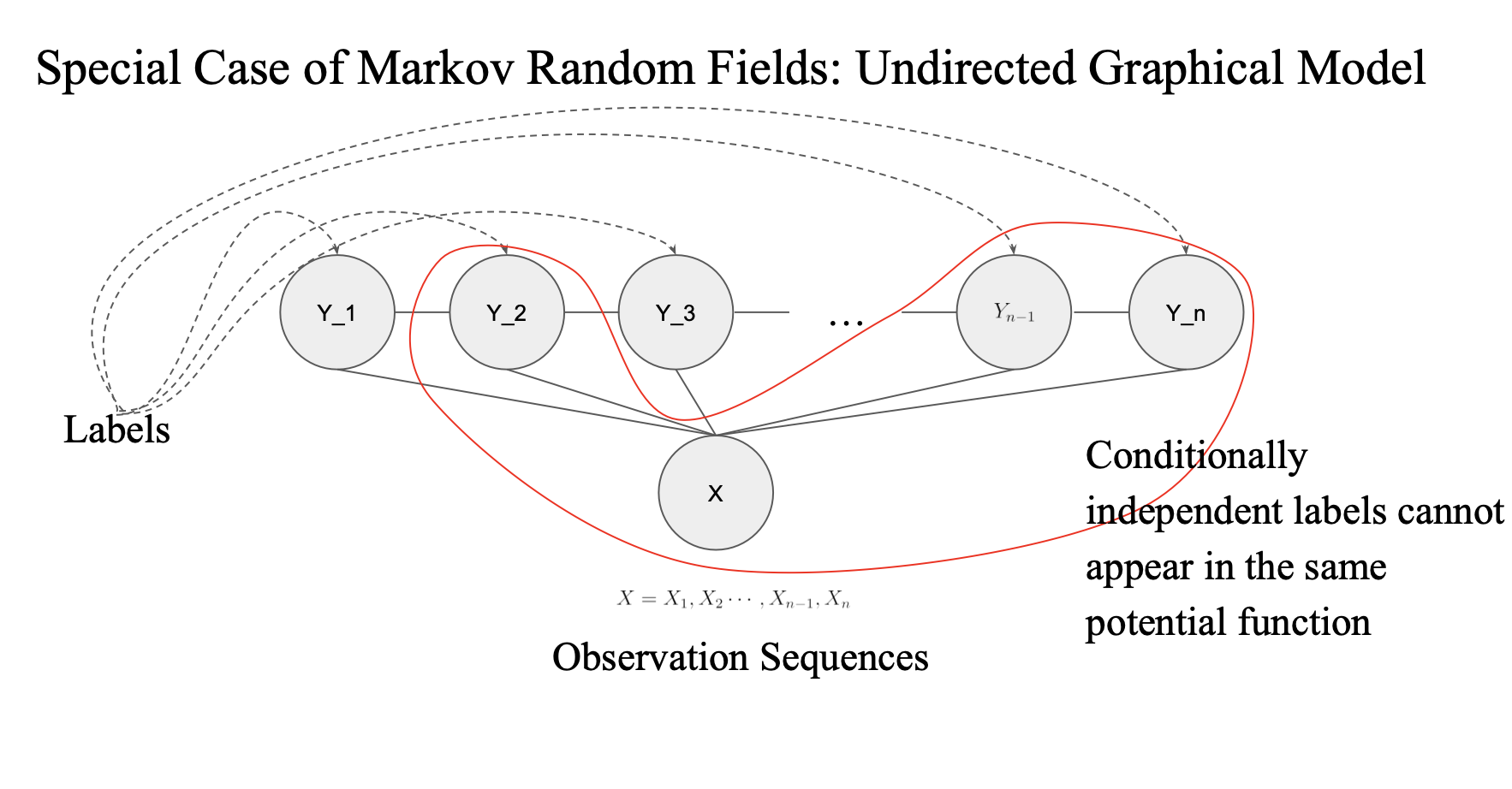
CRF를 만들어가기 위해서는 feature function 을 정의해야함.
feature function 을 만들때 고려해야할 특성
- 여러 label 이 있다고 가정
- sentence가 주어졌을 때 이 label을 갖게끔 설정해놓을 수 있음
- 각각의 label 다 관계가 있는 것
- conditional random field는 뭘하려고?
- sequence label 을 prediction
- y1, y2, y3 가 다 연결되어있고
- feature fuction 정의해야할때 fully connected graph 에서 정의해야함
- 그렇지 않으면 안 됨
- 이 그림에서 y_1 과 y_n 은 연결이 안 되어 있음
conditionally independent labels cannot appear in the same potential function
potential function 은 feature function과 동일한 개념
- 연속된 label 관계에서만 정의해야함..
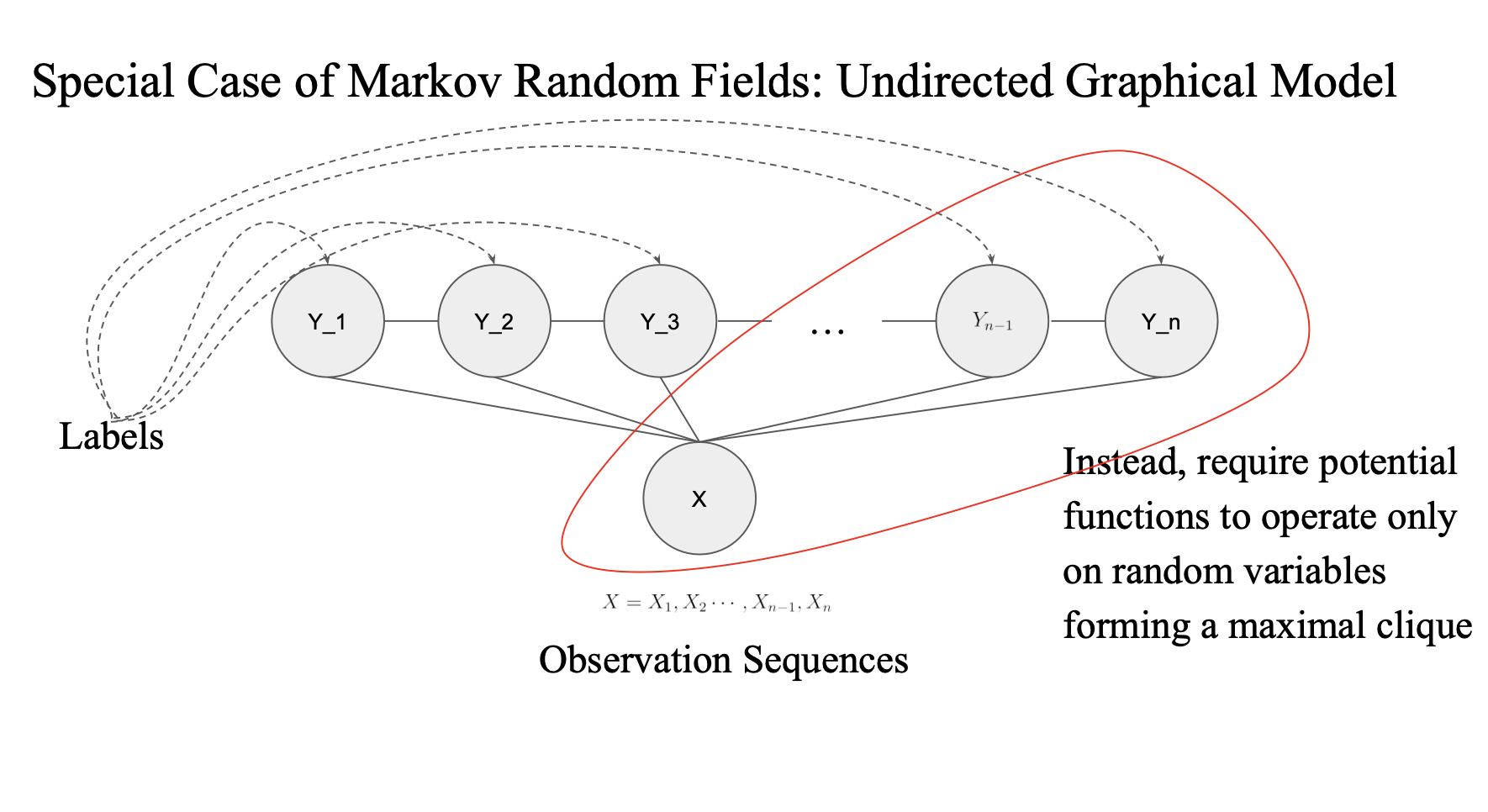
이렇게 다 연결되어있는 경우에는 가능함
Instead, require potential functions to operate only on random variables forming a maximal clique
maximal clique?
수식

