SQL 2
1.탐색적 데이터 분석

데이터 훑어보기1) info, describe 를 통해 훑어보기2) 컬럼에 널값이 있는지 체크3) 중복값 체크4) csv 파일 형식 체크데이터 재구조화1) 그룹바이 (groupby)2) 피봇테이블 (pivot_table)3) 스택/언스택 (Stack_Unstack)
2.구글 코랩 1

1) 중복값 확인은 아래와 같이 할 수 있다12행의 의미는 중복값을 제거한 컬럼의 길이를 구하라는 것.둘이 같은 숫자면 중복값이 없다는 의미가 될 수 있다숫자 형식 컬럼들만 뽑아서 count, mean, std, min 등을 계산해서 보여주는 함수라고 할 수 있다여기에
3.구글 코랩 2
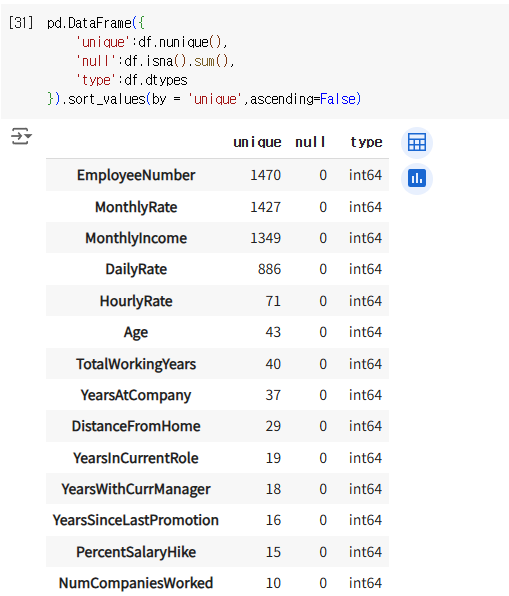
컬럼마다 고유한 값이 몇 개 있는지(중복값을 제외한 값의 갯수)null 갯수를 알려줌데이터 타입을 알려줌df.sort_values(by = '어떤 컬럼을 기준으로', 오름차순/내림차순 선택)정렬하는 함수라고 할 수 있다위와 같이 보게 되면유니크 값이 1인 컬럼 : 무의
4.구글 코랩 3
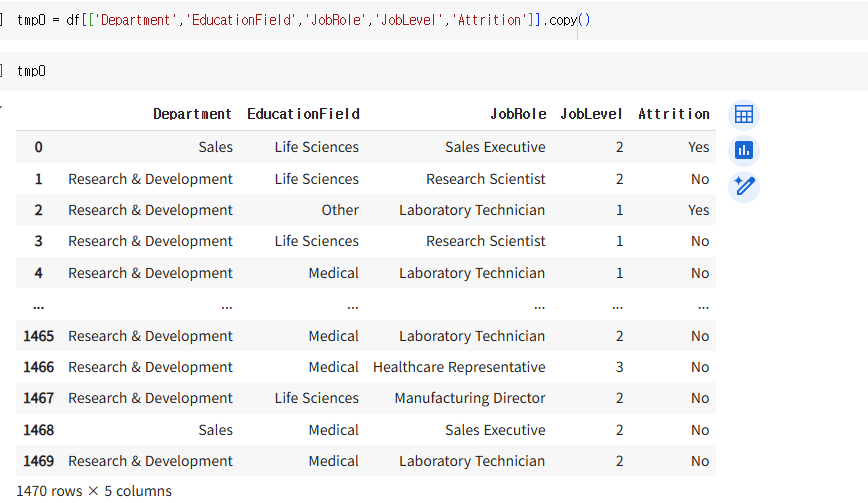
