TL;DR
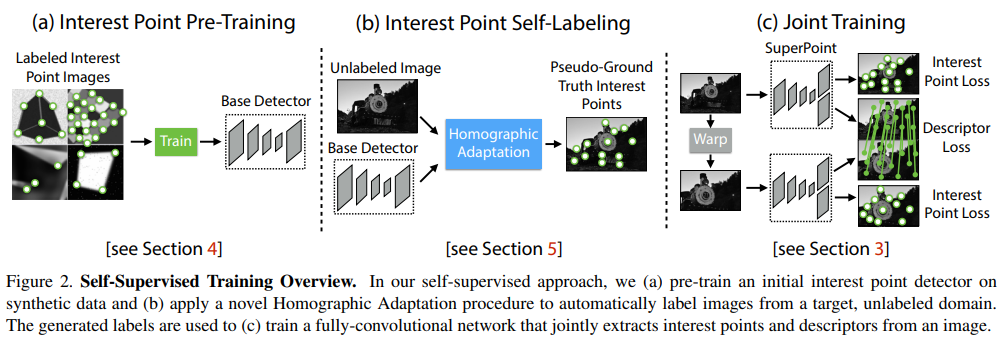
- SLAM 시스템 내에 딥러닝을 접목한 논문 중 하나인 SuperPoint는 SLAM의 많은 컴포넌트 중 ORB feature를 탐색하는 방식을 딥러닝의 self-supervised 기법으로 푼 것을 주 내용으로 하고 있다.
- 딥러닝의 높은 성능을 위해 데이터(interest points)를 만들어 학습을 수행한다.
- Step 1) MagicPoint: Synthetic dataset을 활용해 base detector를 만든다. (
Figure 2.(a)) - Step 2) Homographic Adaptation: unlabeled image들에 다양한 와핑을 적용하고, MagicPoint의 base detector를 통과시켜 interest point들을 추출한 후, 이들을 합쳐서 Pseudo-GroundTruth Interest Points를 생성한다. (
Figure 2.(b)) - Step 3) SuperPoint: MagicPoint의 base detector의 decoder에 추가로 descriptor head를 덧붙여 interest points와 descriptor 를 추출하는 모델을 학습한다. 이 때 학습 데이터셋으로 Step 2)의 Pseudo-GroundTruth Interest Points를 활용한다. (
Figure 2.(c))
- Step 1) MagicPoint: Synthetic dataset을 활용해 base detector를 만든다. (
SuperPoint Architecture
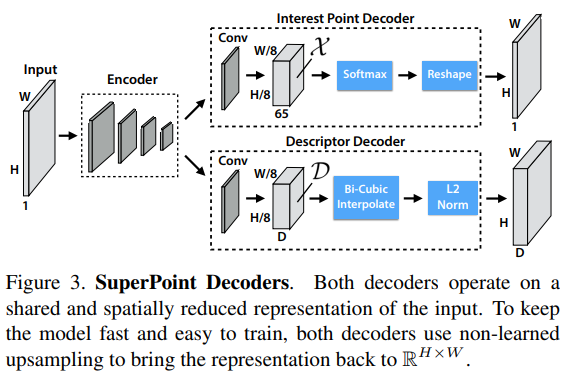
-
위 그림인,
Figure 2.(c) Joint Training에 자세한 설명이 소개되어 있다. -
Shared Encoder:
- CNN 기반 VGG-style로 3번의 max-pooling을 수행해, 최종 피처의 크기는
, 이며, 이 최종 피처를 cell이라 명칭한다.
여기서의 cell의 크기는 8x8로 지정하고 있다.
- CNN 기반 VGG-style로 3번의 max-pooling을 수행해, 최종 피처의 크기는
-
Interest Point Decoder:
- cell의 각 픽셀은 interest point에 해당하는지에 대한 확률값과 대응된다.
- 보통의 dense prediction의 경우에는 추출된 feature 값의 resolution이 작아지면 디코더에서 이미지를 다시 upsampling을 하는데, 이 때 다양한 부작용이 속출(unwanted checkerboard artifact)하기도 하고 연산 시간 측면에서도 오래 걸리는 경향이 있다.
- 그래서 저자는 explicit decoder(=sub-pixel convolution(TensorFlow) or pixel shuffle(PyTorch))를 사용해 연산량을 줄이고 디코더를 간소화하는 방식으로 네트워크를 사용한다.
- 위의 그림에서 Interest Point Decoder의 두번째 레이어가 65개의 채널을 가지는 것을 확인할 수 있는데, 1개는
"no interest point" dustbin, 나머지 64개는 explicit decoder에 사용되는non-overlapping 8x8 grid영역을 표시하게 된다.
-
Descriptor Decoder:
- 위의 그림에서 Descriptor Decoder의 두번째 레이어의 채널인 가 descriptor를 표현하는 벡터가 된다. 후에 실험에서 256 값을 가지며 descriptor를 표현한다.
- bi-cubic과 L2-normaizes(to be unit length)를 거쳐 표현된다.
Superpoint loss function
- 크게 interest point가 잘 학습됐는지 판단하는 와 descriptor가 잘 학습됐는지 판단하는 , 두 가지 loss function이 최소화되도록 loss function을 설계하는 과정이다.
- : 앞서 설명했던 cell의 각 픽셀에 대한 65개의 채널값 중 의 확률을 정답 와 비교하며 cross-entropy 식에 대입하는 방식으로 loss function을 정의하였다.