CRF의 식
e의 몇 제곱? 으로 표현
- 모든 가능한 sequence 들에 중에서 각각 점수를 매기고
- weight * (feature fuction)
- 어떤 possible sequence y 가 있다고 가정
- prediction 은 feature에 의해서 정의가 됨
- 그리고 모든 경우의 합에 대해서 분모 값으로 해줌
- normalization하는 것..
- softmax처럼
Training CRF
트레이닝한다..
세타값들을 찾아간다...
feature를 얼마만큼 weight 값을 줘서 이 확률을 계산할 것인가...

세타가 얼마가 적당한가
- loss를 구해서 업데이트..
- 여기서는 Negative log likelihood 사용
- 어떤 정답에 label 에 해당하는 sequence 의 확률값을 높여가는 것
log likelihood를 최대화 하고 싶은데 그게 어려우니
gradient descent 를 써서 loss가 최소가 되는 것을 찾는게 쉬우니
세타값이 얼마가 적당한지 찾아가는 것
entropy(불확실성)
maximum entropy 원칙에 따라 확률값을 예측할거다(모델을 트레이닝 할거다)
모든 가능한 경우를 최대한 고려해보겠다
최대한 많은 시퀀스를 보고 정답을 찾안나가겠다
확실하게 예측한다는 건 -> entropy 낮은 거
그레디언트 구하려면 미분을 해줘야 함.

Gold label - prediction
관측값(정답, 실제 값) - 모델이 예측한 확률 P
Compute

어떤 probability * feature function
모델에서 얻어온 확률값 을 feature에 곱해줌
결론적으로 weighting 하는 것이 됨
(결국 확률값은 weight 값이 됨(0~1값))
그럼 확률값은 어떻게 구할것이냐?
HMM과 비슷...
쉽지 않다..
