Anthropic의 'Claude 3 Sonnet' 모델을 사용하여 사용자의 질문에 대답하는 간단한 슬랙봇을 만들어 보겠습니다.
RAG로는 Amazon Bedrock의 Knowledge Base를 사용하였으며, 슬랙봇이 사용자와의 이전 대화 내용을 기억하여 답변할 수 있도록 Amazon DynamoDB를 활용하였습니다.
RAG란 Retrieval-Augmented Generation의 약어로, 대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스입니다.
Bedrock 설정
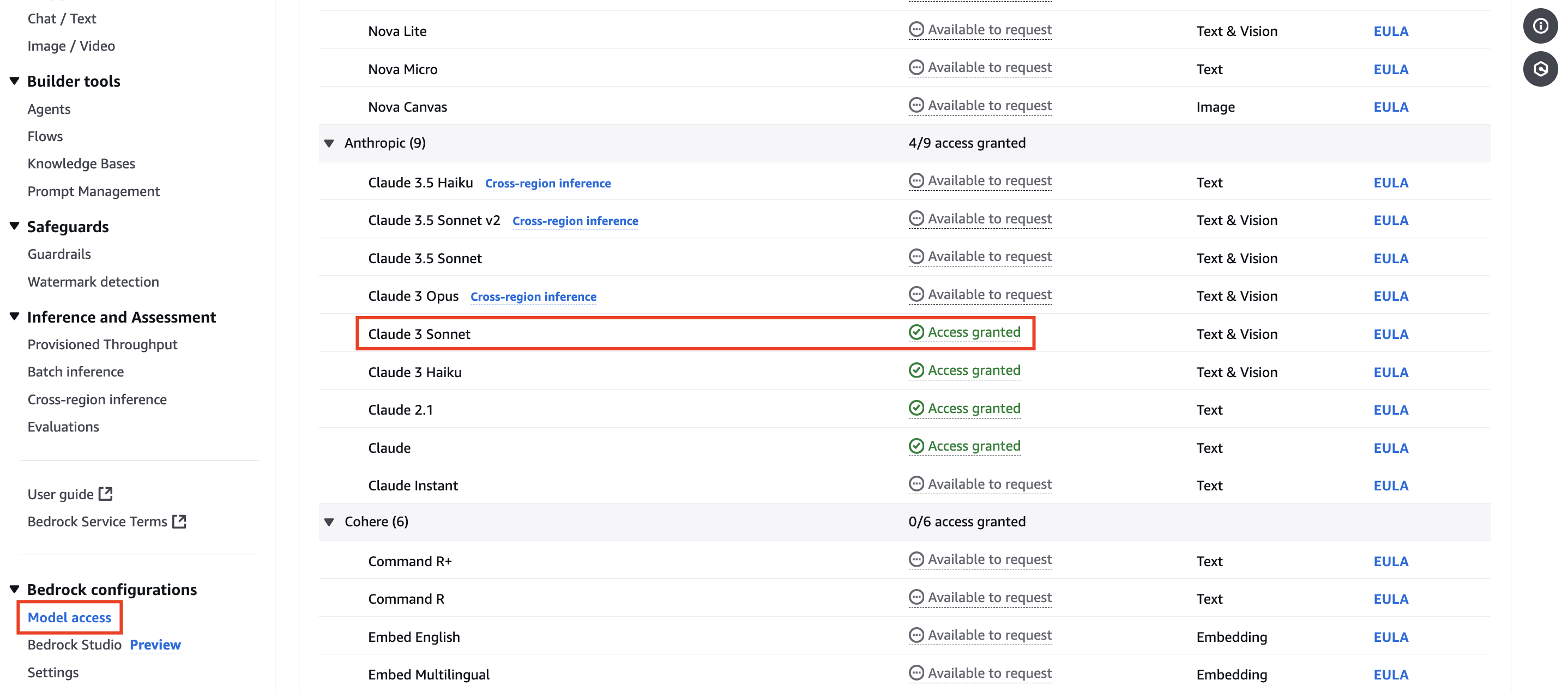
Model 액세스 허용
특정 모델을 사용하기 위해서는 Amazon Bedrock의 'Model access' 페이지에서 사용을 원하는 모델의 액세스를 허용해야 합니다.