이제부터 사내 조직을 파악할건데, 사내 조직 파악에 필요한 컬럼들만 모아보겠다.앞으로 이 컬럼들만을 사용해서 구조를 분석할거기 때문에 tmp0 이라는 변수에 원본을 copy 해서 해당 컬럼만 빼온 데이터프레임을 넣어준다그러면 department부터 살펴보도록 하겠다de
5.구글 코랩 4
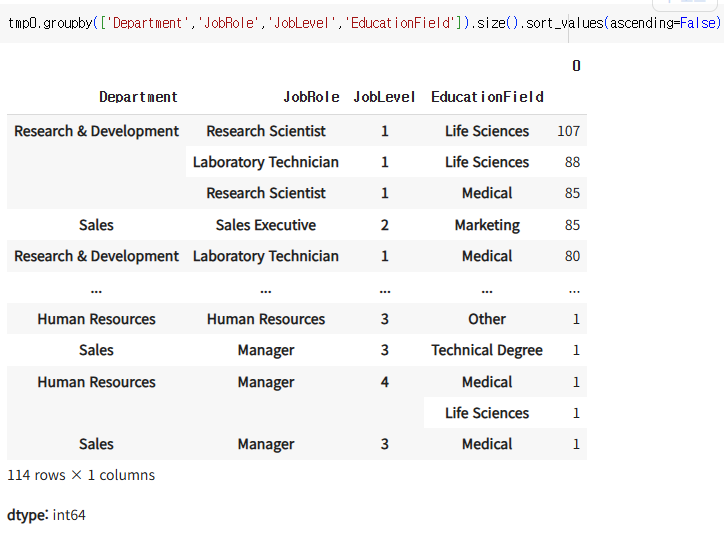
지금 우리가 사용하고 있는 tmp0은 df가 아니라 series이다. !=DataFrame.reset_index()이걸 DataFrame으로 바꿔주기 위해서는 reset_index()를 사용하면 되는데, 이때 우리가 size()로 세어준 셀의 갯수의 컬럼명이 임의로 0
6.파이썬 시각화 1 히트맵

우선 숫자형의 자료들만 모아서 cor_df를 만들어 본다그 다음 히트맵을 만들 건데, 아래와 같은 형식으로 만들어주면 된다우선 matplotlib.pyplot 과 seaborn 을 불러온 뒤 heatmap을 만들어주는데, 괄호 안에 들어갈 내용은 다음과 같다그 위의 p
7.파이썬 시각화 2 바그래프
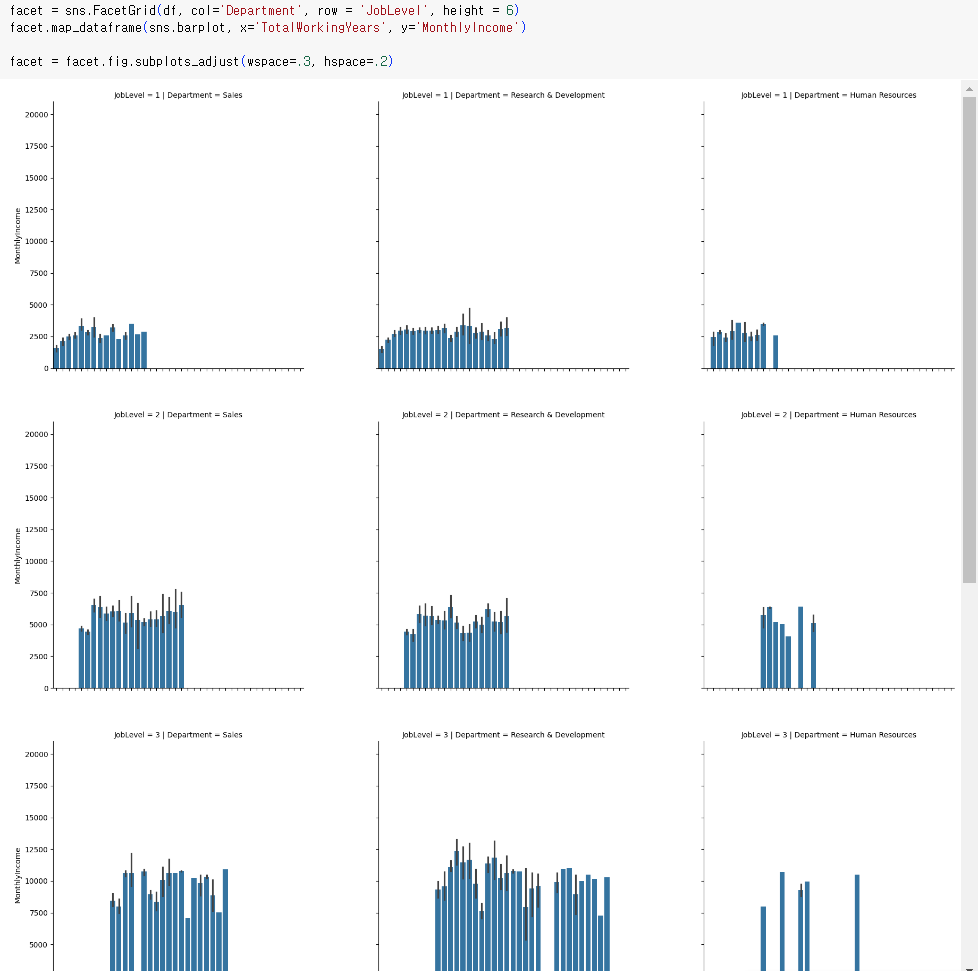
plt.bar( , ) 첫 번째로 들어가는 게 x축, 두 번째로 들어가는 게 y축이다 간단하게만 만들면 위와 같이 만들 수 있다 하지만, 차트의 이름, x/y축의 이름 등을 넣어주고 싶다면 아래와 같이 만들면 된다 또 다른 바 그래프를 만들어보면 다음과 같이 만
