
제로베이스 데이터 취업 스쿨select
=> 어떤 정보(컬럼)을 가지고 올건지
from
=> 어떤 소스에서 가지고올건지
where
=> 어떤 조건을 가지고 가지고올건지
우선 기본적으로 Properties, data 를 통해 전체 데이터를 훑어볼 수 있지만, 쿼리문을 통해 보고 싶다면 아래와 같이 작성하면 된다
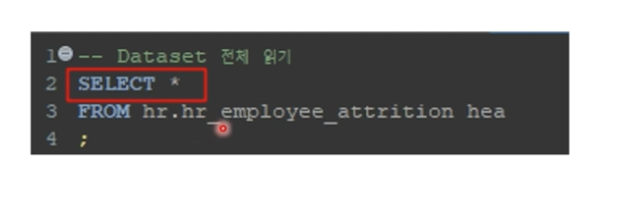
뒤의 hea는 약어이다 (as)를 생략한 것
만약 컬럼 순서를 조작해서 넣고 싶다면?
하나씩 입력하면 된다.

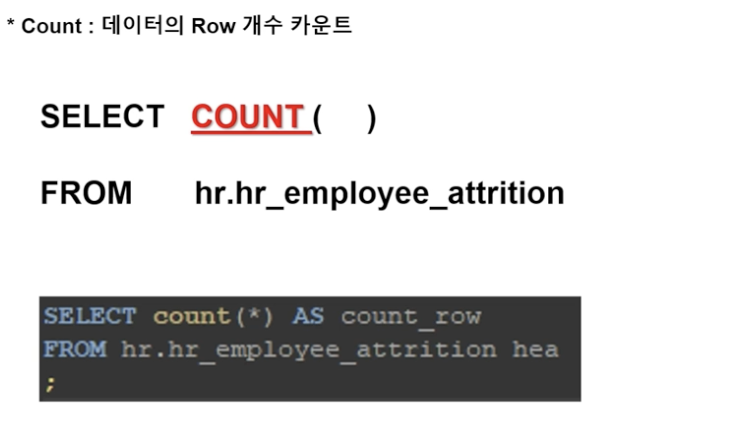
위의 뜻은 모든 데이터의 row를 카운트해달라는 것
즉, SELECT 에는 컬럼 등의 데이터가 올 수 도 있고, count 같은 집계함수가 들어올 수도 있다
하지만 그냥 count()를 하게 되면, 고유값을 알수는 없다.
그러니까 Department를 count 하더라도 전체 row를 count 하는 거기 때문에 count(*)와 같은 값이라는 것이다.
그럼 고유의 값을 즉, Department의 경우 부서의 갯수를 알고 싶다면 어떻게 하면 될까?