Knowledge Base 설정
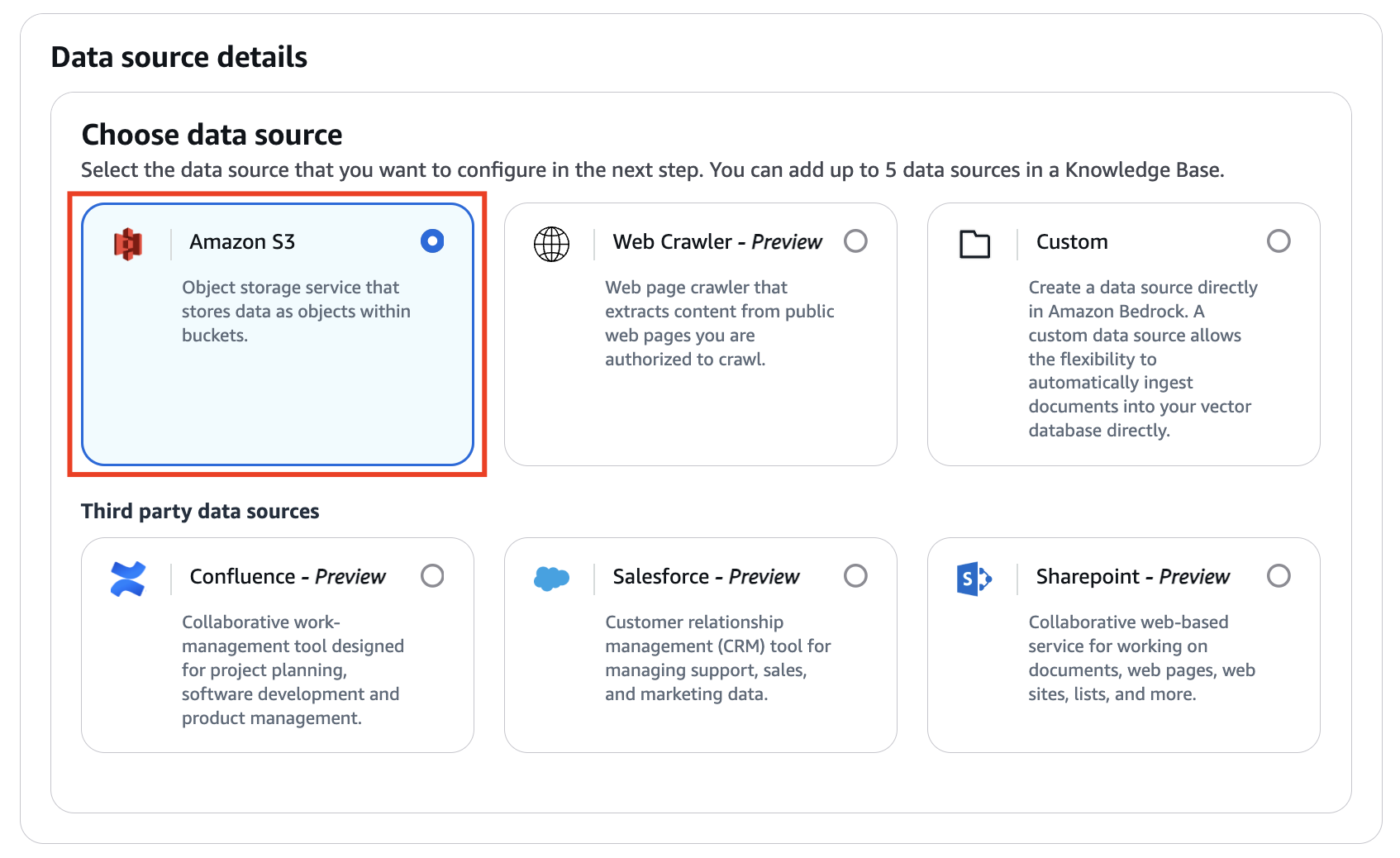
Configure data source
외부 지식 베이스로는 Amazon S3를 사용하였습니다.
Chunking strategy를 선택할 수 있는데, 'Default chunking' 선택 시 chunk 당 디폴트 토큰 수는 300 입니다. 디폴트 값으로 테스트 시 chunk 당 300 토큰은 너무 작아서 지식 베이스에서 적합한 데이터를 가져오지 못해 슬랙봇이 사용자의 질문에 제대로 답변하지 못하는 문제가 발생했습니다. (질문에 대한 지식 베이스의 데이터가 300 토큰 이상인 경우가 많아 데이터가 잘려 부정확한 답변을 하였음)

따라서 Chunking strategy를 'Fixed-size chunking'으로 변경한 뒤 'Max tokens'를 1200으로 설정했습니다.