8.파이썬 시각화 3 regplot
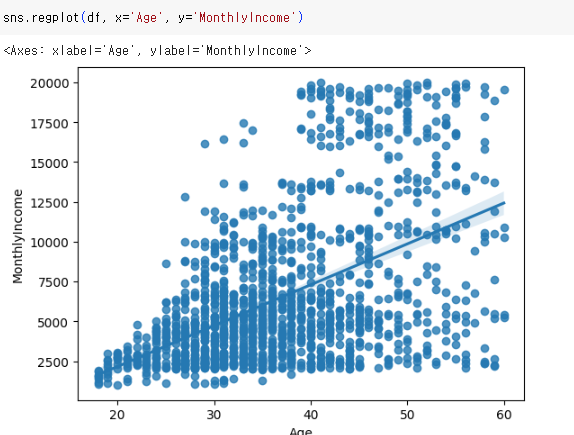
데이터의 분포와, 이 데이터를 선형으로 표현하는 Regression Line을 동시에 표현해주는 그래프점과 선이 함께 있는 그래프라고 생각하면 된다.기본 그래프는 위와 같이 그린다. 하지만 여기서도 차원을 더하고 싶다면 앞서 배운 FacetGrid를 사용한다방식은 똑같
9.파이썬 시각화 4 histplot
histplot 제일 단순하게는 이렇게 그릴 수 있다 다른 그래프들과는 조금 다른 형식의 파라미터를 넣어야 한다. 주의 y축을 따로 설정해주지 않아도 알아서 count 로 설정해서 표를 만들어준다 근데 지금은 age만 볼 수 있는데, 만약 다른 컬럼들의 coun
10.파이썬 시각화 5 jointplot
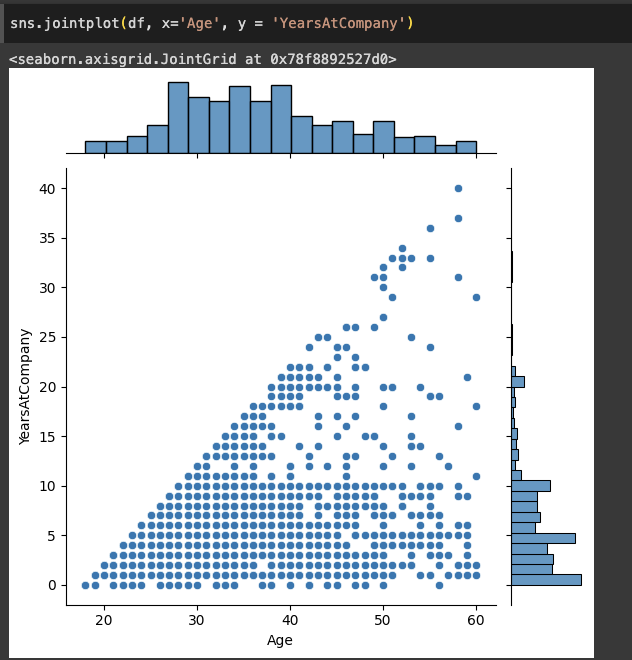
조금 더 복합적으로 만들 수 있는 그래프겹치고, 레이어 추가 가능제일 간단하게 만들면 이렇게 만들 수 있다위의 그래프는 age별 yearatcompany 값을 나타내면서도 각각 인수들의 count 도 함께 나타내준다.뒤에 kind='reg'를 추가해주면 선형 그래프도