- : 한 쌍의 두 이미지를 비교하는 방식인데, 첫번째 이미지와 두번째 이미지가 있을 때, 첫번째 이미지의 의 중심점을 homography 에 대해 와핑해서 두번째 이미지 중심점과 거리를 비교하여 특정 thresholds=8 내에 있으면 1, 아니면 0으로 flag를 만든 후, hinge loss 를 활용해 적당한 마진을 두고() 두 descriptor vector 가 같은 클래스에 속하는 지, 다른 클래스에 속하는 지에 대해 loss function을 정의하였다.

Synthetic Pre-training

- 위 그림인,
figure 2.(a)의 학습에 관여한 데이터와 학습 모델 MagicPoint 를 설명한 챕터로, synthetic dataset을 저자가 직접 만들어 학습은 수행했고, 결과로는 다른 detector보다 깔끔하게 특징점을 잘 추출하는 것을 그림으로 보여주고 있다.
Homographic Adaptation
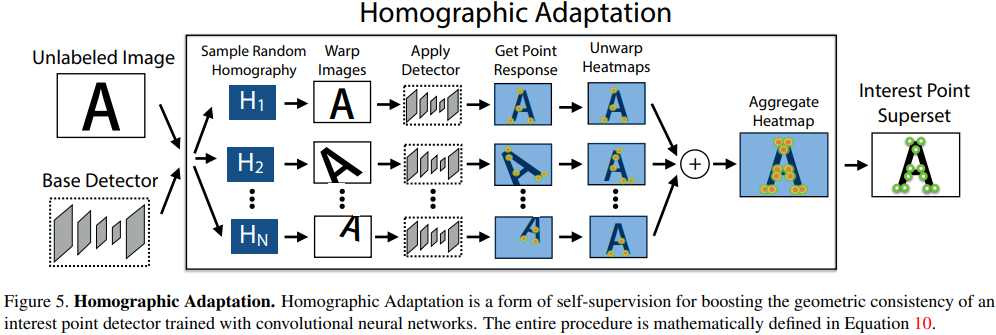
- 위 그림인,
figure 2.(b)의 내용을 자세히 풀어 쓴 파트로, homographic adaptation을 통해 더 많은 augmentation을 수행해 Pseudo-GroundTruth Interest Points 를 만들고, SuperPoint 학습에 사용될 데이터 셋을 구축하는 내용에 대해 담고 있다. - 과정은 다음과 같다:
- Unlabeled image를 랜덤한 homography로 와핑하여 여러 이미지를 만든다.
- 그 후, 와핑된 여러 이미지들을 MagicPoint에 통과시켜 예측된 interest point들을 수집한다.
- 와핑된 이미지와 interest points를 다시 원래대로 돌리고, 모든 interest point들을 잘 정제해 합치면 Interest Point Superset이 생성된다.
- 와핑된 이미지를 다시 원래대로 돌려 잘 합칠 때 아래와 같은 수식을 사용해 진행한다.