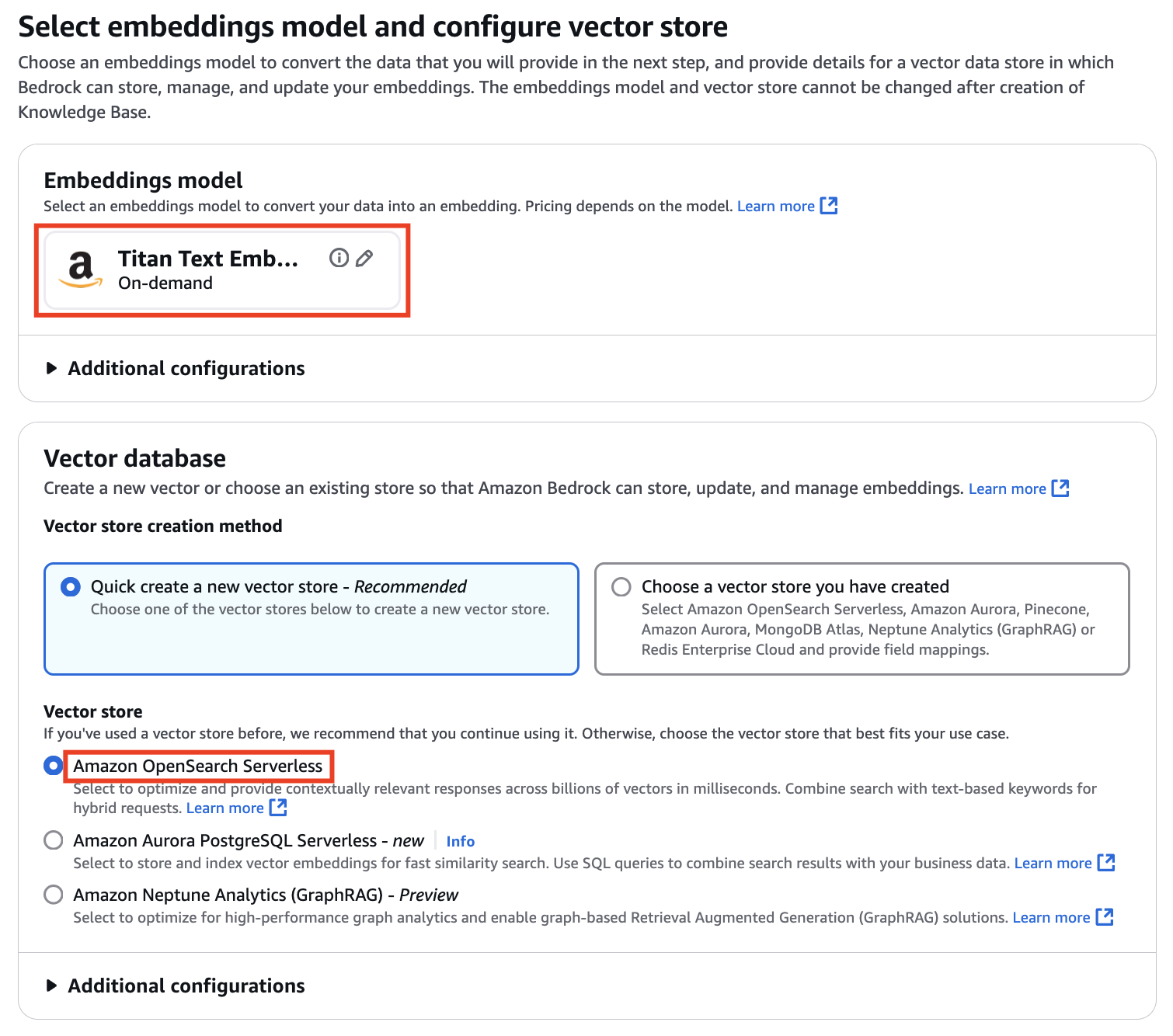
Select embeddings model and configure vector store
지식 베이스인 S3의 데이터를 변환할 임베딩 모델로는 'Titan Text Embeddings v2'를 선택하였으며 Bedrock이 임베딩을 저장, 관리 및 업데이트할 수 있는 벡터 데이터 저장소(=Vector DB)로는 'Amazon Opensearch Serverless'를 선택했습니다. (Knowledge Base를 만든 후에는 임베딩 모델과 Vector store를 변경할 수 없음)
Lambda 설정
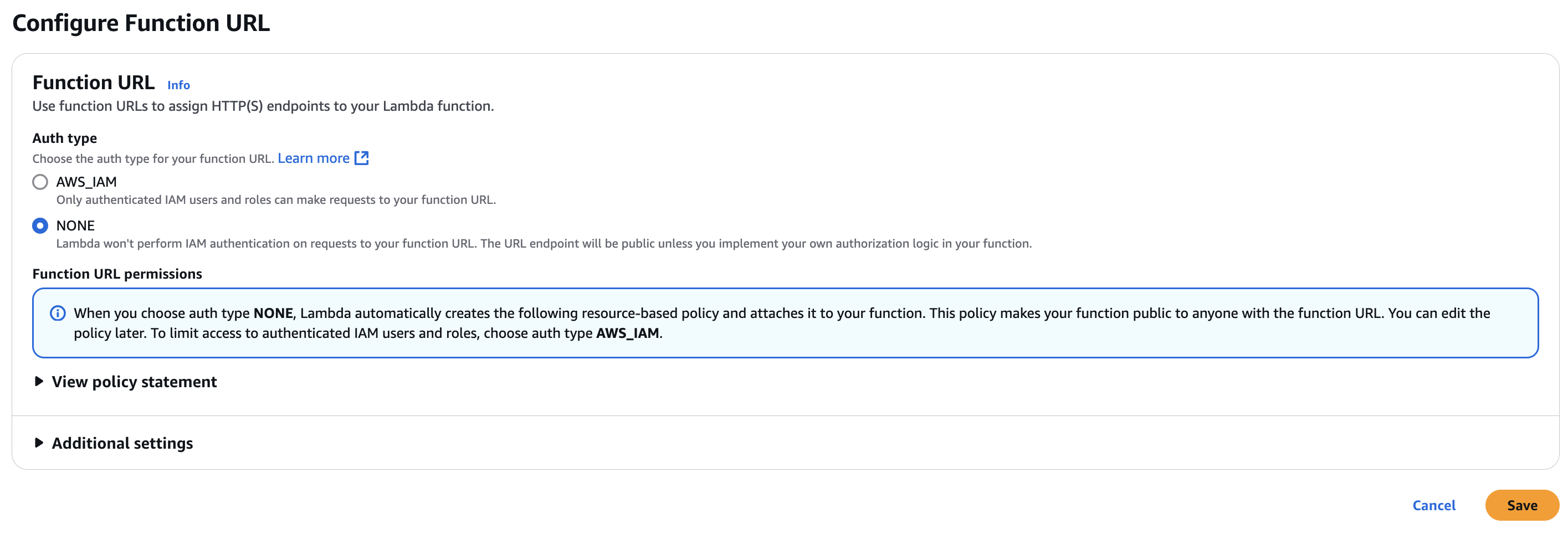
Function URL
슬랙에서 Lambda를 호출하기 위해 Lambda의 Function URL을 생성합니다.
Source code
LangChain 프레임워크
LangChain은 대형 언어 모델(LLM)을 사용하여 자연어 처리(NLP) 응용 프로그램을 구축하기 위한 프레임워크입니다. 주로 LLM을 활용한 다양한 애플리케이션을 쉽게 만들 수 있도록 도와주는 도구 모음이며 특히 복잡한 작업을 처리하는데 유용합니다.
슬랙봇 구현을 위해 LangChain 프레임워크를 활용하였으며, 사용한 함수는 아래와 같습니다.
from langchain_community.chat_models import BedrockChat
from langchain.chains import RetrievalQA
from langchain.retrievers.bedrock import AmazonKnowledgeBasesRetriever
from langchain.prompts import PromptTemplate
from langchain_community.chat_message_histories import DynamoDBChatMessageHistory
from langchain.memory import ConversationBufferMemorymain 함수
def lambda_handler(event, context):
slackBody = json.loads(event['body'])
slackBotId = slackBody['event']['blocks'][0]['elements'][0]['elements'][0]['user_id']
slackText = slackBody.get('event').get('text').replace('<@' + slackBotId + '>','')