11.MY SQL 1 기본 골자
제로베이스 데이터 취업 스쿨 select => 어떤 정보(컬럼)을 가지고 올건지 from => 어떤 소스에서 가지고올건지 where => 어떤 조건을 가지고 가지고올건지 우선 기본적으로 Properties, data 를 통해 전체 데이터를 훑어볼 수 있지만,
12.MY SQL 2 연산자
SELECT 에서 연산자를 쓰면 바로바로 0과 1로 true, false의 값을 알 수 있는데, 이 점을 이용해서 아래와 같은 것들을 수행할 수 있다 (1이 true, 0이 false) 1) 중복된 값이 있는지 없는지 확인하기 두 개의 값을 비교하면 중복된 값이 있
13.MY SQL 3 논리 연산자
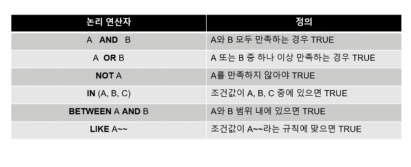
논리 연산자 표in 과 between 의 차이in => 비연속적between => 연속적인 데이터, A between B 일때 A와 B를 포함하는 값이다like는 와일드카드 같은 느낌논리 연산자도 마찬가지로 select 절에서 사용할 수 있다쉬운 예시로 살펴보면 위와
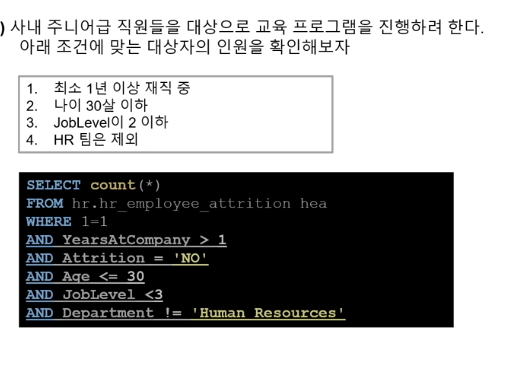
14.쿼리 과제 1

