matplotlib 과 seaborn 을 사용하면 시각화할 수 있다

우선 숫자형의 자료들만 모아서 cor_df를 만들어 본다

그 다음 히트맵을 만들 건데, 아래와 같은 형식으로 만들어주면 된다

우선 matplotlib.pyplot 과 seaborn 을 불러온 뒤 heatmap을 만들어주는데, 괄호 안에 들어갈 내용은 다음과 같다
그 위의 plt.figure(figsize = (15,10))은 히트맵의 사이즈를 의미한다

마지막으로 색상까지 넣게 되면 아래와 같은 결과물이 만들어진다
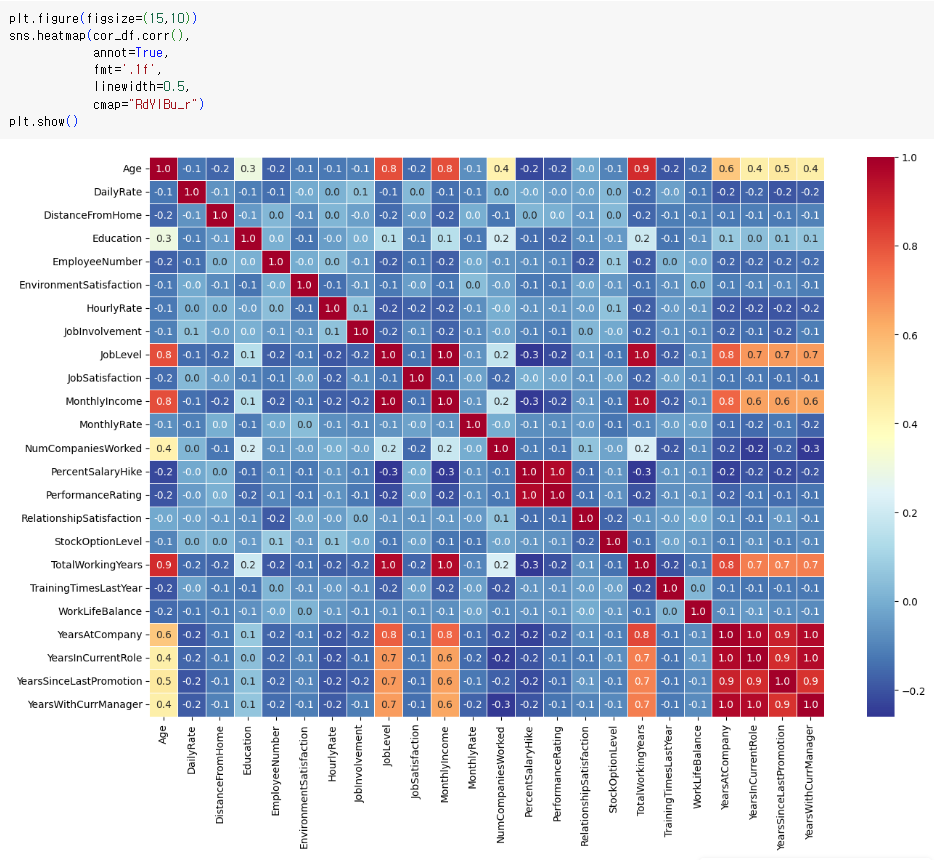
아직까지 익숙하지 않아서 보기 힘든데, 컬럼의 수를 적게 해서 다시 한번 만들어 보겠다
df.select_dtypes(include='int64').corr().sum().sort_values(ascending=False)[:8]
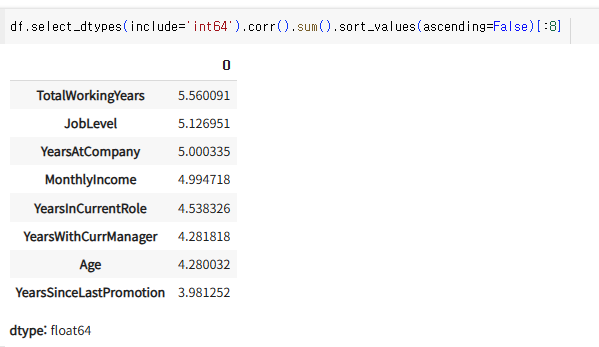
위의 의미는 각 열과의 상관관계가 제일 높은 아이들 순서대로 9번째 아이까지만 고르겠다는 의미.
.corr() 의 의미는 각 열 간의 상관계수를 반환하는 것
.sum() 의 의미는 각 열간의 상관계수가 차이가 크지도 않고, 뭔가 적절해서 그냥 합한 수로 순위를 매기겠다는 의미
여기서 우리는 이 표가 중요한 게 아니라, 1~9위까지의 컬럼을 사용하겠다고 추출한 거기 때문에 이 컬럼들을 list로 변환하여 top8_cols라는 변수에 넣어준다