slackUser = slackBody.get('event').get('user')
slackChannel = slackBody.get('event').get('channel')
message_history = DynamoDBChatMessageHistory(table_name=DMDB_NAME, session_id=slackUser, history_size=6)
memory = ConversationBufferMemory(
memory_key = "chat_history",
input_key = "question",
chat_memory = message_history,
return_messages = True
)
answer = retrieve_knowledge_base(slackText, memory, BEDROCK_REGION, BEDROCK_RUNTIME_EP, BEDROCK_MODEL_ID, BEDROCK_KNOWLEDGEBASE_ID)
request_slack_api(slackChannel, slackUser, answer)retrieve_knowledge_base 함수
BEDROCK_RUNTIME_EP = 'https://vpce-004xxxxxxxxxxxxxxxx.bedrock-runtime.us-east-1.vpce.amazonaws.com'
BEDROCK_KNOWLEDGEBASE_ID = 'S59xxxxxxx'
BEDROCK_REGION = 'us-east-1'
BEDROCK_MODEL_ID = 'anthropic.claude-3-sonnet-20240229-v1:0'
def retrieve_knowledge_base(question, memory, bedrock_region_id, bedrock_runtime_ep, bedrock_model_id, bedrock_knowledgebase_id):
PROMPT_TEMPLATE = """
Human: You are a kind guide, and provides answers to questions by using fact based information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context}
</context>
<question>
{question}
</question>
The response should be specific.