select employeenumberfromwhere 1=1,and workingyear >= 5,and workingyear = yearsincurrentrole,and yearsincelastpromotion >=1and attrition = 'No'select
15.MY SQL 4 테이블 크리에이트 1

지금까지는 한 큐에 원하는 컬럼들이 다 있어서 사용하기 편리했다.당연히 이러한 자료가 사용하기 편리하고, 좋긴 한데예를 들어 address 라는 값이 있다고 치자.그러면 그 내부의 값은 적어도 5글자~15글자가 되는데 ,데이터용량을 많이 먹기도 하고, 중복되는 값이 있
16.MY SQL 5 데이터 타입
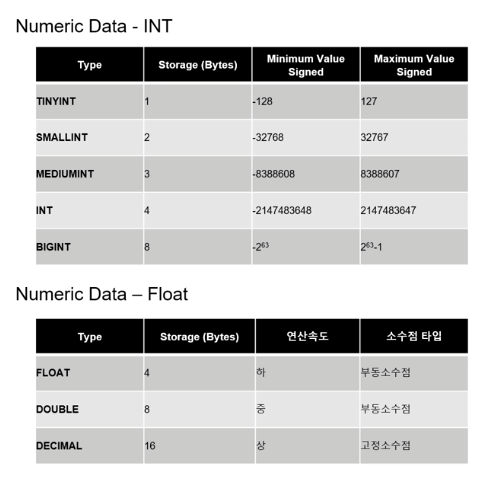
storage = db 공간=> ex. 작은 숫자를 쓸 때는 굳이 int 쓰지 않고 tinyint를 쓰면 도움이 된다(-128~127까지의 숫자)decimal => 고정 소수점, 미묘하게 0.00001 처럼 자투리가 생기는 것도 전부 다 잡아줌char(4) 는 첫번째
17.MY SQL 6 테이블 크리에이트 2
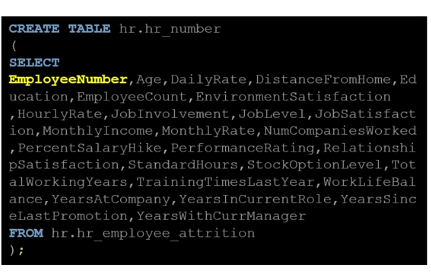