그러면 이런 값을 얻을 수 있다.
우리는 이제 이 컬럼들을 이용해서 히트맵을 그려볼 것이다
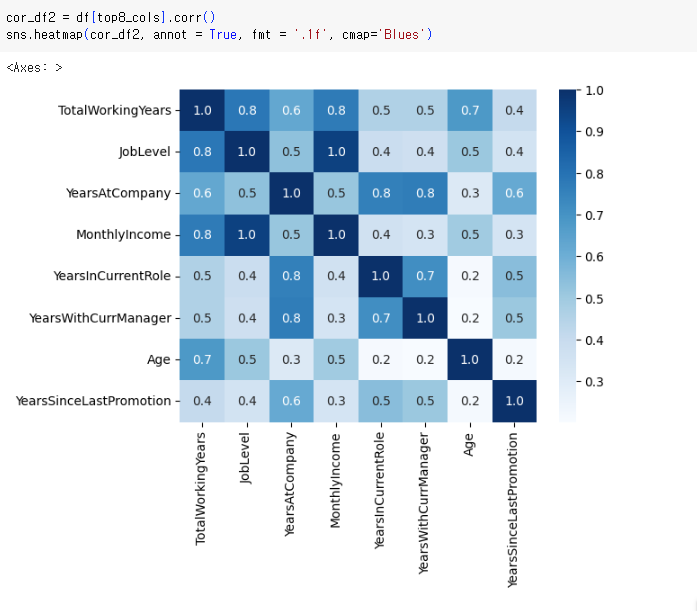
위의 히트맵보다 값이 적어서 훨씬 보기 좋은 것을 볼 수 있다
(+앞서서 내림차순으로 정렬했기 때문에 더 보기 좋은 것도 있다)
그리고 이제 이 히트맵을 삼각형으로 만들어서 더 보기 좋게 만들 수 있는데,
import numpy as np (넘파이를 import 해 주고)
np.triu_indices_from : 위의 삼각형을 날려주는 함수
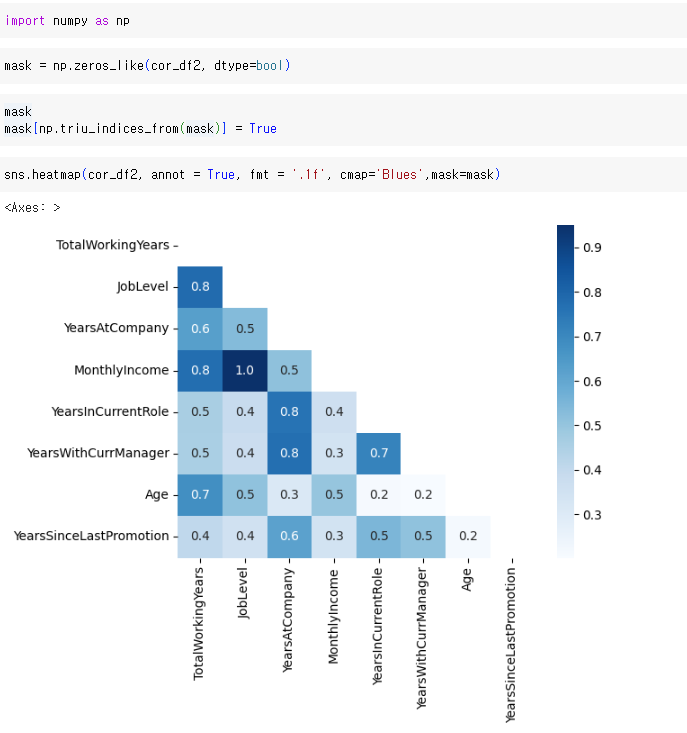
아무튼 마스크를 씌워서 위의 삼각형을 날려주는 작업을 했다고 할 수 있다