Assistant:"""
claude_prompt = PromptTemplate(
template = PROMPT_TEMPLATE,
input_variables = ["context", "question"]
)
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id = bedrock_knowledgebase_id,
retrieval_config = {"vectorSearchConfiguration": {"numberOfResults": 20}},
)
bedrock_client = boto3.client("bedrock-runtime")
claude_llm = BedrockChat(
model_id = bedrock_model_id,
model_kwargs = {
"temperature": 0.2, # 0 ~ 1
"top_k": 10, # 1 ~ (일반적으로)50-100
"top_p": 0.5, # 0 ~ 1
},
client = bedrock_client
)
qa = ConversationalRetrievalChain.from_llm(
llm=claude_llm,
retriever=retriever,
memory=memory,
combine_docs_chain_kwargs={"prompt": claude_prompt}
)
result = qa({"question": question})
answer = result["answer"]
return answerrequest_slack_api 함수
SLACK_API_URL = 'https://slack.com/api/chat.postMessage'
SLACK_BOT_OAUTH_TOKEN = 'xoxb-30615xxxxxxxxxxxxxxxxxx' # 하기 'Slack 설정' 부분에서 확인 가능한 값
def request_slack_api(slack_channel, slack_user, ai_answer):
slack_answer = {'channel': slack_channel, 'text': f"<@{slack_user}> {ai_answer}"}
print('* slack_answer: ' + str(slack_answer))
headers = {
'Authorization': f'Bearer {SLACK_BOT_OAUTH_TOKEN}',
'Content-Type': 'application/json'
}
http = urllib3.PoolManager()
response = http.request('POST', SLACK_API_URL, headers=headers, body=json.dumps(slack_answer))Slack 설정
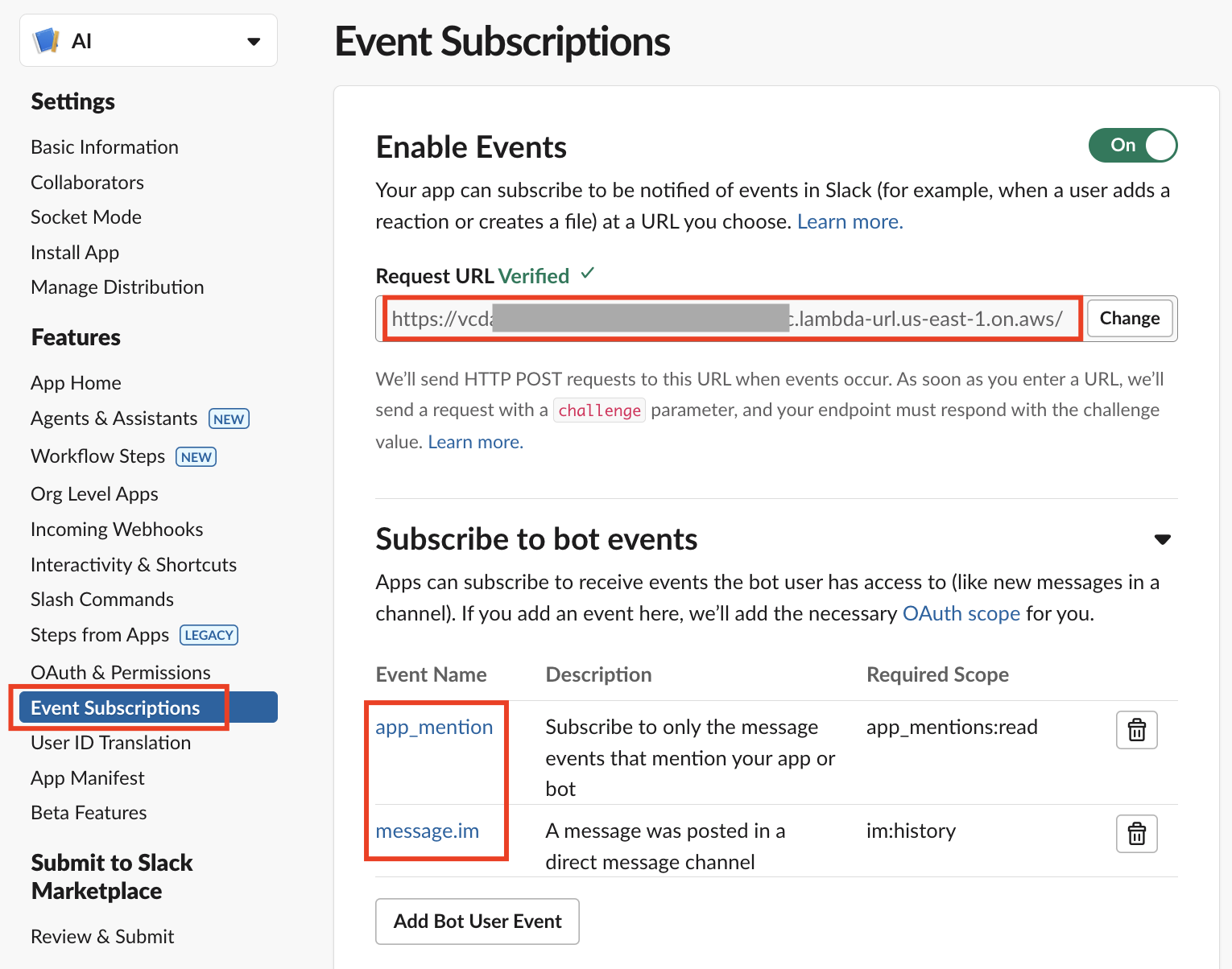
슬랙 앱을 생성한 뒤 'Event Subscriptions' 페이지 내 'Request URL'에 Lambda의 Function URL을 입력하여 최초 1회 인증(verify)을 진행합니다.