distict를 써주면 된다
groupby

어떤 컬럼을 기준으로 데이터의 집계값을 산출할지를 알려주는 키워드이다
groupby를 쓸 때는 select에 agg()로 어떻게 집계할건지 알려주는 함수도 함께 들어가야 한다
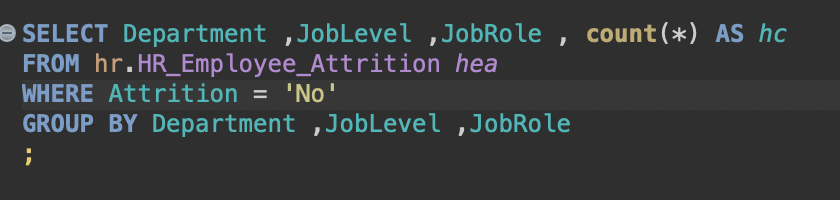
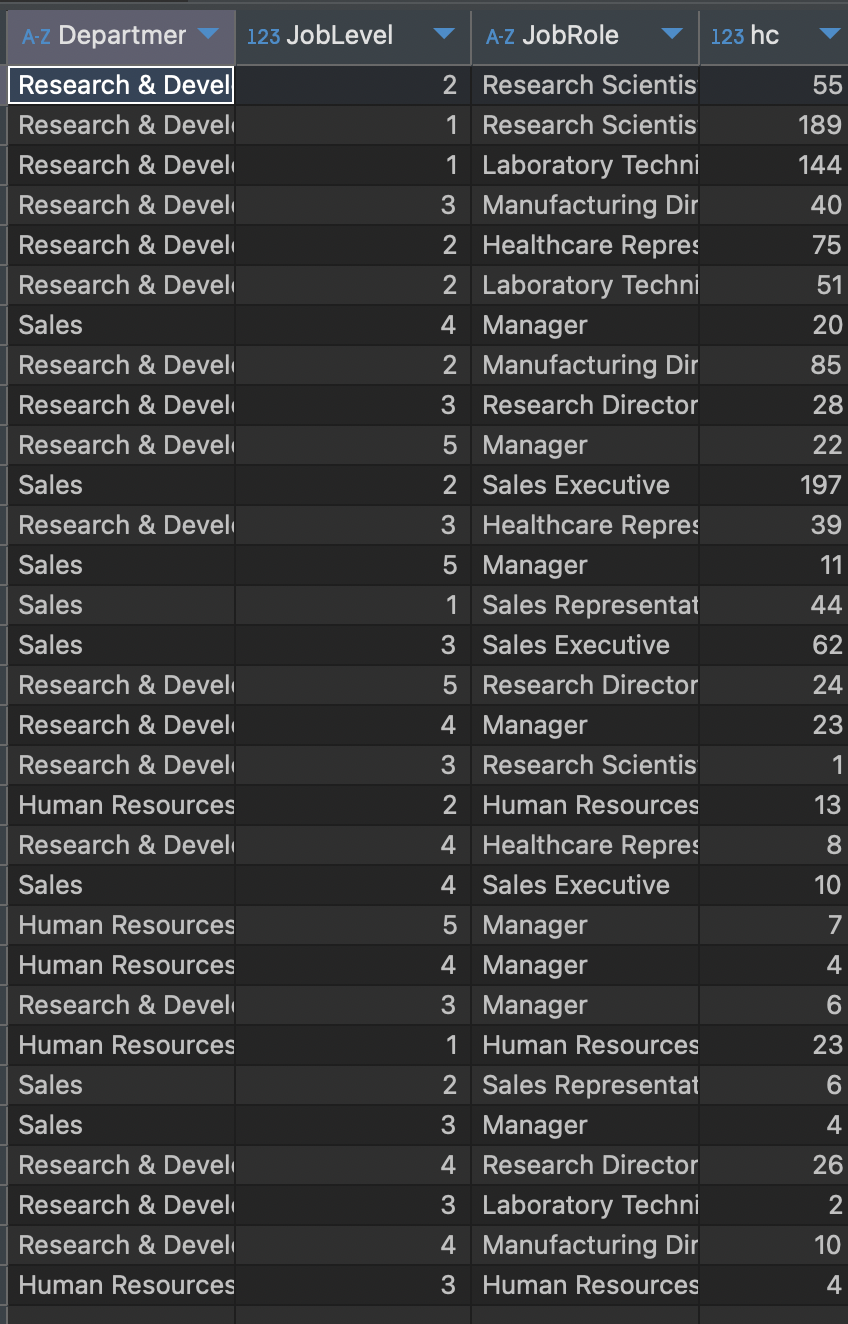
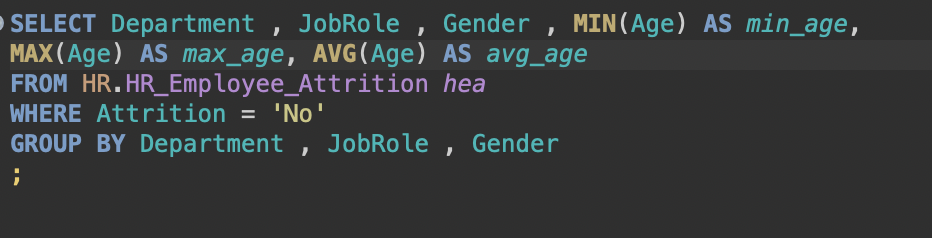
이렇게 하게 되면 재직중인 사람들 중에 부서별, 레벨별, 역할별로 나누어서(컬럼으로 지정해서) 그 안에 속하는 사람들의 수를 세어라 라는 명령이 되며, 결과는 아래와 같이 나온다.
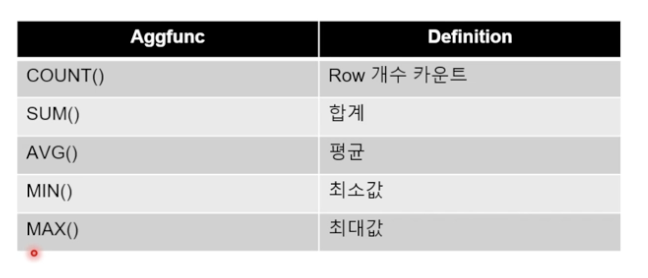
집계 함수 형식
제로베이스 데이터 취업 스쿨quiz
1)

