의료 IT를 할때는 오라클을 썼는데, SM근무를 하며 병원통계기록을 뽑아줄때 select 쿼리를 참 많이 사용했었다. 지금은 frontend로 커리어 전환을 하려다보니 쿼리를 안써버릇해서 다시 공부중이다. mysql로 공부를 하려고 하다 아래 사이트를 찾았는데 공부하기 좋은 사이트 같다.
MySQL 학습사이트
https://www.mysqltutorial.org/
MySQL etc
1. Built-in BOOLEAN?
mySQL은 빌트인 BOOLEAN타입을 가지고 있지 않다. 대신 TINYINT(1)를 BOOLEAN으로 사용한다. 1은 참, 0은 거짓
2. Treatment of date '0000-00-00'
'0000-00-00'은 is null에 대응된다.
select cast('0000-00-00' as date) is null // 13. influence of @@sql_auto_is_null
mySQL의 @@sql_auto_is_null의 디폴트는 0이다. 이것이 만약 1로 세팅이 되고 is null 조건에 의해 조회를 하면 auto_increment column이 입력되고 마지막으로 성공한 값을 조회한다.
4. evaluate 순서
표준 SQL의 일반적인 evaluate 뒤는 순서는 아래와 같다.
FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY > LIMIT하지만 mySQL의 evaluate 순서는 아래와 같다. 관련이유 링크(ONLY_FULL_GROUP_BY)
FROM > WHERE > SELECT > GROUP BY > HAVING > ORDER BY > LIMIT5. ALIAS 별치
select절에서 ALIAS를 컬럼에 사용한다.
mySQL에서는 group by, having에도도 알리아스를 사용할 수 있다.
WHERE에서는 못쓴다. 왜냐하면 WHERE는 SELECT 절이 평가되기전에 실행되기 때문에...그럼 MYSQL에서는 왜 GROUP BY, HAVING에서는 쓸 수 있을까?
mysql의 ONLY_FULL_GROUP_BY 기능과 관련이 있는데 스탠다드한 ALIAS 사용을 원한다면 sql_mode에서 ONLY_FULL_GROUP_BY를 설정하면 된다.
SET [SESSION | GLOBAL] sql_mode = ONLY_FULL_GROUP_BY;그럼 group by와 having에서 별칭을 사용할 수 없다.
테이블에도 ALIAS를 사용할 수 있는데 조인시에 동일한 컬럼이 있을 때 어느 테이블을 가리키는지 명확히 하기 위해서이다.
6. JOIN
mySQL에서는 full outer join을 지원하지 않는다.
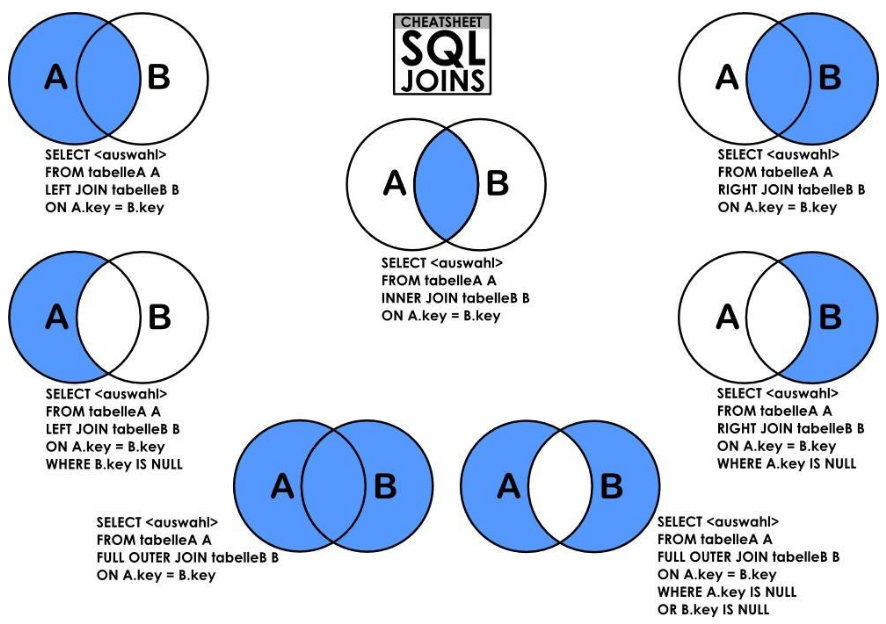
6-1. using 과 on
join시에 비교하는 컬럼이 같은 컬럼명이면 using을 쓸수있고 on으로 했을 때와 동일하다.
-- on 사용시
SELECT
m.member_id,
m.name member,
c.committee_id,
c.name committee
FROM
members m
INNER JOIN committees c
ON c.name = m.name;
-- using 사용시
SELECT
m.member_id,
m.name member,
c.committee_id,
c.name committee
FROM
members m
INNER JOIN committees c USING(name);6-2. on 과 where
table a를 기준으로 b를 left조인 한다고 하자.
select
...
from
table a,
left join table b on a.id = b.id
left 조인(left outer 조인) right 조인(right outer 조인)은 기준이 되는 테이블의 데이터 전부를 대상
- 조건(on 혹은 using사용)과 맞으면
조건과 맞는 데이터를 조회 - 조건과 맞지 않으면
b에서 해당하는 데이터는 null데이터로 조회
한다. 즉 left 조인 right 조인에서 on에 해당하는 조건은 조회가 될 데이터가 나오느냐 null로 된 데이터가 나오느냐의 차이일 뿐 기준테이블의 모든 데이터를 다 대상으로 row가 조회된다.