이번에는 테이블 크리에이트를 하는 또 다른 방법을 알아볼 것이다.(1에서는 문자열 컬럼만 모아서 테이블을 만들었고, 이번에는 숫자열 컬럼들만 모아서 테이블을 만들 것이다)원천 테이블이 있는 경우 가능한번에 create 와 insert 를 하는 방법이라고 할 수 있다여기
18.MY SQL 7 JOIN
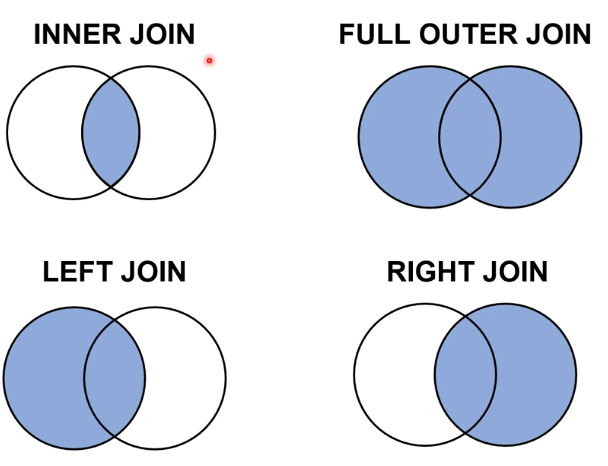
left (join을 기준으로 왼쪽의 테이블과) , right (join을 기준으로 오른쪽의 테이블)두 개의 테이블을 합체하는 것을 조인이라고 한다두 개의 테이블의 교집합만 결과물로 나오게 되는 joinwhere 절의 필터와 같은 효과를 낸다고도 볼 수 있다
19.MY SQL 8 limit/having
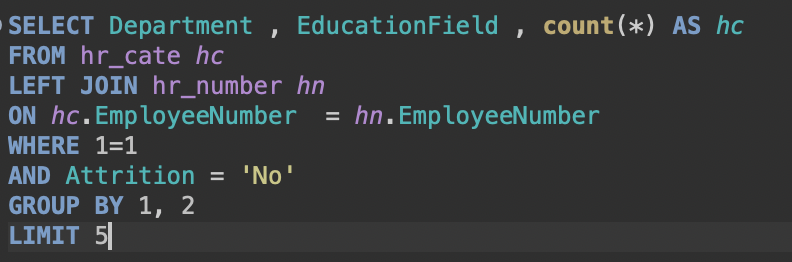
=> 판다스에서 print 할때 첫 5 행만 보여주는 게 head(5) 였고, 그 역할을 대신하는 게 limit 이다(order by를 더해서 최상단 5명만 보여줌)집계값에 조건 걸기where 은 select의 컬럼들에 조건을 걸었다면,having은 select의 집계
20.MY SQL 9 window_function