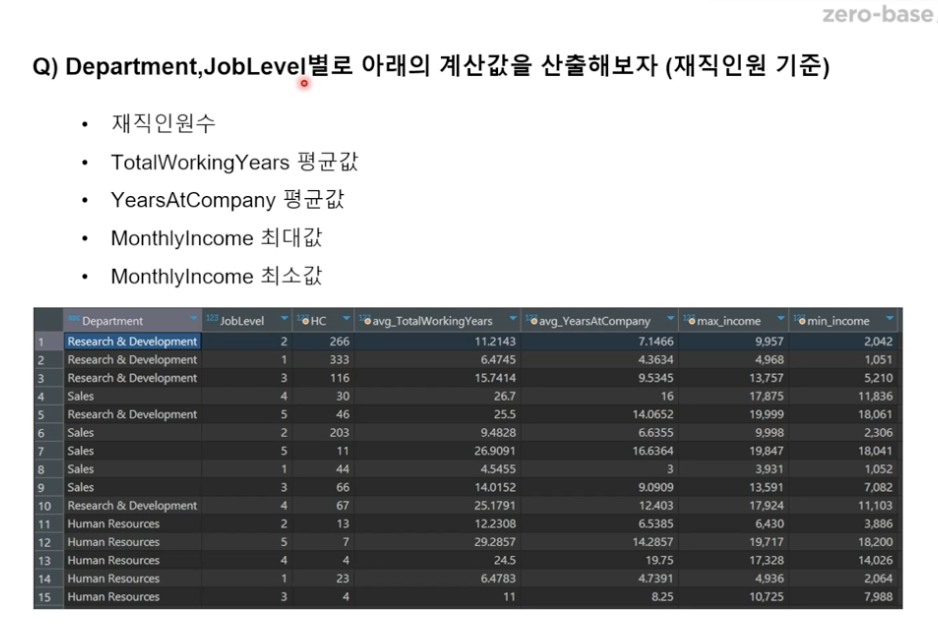
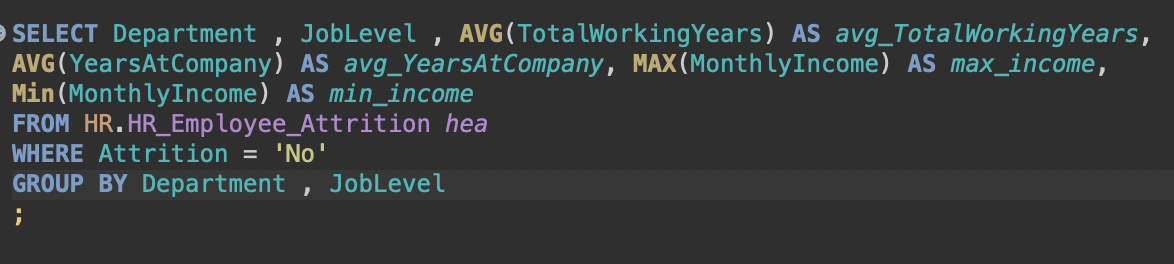
2)
oderby

oderby는 groupby 다음에 쓸 수 있음
데이터를 보여줄 때 우리가 원하는대로 정렬해서 보여주기 위한 키워드이다
=> agg로 새로 만들어진 컬럼들도 다 적어서 순서 정렬할 수 있음
기본적으로 oderby로 순서가 정해진 컬럼들은 row가 오름차순이다
만약 내림차순으로 하고 싶다면 아래와같이 하면 된다