하지만 where 절에서 조건을 건다면 기준테이블의 모든 데이터를 다 대상으로 row를 조회하지 않고 where조건에 맞는 것들만 대상으로 한다.
inner 조인에서는 on에 걸든 where에 걸든 조회결과는 같다.
6-3. cross join
크로스 조인은 조건이 없는 조인이라고 생각하면된다. 따라서 각 테이블의 row수만큼 n x m 개의 행이 만들어진다. 즉 모든 조건에 대응되는 조인이며 이때 where을 사용해서 조건을 추가하면 inner join과 같다.
Group by
group by는 컬럼이나 표현식의 값을 기준으로 행집합을 요약행집합으로 그룹화한다. 즉 각 gruop에 대해 하나의 행을 반환한다.
ℹ️ aggregate function: sum,avg,max,min,count 등의 집계함수
- mySQL에서는 표준 SQL과 달리
group by와having에 alias를 사용할 수 있다. - mySQL에서는 표준 SQL과 달리
group by에 desc을 사용할 수 있다.
Rollup
하나의 쿼리에서 두개 이상의 그룹화 집합을 함께 생성하려면 union all을 사용할 수 있다. 하지만 두개의 문제가 있다.
- 쿼리가 길어질 수 있다.
- 디비엔진이 두개의 개별쿼리를 실행하고 다시 하나로 결합해야하므로 성능이 좋지 않을 수 있다.
이때 사용하는게 with rollup이다.
SELECT
productLine,
orderYear,
SUM(orderValue) totalOrderValue
FROM
sales
GROUP BY
productline,
orderYear
WITH ROLLUP;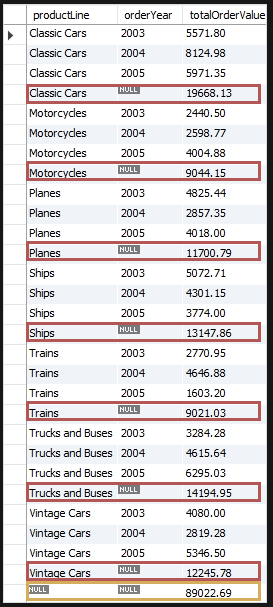
rollup은 부분합 행에 대해서 그룹핑을 해준다.
1. grouping()
grouping() 함수는 supper-aggregate row에서 null이면 1을 리턴, 아닌경우 0을 리턴한다.
grouping()함수는 select,having,order by에서 사용할 수 있다.
rollup을 사용함으로서 발생한 null에 대응할수 있는 함수이다.
select
if(grouping(orderyear), 'ALL YEARS', orderYear) orderyear,
if(grouping(productLine), 'ALL PRODUCTLINES', productLine) productLine,
sum(orderValue) totalOrderValue
from
sales
group by
orderYear,
productline
with rollup;CTE : Common Table Expression
mySQL의 8.0 버전이상에만 사용가능하다.
재귀 CTE는 CTE 이름 자체를 참조하는 하위쿼리가 있는 CTE이다.
재퀴 CTE는 아래와 같은 형태로 만들어진다.
WITH RECURSIVE cte_name AS (
initial_query -- anchor member
UNION ALL
recursive_query -- recursive member that references to the CTE name
)
SELECT * FROM cte_name;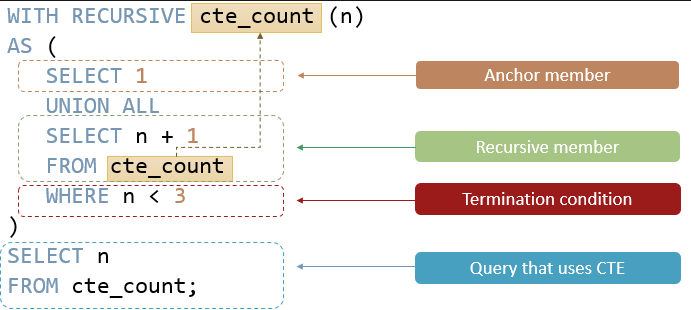
ℹ️ 실행순서
- 멤버를 앵커멥버와 재귀멤버로 구분한다.
- 앵커멤버를 실행하여 기본 결과 집합 R0를 형성하고 이 기본 결과 집합을 다음 반복에 사용함
- 그런다음 Ri 결과 집합을 입력으로 재귀멤버를 실행하고 Ri+1 출력으로 만듬
- 재귀멤버가 빈 결과집합을 반환할때까지 3단계를 반복함. 종료조건이 충족된다.
- 마지막으로 union all 연산자를 사용해서 R0 ~ Rn으로 결과 집합을 결합한다.
ℹ️ 재귀멤버 제한
재귀멤버는 다음 구성을 포함하지 않아야한다.
- 집계함수
- group by
- order by
- limit
- distinct (union distinct 사용시에는 허용됨)
앵커멤버에는 적용되지 않는다.
EXISTS 와 IN
exists 는 실행결과가 있으면 true, 없으면 false를 리턴한다. 즉 최소한의 결과가 있는지 여부만 확인되면 스캔을 멈추기 때문에 일반적으로 in 보다 빠르다.
하지만 in을 사용시 결과가 적다면 in이 더 빠를 수 있다.
MINUS, INTERSECT
SQL의 표준 세집합 연산자는 UNION,INTERSECT,MINUS이다.
1. MINUS
mySQL은 MINUS연산자를 지원하지 않는다. 대신 LFET JOIN 절을 사용해서 MINUS와 동일한 결과를 반환한다.
2. INTERSECT
mySQL은 INTERSECT연산자를 지원하지 않는다. 대신 INNER JOIN과 DISTINCT를 사용하거나 DISTINCT와 하위쿼리를 사용해서 결과를 동일하게 얻을 수 있다.
참고링크