기본 개념그러니까 group by 처럼 집계된 값만 보여주는 게 아니라, 새로운 컬럼을 추가해서 그 안에 우리가 집계하고자 했던 값을 넣어서 보여주는 형태라고 보면 될듯=> job level 별로 employee number 를 더해라 대신 더한 값을 바로 보여주지말고
21.MY SQL 10 lead&lag
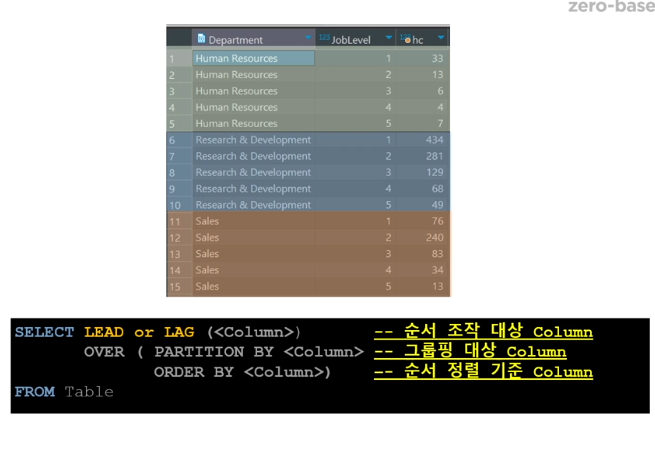
기본 개념 lead = 나보다 앞서나가고 있는 것을 당겨오는 느낌 lag = 뒤에있는 것을 데려오는 느낌 제로베이스 사용법 window function에서 우리는 sum(집계함수)를 쓰는 것만 배웠었는데, 그 자리에 lead/lag 를 작성하면 된다 내부에 or
22.POWER BI 1
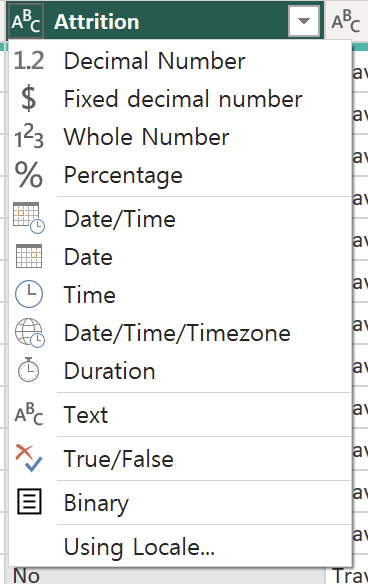
csv 파일 그냥 가져오면 컬럼명이 사라질 수 있다.이런 경우 데이터 변환 해줘야 함 => '첫 행을 머릿글로 사용'그리고 데이터 변환 창에서 저렇게 데이터 형식에 대한 많은 정보들을 지정하고 변경할 수 있다만약 숫자 데이터가 스트링으로 인식이 되었다면, 그것도 변경할
23.POWER BI 2
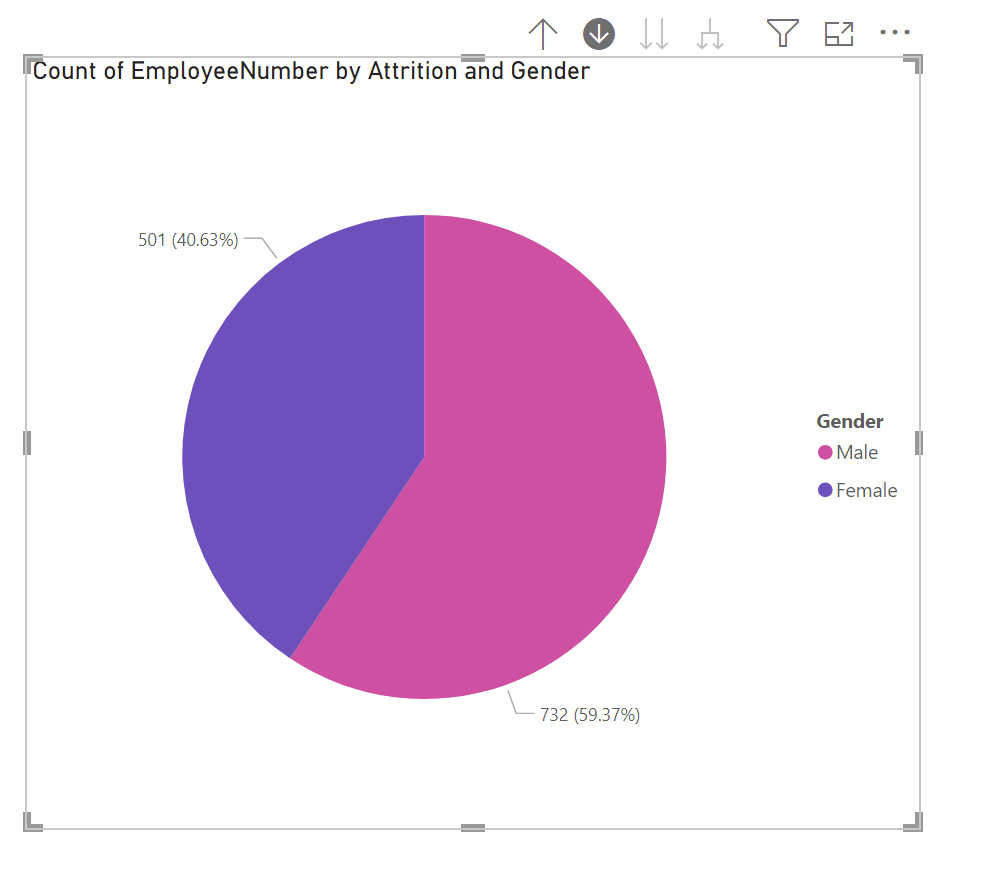