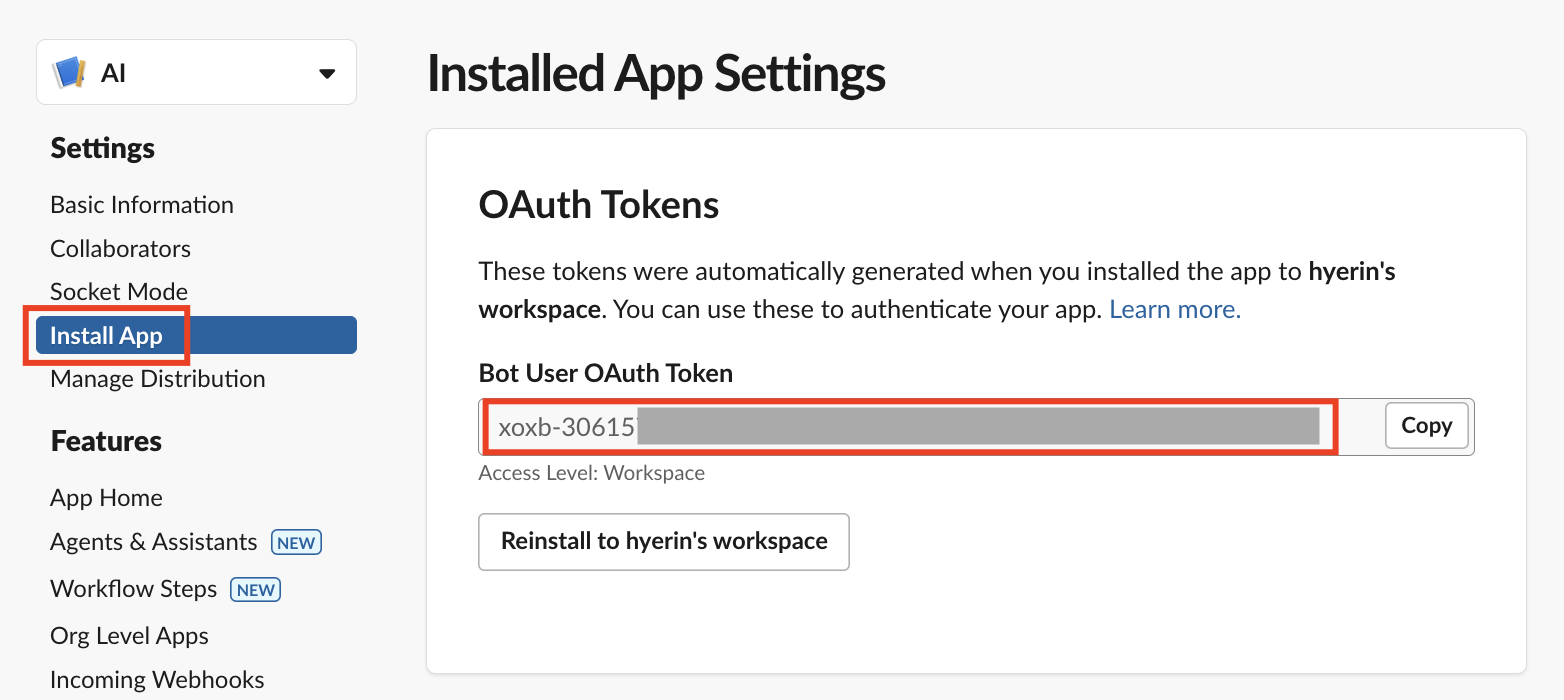
'Install App' 페이지의 'Bot User OAuth Token' 값이 바로 Lambda 소스 코드 내 SLACK_BOT_OAUTH_TOKEN 변수에 입력한 값입니다.