Experiments
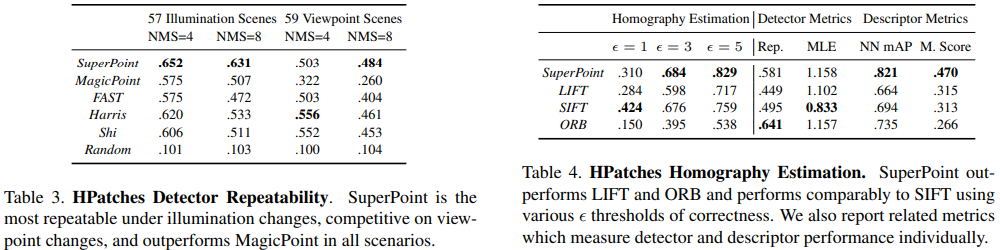
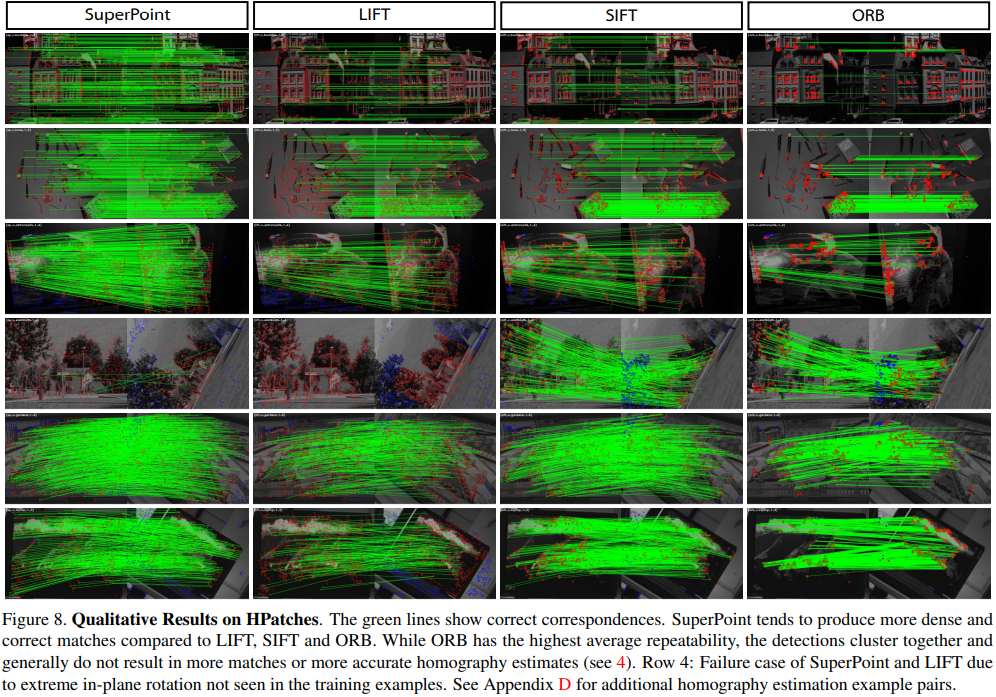
- 성능면에서 예전 방식보다 낫다고 주장하고 있다.
- ORB 특징점 매칭 알고리즘과 비교해서 SuperPoint의 Repeatability가 떨어지는 측면이 있지만, ORB의 특징점 추출이 sparce 한 측면이 더 많아서 전체적인 homography estimation task 측면에서 봤을 때는 점수가 높지 않다고 한다.
- Evaluation Metric에서도 전반적으로 높은 점수를 가지고 있다.
(Evaluation Metric은 Appendix에 첨부됨, 추후 포스팅 예정)
Conclusion
(1) Synthetic dataset의 Knowledges를 실제 이미지로 활용하는 것이 가능하다는 것을 보여준다.
(2) Sparce interest point detection & description을 단일의 convolutional network에 적용하여 학습해도 효율적으로 잘 동작한다.
(3) 결과 시스템은 Homography Estimation과 같은 기하학적 컴퓨터 비전 매칭 작업에 적합하다.
References

First Attempt In Learning