파이차트에서 드릴업/다운이 가능하다이렇게 범례가 2개이면 드릴다운 가능함아래 화살표 하나있는 걸 한 번 누르면 드릴모드그 상태에서 첫번째 범례 (attrition)으로 가서 no/yes를 선택하게 되면 드릴다운되어범례 yes/no각각이 100%인 상태에서 여성과 남성의
24.POWER BI 3
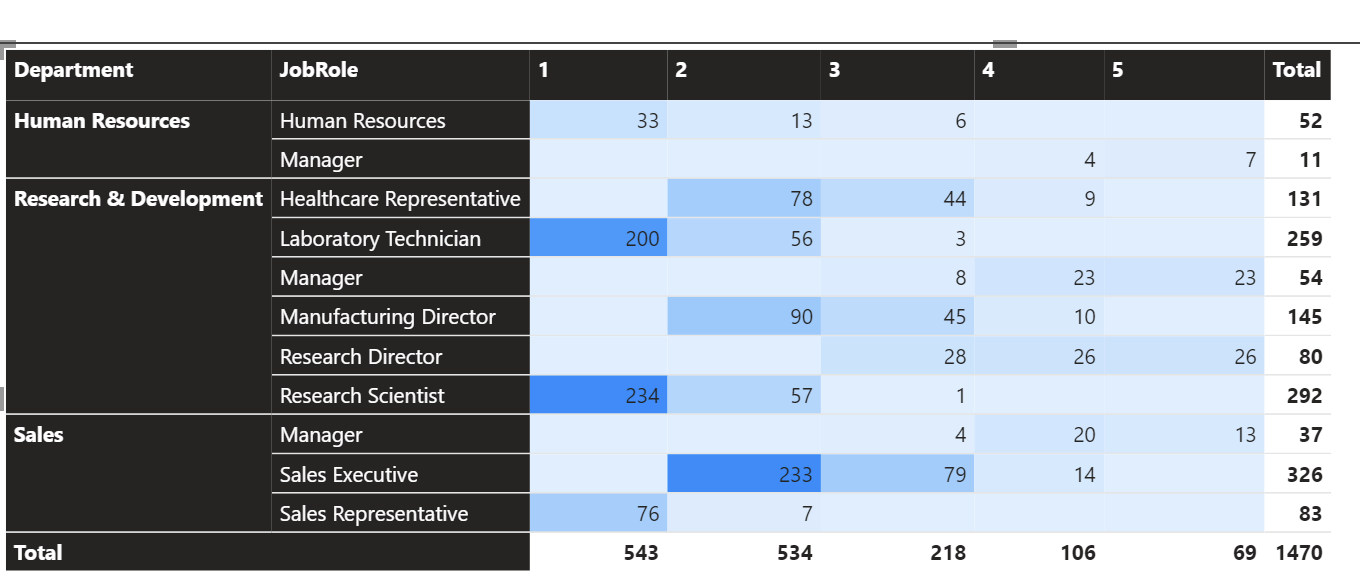
MATRIX 드릴다운 사용 가능. Rows 에 두 개 이상의 컬럼을 넣게 되면, 위쪽 컬럼을 기준으로만 값이 보이게 되고, 드릴 다운하면 그 하위컬럼이, 또 하게 되면 그 하위 컬럼이 다 보이게 되는 형태이다
25.PWER BI 4
데이터 추가하기 = Enter Data => 외부 데이터가 아니라, 내가 직접 작은 데이터를 써서 추가할 수 있고, 연결할 수도 있다 여기서 내가 원하는 데이터들을 추가할 수 있다. 그렇게 load를 하게 되면 오른쪽에 데이터가 추가된 것을 볼 수 있다 연결하는 방
26.POWER BI 라인그래프
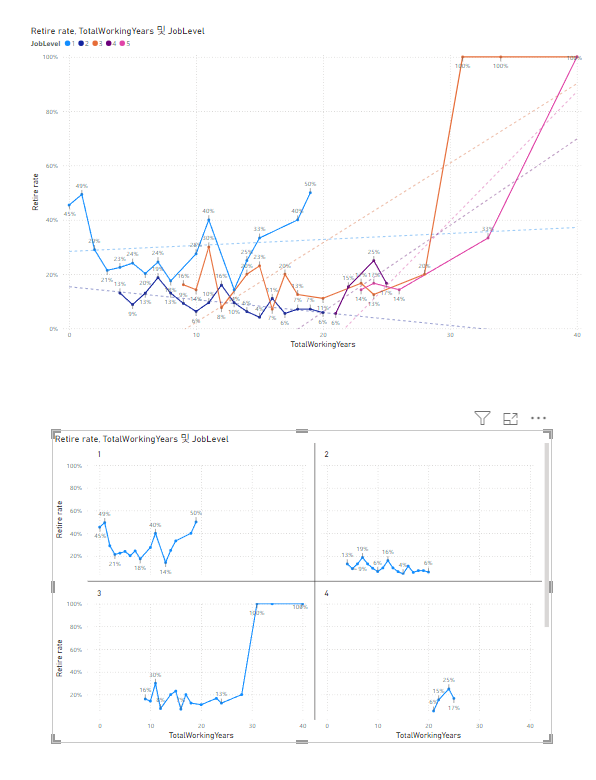
범례의 구분이 많아서 한 그래프에 나타내기 힘들 때, 같은 기준으로 범례들을 따로따로 다른 그래프에 그려주는 것을 한 번에 보여주는 그래프1) 슬라이서 사용하기2) 테이블 사용하기슬라이서는 보는 분들이 하나하나 체크하면서 확인하기 위한 것필터는 애초에 보여줄 때부터 (