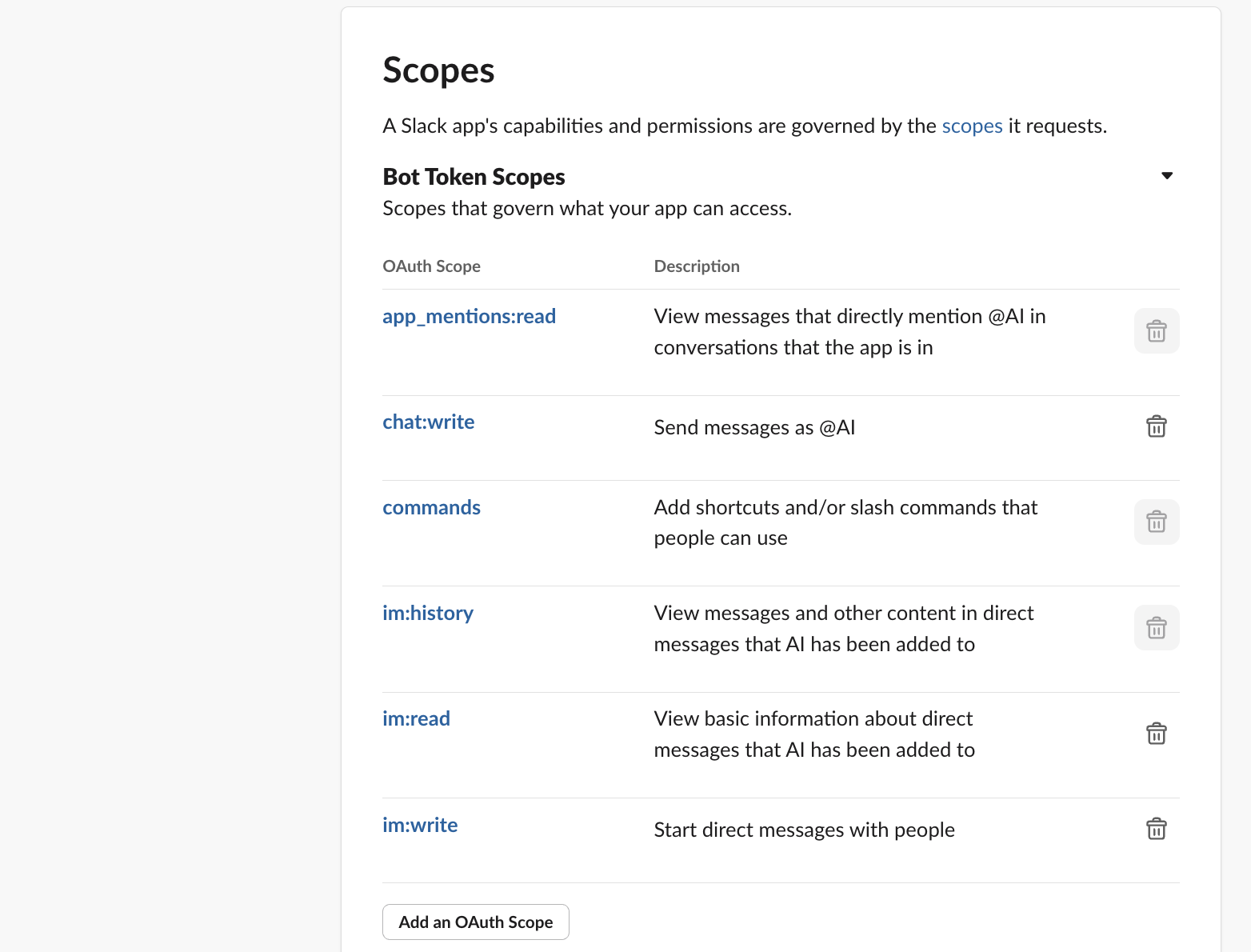
하단 'Scopes' 설정도 필요합니다.
테스트
이제 구현한 것을 테스트해 보겠습니다.
Data source인 S3에는 아래와 같은 Excel 파일을 넣었습니다.

이제 Slack에 미리 설정해 둔 App을 태그하여 지식 베이스 기반 질문을 해 보겠습니다.

이번에는 기존 대화 내용을 잘 기억해서 대답하는지 확인해 보기 위해 아래와 같이 질문해 보았으나 S3 데이터 기반 질문이 아닌 것은 잘 대답하지 못하는 현상이 발생했습니다.

따라서 Lambda Source code에 아래와 같은 구문을 추가하였습니다.
def retrieve_knowledge_base(question, memory, bedrock_region_id, bedrock_runtime_ep, bedrock_model_id, bedrock_knowledgebase_id):
...
