df.nunique()
컬럼마다 고유한 값이 몇 개 있는지
(중복값을 제외한 값의 갯수)
df.isna()
null 갯수를 알려줌
df.dtypes()
데이터 타입을 알려줌
sort_values(by = '',ascending = False)
df.sort_values(by = '어떤 컬럼을 기준으로', 오름차순/내림차순 선택)
정렬하는 함수라고 할 수 있다
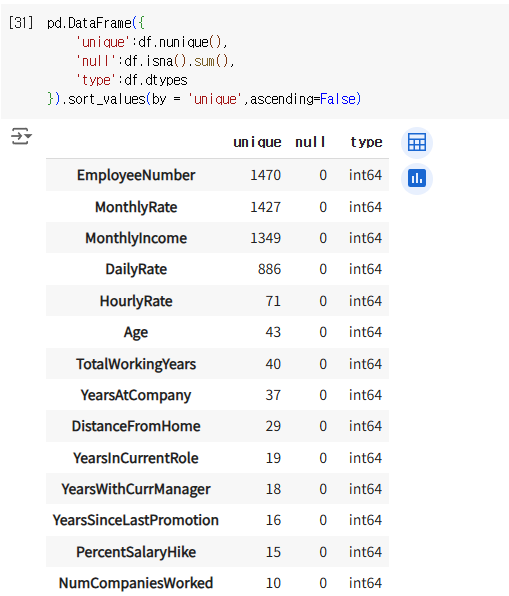
위와 같이 보게 되면
유니크 값이 1인 컬럼 : 무의미하다
모두 같은 값을 가지고 있기 때문에
그렇다면 무의미한 컬럼을 지워줄건데, 방법은 아래와 같다
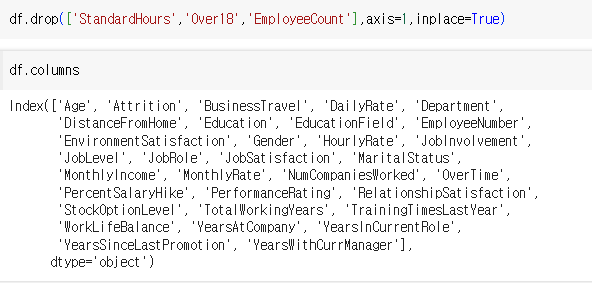
axis=1의 의미는 앞의 정보들은 컬럼이라는 것을 나타내고, 컬럼을 지울 거라고 알려주는 부분이다.
만약 이 부분을 설정하지 않으면 row에서 앞의 값을 찾게 되기 때문에 오류가 난다
inplace는 굳이 변수로 한번 넣어주지 않아도 그냥 df에 drop한 값을 넣어주겠다는 의미가 된다.
drop 하고 나서 저렇게 컬럼이 너무 많아서 한번에 확인하기 어려운 경우는 len(df.columns)를 하면 숫자로 쉽게 확인이 가능하다
df.select_dtypes(include = 'object')
이렇게 하면 데이터타입이 object인 컬럼들만 모아서 보여준다
숫자타입을 보고 싶다면아래와 같이 하면 된다
df.select_dtypes(include='int64')

이직 준비중