# ✅ Claude의 대답 내용이 "정보 없음"일 경우 fallback하는 구문 추가
fallback_triggers = [
"죄송합니다",
"제공된 정보에는",
"관련 정보가 없습니다",
"설명할 수 없습니다",
"정보가 없습니다",
"답변할 수 없습니다",
"관련된 컨텍스트가 없습니다"
]
if any(trigger in answer for trigger in fallback_triggers):
print('* Answer indicates insufficient context. Using LLM fallback.')
response = claude_llm.invoke(question)
answer = response.content if hasattr(response, 'content') else response
return answer위 구문을 추가한 뒤 다시 똑같은 질문을 해 보았더니 이제는 S3 기반 질문이 아니어도 대답을 잘 하는 것을 확인할 수 있었습니다.
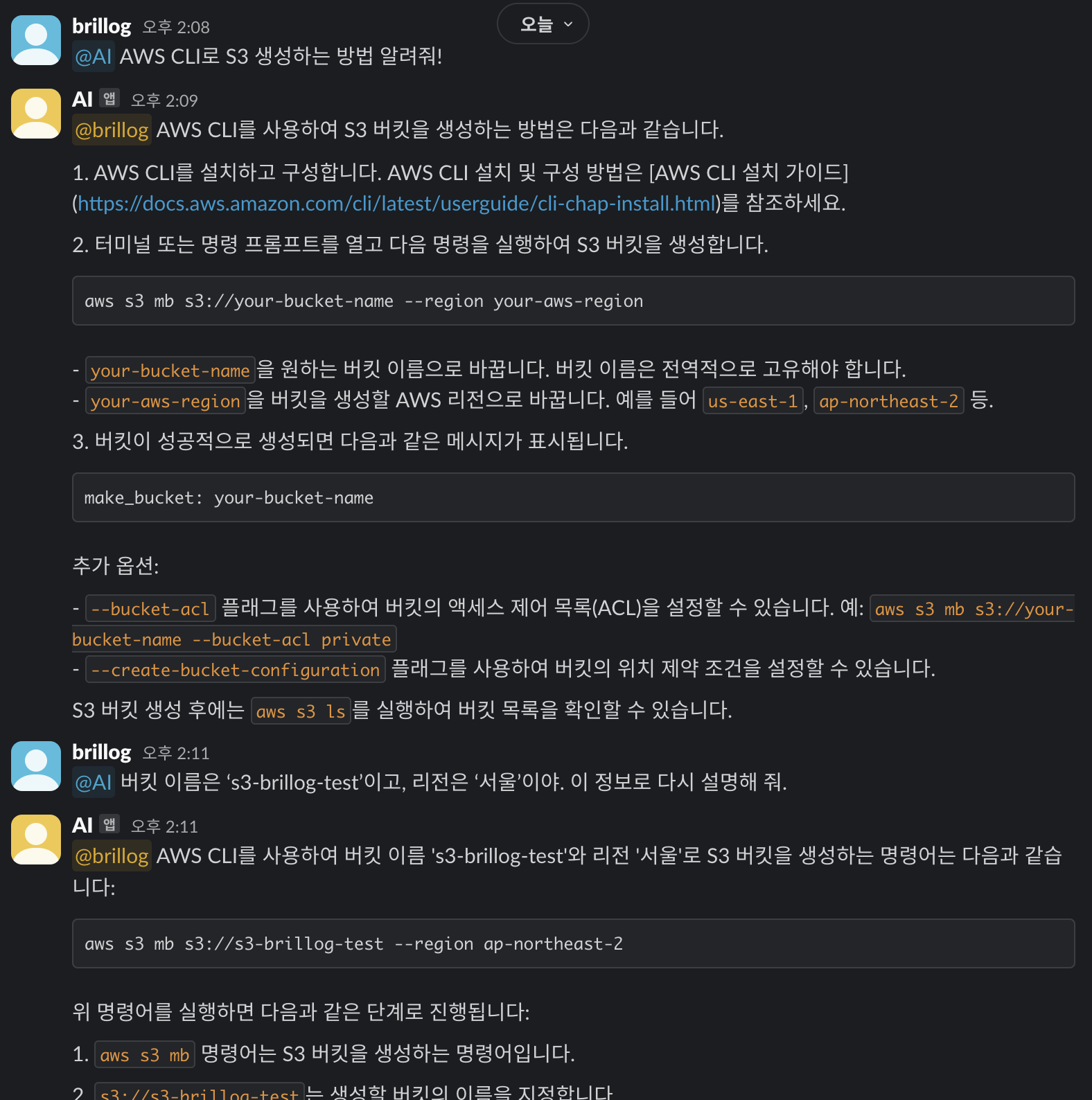
이전 대화 내용을 기억하여 대답하는지 확인하기 위한 질문에도 잘 대답하는 모습을 확인할 수 있습니다.
Reference
개인적으로 공부하며 작성한 글로, 내용에 오류가 있을 수 있습니다.
